案例数据集是在线零售业务的交易数据,采用Python为编程语言,采用Hadoop存储数据,采用Spark对数据进行处理分析,并使用Echarts做数据可视化。
由于案例公司商业模式类似新零售,或者说有向此方向发展利好的趋势,所以本次基于利于公司经营与发展的方向进行数据分析。
用大数据对产品的开发、生产、销售、流通等进行效能升级,优化整合线上线下资源,全方位提升用户体验的零售模式,这就是新零售。
这不仅与广告系列有关。可以使用Hadoop构建大量应用程序,从分析客户到分析品牌,下面将详细介绍其中五个最常见的应用程序。
1.全面了解客户
零售商与客户互动的方式有很多(社交媒体,商店新闻通讯,店内等),但是如果没有Hadoop,客户的行为几乎是完全无法预测的。 Hadoop能够存储和关联交易数据和在线浏览行为,从而使企业能够确定客户生命周期的各个阶段,从而更好地提高销售额,减少库存支出并建立忠实的客户群。
2.衡量品牌情绪
内部品牌研究可能缓慢,昂贵且存在缺陷。借助Hadoop,公司可以在产品发布,广告,竞争对手动作,新闻报道甚至店内体验的影响下,公正地了解客户对品牌的看法。
Hadoop扫描社交媒体(如Facebook,Twitter或LinkedIn),浏览器搜索和其他行业特定的社交媒体中的相关关键字,以提供客户满意度和品牌认知度的实时快照。通过更好地理解一般客户的意见,零售商可以调整其消费者范围,产品和促销活动。
3.本地化和个性化促销
Hadoop是一个改变游戏规则的平台,可以结合历史存储和实时流数据,使零售商能够本地化和个性化促销活动。拥有移动应用程序的零售商可以根据地理位置向应用程序用户发送个性化的推送通知,以便向商店附近的顾客通知将吸引他们的促销或特定产品。访问在线搜索历史和地理位置也有助于在客户的社交媒体页面的提要中推广广告。
4.优化网站
点击流数据是大数据营销的重要组成部分:它告诉零售商哪些客户单击并购买(或不购买)。但是,用于查看和分析其他数据库上的洞察力的存储成本很高,或者它们只是没有能力处理所有数据。 Apache Hadoop能够存储多年的所有Web日志和数据,并且价格低廉,从而使零售商能够了解用户路径,进行购物篮分析,运行A / B测试并确定站点更新的优先级,从而提高了客户转化率和收入。
5.重新设计商店布局
对于零售商而言,最难分析的是客户的店内体验,因为没有数据可用于他们的结帐前行为。但是,众所周知的事实是,商店的布局对产品的销售有重大影响,因此已经开发出传感器(例如RFID标签和QR码)来帮助填补数据空白。他们通过Hadoop存储了大量信息,这些信息经过分析,可以帮助零售商优化商店布局并改善店内体验,同时降低成本。
1、新零售不仅仅是销售。
除了营销层面,新零售几乎涉及了产品的研发、设计、生产、品控、调度、包装、物流、品牌、服务、体验等各个环节。
所以绝对不能把新零售仅仅定义在营销和销售的层面上,不仅仅是卖东西,除了卖东西,涉及到了企业经营的几乎所有方面,其最终目的是对内提升企业效能,对外增强客户体验。
2、新零售的核心是用户体验。
不管是线下还是线上,不管什么形式,什么业态,不管是不是电子商务,只要不能在“多快好省”4个方面提升消费者的用户体验,那就不是新零售,就是伪新零售。
新零售会围绕“选择更多、配送更快、质量更好、价格更省”4个维度来提升用户体验,盒马鲜生为什么火,因为现场买完就下锅明显满足了后面3个“更快 更好 更省”;便利蜂、无人售货机等新零售为什么快速扩张?更快。
3、数据驱动。
比如,今年双十一,平台上的大数据会根据你在双十一前放到购物筐里但没下单的商品,凭借你在平台上的购物习惯和频次,判断你在双十一期间下单的数量和商品类别,然后提前发货到离你家最近的仓储点。未来随着无人机等工具的发展,有可能你刚下完单,11楼窗口无人机就会载着货敲你家窗户。另外大数据还可以根据用户的下单数据确定产品的颜色、样式,分析出最可能热卖的产品,直接主导研发过程。

Enno
二、案例与需求分析
采用Python为编程语言,采用Hadoop存储数据,采用Spark对数据进行处理分析,并使用Echarts做数据可视化。由于案例公司商业模式类似新零售,或者说有向此方向发展利好的趋势,所以本次基于利于公司经营与发展的方向进行数据分析。
工作流程如下:
1、环境搭建:本次作业使用的环境和软件如下:
(1)Linux操作系统:Ubuntu 18.04
(2)Python:3.5.2
(3)Hadoop:3.1.3
(4)Spark:2.4.0
(5)Bottle:v0.12.18
2、数据预处理:进行数据清洗,过滤掉有缺失值的记录
3、数据处理:
(1)筛选出10个客户数最多的国家
(2)筛选出10个销量最高的国家
(3)统计各个国家的总销售额分布情况
(4)统计销量最高的10个商品
(5)统计商品描述的热门关Top300
(6)统计退货订单数最多的10个国家
(7)统计月销售额随时间的变化趋势
(8)统计日销量随时间的变化趋势
(9)统计各国的购买订单量和退货订单量的关系
(10)统计商品的平均单价与销量的关系

sudo apt-get install python3-pippip3 install bottle此外,我还安装了jupyter notebook,个人觉得比较方便快捷。
2、数据预处理:
数据集时间跨度为2010-12-01到2011-12-09,每个记录由8个属性组成,具体的含义如下表:
随时关注您喜欢的主题

首先,将数据集上传至hdfs上,命令如下:
接着,使用如下命令进入pyspark的交互式编程环境,对数据进行初步探索和清洗:
(1)读取在HDFS上的文件,以csv的格式读取,得到DataFrame对象。

(2)查看数据集的大小,输出541909,不包含标题行。

(3)打印数据集的schema,查看字段及其类型信息。输出内容就是上文中的属性表。

(4)创建临时视图data。

(5)由于顾客编号CustomID和商品描述Description均存在部分缺失,所以进行数据清洗,过滤掉有缺失值的记录。特别地,由于CustomID为integer类型,所以该字段若为空,则在读取时被解析为0,故用df[“CustomerID”]!=0 条件过滤。
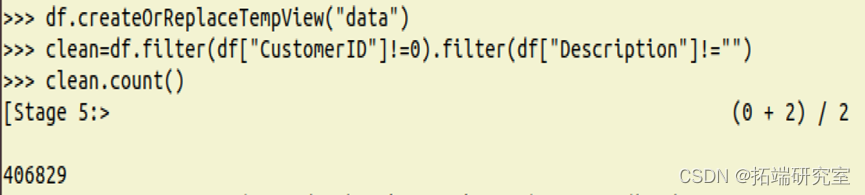
(6)查看清洗后的数据集的大小,输出406829。

(6)数据清洗结束。根据作业要求,预处理后需要将数据写入HDFS。将清洗后的文件以csv的格式,写入E_Commerce_Data_Clean.csv中(实际上这是目录名,真正的文件在该目录下,文件名类似于part-00000),需要确保HDFS中不存在这个目录,否则写入时会报“already exists”错误。

至此,数据预处理完成。接下来将使用python编写应用程序,对清洗后的数据集进行统计分析。
3、数据处理
首先,导入需要用到的python模块。

接着,获取spark sql的上下文。

最后,从HDFS中以csv的格式读取清洗后的数据目录E_Commerce_Data_Clean.csv,程序会取出该目录下的所有数据文件,得到DataFrame对象,并创建临时视图data用于后续分析。

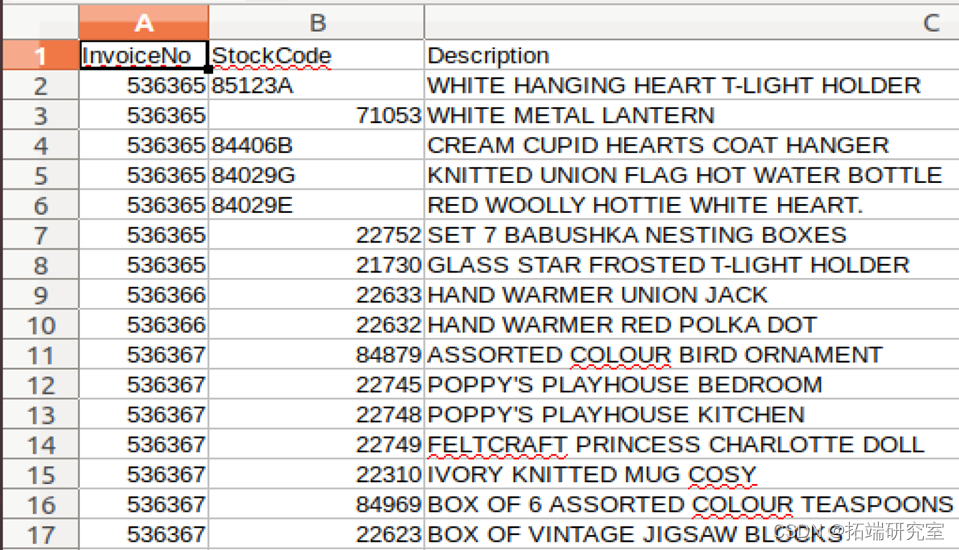
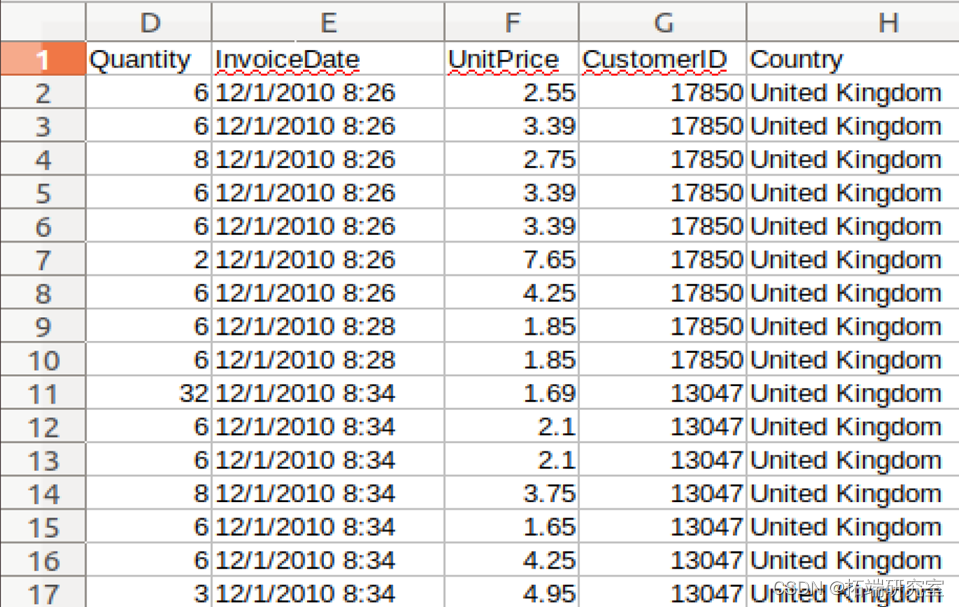
清洗过后的部分数据展示:

想了解更多关于模型定制、咨询辅导的信息?
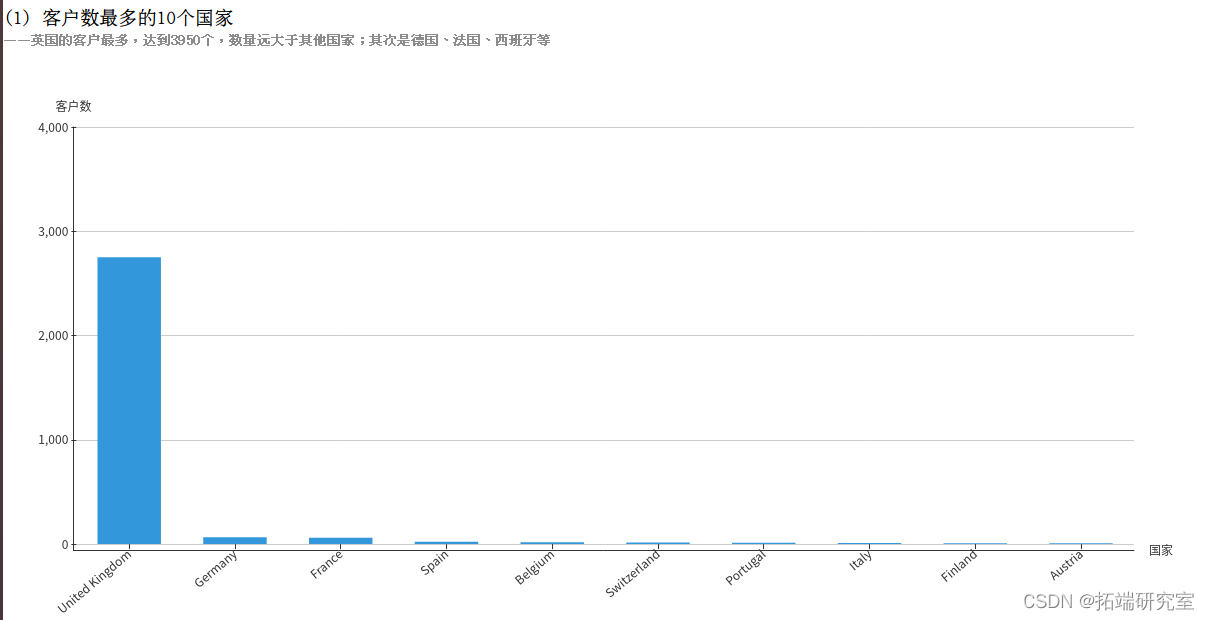
(1)筛选出10个客户数最多的国家
每个客户由编号CustomerID唯一标识,所以客户的数量为COUNT(DISTINCT CustomerID),再按照国家Country分组统计,根据客户数降序排序,筛选出10个客户数最多的国家。得到的countryCustomerDF为DataFrame类型,执行collect()方法即可将结果以数组的格式返回。

最后调用save方法就可以将结果导出至文件了,结果如下:
(2)筛选出10个销量最高的国家
Quantity字段表示销量,因为退货的记录中此字段为负数,所以使用SUM(Quantity)即可统计出总销量,即使有退货的情况。再按照国家Country分组统计,根据销量降序排序,筛选出10个销量最高的国家。得到的countryQuantityDF为DataFrame类型,执行collect()方法即可将结果以数组的格式返回。


(3)各个国家的总销售额分布情况
UnitPrice 字段表示单价,Quantity字段表示销量,退货的记录中Quantity字段为负数,所以使用SUM(UnitPrice*Quantity)即可统计出总销售额,即使有退货的情况。再按照国家Country分组统计,计算出各个国家的总销售额。得到的countrySumOfPriceDF为DataFrame类型,执行collect()方法即可将结果以数组的格式返回。


(4)销量最高的10个商品
Quantity字段表示销量,退货的记录中Quantity字段为负数,所以使用SUM(Quantity)即可统计出总销量,即使有退货的情况。再按照商品编码StockCode分组统计,计算出各个商品的销量。得到的stockQuantityDF为DataFrame类型,执行collect()方法即可将结果以数组的格式返回。


(5)商品描述的热门关Top300
Description字段表示商品描述,由若干个单词组成,使用LOWER(Description)将单词统一转换为小写。此时的结果为DataFrame类型,转化为rdd后进行词频统计,再根据单词出现的次数进行降序排序,流程图如下:
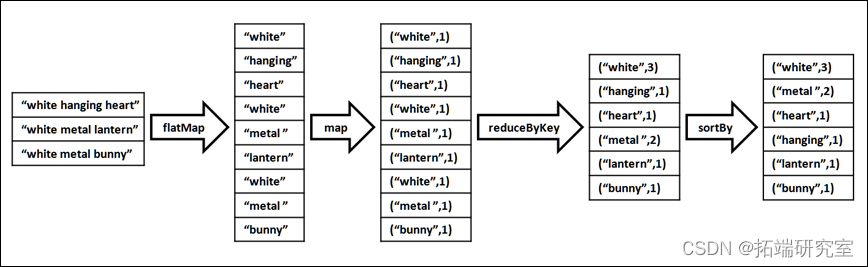
得到的结果为RDD类型,为其制作表头wordCountSchema,包含word和count属性,分别为string类型和integer类型。调用createDataFrame()方法将其转换为DataFrame类型的wordCountDF,将word为空字符串的记录剔除掉,调用take()方法得到出现次数最多的300个关键词,以数组的格式返回。


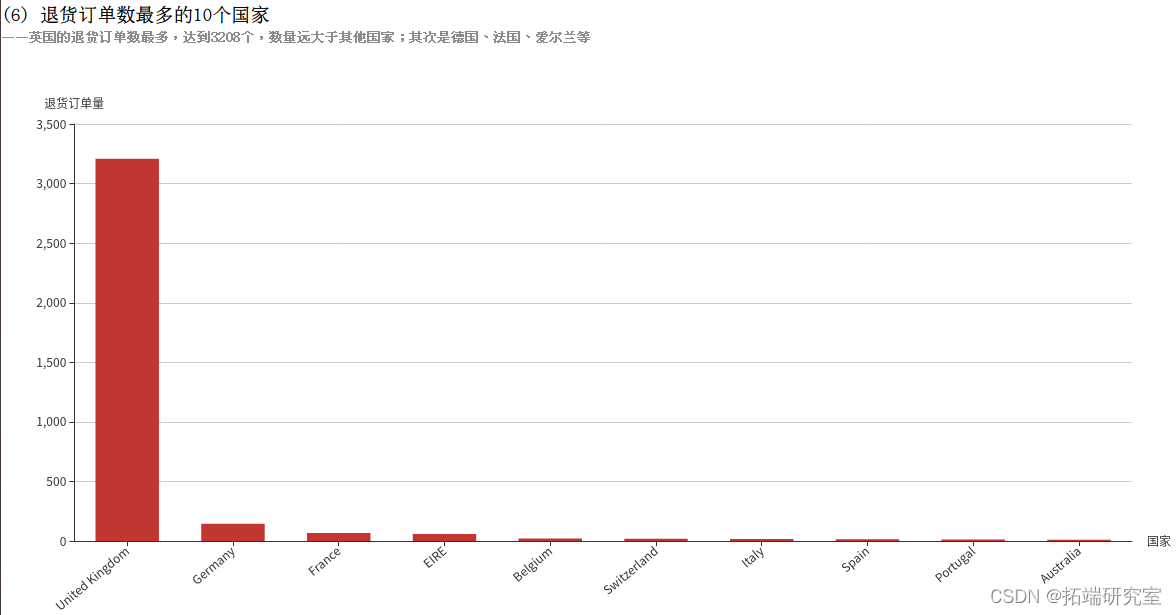
(6)退货订单数最多的10个国家
InvoiceNo字段表示订单编号,所以订单总数为COUNT(DISTINCT InvoiceNo),由于退货订单的编号的首个字母为C,例如C540250,所以利用WHERE InvoiceNo LIKE ‘C%’子句即可筛选出退货的订单,再按照国家Country分组统计,根据退货订单数降序排序,筛选出10个退货订单数最多的国家。得到的countryReturnInvoiceDF为DataFrame类型,执行collect()方法即可将结果以数组的格式返回。


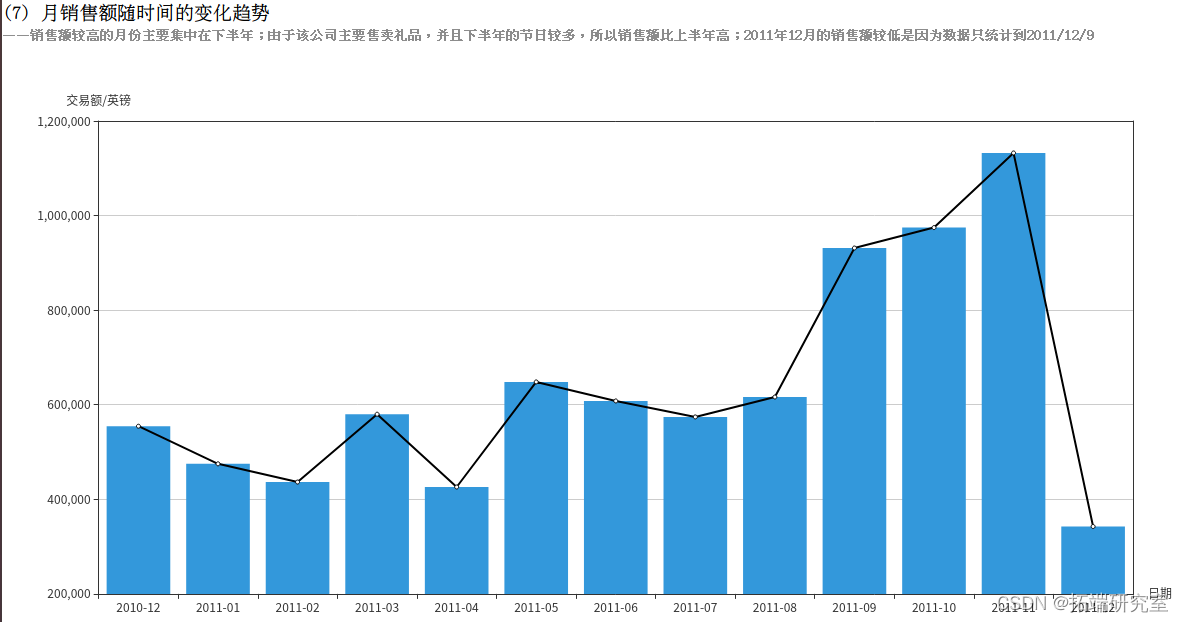
(7)月销售额随时间的变化趋势
统计月销售额需要3个字段的信息,分别为订单日期InvoiceDate,销量Quantity和单价UnitPrice。由于InvoiceDate字段格式不容易处理,例如“8/5/2011 16:19”,所以需要对这个字段进行格式化操作。由于统计不涉及小时和分钟数,所以只截取年月日部分,并且当数值小于10时补前置0来统一格式,期望得到年、月、日3个独立字段。先实现formatData()方法,利用rdd对日期、销量和单价字段进行处理。
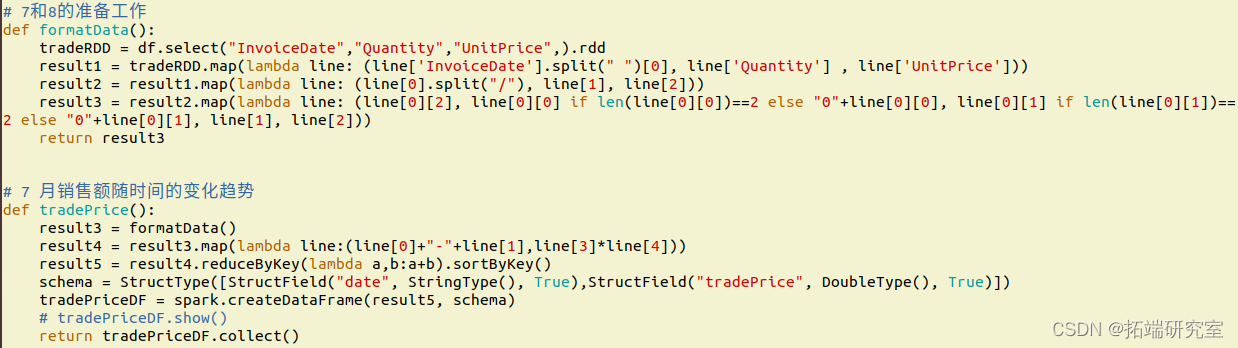
流程图如下:
由于要统计的是月销售额的变化趋势,所以只需将日期转换为“2011-08”这样的格式即可。而销售额表示为单价乘以销量,需要注意的是,退货时的销量为负数,所以对结果求和可以表示销售额。RDD的转换流程如下:
得到的结果为RDD类型,为其制作表头schema,包含date和tradePrice属性,分别为string类型和double类型。调用createDataFrame()方法将其转换为DataFrame类型的tradePriceDF,调用collect()方法将结果以数组的格式返回。

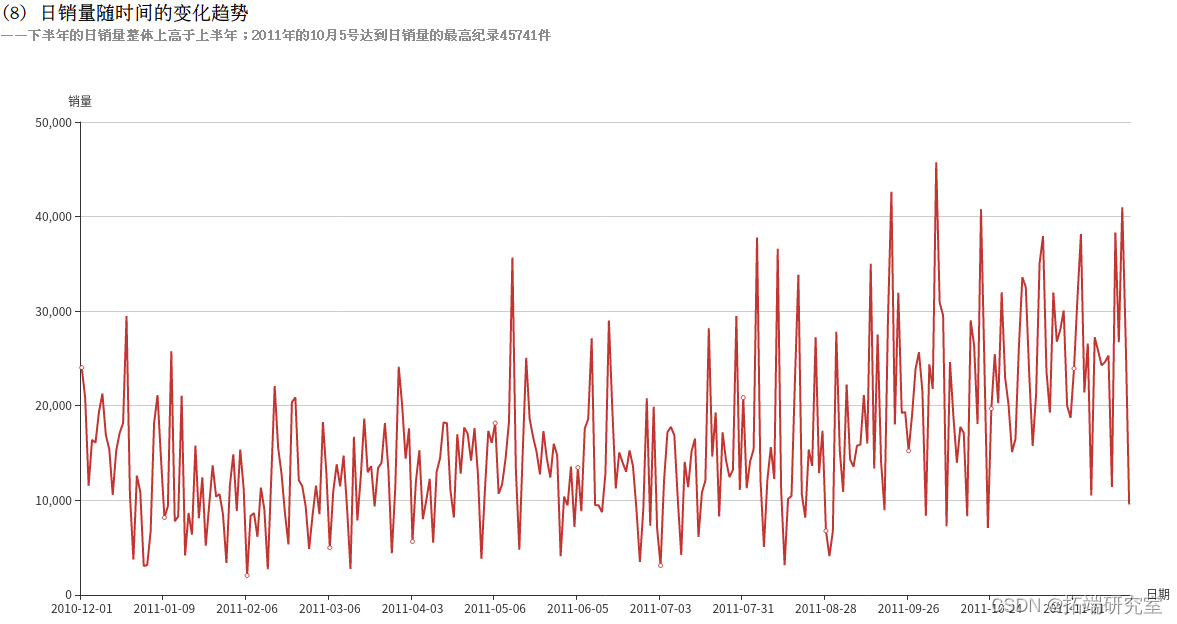
(8)日销量随时间的变化趋势
由于要统计的是日销量的变化趋势,所以只需将日期转换为“2011-08-05”这样的格式即可。先调用上例的formatData()方法对日期格式进行格式化。RDD的转换流程如下:
得到的结果为RDD类型,为其制作表头schema,包含date和saleQuantity属性,分别为string类型和integer类型。调用createDataFrame()方法将其转换为DataFrame类型的saleQuantityDF,调用collect()方法将结果以数组的格式返回。

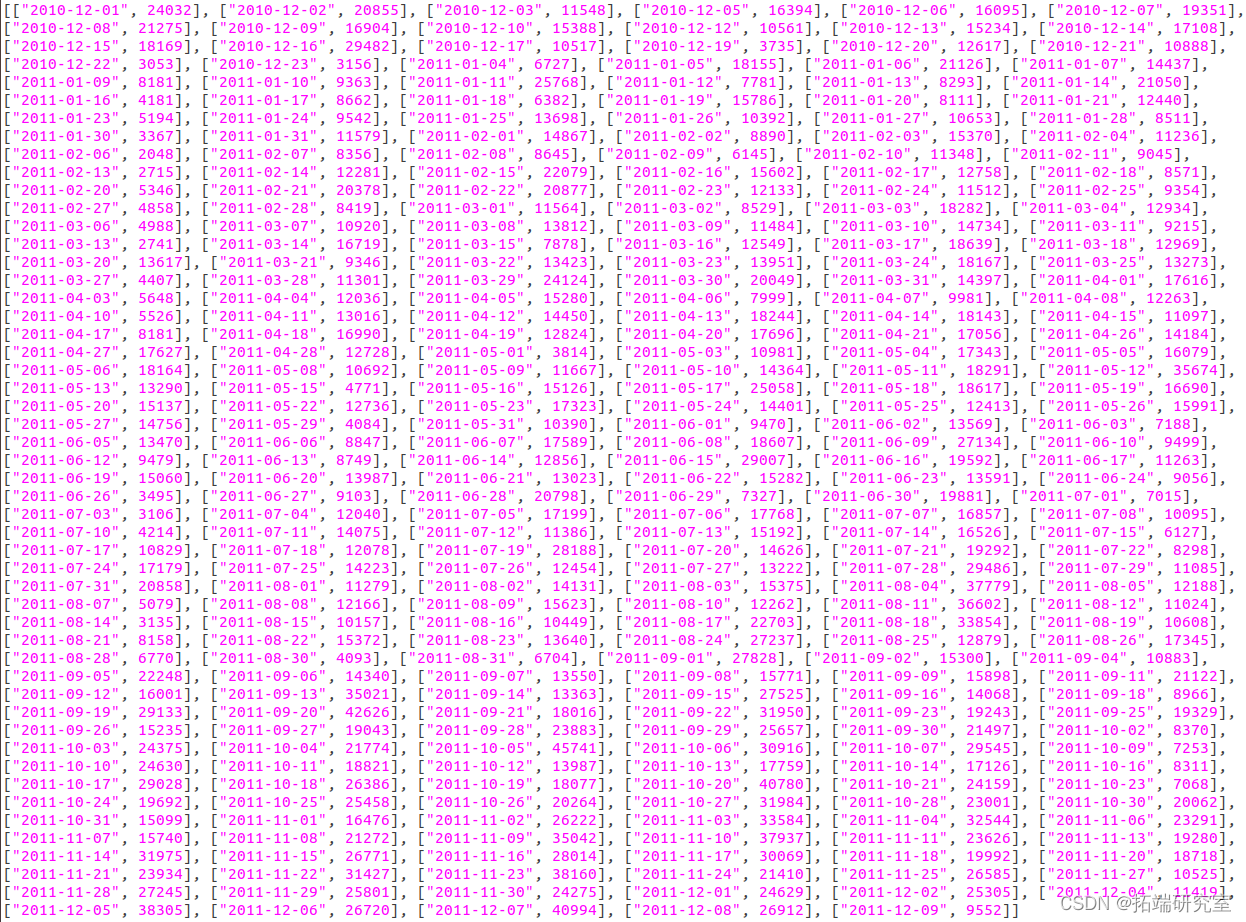
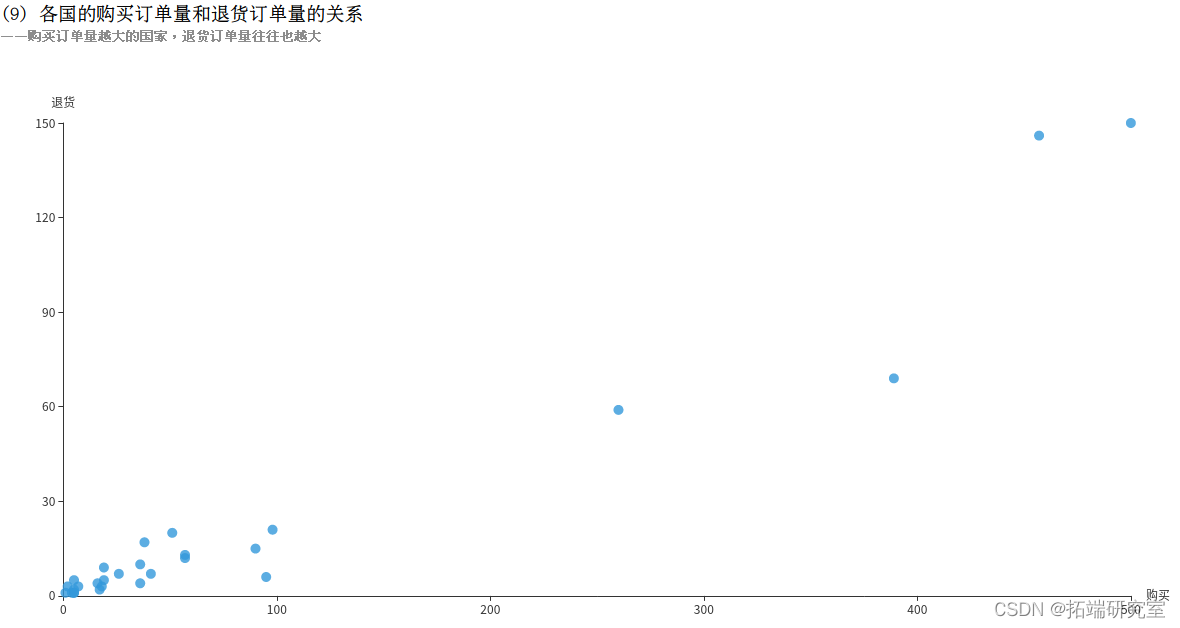
(9)各国的购买订单量和退货订单量的关系
InvoiceNo字段表示订单编号,退货订单的编号的首个字母为C,例如C540250。利用COUNT(DISTINCT InvoiceNo)子句统计订单总量,再分别用WHERE InvoiceNo LIKE ‘C%’和WHERE InvoiceNo NOT LIKE ‘C%’统计出退货订单量和购买订单量。接着按照国家Country分组统计,得到的returnDF和buyDF均为DataFrame类型,分别表示退货订单和购买订单,如下所示:
再对这两个DataFrame执行join操作,连接条件为国家Country相同,得到一个DataFrame。但是这个DataFrame中有4个属性,包含2个重复的国家Country属性和1个退货订单量和1个购买订单量,为减少冗余,对结果筛选3个字段形成buyReturnDF。如下所示:
最后执行collect()方法即可将结果以数组的格式返回。


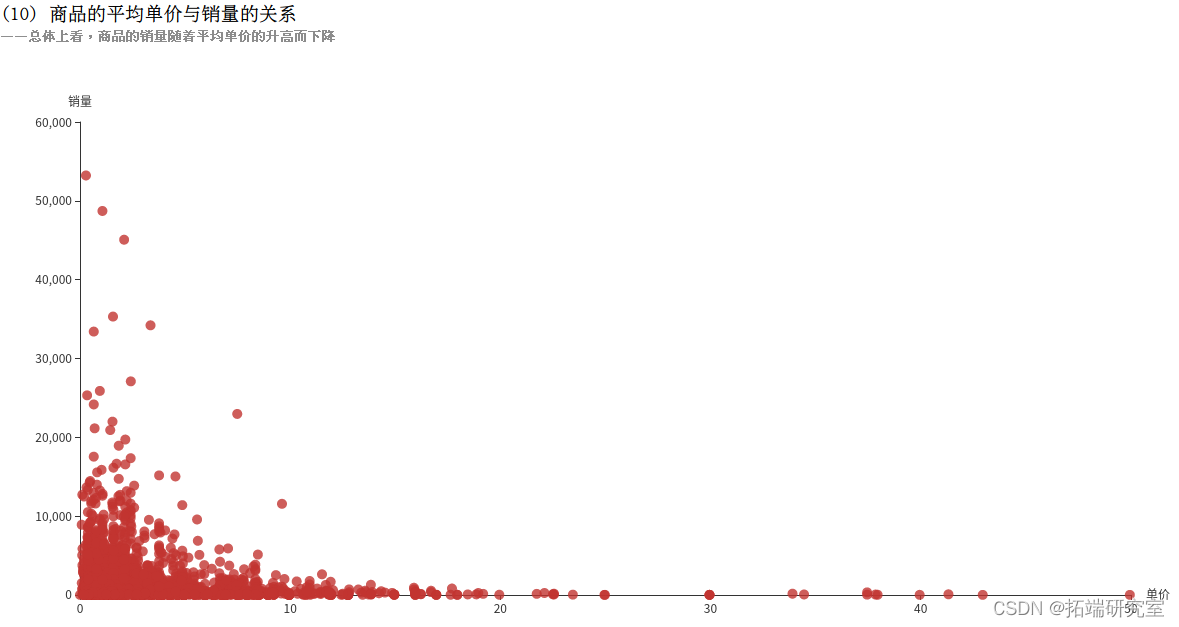
(10)商品的平均单价与销量的关系
由于商品的单价UnitPrice是不断变化的,所以使用平均单价AVG(DISTINCT UnitPrice)来衡量一个商品。再利用SUM(Quantity)计算出销量,将结果按照商品的编号进行分组统计,执行collect()方法即可将结果以数组的格式返回。

最后,将所有的函数整合在变量 m中,通过循环调用上述所有方法并导出json文件到当前路径的static目录下。


最后利用如下指令运行分析程序:

4、结果可视化
结果可视化使用百度开源的免费数据展示框架Echarts。Echarts是一个纯Javascript的图表库,可以流畅地运行在PC和移动设备上,兼容当前绝大部分浏览器,底层依赖轻量级的Canvas类库ZRender,提供直观,生动,可交互,可高度个性化定制的数据可视化图表。
编写python程序,实现一个简单的web服务器,代码如下:
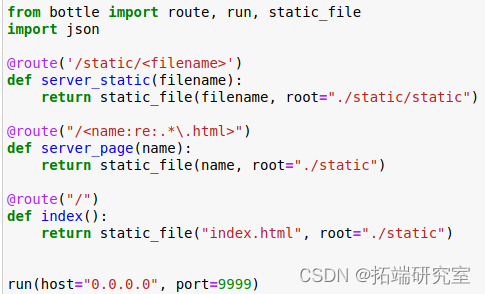
bottle服务器对接收到的请求进行路由,规则如下:
(1)访问/static/时,返回静态文件
(2)访问/.html时,返回网页文件
(3)访问/时,返回首页index.html
服务器的9999端口监听来自任意ip的请求(前提是请求方能访问到这台服务器)。
首页index.html的主要代码如下(由于篇幅较大,只截取主要的部分)
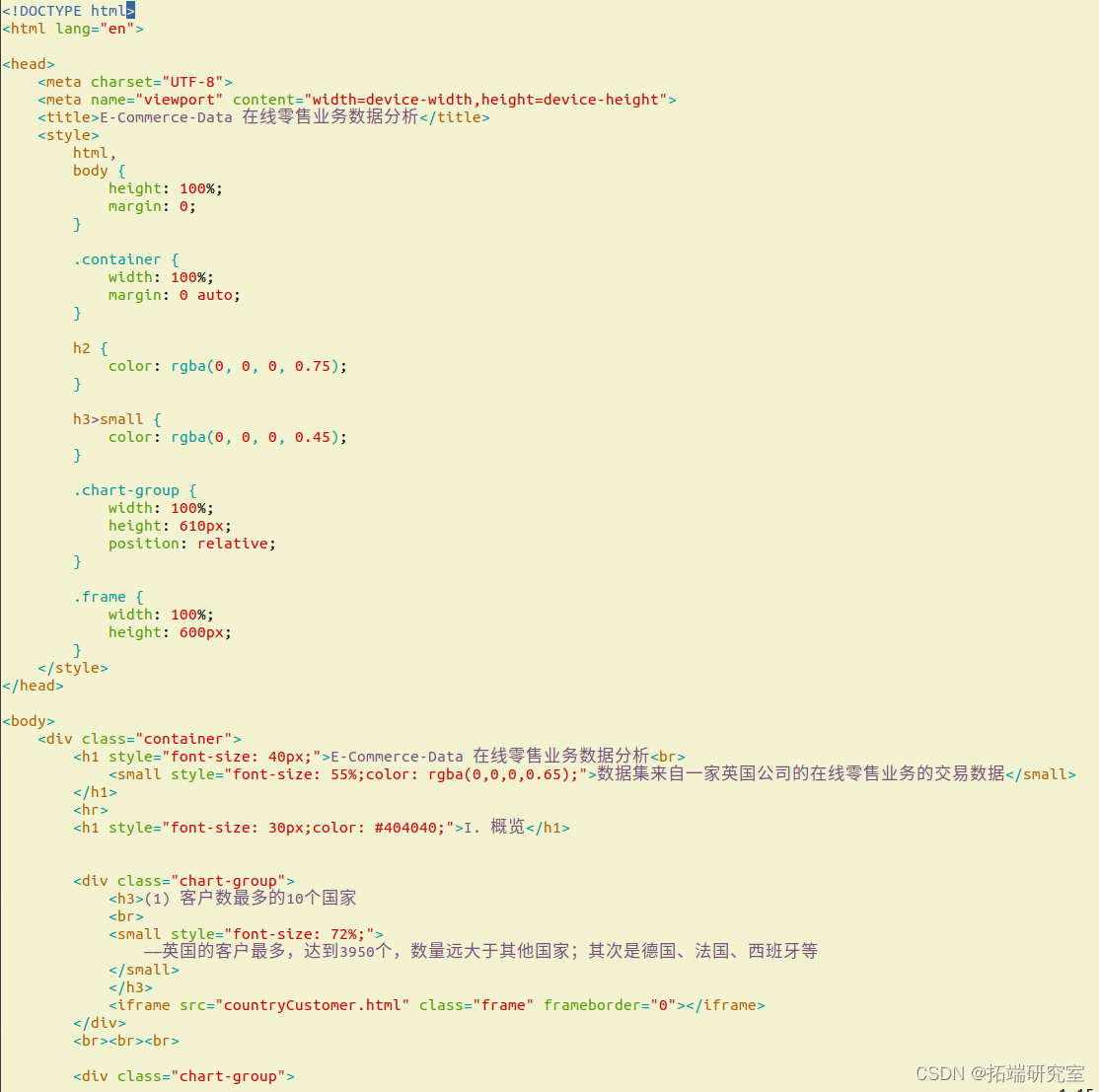
图表页通过一个iframe嵌入到首页中。以第一个统计结果的网页countryCustomer.html为例,展示主要代码:
若打印出以下信息则表示web服务启动成功。接着,可以通过使用浏览器访问网页的方式查看统计结果。

可视化结果如下:
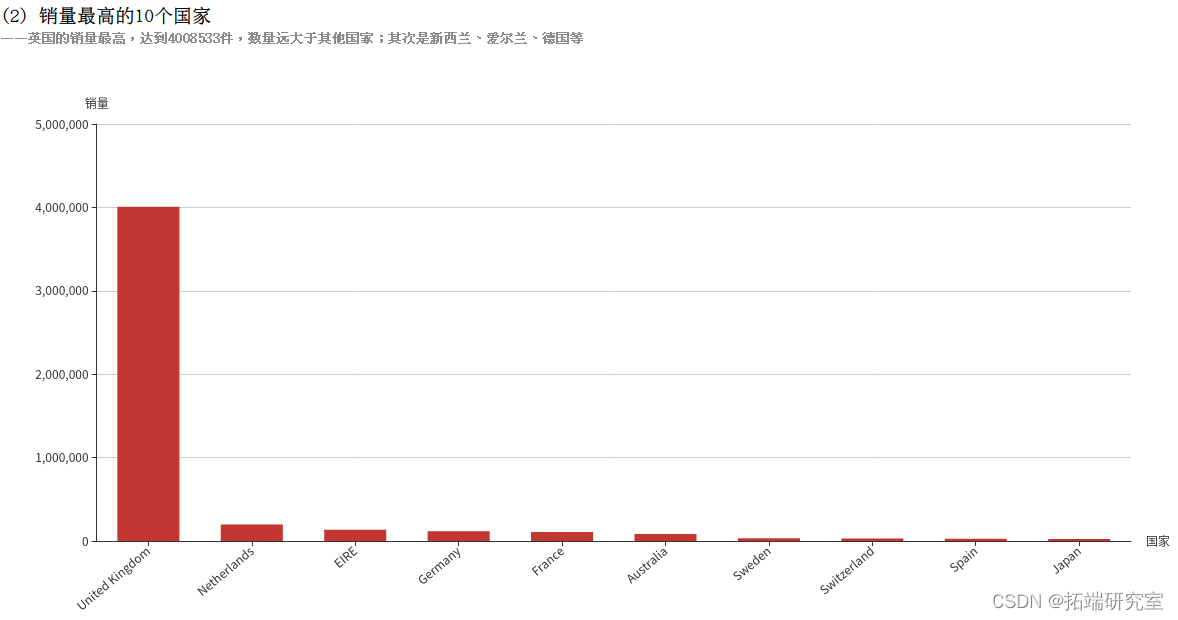
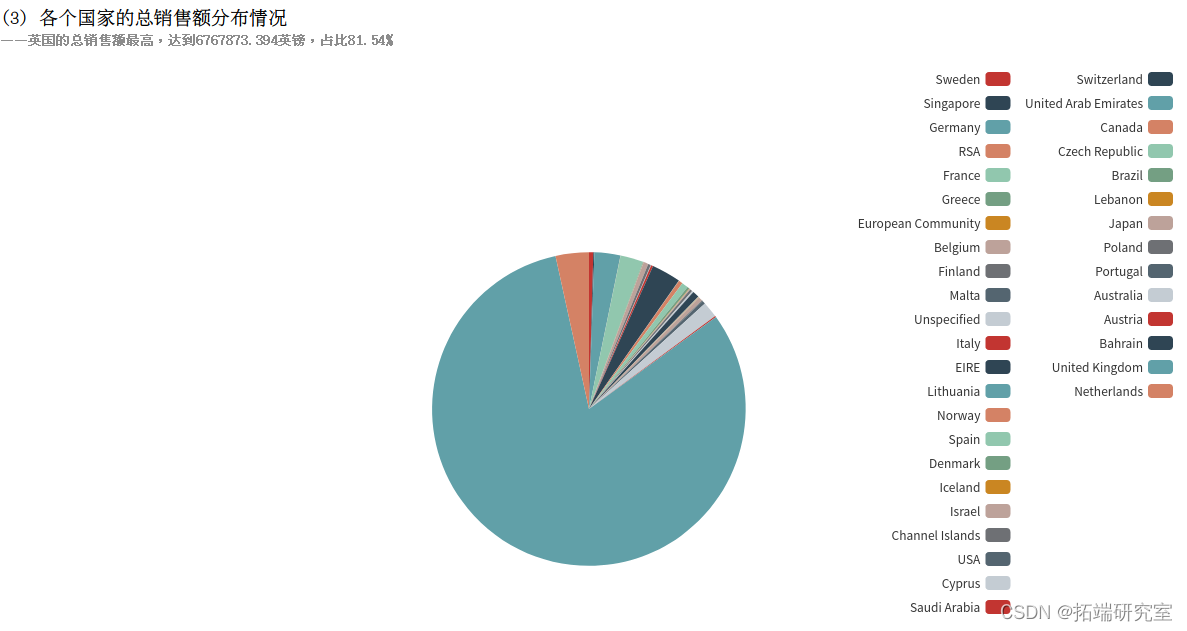
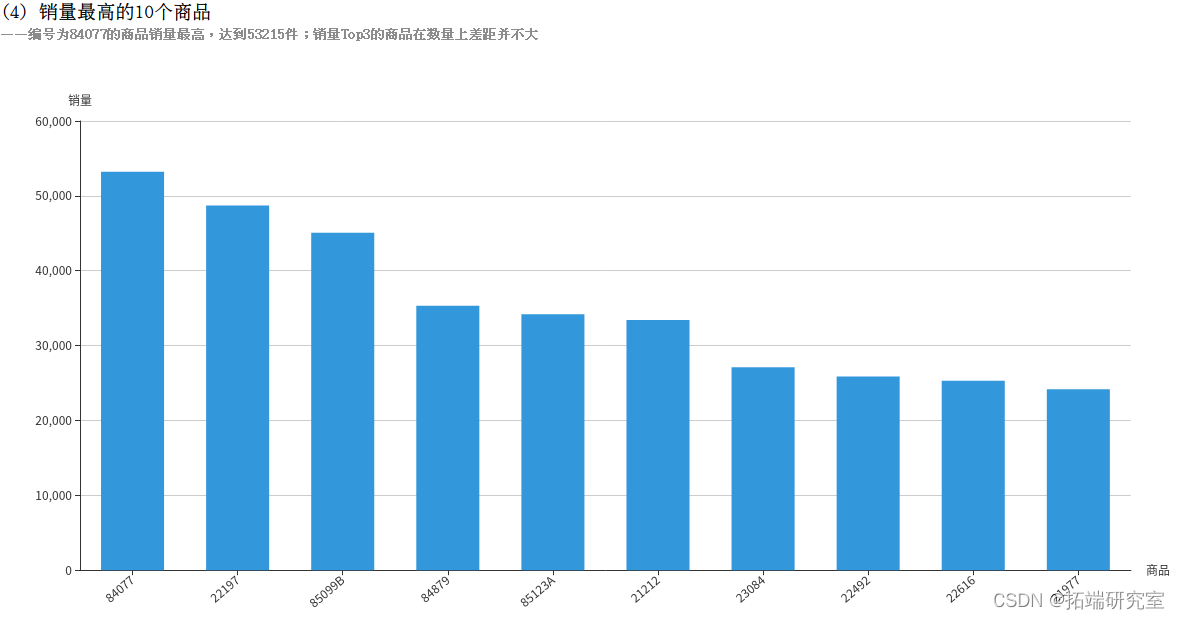
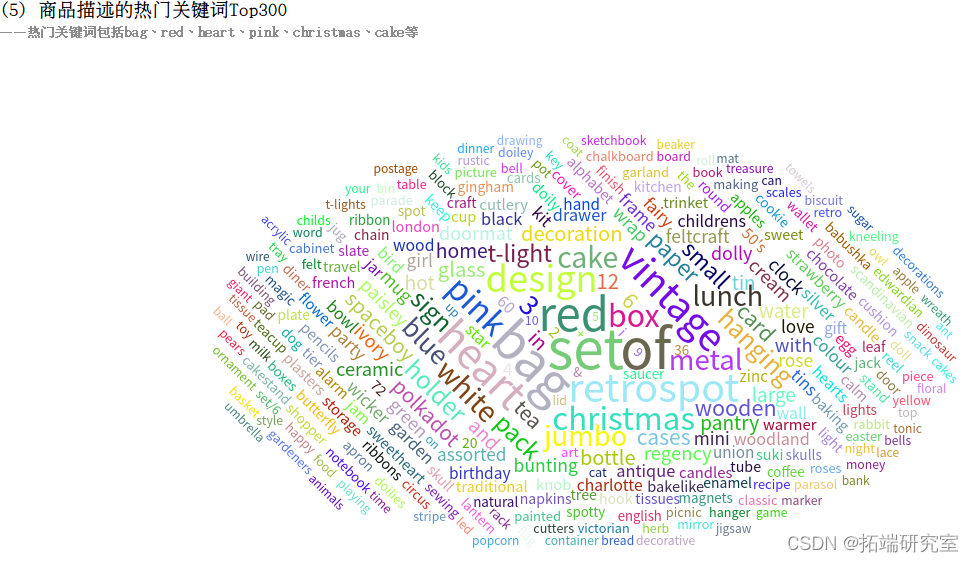
四、拓展分析
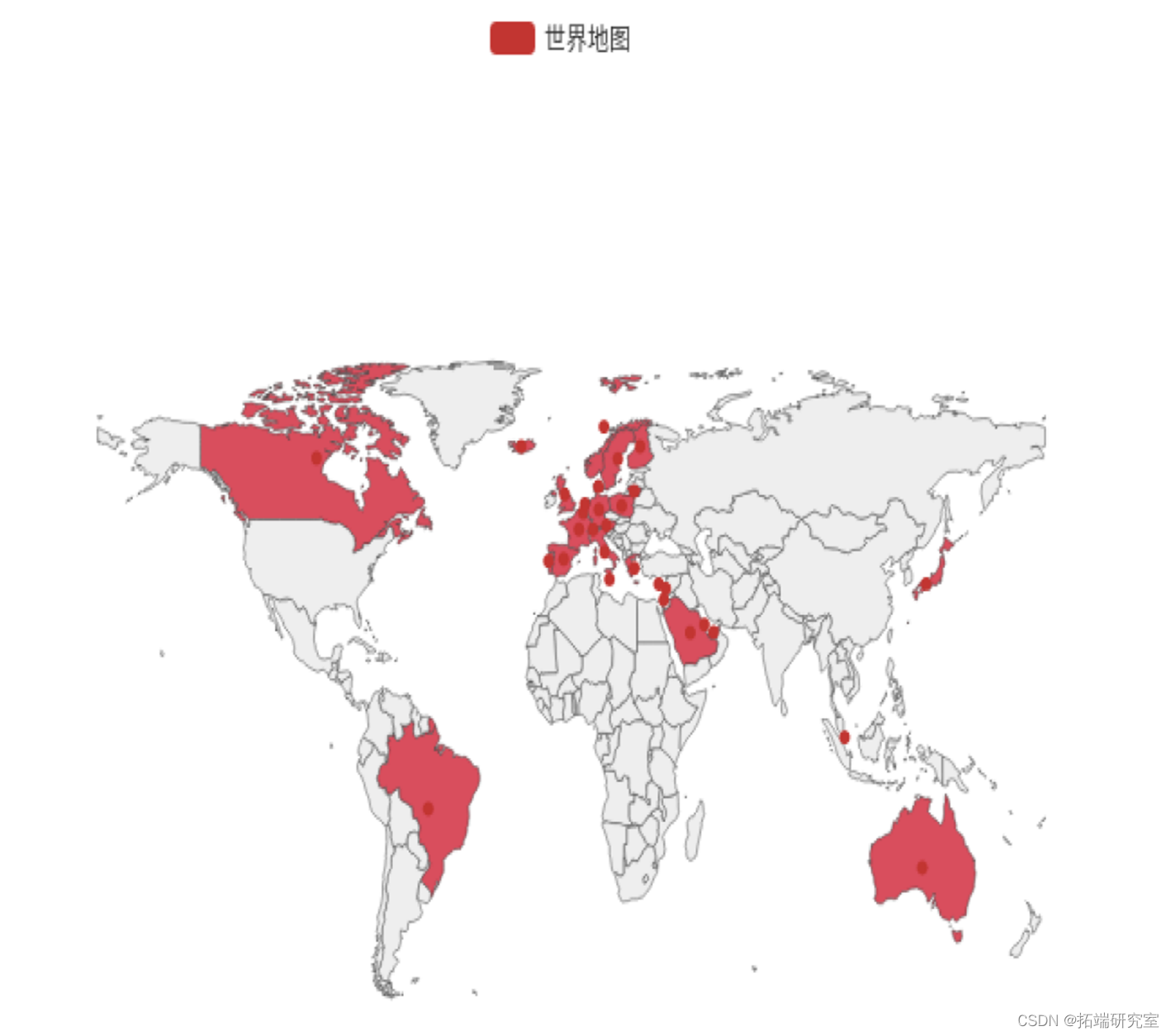
为了使销售情况更直观,我进行了热力图绘制,能够明显看出当前公司的业务板块分布,也方便后续的更多分析。
代码如下: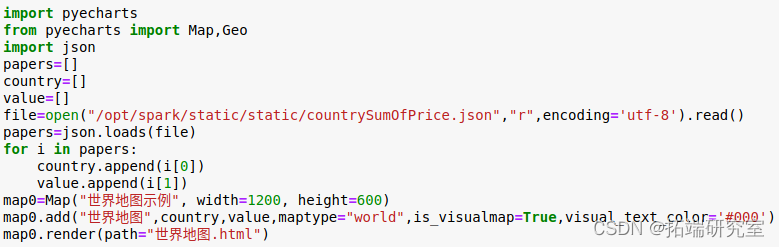
地图如下:
- 运营管理与决策
- 拓展业务板块
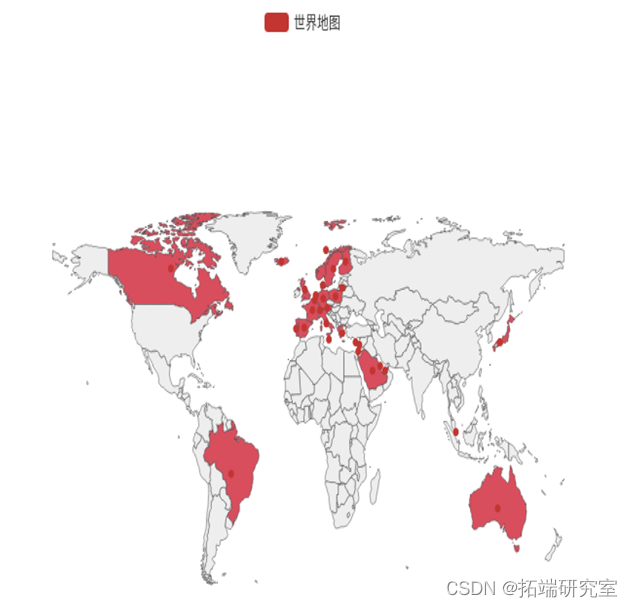
从热力图可以看出业务主要在英国本地,加拿大,澳大利亚,巴西,沙特阿拉伯等国家,而美国、亚洲、俄罗斯、非洲等地几乎没有业务,而其实美国、亚洲等地潜力巨大,可以通过宣传广告等营销方式尝试将商品销售至这些国家。
- 巩固原有客人
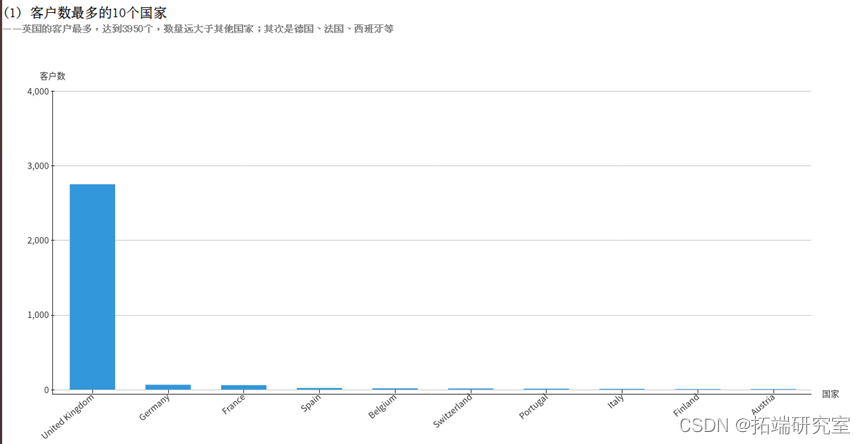
目前公司顾客主要集中在英国本地及周边的欧洲国家,且顾客数量悬殊巨大,
需要钻研顾客喜好或提升品质保留原有客人,以及使在拥有顾客的国家能够吸引更多消费者。
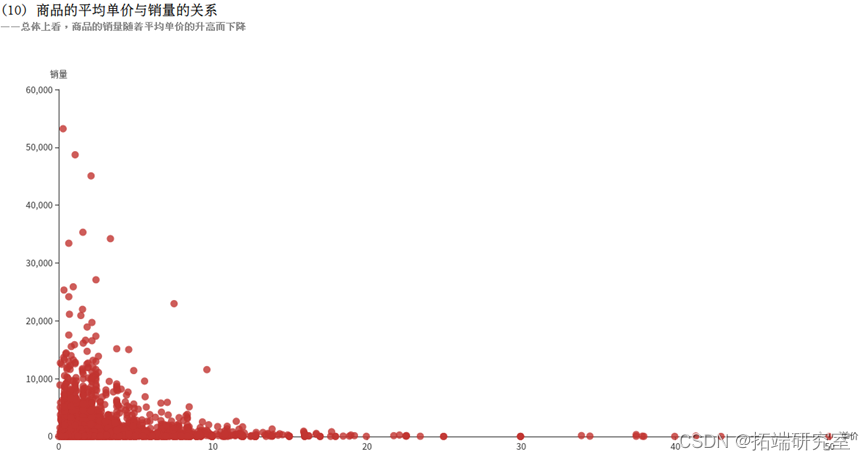
可以看到看到有些商品即使价格较高,销量仍然很高,可以考虑适当调整价格,赚取更多利润;还有有些商品销量过低,可以调整价格,或者停止生产。
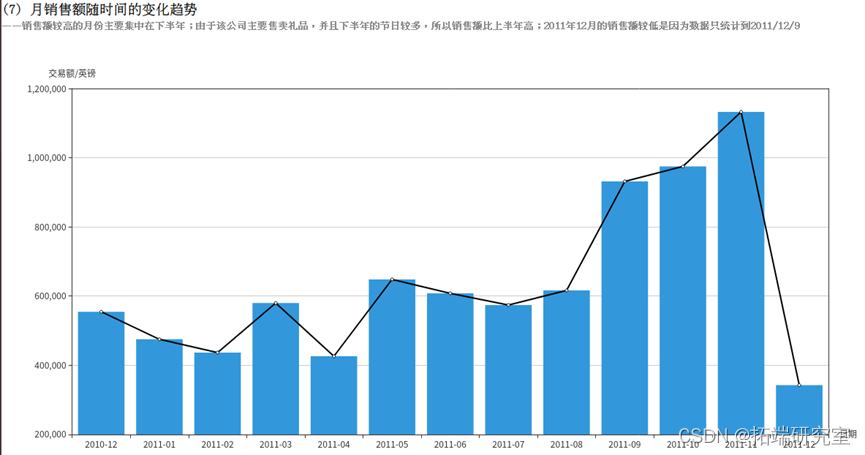
上半年销量较低,可以在上半年多运用营销手段提高销量。
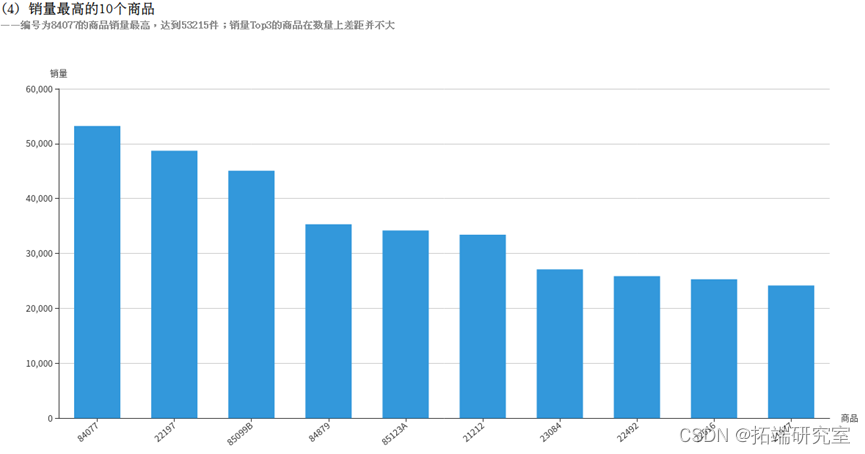
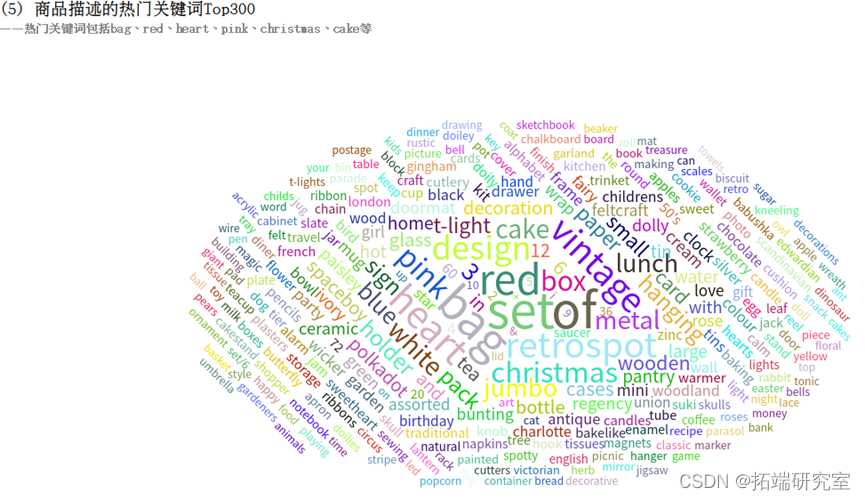
根据热门商品以及热门关键词预测生产商品。
- 针对性削减业务
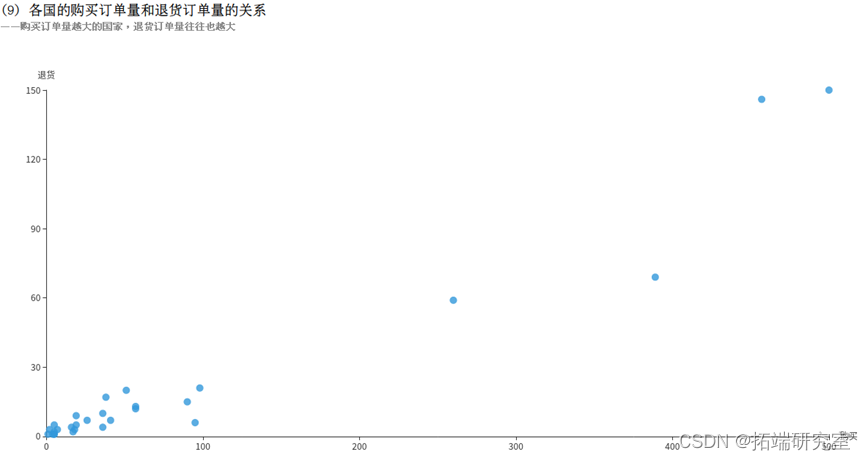
有一些进货量不多,退货量还大的国家,可以计算利润,可以停止或减少在这些地区的销售业务。
2、优化企业供应链资源配置
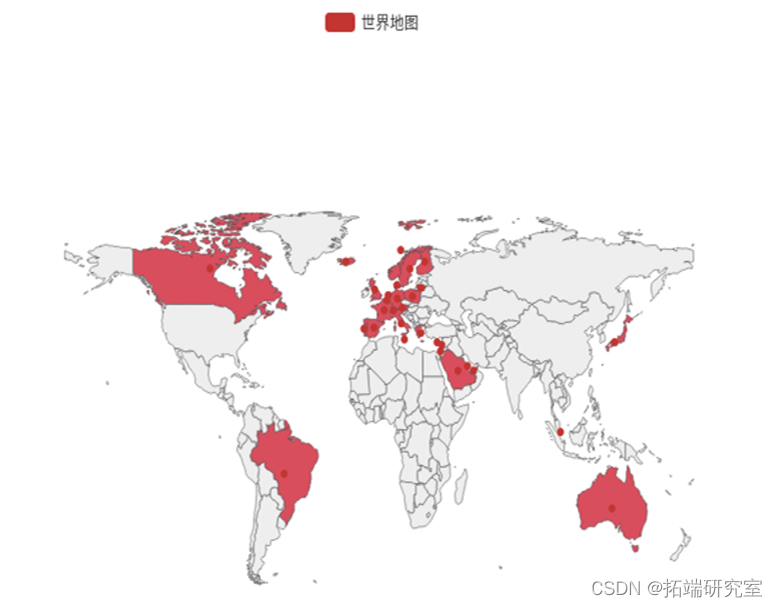
物流资源主要分配给英国本地,加拿大,澳大利亚,巴西,沙特阿拉伯。
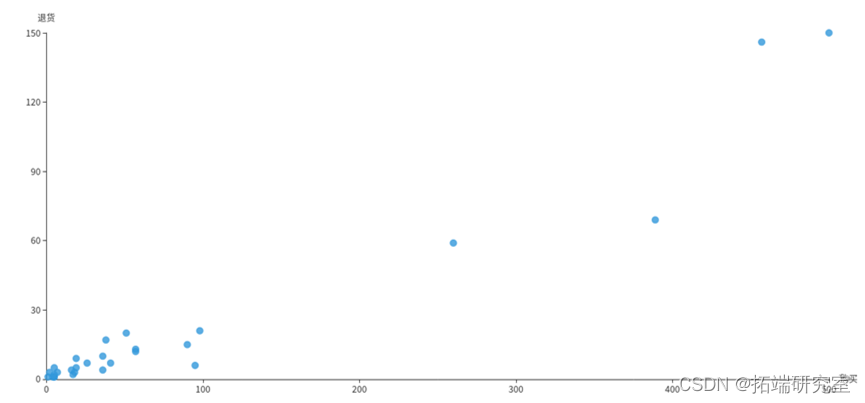
由于销量大的地区退货量也大,所以要倾斜物流资源,最好可以有办法将物流成本降低,比如跟当地物流形成合作。
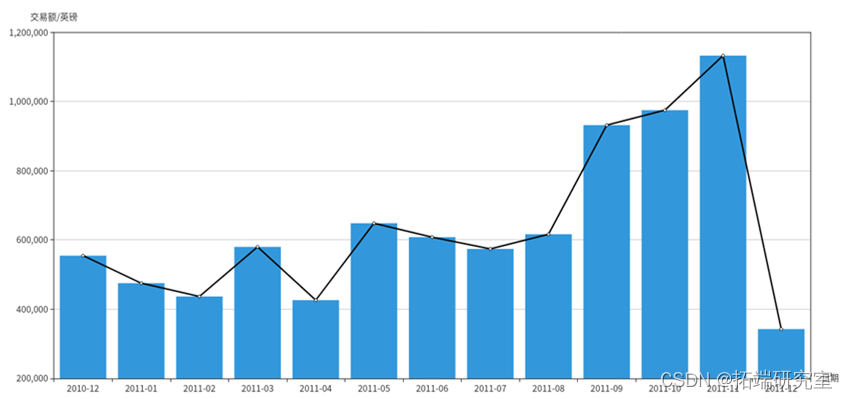
在上半年货品产量可以稍小,下半年货物可以递增缓步增加产量,下半年以生产礼品为重点
3、财务数据分析
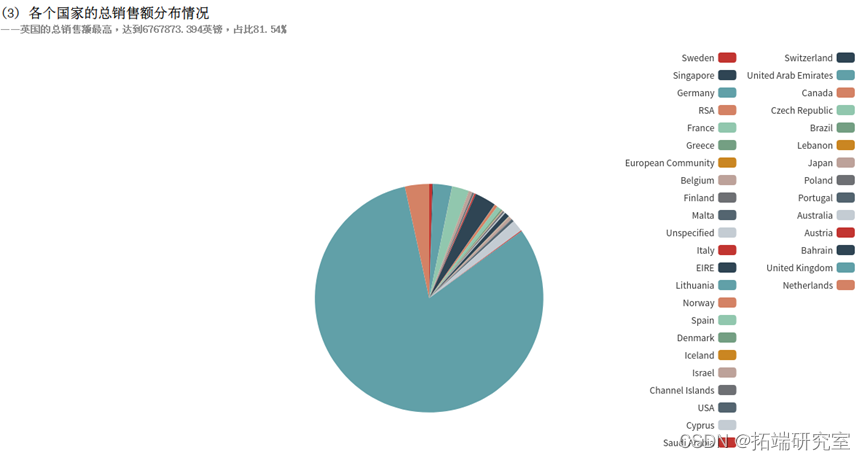
在此可看到各个国家销售额,若有更多例如商品成本、物流成本等数据还可以进行如资产质量分析、 利润质量分析、 资本结构分析、 现金流分析等更多详细的分析,但由于有些数据涉及公司隐私爬取不到,所以在此分析结束。
关于分析师
Enno
在此对Enno对本文所作的贡献表示诚挚感谢,她专长Spark、Python、hadoop数据分析。
 多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码
多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码 RAG与Python的智能编程教程问答系统:DeepSeek大模型驱动、LangChain流程构建、FAISS向量检索与语义相似度匹配技术实现|附教程文档
RAG与Python的智能编程教程问答系统:DeepSeek大模型驱动、LangChain流程构建、FAISS向量检索与语义相似度匹配技术实现|附教程文档 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
