
对于某企业新用户,会利用大数据来分析该用户的信息来确定是否为付费用户,弄清楚用户属性,从而针对性的进行营销,提高运营人员的办事效率。
对于付费用户预测,主要是思考付费由哪些因素推动,再对每个因素做预测,最后得出付费预测。这其实不是一个财务问题,是一个业务问题。
可下载资源
流失预测。这方面会偏向于大额付费用户,提取额特征向量运用到应用场景的用户流失和预测里面去。
一、准确率
定义:预测正确的结果占总样本的百分比
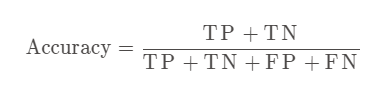
1、几类样本
(1)正样本:在二分类问题中,目标样本是正样本。如在人脸识别问题中,人脸样本就是正样本。
(2)负样本:非目标样本为负样本。如除了人脸样本之外的如窗户、门的样本就是负样本。
-
真正例(True Positive,TP):被模型预测为正的正样本
-
假正例(False Positive,FP):被模型预测为正的负样本
-
假负例(False Negative,FN):被模型预测为负的正样本
-
真负例(True Negative,TN):被模型预测为负的负样本
2、准确率的缺点
在数据的类别不均衡,特别是有极偏的数据存在时,准确率不能客观评价算法的优劣。如100个预测样本,99个反例,仅1个正例。
二、精确率和召回率
1、精确率
又叫查准率,针对预测结果而言。定义:在所有被预测为正的样本中实际为正的样本的概率。
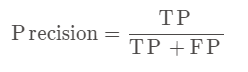
表示对正样本的预测准确程度。
2、召回率
又叫查全率,针对原样本而言。定义:在实际为正的样本中被预测为正样本的概率。
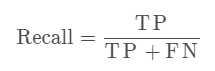
3、两者的关系
相对关系,此消彼长。在不同问题中,关注点不同,需要结合两个指标,寻找平衡点。
三、F1-Score
F1值是P和R值的加权调和平均,是兼顾精准率和召回率的指标。当F1较高时,模型性能越好。

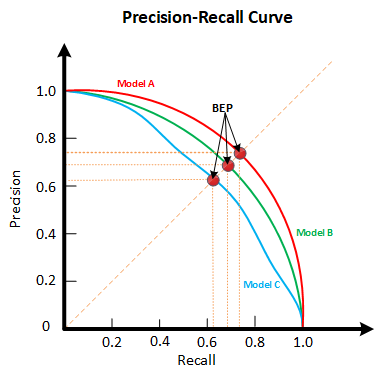
四、P-R曲线
含义:用以描述精确率和召回率的变化。
定义:根据预测结果(一般为实值或概率),按测试样本为“正例”的可能性由高到低进行排序,每次计算出当前的P值和R值,绘图得到P-R曲线。
评估模型性能的方式
-
若某一学习器A曲线被另一学习器B的P-R曲线完全包住,则称B的性能优于A。
-
若A和B的曲线发生交叉,则曲线下面积大的性能更优。
-
一般而言,曲线下面积难以估算,根据平衡点(BEP,P=R时的取值),平衡点的取值越高,性能越优。
五、ROC曲线
1、性能指标
灵敏度(sensitivity)和特异度(specificity)的选择使得ROC可以无视样本的不平衡。
真正率 (True Positive Rate , TPR),又称灵敏度,表示正样本的召回率:

真负率 (True Negative Rate , TNR),又称特异度,表示负样本的召回率:

假负率 (False Negative Rate , FNR),FNR=1-TPR:

假正率 (False Positive Rate , FPR),FPR=1-TNR:

假设总样本中,90%是正样本,10%是负样本。由于TPR只关注90%正样本中有多少是被预测正确的,与10%负样本无关,同理FPR只关注10%负样本中有多少是被预测错误的,也与90%正样本无关。这样就避免了样本不平衡的问题。
2、ROC曲线概念
ROC又称接受者操作特征曲线,ROC曲线以假正率FPR为横坐标,真正率TPR为纵坐标。
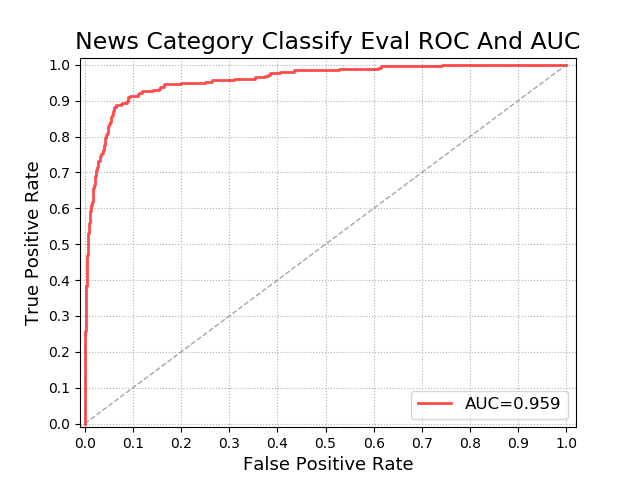
评估模型性能的方式
-
负样本误判的越少越好,正样本召回的越多越好。即TPR 越高,同时 FPR 越低(即 ROC 曲线越陡),那么模型的性能就越好。
-
若一个模型A的ROC曲线被另一个模型B的ROC曲线完全包住,则称B的性能优于 A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。
3、优点
1)阈值问题
ROC 曲线通过遍历所有阈值来绘制整条曲线,在遍历阈值的过程中,预测的正样本和负样本不断变化,在ROC曲线中会沿着曲线滑动。改变阈值仅改变正负样本数,曲线本身不变。
2)无视样本不平衡
当测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变,消除样本不平衡对指标结果产生的影响。
4、AUC
又称曲线下面积,表示处于ROC曲线下方的面积大小。AUC越大,模型分类效果越好,通常AUC值介于0.5到1之间。
物理意义:AUC 值是一个概率值,表示随机挑选一个正样本以及一个负样本,分类器判定正样本分值高于负样本分值的概率就是 AUC 值。
六、混淆矩阵
定义:每一列表示样本的预测分类,每一行是样本的真实分类(反过来也可以),反映了分类结果的混淆程度。以二分类为例,下图表示分类结果的混淆矩阵。
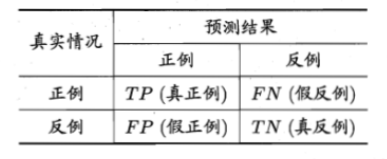
七、多分类场景
1、问题场景
多分类场景或二分类问题中,多个混淆矩阵的情况。
2、计算方法(以计算F1值为例)
1)宏平均
先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,再算出F1值。
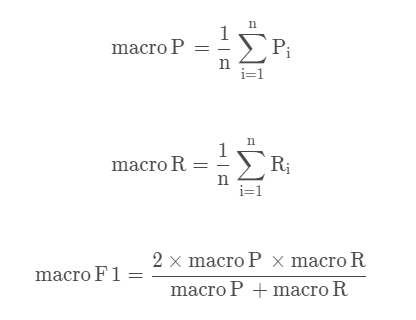
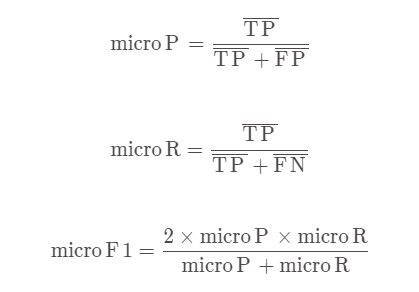
2)微平均
计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出F1值。
3、区别
多分类问题中,宏平均的值主要受稀有类别的影响,平等对待每一个类别。微平均的值受到常见类别的影响比较大,平等考虑数据集中的每一个样本。整体而言,宏平均优于微平均。
方法
回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
问题描述
我们尝试并预测用户是否可以根据数据中可用的人口信息变量使用逻辑回归预测月度付费是否超过 50K。
在这个过程中,我们将:
1.导入数据
2.检查类别偏差
3.创建训练和测试样本
4.建立logit模型并预测测试数据
5.模型诊断
检查类偏差
理想情况下,Y变量中事件和非事件的比例大致相同。 所以,我们首先检查因变量ABOVE 50K中的类的比例。
0 1
24720 7841显然,不同付费人群比例 有偏差 。 所以我们必须以大致相等的比例对观测值进行抽样,以获得更好的模型。
构建Logit模型和预测
确定模型的最优预测概率截止值,默认的截止预测概率分数为0.5或训练数据中1和0的比值。 但有时,调整概率截止值可以提高开发和验证样本的准确性。InformationValue :: optimalCutoff功能提供了找到最佳截止值,减少错误分类错误。
optCutOff <- optimalCutoff(testData$ABOVE50K, predicted)[1]
=> 0.71模型诊断
分类错误
错误分类错误是预测与实际的不匹配百分比 。 错误分类错误越低, 模型越好。
misClassError(testData$ABOVE50K, predicted, threshold = optCutOff)
[1] 0.0892ROC曲线
ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
上述模型的ROC曲线面积为89%,相当不错。
一致性
简单来说,在1-0 的所有组合中,一致性是预测对的百分比 ,一致性越高,模型的质量越好。
$Concordance
[1] 0.8915107
$Discordance
[1] 0.1084893
$Tied
[1] -2.775558e-17
$Pairs
[1] 45252896上述型号的89.2%的一致性确实是一个很好的模型。
混淆矩阵
在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
confusionMatrix(testData$ABOVE50K, predicted, threshold = optCutOff)
0 1
0 18849 1543
1 383 810结论
这里仅仅介绍了模型的建立和评估。通过模型的结论,我们可以得到一些已经为公众所接受和熟知的现象是:付费和受教育程度、智力、年龄以及性别等相关。 基于此用户规模预测模型,结合用户的人口信息,即可粗略预估产品在一般情况下的收入情况, 从而判断就得到了付费用户预测模型,如果把收入分类转换成流失用户和有效用户,就得到了流失用户预测模型。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据

