在当今数据驱动的时代,数据分析师和数据建模师面临着各式各样复杂且极具挑战性的任务。本专题合集便是围绕这些挑战展开的宝贵知识盛宴。
在预测医生欺诈领域,医疗数据存在严重类不平衡问题,影响机器学习模型预测效果。分析师通过对 CMS 大型数据集进行数据处理,运用 10 种重采样方法结合 5 种机器学习模型,发现 SMOTEENN 重采样方法和 XGBoost 模型表现最佳。
在在线食品配送业务研究中,为建立印度班加罗尔地区消费者画像及预测购买意愿,分析师对调研问卷数据进行特征转换、划分训练测试集、建模与优化。通过基于 AIC 筛选自变量、引入 smote 采样法,提升了模型性能,并对比多种模型效果。
对于严重不平衡的破产数据,分析师先进行数据预处理,包括导入探索、处理缺失值、检查多重共线性、分析异常值及聚类分析,再应用 SMOTE 技术重采样,最后评估多种模型性能,凸显 XGBoost 在处理此类数据时的优势。
本专题合集涵盖了医疗、互联网餐饮、金融等多领域的数据处理与建模实战案例,为数据分析师和数据建模师提供了丰富的经验与思路。梯度提升专题合集已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长,一起在数据的海洋中探索前行,提升专业技能,应对更多数据挑战 。
研究预测医生欺诈领域中的重采样方法
少数医生在索赔时存在欺诈行为,若能成功预测这部分人将会有助于缓解政府的财政压力。但由于存在着严重的类不平衡问题,致使机器学习模型预测效果不好,而重采样方法的使用可以有效地改善这一问题。因此,此项目的研究重点是哪种重采样方法在这一领域的表现最好

解决方案
任务/目标
对CMS大型数据集进行大量数据处理并应用重采样方法,利用生成的新数据集进行机器学习模型训练,观察预测效果
数据处理
首先,因为数据集中存在少数null值,通过观察对比统计性分析中的部分值,决定使用中位数对所有null值进行替换。其次,数据集中部分特征为字符串形式,因为绝大多数机器学习模型无法对字符串进行学习,因而运用独热编码进行处理。
为实现有监督学习,还对所有数据集进行了贴标签处理。将数据集和标签集中的特征NPI作为共同特征,如果存在着欺诈行为则新增的特征‘exclusion’为1反之为0。最后,因少数类数据量过少,将几年的数据集进行聚合从而增加少数类数据总数。
视频
Python用SMOTEBoost、RB-Boost 和 RUS-Boost不平衡数据集的集成分类器
视频
【讲解】ARIMA、XGBOOST、PROPHET和LSTM预测比特币价格
视频
Python比赛讲解LightGBM、XGBoost+GPU和CatBoost预测学生在游戏学习过程表现
重采样
首先需要申明的是,该数据集存在着严重的类不平衡问题。

倘若使用有着类不平衡问题的数据集,则模型会存在着严重的过拟合情况,使训练和预测失去意义。适合的重采样方法将极大的帮助缓解类不平衡问题,从而是模型可以更好的训练。因而,在此项目中, 10 种不同的重采样方法将被使用。其中包括 4 种过采样, 4 种下采样和 2 种过采样和下采样的组合。
机器学习模型
在此项目中,共有 5 种机器学习模型被使用,它们分别是 Naive Bayes , Logistic Regression , Random Forests , Gradient Boosting Machines (GBM) , Extreme Gradient Boosting (XGBoost) 。其中, Naive Bayes 和 Logistic Regression 已经在其他研究中已经被证实了不可靠性,因此将在本项目中作为 baseline 进行对比。剩余三个皆为集成算法,且 GBM 和 XGBoost 在此领域还未被使用,本研究将同时探究其表现。值得一提的是,为了保证算法比较的公平性,所有重采样方法和机器学习模型使用的参数皆为默认值。
评价指标
本项目中选择使用两个不同的评估指标( ROC Curve & AUC, , F1-score )来帮助我们更好地分析模型的性能。比较不同的性能分数可以帮助我们找到更好的模型。它还可以帮助我们避免基于度量 “ 失败 ” 而做出糟糕的决策。
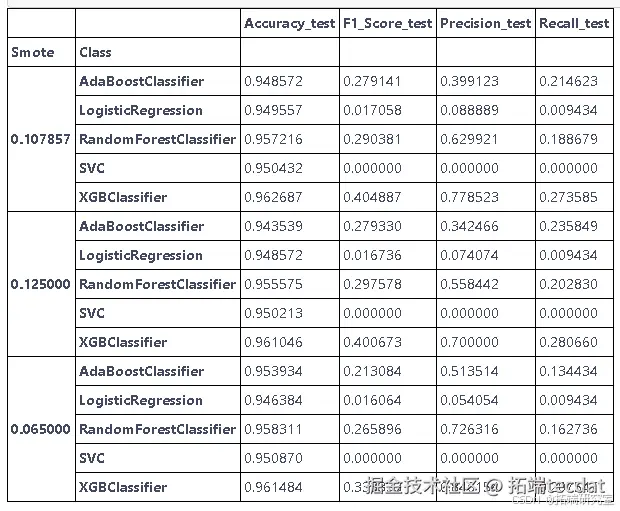
此研究的最重要成果将在下图中展出。
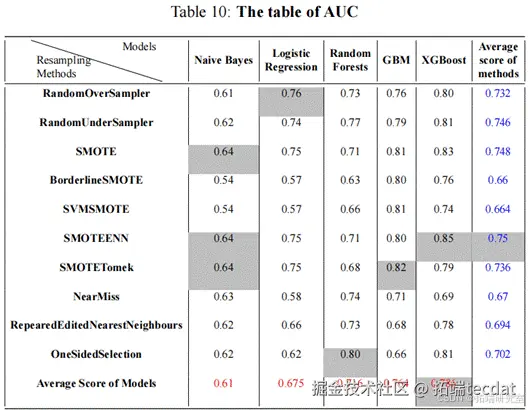
其中,我们通过最右栏和最下栏可以清楚的发现重采样方法和机器学习算法中表现最好的分别是SMOTEENN和XGBoost。这样的结果也是符合我对它们一开始的期望,SMOTEENN 实 际 上 由 SMOTE 和EditedNearestNeighbours 组合而成。SMOTE 算法的缺点是生成的少数类样本容易与周围的多数类样本产生重叠难以分类,而 EditedNearestNeighbours 的数据清洗技术恰好可以处理掉重叠样本。即先用SMOTEENN 过采样再用EditedNearestNeighbours 数据清理。简而言之,它具有两者的优点并去除了两者的缺点。而XGBoost相比于另外两个集成算法,其对代价函数做了二阶Talor展开,引入了一阶导数和二阶导数,因而收敛速度很快。其次,XGBoost在代价函数里也加入了正则项,用于控制模型的复杂度,也可以在一定程度上防止过拟合。最后,XGBoost 支持并行处理,有利于节省时间和空间。
过采样SMOTE逻辑回归、SVM、随机森林、AdaBoost和XGBoost对不平衡数据分析预测
近几年,伴随着互联网的发展,在线食品配送业务成为了新潮流。在此背景下,我们帮助客户对“在线食品交付偏好-班加罗尔地区”数据开展研究,建立印度在线食品配送平台消费者的用户画像,研究影响顾客购买意愿的因素,并给出相应的预测。本文结合一个Python预测不平衡破产数据实例的代码数据,为读者提供一套完整的实践数据分析流程。
解决方案
任务/目标
建立印度班加罗尔地区在线食品配送平台消费者的用户画像,研究影响顾客购买意愿的因素。
数据源准备
数据集中包含一个完整的调研问卷和相应的用户反馈结果。问卷共计有效填写量338条,包含55项与订购用户相关的调研内容。问卷的发放方式为简单随机抽样(simple random),即随机选取到店和在线下单的用户并邀请填写问卷内容。
特征转换
由于数据集是问卷的形式,因而在数据预处理阶段将部分描述程度的变量转化为了整数,我们根据用户的意愿按程度进行给分:
Strongly agree (Very important): 2
Agree (Important): 1
Neutral (Moderately important): 0
Disagree (Slightly important): -1
Strongly disagree (Unimportant): -2
数据集的(部分)变量如下:
Output: 用户是否愿意再次线上下单(作为本数据集的因变量)
Age: 用户的年龄
Monthly income: 用户月薪的等级
Ease and convenience: 线上下单的便捷程度
Late delivery: 较慢的配送对不再购买的影响程度
Politeness: 送餐骑手的礼貌程度
Temperature: 食品温度的重要程度
划分训练集和测试集
为了验证模型的优劣,将数据集分为两部分,70%的数据作为训练集,30%的数据作为测试集。

想了解更多关于模型定制、咨询辅导的信息?
建模
模型的目标是对output(用户是否愿意再次线上下单)进行预测,并对研究各变量对output的影响。
基于AIC的模型初步筛选
由于原数据集有55个自变量,为了让模型有更好的解释性,我们利用逻辑回归和AIC准则初步筛选得到9个自变量。如下所示:
Age
Ease.and.convenient
Time.saving
Late.Delivery
Unaffordable
Order.placed.by.mistake
Politeness
Freshness
Temperature
根据这九个自变量重新尝试搭建模型,得到的预测准确率为88%,AUC为94%
模型优化
由于数据集中因变量output为0和1的数据量有较大差异,为1:3,为了保证样本的平衡性,引入smote采样法(Smote采样简而言之是通过对原样本进行线性变换得到新的模拟样本,与bootstrap不同)经过采样,得到了数据量更大且具有较好平衡性的样本。通过此方法重新进行逻辑回归,模型的AUC从94%提升至97%,模型的表现得到了提升。
除了基于Smote采样的逻辑回归以外,在模型的探索过程中还引入了决策树、朴素贝叶斯以及加入交叉项等方法,得到的结果如下所示
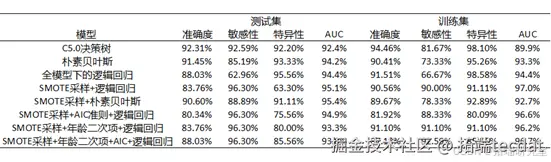
综上,我们可以发现,就测试集合的准确率而言,C5.0决策树的准确率最高,为92.31%,其次是朴素贝叶斯模型,准确率为91.45%;
然而, 由于他们不是线性模型,这两者模型不具有可观的解释性;
特别的,通过之前的描述性统计与常识可以知道,年龄分布是类似正态的,因此有必要考虑年龄的二次项使得模型更加有效,而上表也进一步证实了引入年龄二次项使得模型的精度有较为显著的提高。
值得注意的是, 在具体选择模型的时候,需要结合具体所研究的数据特征进行选择模型; 例如,没有smote采样的模型由于训练的样本不平衡, 在测试集上的准确率较高但是在训练集上的AUC较少, 容易发生误判, 对于未知Output的分布未知的数据, 则Smote的采样显得必要了。
SMOTE逻辑回归、SVM、随机森林、AdaBoost和XGBoost分析严重不平衡的破产数据|附数据代码
本文旨在探讨如何有效处理并分析严重不平衡的破产数据,采用XGBoost模型作为主要分析工具。数据集包含实体的多种特征和财务比率,目标变量为公司未来几年是否破产(1表示破产,0表示未破产)。通过一系列预处理步骤,包括缺失值处理、多重共线性检查、异常值分析以及通过K-means聚类探索数据分布,本文最终实现了对不平衡数据的有效重采样,并评估了多种机器学习模型在破产预测任务上的性能。
数据预处理
数据导入与探索
首先,使用pandas库导入数据集,并设置实体ID为索引:
df = pd.read_csv('train.csv')
df.set_index('ID', inplace = True)
df.head()
数据不平衡性
初步分析表明数据存在严重的不平衡性,这是破产预测任务中常见的挑战。不平衡性可能源于罕见但影响重大的事件发生。


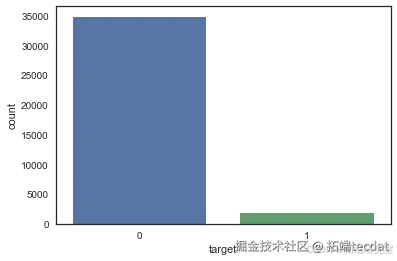
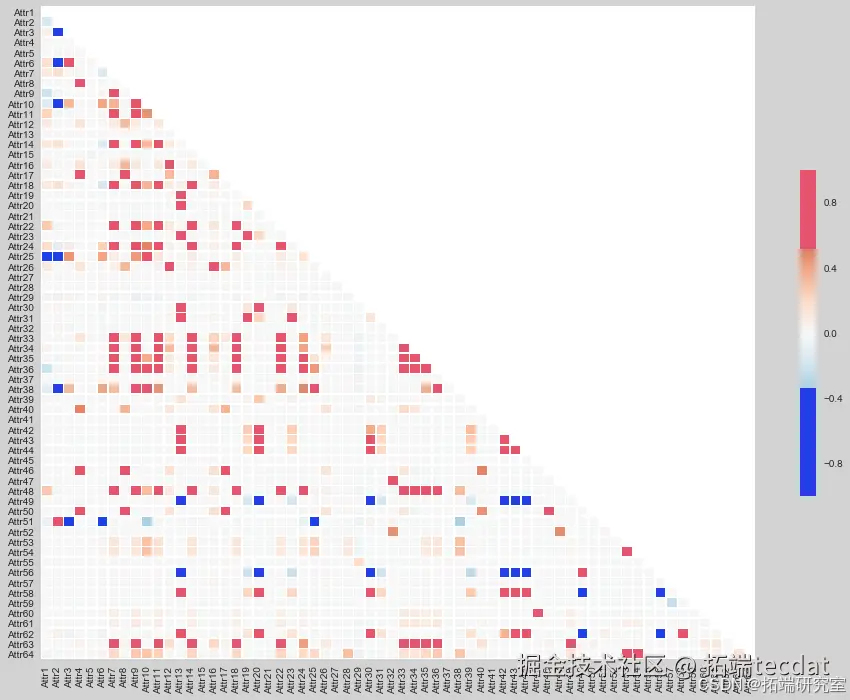

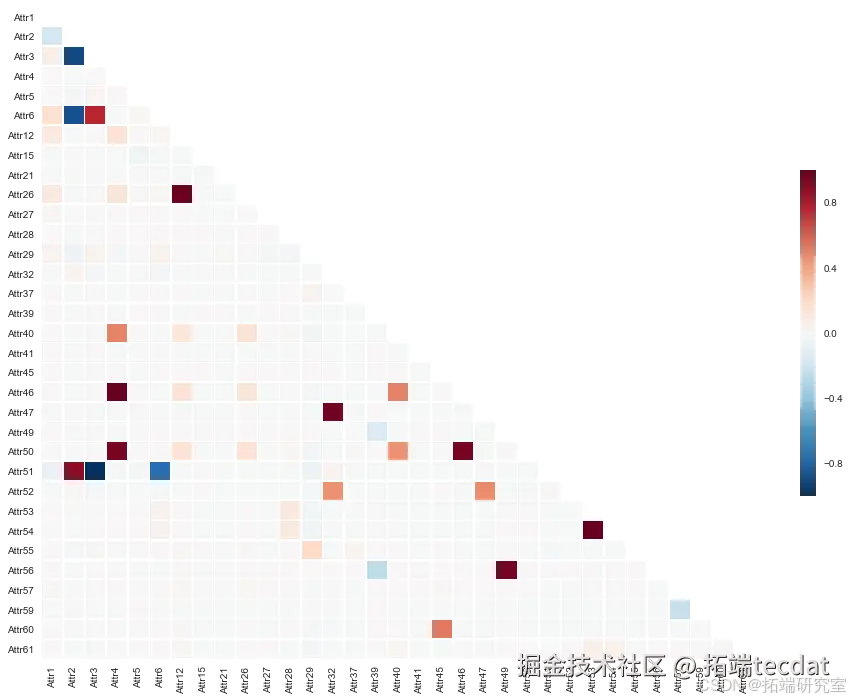
数据探索与聚类分析
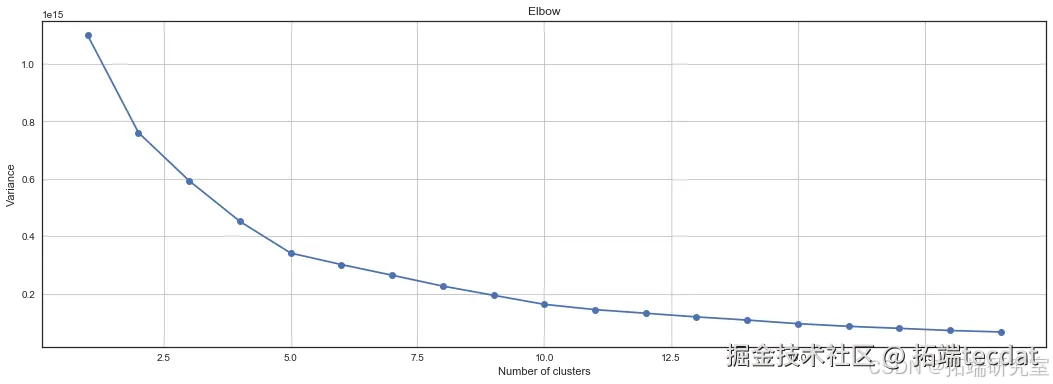
SMOTE技术
pd.DataFrame(predictors).T
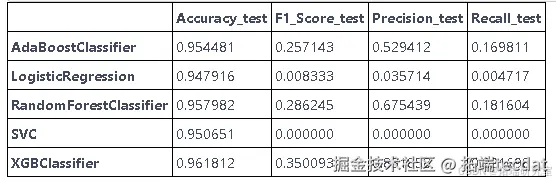
性能比较
通过多次实验调整SMOTE中的过采样比率,并对比不同模型在召回率上的表现。结果显示,XGBoost模型在0.11214的打击率下取得了最高的召回率,表明其在处理不平衡数据方面的优势。
smote_values = np.linspace(0.065, 0.125, num= 15)
smote_values

召回分数是我们感兴趣的。召回率显示了我们的模型将正值预测为正值的能力。由于我们的数据高度不平衡,因此任何模型都很难获得更好的召回率。有时模型忽略了少数群体。

结论
综上所述,XGBoost模型在破产预测任务中表现优异,特别是在处理严重不平衡的数据集时,其高召回率证明了其在识别少数类(破产公司)方面的有效性。通过合理的数据预处理、重采样策略以及模型选择,本文为类似的不平衡分类问题提供了一种有效的解决方案。未来的研究可以进一步探索更多先进的重采样技术和模型优化策略,以提升模型的整体性能。
Python信贷风控模型:梯度提升Adaboost,XGBoost,SGD, GBOOST, SVC,随机森林, KNN预测金融信贷违约支付和模型优化|附数据代码
在此数据集中,我们必须预测信贷的违约支付,并找出哪些变量是违约支付的最强预测因子?以及不同人口统计学变量的类别,拖欠还款的概率如何变化?
有25个变量:
1. ID: 每个客户的ID
2. LIMIT_BAL: 金额
3. SEX: 性别(1 =男,2 =女)
4.教育程度: (1 =研究生,2 =本科,3 =高中,4 =其他,5 =未知)
5.婚姻: 婚姻状况(1 =已婚,2 =单身,3 =其他)
6.年龄:
7. PAY_0: 2005年9月的还款状态(-1 =正常付款,1 =延迟一个月的付款,2 =延迟两个月的付款,8 =延迟八个月的付款,9 =延迟9个月以上的付款)
8. PAY_2: 2005年8月的还款状态(与上述相同)
9. PAY_3: 2005年7月的还款状态(与上述相同)
10. PAY_4: 2005年6月的还款状态(与上述相同)
11. PAY_5: 2005年5月的还款状态(与上述相同)
12. PAY_6: 还款状态2005年4月 的账单(与上述相同)
13. BILL_AMT1: 2005年9月的账单金额
14. BILL_AMT2: 2005年8月的账单金额
15. BILL_AMT3: 账单金额2005年7月 的账单金额
16. BILL_AMT4: 2005年6月的账单金额
17. BILL_AMT5: 2005年5月的账单金额
18. BILL_AMT6: 2005年4月
19. PAY_AMT1 2005年9月,先前支付金额
20. PAY_AMT2 2005年8月,以前支付的金额
21. PAY_AMT3: 2005年7月的先前付款
22. PAY_AMT4: 2005年6月的先前付款
23. PAY_AMT5: 2005年5月的先前付款
24. PAY_AMT6: 先前的付款额在2005年4月
25. default.payment.next.month: 默认付款(1 =是,0 =否)
现在,我们知道了数据集的整体结构。因此,让我们应用在应用机器学习模型时通常应该执行的一些步骤。
第1步:导入
import numpy as np
import matplotlib.pyplot as plt
所有写入当前目录的结果都保存为输出。
dataset = pd.read_csv('Card.csv')
现在让我们看看数据是什么样的
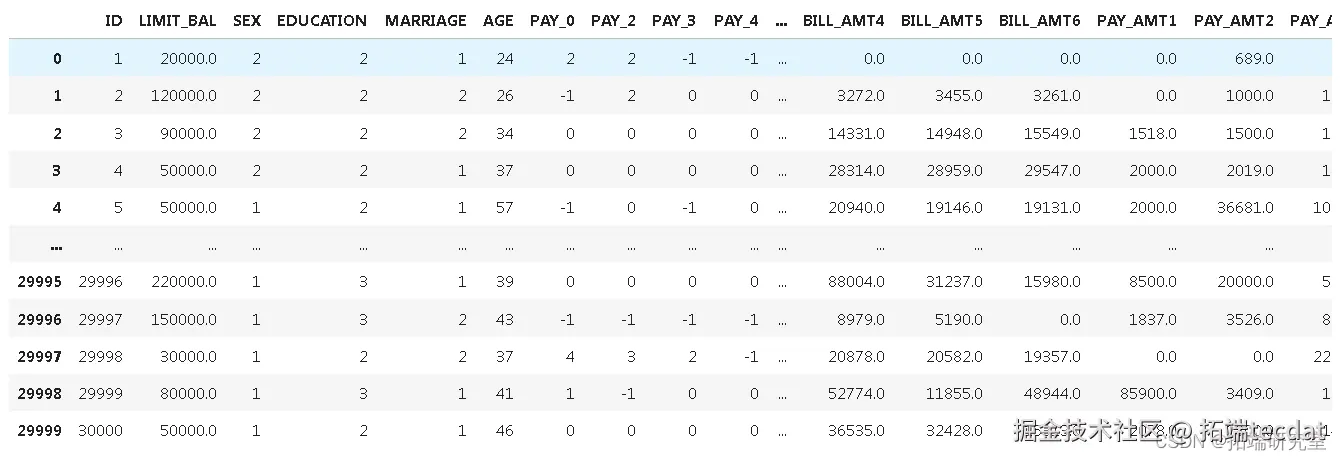
第2步:数据预处理和清理
dataset.shape
(30000, 25)
意味着有30,000条目包含25列
从上面的输出中可以明显看出,任何列中都没有对象类型不匹配。
#检查数据中Null项的数量,按列计算。
dataset.isnull().sum()
步骤3.数据可视化和探索性数据分析
# 按性别检查违约者和非违约者的计数数量
sns.countplot
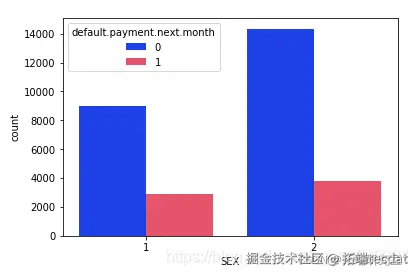
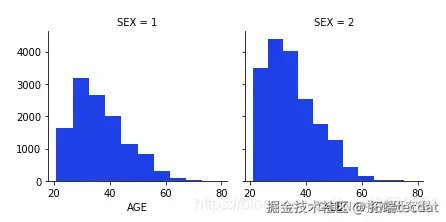
从上面的输出中可以明显看出,与男性相比,女性的整体拖欠付款更少
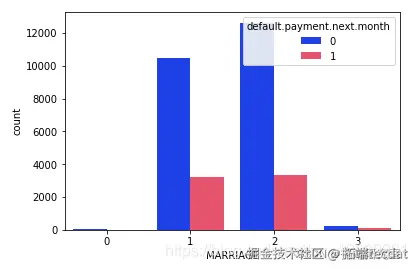
可以明显看出,那些拥有婚姻状况的人的已婚状态人的默认拖欠付款较少。
sns.pairplot

sns.jointplot
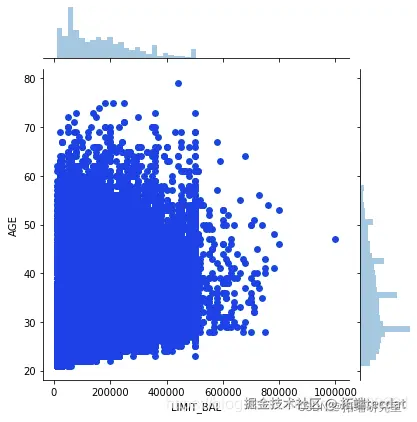
男女按年龄分布
g.map(plt.hist,'AGE')
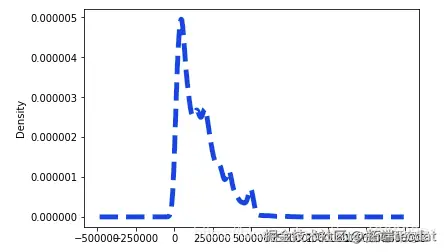
dataset['LIMIT_BAL'].plot.density
步骤4.找到相关性
X.corrwith
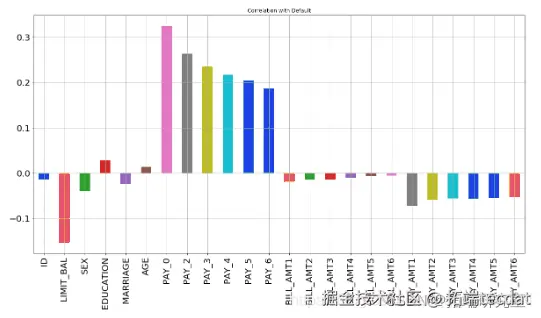
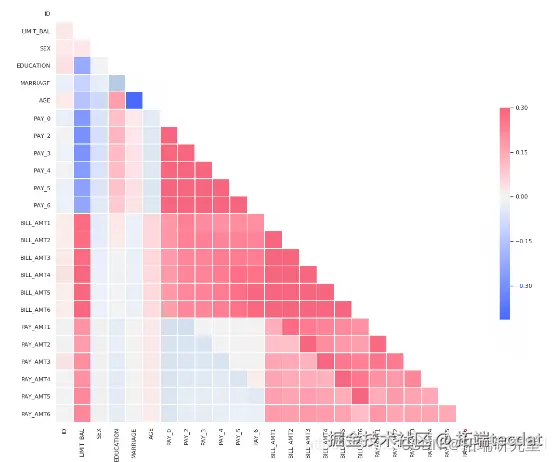
从上图可以看出,最负相关的特征是LIMIT_BAL,但我们不能盲目地删除此特征,因为根据我的看法,这对预测非常重要。ID无关紧要,并且在预测中没有任何作用,因此我们稍后将其删除。
# 绘制热图
sns.heatmap(corr)
步骤5:将数据分割为训练和测试集
训练数据集和测试数据集必须相似,通常具有相同的预测变量或变量。它们在变量的观察值和特定值上有所不同。如果将模型拟合到训练数据集上,则将隐式地最小化误差。拟合模型为训练数据集提供了良好的预测。然后,您可以在测试数据集上测试模型。如果模型在测试数据集上也预测良好,则您将更有信心。因为测试数据集与训练数据集相似,但模型既不相同也不相同。这意味着该模型在真实意义上转移了预测或学习。
因此,通过将数据集划分为训练和测试子集,我们可以有效地测量训练后的模型,因为它以前从未看到过测试数据,因此可以防止过度拟合。
我只是将数据集拆分为20%的测试数据,其余80%将用于训练模型。
train_test_split(X, y, test_size = 0.2, random_state = 0)
步骤6:规范化数据:特征标准化
对于许多机器学习算法而言,通过标准化(或Z分数标准化)进行特征标准化可能是重要的预处理步骤。
许多算法(例如SVM,K近邻算法和逻辑回归)都需要对特征进行规范化,
min_test = X_test.min()
range_test = (X_test - min_test).max()
X_test_scaled = (X_test - min_test)/range_test
步骤7:应用机器学习模型
from sklearn.ensemble import AdaBoostClassifier
adaboost =AdaBoostClassifier()

xgb_classifier.fit(X_train_scaled, y_train,verbose=True)
end=time()
train_time_xgb=end-start
应用具有100棵树和标准熵的随机森林
classifier = RandomForestClassifier(random_state = 47,
criterion = 'entropy',n_estimators=100)

svc_model = SVC(kernel='rbf', gamma=0.1,C=100)
knn = KNeighborsClassifier(n_neighbors = 7)
步骤8:分析和比较机器学习模型的训练时间
Train_Time = [
train_time_ada,
train_time_xgb,
train_time_sgd,
train_time_svc,
train_time_g,
train_time_r100,
train_time_knn
]
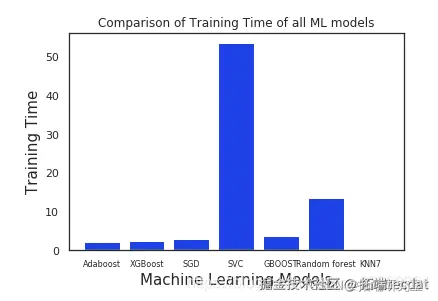
从上图可以明显看出,与其他模型相比,Adaboost和XGboost花费的时间少得多,而其他模型由于SVC花费了最多的时间,原因可能是我们已经将一些关键参数传递给了SVC。
步骤9.模型优化
在每个迭代次数上,随机搜索的性能均优于网格搜索。同样,随机搜索似乎比网格搜索更快地收敛到最佳状态,这意味着迭代次数更少的随机搜索与迭代次数更多的网格搜索相当。
在高维参数空间中,由于点变得更稀疏,因此在相同的迭代中,网格搜索的性能会下降。同样常见的是,超参数之一对于找到最佳超参数并不重要,在这种情况下,网格搜索浪费了很多迭代,而随机搜索却没有浪费任何迭代。
现在,我们将使用Randomsearch cv优化模型准确性。如上表所示,Adaboost在该数据集中表现最佳。因此,我们将尝试通过微调adaboost和SVC的超参数来进一步优化它们。
参数调整
现在,让我们看看adaboost的最佳参数是什么
random_search.best_params_
{'random_state': 47, 'n_estimators': 50, 'learning_rate': 0.01}

random_search.best_params_
{'n_estimators': 50, 'min_child_weight': 4, 'max_depth': 3}

random_search.best_params_
{'penalty': 'l2', 'n_jobs': -1, 'n_iter': 1000, 'loss': 'log', 'alpha': 0.0001}
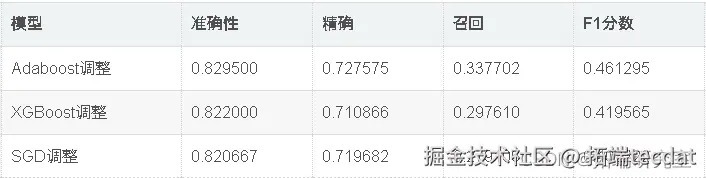
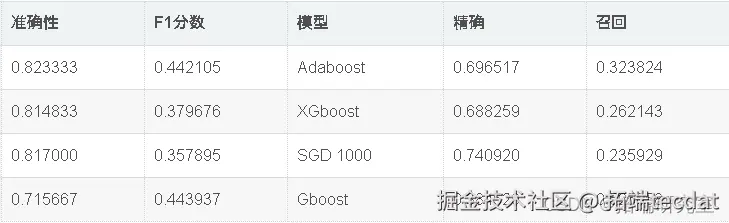
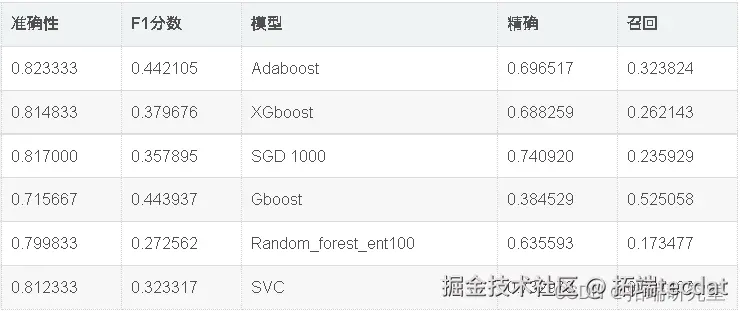
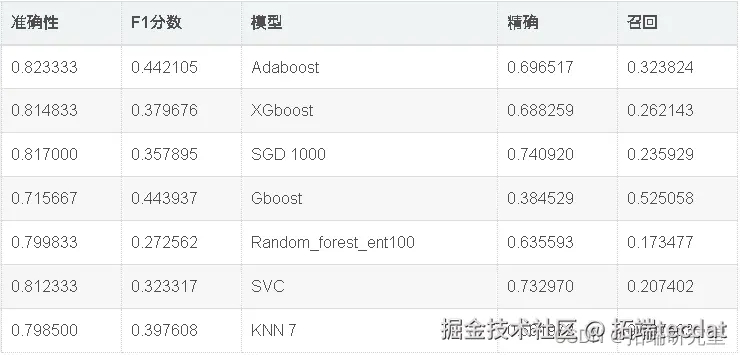
出色的所有指标参数准确性,F1分数精度,ROC,三个模型adaboost,XGBoost和SGD的召回率现已优化。此外,我们还可以尝试使用其他参数组合来查看是否会有进一步的改进。
ROC曲线图
auc = metrics.roc_auc_score(y_test,model.predict(X_test_scaled))
plt.plot([0, 1], [0, 1],'r--')
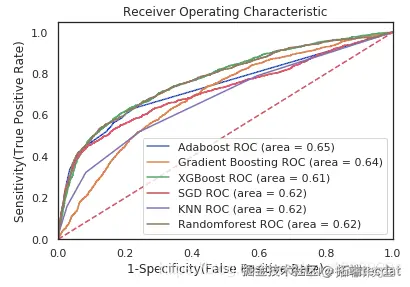
# 计算测试集分数的平均值和标准差
test_mean = np.mean
# 绘制训练集和测试集的平均准确度得分
plt.plot
# 绘制训练集和测试集的准确度。
plt.fill_between
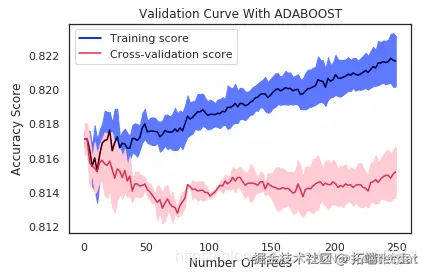
验证曲线的解释
如果树的数量在10左右,则该模型存在高偏差。两个分数非常接近,但是两个分数都离可接受的水平太远,因此我认为这是一个高度偏见的问题。换句话说,该模型不适合。
在最大树数为250的情况下,由于训练得分为0.82但验证得分约为0.81,因此模型存在高方差。换句话说,模型过度拟合。同样,数据点显示出一种优美的曲线。但是,我们的模型使用非常复杂的曲线来尽可能接近每个数据点。因此,具有高方差的模型具有非常低的偏差,因为它几乎没有假设数据。实际上,它对数据的适应性太大。
从曲线中可以看出,大约30到40的最大树可以最好地概括看不见的数据。随着最大树的增加,偏差变小,方差变大。我们应该保持两者之间的平衡。在30到40棵树的数量之后,训练得分就开始上升,而验证得分开始下降,因此我开始遭受过度拟合的困扰。因此,这是为什么30至40之间的任何数量的树都是一个不错的选择的原因。
结论
因此,我们已经看到,调整后的Adaboost的准确性约为82.95%,并且在所有其他性能指标(例如F1分数,Precision,ROC和Recall)中也取得了不错的成绩。
此外,我们还可以通过使用Randomsearch或Gridsearch进行模型优化,以找到合适的参数以提高模型的准确性。
我认为,如果对这三个模型进行了适当的调整,它们的性能都会更好。
关于分析师

Jiajie Shi
在此对 Jiajie Shi 对本文所作的贡献表示诚挚感谢,他在伦敦大学学院完成了科学与数据密集型计算专业的硕士学位,专注数据处理、机器学习领域。擅长 Python、SQL 。

Yimeng Li 是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在南京大学完成了数学系统计学专业的学位,专注数理统计、机器学习领域。擅长R语言、Python、Tableau。
 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据



