在本文中,我想向你展示如何使用R的Metropolis采样从贝叶斯Poisson回归模型中采样。
Metropolis-Hastings抽样算法是一类马尔科夫链蒙特卡洛(MCMC)方法
Metropolis-Hastings算法
其主要思想是生成一个马尔科夫链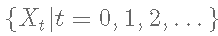 使其平稳分布为目标分布。这种算法最常见的应用之一是在贝叶斯统计中从后验密度中取样,这也是本文的目标。
使其平稳分布为目标分布。这种算法最常见的应用之一是在贝叶斯统计中从后验密度中取样,这也是本文的目标。
-
Proposed distribution选symmetric的,比如Gaussian,假定你当前的sample是
,那么
是一个不错的选择,实际使用中应该根据
。这其实和你选Uniform distribution要选的区间一样,这不叫玄学,叫prior knowledge(笑。
-
模型表现基本是看你说的那几项,表现都很好的话基本可以收工了。
-
Autocorrelation很强的情况下应该考虑thinning,一个step size为
的thinning就是每t次采样只会保留一个sample,这样可以比较有效地降低correlation。
-
ESS和Acceptance ratio比较差的情况需要考虑proposed distribution是否合理,尤其是有没有覆盖到真实的分布所在的值域或者跳跃的范围是否过大,根据proposed distribution的参数进行grid search是比较常用的调参方法。
-
为了提升效果通常先burn in,也就是MCMC先跳个几千次不采样,观察一下trace是否较为平稳,然后再开始采样。毕竟,磨刀不误砍柴工。
-
考虑问题的维数是否过高,可以考虑试试Gibbs Sampling或者HMC。
该算法规定对于一个给定的状态Xt,如何生成下一个状态 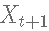 有一个候选点Y,它是从一个提议分布
有一个候选点Y,它是从一个提议分布 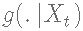 ,中生成的,根据决策标准被接受,所以链条在时间t+1时移动到状态Y,即Xt+1=Y或被拒绝,所以链条在时间t+1时保持在状态Xt,即Xt+1=Xt。
,中生成的,根据决策标准被接受,所以链条在时间t+1时移动到状态Y,即Xt+1=Y或被拒绝,所以链条在时间t+1时保持在状态Xt,即Xt+1=Xt。
Metropolis 采样
在Metropolis算法中,提议分布是对称的,也就是说,提议分布 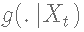 满足
满足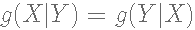
,所以Metropolis采样器产生马尔科夫链的过程如下。
- 选择一个提议分布
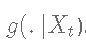 . 在选择它之前,了解这个函数中的理想特征。
. 在选择它之前,了解这个函数中的理想特征。 - 从提议分布g中生成X0。
- 重复进行,直到链收敛到一个平稳的分布。
- 从
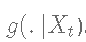 生成Y.
生成Y. - 从Uniform(0, 1)中生成U。
- 如果
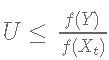 , 接受Y并设置Xt+1=Y,否则设置Xt+1=Xt。这意味着候选点Y被大概率地接受
, 接受Y并设置Xt+1=Y,否则设置Xt+1=Xt。这意味着候选点Y被大概率地接受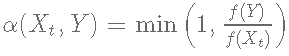 .
. - 递增t.
贝叶斯方法
正如我之前提到的,我们要从定义为泊松回归模型的贝叶斯中取样。
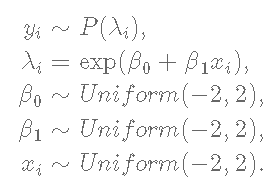
对于贝叶斯分析中的参数估计,我们需要找到感兴趣的模型的似然函数,在这种情况下,从泊松回归模型中找到。
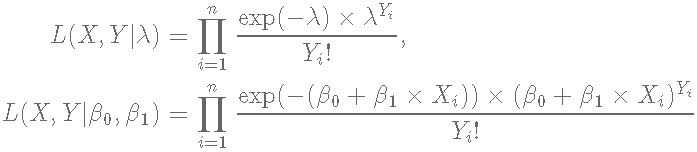
现在我们必须为每个参数β0和β1指定一个先验分布。我们将对这两个参数使用无信息的正态分布,β0∼N(0,100)和β1∼N(0,100) 。
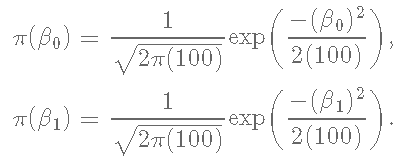
最后,我们将后验分布定义为先验分布和似然分布的乘积。
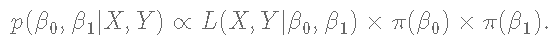
使用Metropolis采样器时,后验分布将是目标分布。

计算方法
这里你将学习如何使用R语言的Metropolis采样器从参数β0和β1的后验分布中采样。
数据
首先,我们从上面介绍的泊松回归模型生成数据。
n <- 1000 # 样本大小 J <- 2 # 参数的数量 X <- runif(n,-2,2) # 生成自变量的值 beta <- runif(J,-2,2) #生成参数的值 y <- rpois(n, lambda = lambda) # 生成因变量的值
随时关注您喜欢的主题
似然函数
现在我们定义似然函数。在这种情况下,我们将使用这个函数的对数,这是强烈建议的,以避免在运行算法时出现数字问题。
LikelihoodFunction <- function(param){
beta0 <- param[1]
beta1 <- param[2]
lambda <- exp(beta1*X + beta0)
# 对数似然函数
loglikelihoods <- sum(dpois(y, lambda = lambda, log=T))
return(loglikelihoods)
}
先验分布
接下来我们定义参数β0和β1的先验分布。与似然函数一样,我们将使用先验分布的对数。
beta0prior <- dnorm(beta0, 0, sqrt(100), log=TRUE)
beta1prior <- dnorm(beta1, 0, sqrt(100), log=TRUE)
return(beta0prior + beta1prior) #先验分布的对数
后验分布
由于我们是用对数工作的,我们把后验分布定义为似然函数的对数与先验分布的对数之和。
记住,这个函数是我们的目标函数f(.),我们要从中取样。
return (LikelihoodFunction(param) + LogPriorFunction(param)) }
提议函数
最后,我们定义提议分布g(.|Xt)。由于我们将使用Metropolis采样器,提议分布必须是对称的,并且取决于链的当前状态,因此我们将使用正态分布,其平均值等于当前状态下的参数值。
ProposalFunction <- function(param){
}
Metropolis 采样器
最后,我们编写代码,帮助我们执行Metropolis采样器。在这种情况下,由于我们使用的是对数,我们必须将候选点Y被接受的概率定义为。
在这种情况下,我们将在算法的每20次迭代中为我们的最终链选择一个值。
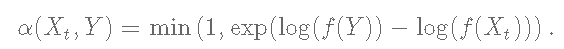
# 创建一个数组来保存链的值
chain[1, ] <- startvalue # 定义链的起始值
for (i in 1:iterations){
# 从提议函数生成Y
Y <- ProposalFunction(chain[i, ])
# 候选点被接受的概率
PosteriorFunction(chain[i, ]))
# 接受或拒绝Y的决策标准
if (runif(1) < probability) {
chain[i+1, ] <- Y
}else{
chain[i+1, ] <- chain[i, ]
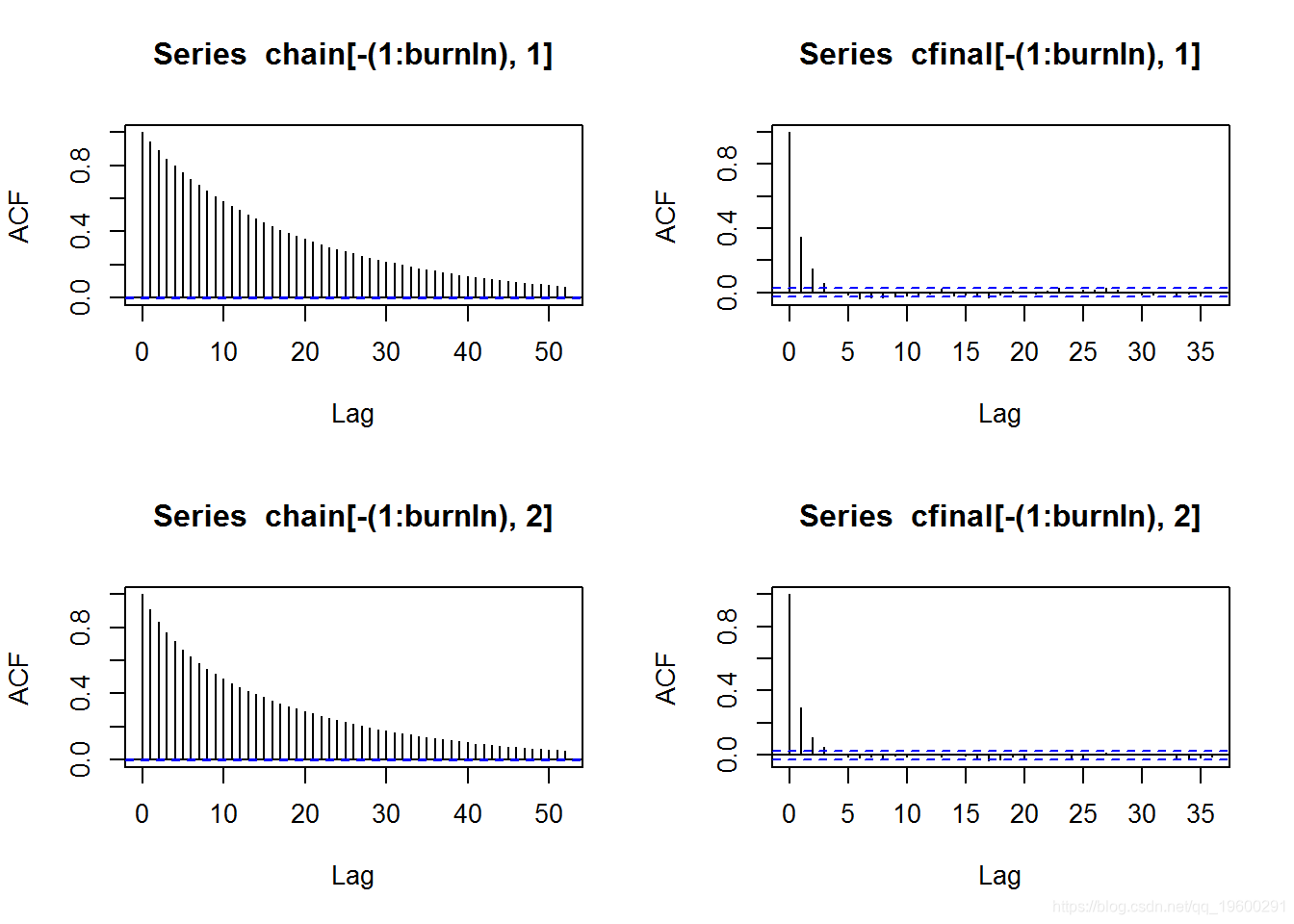
由于MCMC链具有很强的自相关,它可能产生的样本在短期内无法代表真实的基础后验分布。那么,为了减少自相关,我们可以只使用链上的每一个n个值来稀释样本。
startvalue <- c(0, 0) # 定义链条的起始值
#每20次迭代选择最终链的值
for (i in 1:10000){
if (i == 1){
cfinal[i, ] <- chain[i*20,]
} else {
cfinal[i, ] <- chain[i*20,]
# 删除链上的前5000个值
burnIn <- 5000
在这里,你可以看到ACF图,它给我们提供了任何序列与其滞后值的自相关值。在这种情况下,我们展示了初始MCMC链的ACF图和对两个参数的样本进行稀释后的最终链。从图中我们可以得出结论,所使用的程序实际上能够大大减少自相关。
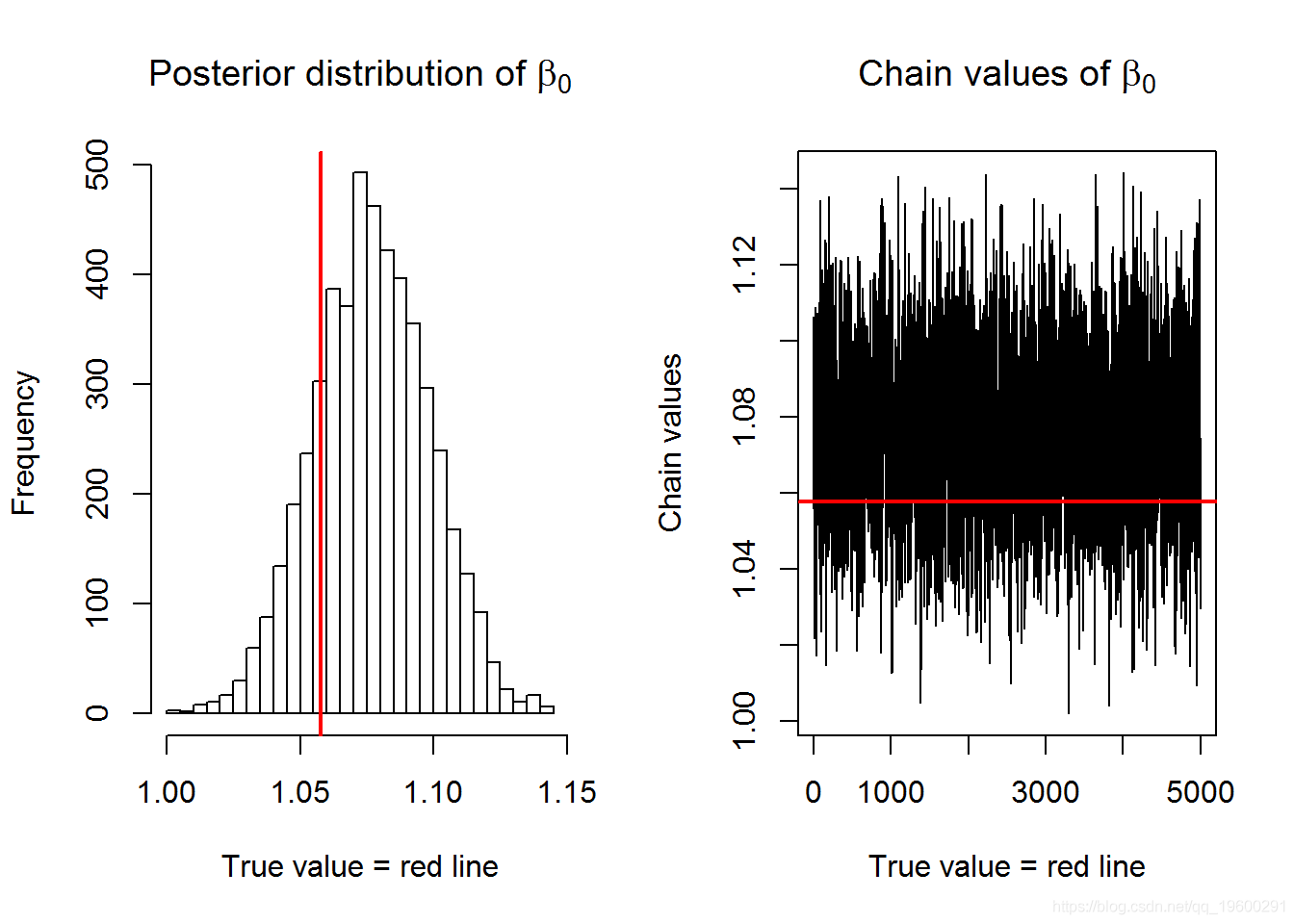
结果
在这一节中,我们介绍了由Metropolis采样器产生的链以及它对参数β0和β1的分布。参数的真实值由红线表示。
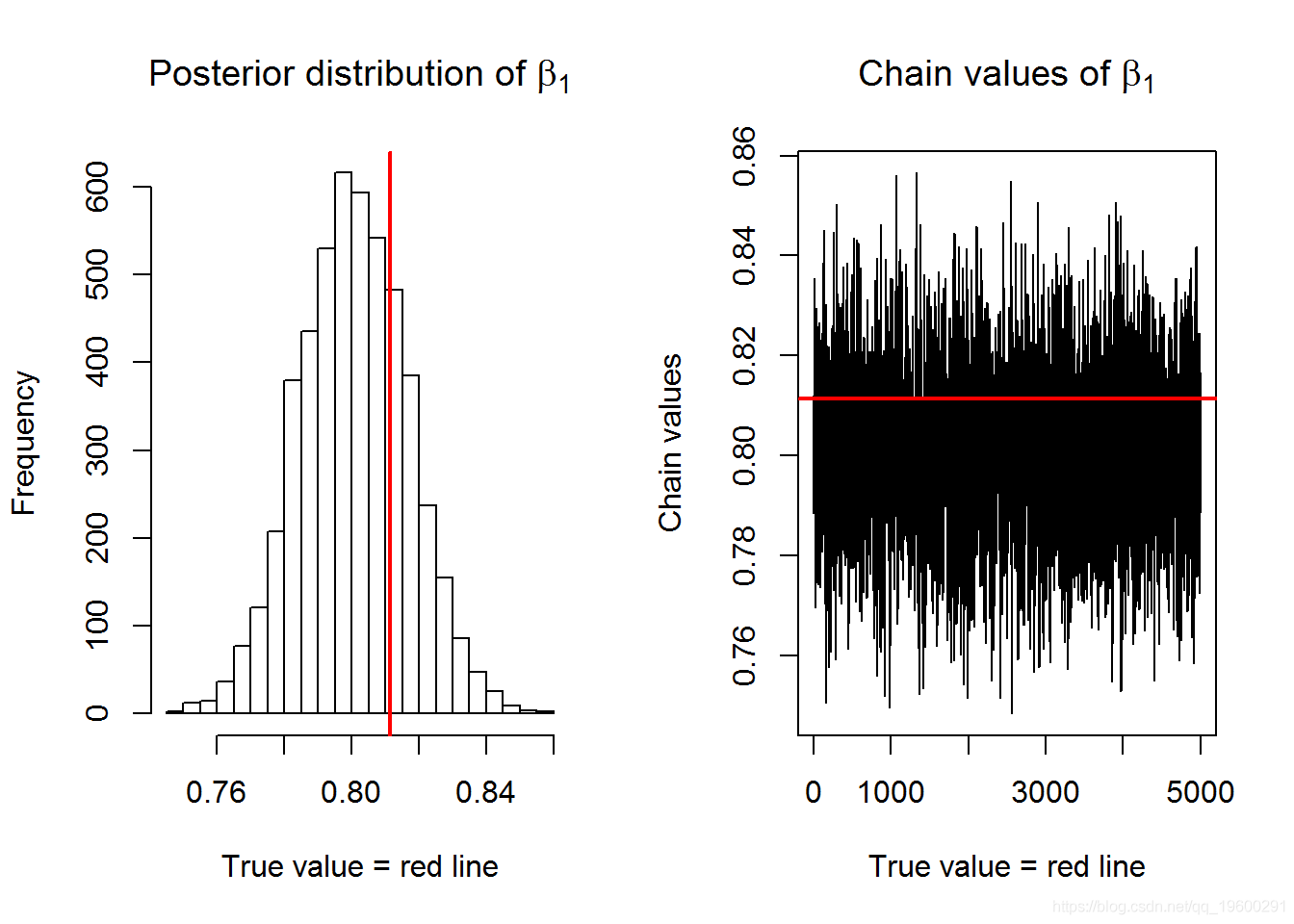
与glm()的比较
现在我们必须将使用Metropolis采样得到的结果与glm()函数进行比较,glm()函数用于拟合广义linera模型。
下表列出了参数的实际值和使用Metropolis采样器得到的估计值的平均值。
## True value Mean MCMC glm ## beta0 1.0578047 1.0769213 1.0769789 ## beta1 0.8113144 0.8007347 0.8009269
结论
从结果来看,我们可以得出结论,使用Metropolis采样器和glm()函数得到的泊松回归模型的参数β0和β1的估计值非常相似,并且接近于参数的实际值。另外,必须认识到先验分布、建议分布和链的初始值的选择对结果有很大的影响,因此这种选择必须正确进行。

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践
视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践 MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例 Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究 Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
