当您处理金融时间序列时,我们通常可以获得相对高频的观察结果。
例如,每天进行观察是很常见的。事实上,现在可以获得每小时、分钟、秒甚至毫秒的观测值。
可下载资源
使用的包
有许多软件包可以使我们能够估计波动率模型。
我们将使用单变量 GARCH 模型和 (用于多变量模型)包。
我们还将使用该 quantmod 软件包,因为它可以让我们轻松访问一些标准财务数据。
数据上传
在这里,我们将使用包提供的方便的数据检索功能(getSymbols) quantmod 来检索一些数据。例如,此函数可用于检索股票数据。
默认来源是 Yahoo Finance. 如果您想找出哪些股票有哪个符号,您应该能够在互联网上搜索以找到股票代码列表。下面介绍如何使用该功能。但请注意,我的经验是有时连接不起作用,您可能会收到错误消息。在这种情况下,只需在几秒钟后重试,它就可以正常工作。
getSymbols("IBM")
## \[1\] "IBM"
getSymbols("GOOG")
## \[1\] "GOOG"
getSymbols("BP")
## \[1\] "BP"
在您的环境中,您可以看到这些命令中的每一个都使用各自的股票代码名称加载一个对象。让我们看一下这些数据框之一,以了解这些数据是什么:

您可以看到该对象包含一系列每日观察结果( Open、 High和 Close股价 )。我们还了解到对象被格式化为xts 对象, 是一种时间序列格式,实际上我们了解到数据范围从 2007-01-03 到 2022-03-24。
使用以下命令生成一个看起来有点花哨的图表
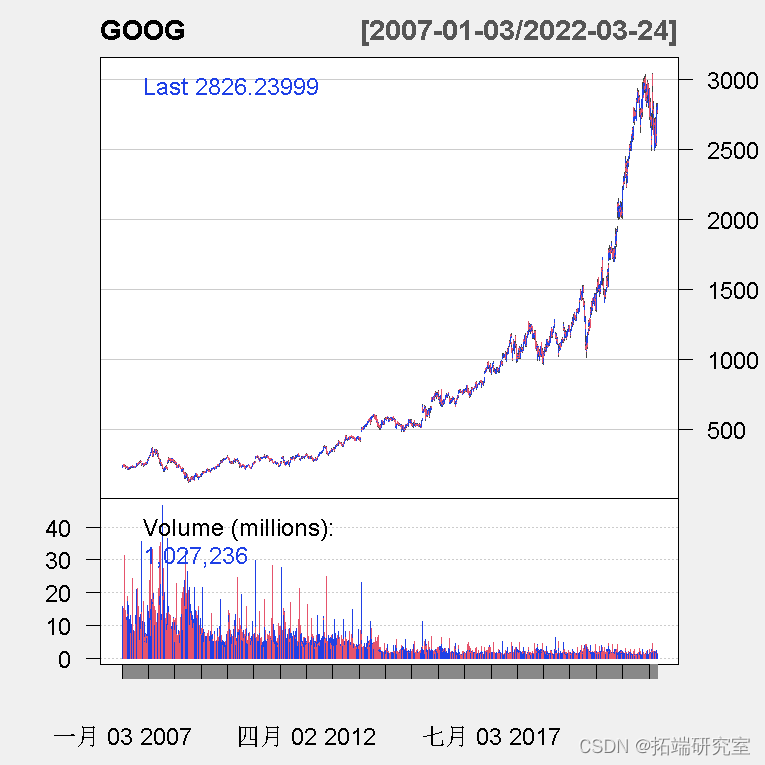
当我们估计波动率模型时,我们使用收益率。有一个函数可以将数据转换为收益率。
dailyReturn(IBM)
单变量 GARCH 模型
您需要做的第一件事是确保您知道要估计的 GARCH 模型类型,然后让 R 知道这一点。让我们看看:
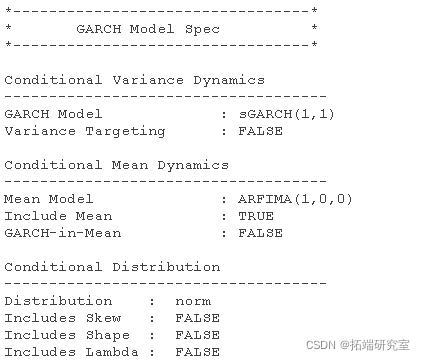
这里的关键问题是 Mean Model (这里是 ARMA(1,1) 模型)和 GARCH Model, 这里 sGARCH(1,1) 基本上是 GARCH(1,1) 的模型。

假设您要将平均模型从 ARMA(1,1) 更改为 ARMA(1,0),即 AR(1) 模型。
uec <- ugarchspec
以下是 EWMA 模型示例。
ewm = ugarchspe
模型估计
现在我们已经指定了一个模型来估计,我们需要找到最好的参数,即我们需要估计模型。这一步是通过 it 函数来实现的。
fit(specrIBM)
fit 现在是一个包含一系列估计结果的列表。让我们看看结果
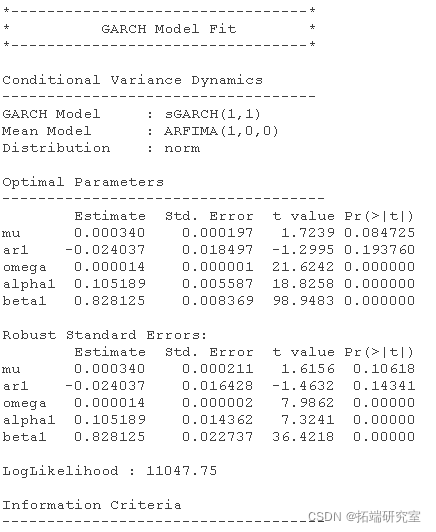

ar1 是均值模型的 AR1 系数(这里非常小且基本上不显着), alpha1 是 GARCH 方程中残差平方 beta1 的系数,是滞后方差的系数。
随时关注您喜欢的主题
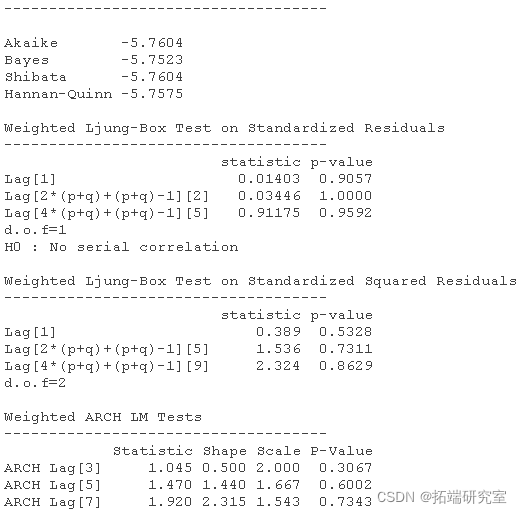
通常,您会希望使用模型输出进行一些进一步的分析。因此,了解如何提取参数估计值、标准误差或残差等信息非常重要。该对象 ugfit 包含所有信息。
names
如果您想提取估计的系数,您可以通过以下方式进行:

让我们绘制平方残差和估计的条件方差:
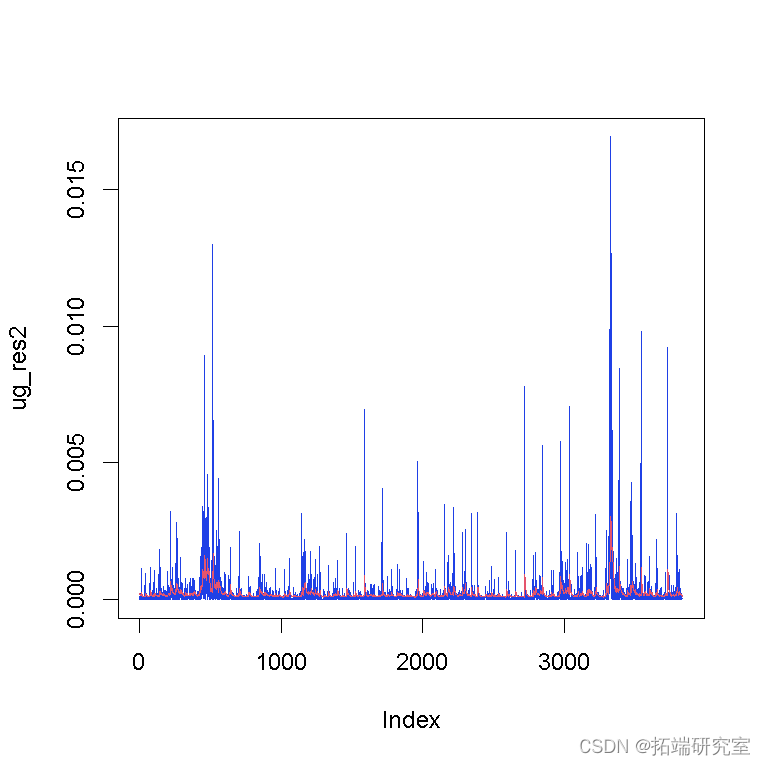
模型预测
通常您会希望使用估计模型来随后预测条件方差。用于此目的的函数是 forecast 函数。该应用程序相当简单:
hforecast(ugfit

正如你所看到的,我们已经对未来十天进行了预测,包括预期收益 ( Series) 和条件波动率(条件方差的平方根)。您可以提取条件波动率预测如下:
forecast$sigmaFor plot
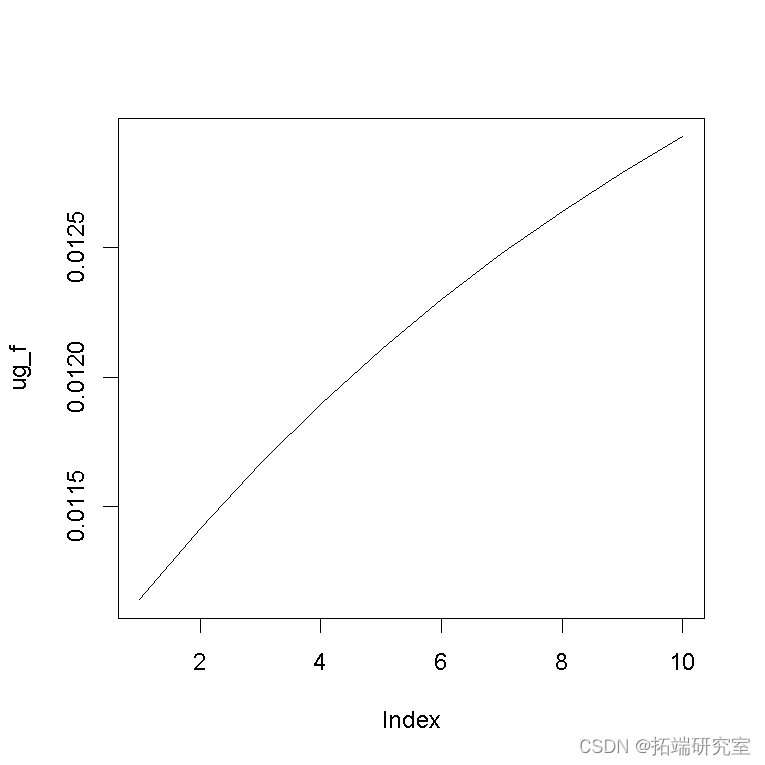
请注意,波动率是条件方差的平方根。
为了将这些预测放在上下文中,让我们将它们与估计中使用的最后 50 个观察值一起显示。
(tail(ug_var,20) ) # 得到最后20个观察值 tail(ug_res2,20 )) # 得到最后的20个观测值
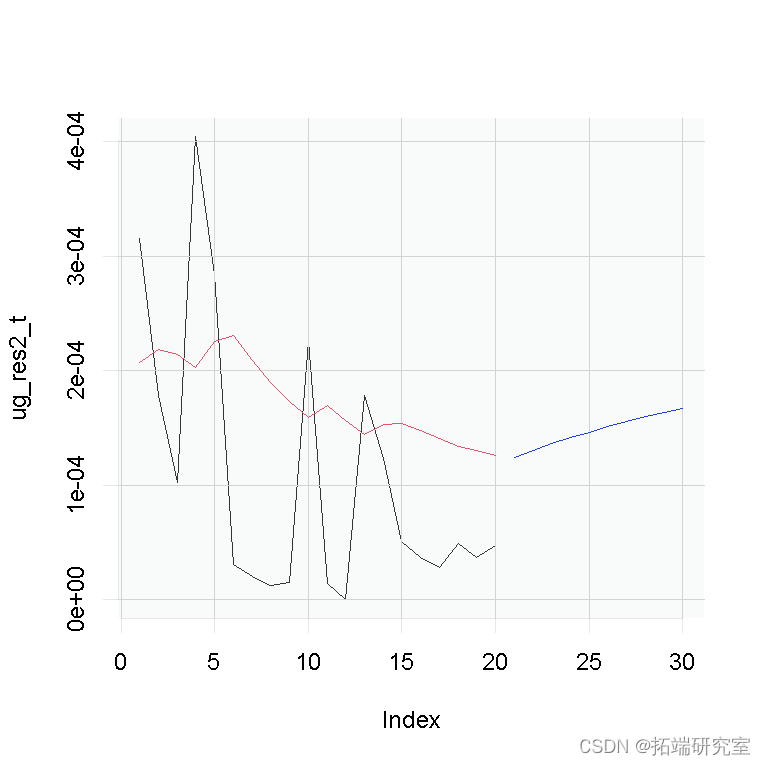
您可以看到条件方差的预测是如何从上次估计的条件方差中得出的。事实上,它从那里慢慢地向无条件方差值递减。
多元 GARCH 模型
通常,您需要对波动性进行建模。这可以通过单变量 GARCH 模型的多变量版本来完成。估计多变量 GARCH 模型比单变量 GARCH 模型要困难得多,但幸运的是,已经开发了处理大多数这些问题的程序。
在这里,我们来估计 BP、Google/Alphabet 和 IBM 股票收益率的多元波动率模型。
在这里,我们坚持使用动态条件相关 (DCC) 模型。在估计 DCC 模型时,基本上是估计单个 GARCH 类型模型。然后将这些用于标准化各个残差。作为第二步,必须指定这些标准化残差的相关动态。
模型设置
在这里,我们假设我们对三种资产中的每一种都使用相同的单变量波动率模型。
# DCC (MVN) u.n = multispec
这个命令有什么作用?它指定了一个 AR(1)-GARCH(1,1) 模型。将这个模型复制了 3 次(因为我们拥有三种股票,IBM、Google/Alphabet 和 BP)。
我们现在使用命令估计
结果保存在 multf 其中,您可以 multf 在命令窗口中键入以查看这三个模型的估计参数。但是我们将在这里继续指定 DCC 模型。
spec
模型估计
现在我们可以使用该 fit 函数来估计模型了。
fit1 =fit(spec1)
当您估计像 DCC 模型这样的多元波动率模型时,您通常对估计的协方差或相关矩阵感兴趣。毕竟,这些模型的核心是允许股票之间的相关性随时间变化。因此,我们现在将学习如何提取这些。
# 获取基于模型的时间变化协方差(阵列)和相关矩阵 rcov(fit1) # 提取协方差矩阵 rcor(fit1) # 提取相关矩阵
要了解我们手头的数据,我们可以看一下维度:
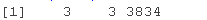
我们得到三个输出,告诉我们我们有一个三维对象。前两个维度各有 3 个元素(想想一个 3×3 相关矩阵),然后是第三个维度,有 3834个元素。这告诉我们 cor1 存储了 3834(3×3) 个相关矩阵,一个用于每天的数据。
让我们看看最后一天的相关矩阵,第 3834天;
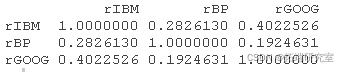
因此,假设我们要绘制 Google 和 BP 之间的时变相关性,即最后一天的 0.1924。在我们的收益矩阵中, rX BP 是第二个资产,而 Google 是第三个。因此,在任何特定的相关矩阵中,我们都需要第 2 行和第 3 列中的元素。
cor1\[2,1,\] # 将最后一个维度留空意味着我们需要所有元素 as.xts(c G) # 采用xts的时间序列格式--对绘图很有用
现在我们绘制这个。
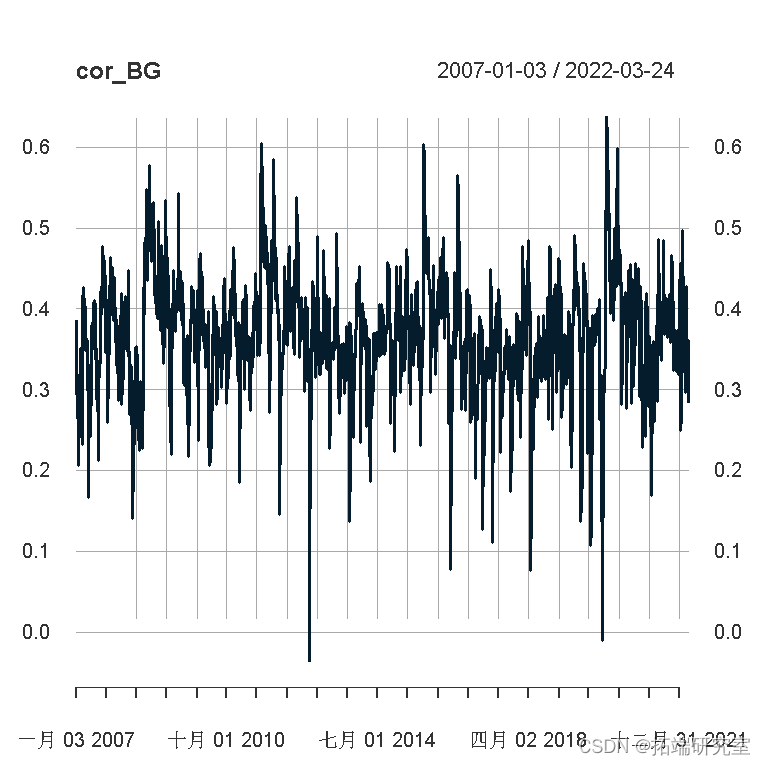
如您所见,随着时间的推移存在显着变化,相关性通常在 0.2 和 0.5 之间变化。
让我们绘制三种资产之间的所有三种相关性。
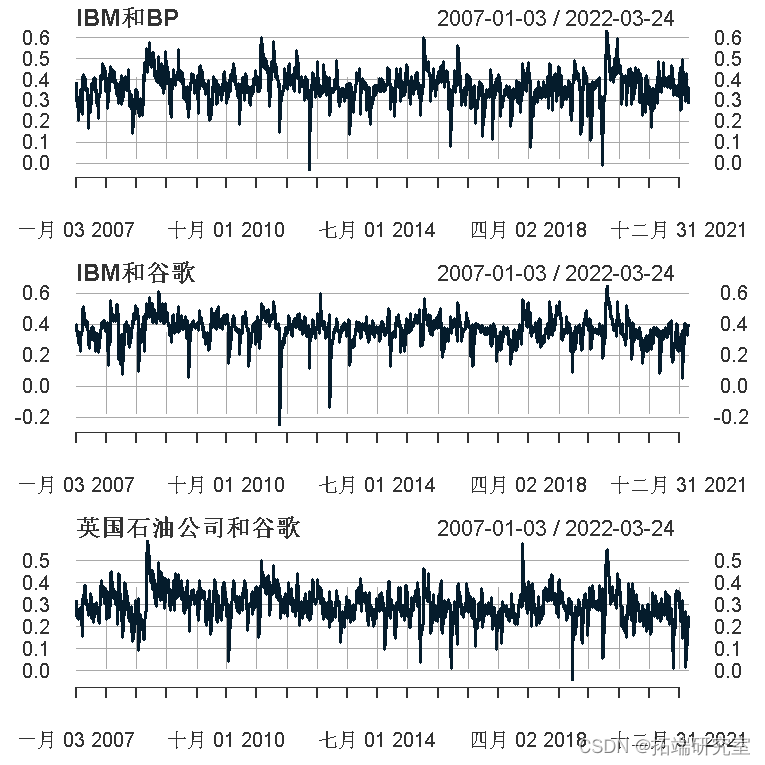
预测
通常您会希望使用您的估计模型来生成协方差或相关矩阵的预测
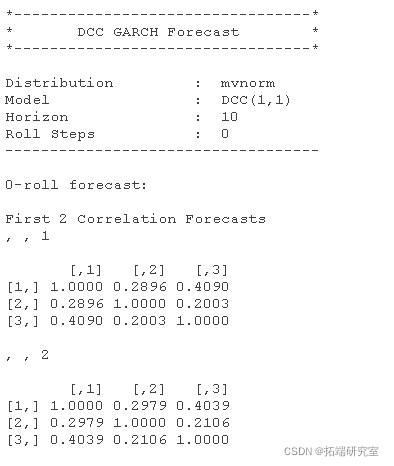
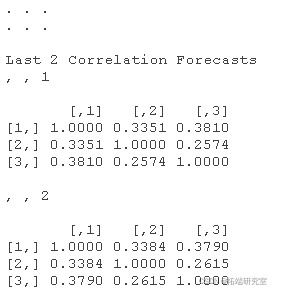
相关性的实际预测可以通过
mforecast$R # 用H来预测协方差
检查结构时 Rf

您意识到该对象 Rf 是一个包含一个元素的列表。事实证明,这个列表项是一个 3 维矩阵/数组,其中包含 3×3 相关矩阵的 10 个预测。例如,如果我们想提取 IBM(第一项资产)和 BP(第二项资产)之间相关性的 10 个预测,我们必须按以下方式进行:
Rf\[\[1\]\]\[1,2,\] # IBM和BP之间的相关预测值 Rf\[\[1\]\]\[1,3,\] # IBM和谷歌之间的相关预测 Rf\[\[1\]\]\[2,3,\] # BP和Google之间的相关性预测
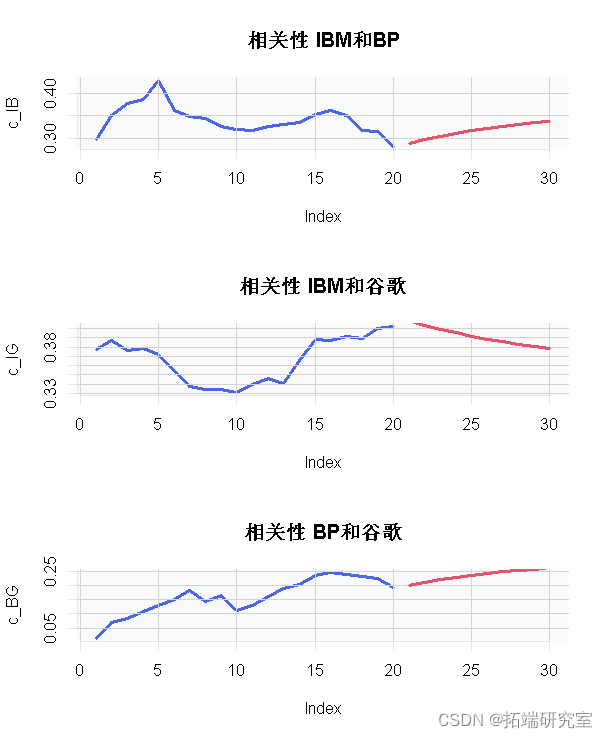
至于单变量波动性模型,让我们将预测与相关性的最后样本内估计一起显示。
# 这将创建一个有3个窗口的框架,由图画来填充 c(tail(cor1\[1,2,\],20),rep(NA,10)) # 得到最后20个相关观测值 c(rep(NA,20),corf_IB) # 得到10个预测值 plot c(tail(cor1\[1,3,\],20),rep(NA,10)) # 得到最后20个相关观测值 c(rep(NA,20),corf_IG) # 得到10个预测值 c(tail(cor1\[2,3,\],20),rep(NA,10)) # 获得最后20个相关观测值 c(rep(NA,20),corf_BG) # 得到10个预测值
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

