
当我们要可视化事故数量时,其想法是根据部门的人员进行标准化。
我们将从恢复底图开始
可下载资源
library(rgdal)
library(sp)
library(data.table)
library(dplyr)
library(plyr)
destfile="GEOFLA.tar.gz")
untar("GEOFLA.tar.gz")这些数据包含人口。所以我们要按部门汇总
dep@data <- inner_join(dep@data, pop)
dep@data <- inner_join(dep@data, superficie)
dep@data$POPULATION <- dep@data$POPULATION * 1000然后我们将恢复道路事故数据
acc_caract$dep[which(acc_caract$dep %in% "201")] <- "2A0"
acc_caract$dep[which(acc_caract$dep %in% "202")] <- "2B0"
acc_caract$dep <- substr(acc_caract$dep, 1, 2)现在,我们可以按年份、按部门(或按时间汇总)进行计数
data_plot <- c(
"2010_2015" = dep_with_nb_acc(acc_caract, dep,nb_an = 6),
"2010_2015_n" = dep_with_nb_acc(acc_caract, dep,nb_an = 6,normalize=TRUE))第一个是超过6年的事故数量,已按人群归一化(可以将其视为人身伤害的频率)
zmax = max(data_plot[[1]]@data$freq_par_hab)
spplot(obj = data_plot$'2010_2015',"freq_par_hab",at = seq(0, zmax, by = zmax/10),main = "")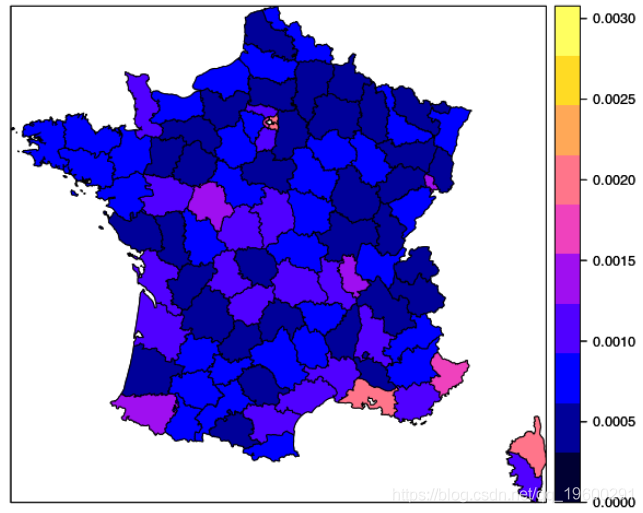
我们也可以按频率进行标准化,以找出最危险的部门。我们还采用了对数。
zmin = min(data_plot[[8]]@data$freq_par_hab)
zmax = max(data_plot[[8]]@data$freq_par_hab)
spplot(obj = data_plot$'2010_2015_n',"freq_par_hab",at = seq(zmin, zmax, by = (zmax-zmin)/10),main = "")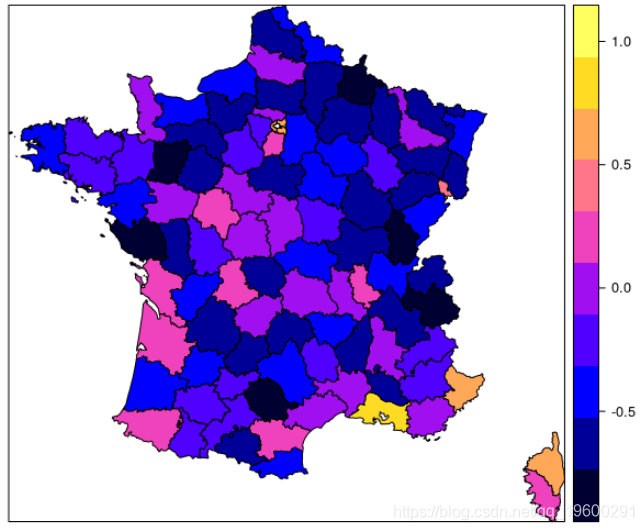
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据



