
航空业的庞大规模让人有理由关心它:它不仅直接影响数百万人(飞行员,工程师等),而且数百万人因间接影响其经济实力而间接影响数百万人。
尽管航空业强劲,但为了保持持续增长以及作为跨地区行业领导者的持续地位,必须时刻保持警惕,以跟上客户需求。
可下载资源
动机
当然,在这方面的成功要求航空公司首先了解客户关心的是什么。发现航空公司客户喜欢和不喜欢他们的飞行体验是该项目的起点。
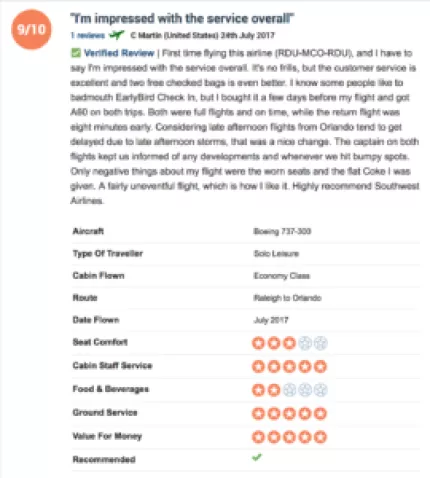
包含在这个中的变量是:
航空公司:
评论作者给出的整体航空公司评分(满分10分)
作者:评论作者的名字
日期:撰写评论的日期
作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。最初,我是在参加校外竞赛时接触到随机森林算法的。最近几年的国内外大赛,包括2013年百度校园电影推荐系统大赛、2014年阿里巴巴天池大数据竞赛以及Kaggle数据科学竞赛,参赛者对随机森林的使用占有相当高的比例。此外,据我的个人了解来看,一大部分成功进入答辩的队伍也都选择了Random Forest 或者 GBDT 算法。所以可以看出,Random Forest在准确率方面还是相当有优势的。
那说了这么多,那随机森林到底是怎样的一种算法呢?
如果读者接触过决策树(Decision Tree)的话,那么会很容易理解什么是随机森林。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想–集成思想的体现。“随机”的含义我们会在下边部分讲到。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
随机森林的特点
我们前边提到,随机森林是一种很灵活实用的方法,它有如下几个特点:
-
在当前所有算法中,具有极好的准确率/It is unexcelled in accuracy among current algorithms;
-
能够有效地运行在大数据集上/It runs efficiently on large data bases;
-
能够处理具有高维特征的输入样本,而且不需要降维/It can handle thousands of input variables without variable deletion;
-
能够评估各个特征在分类问题上的重要性/It gives estimates of what variables are important in the classification;
-
在生成过程中,能够获取到内部生成误差的一种无偏估计/It generates an internal unbiased estimate of the generalization error as the forest building progresses;
-
对于缺省值问题也能够获得很好得结果/It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing
-
… …
实际上,随机森林的特点不只有这六点,它就相当于机器学习领域的Leatherman(多面手),你几乎可以把任何东西扔进去,它基本上都是可供使用的。在估计推断映射方面特别好用,以致都不需要像SVM那样做很多参数的调试。具体的随机森林介绍可以参见随机森林主页:Random Forest。
customer_review:客户评论的文本
飞机:飞机类别/类型(可能性太多,无法列出;例如:波音737)
traveller_type:旅行者类型(商务,情侣休闲,家庭休闲,独奏休闲)
客舱:评论作家飞行的机舱类型(商务舱,经济舱,头等舱,特级经济舱)
航线:航班起点和目的地(例如:芝加哥至波士顿)
问题1
在座位舒适度,座舱服务,食品和饮料,娱乐和地面服务方面,飞行的哪个方面对客户的整体评价影响最大?
这是一个经典的机器学习问题,很容易提出,但难以回答,难点在于预测变量之间潜在的微妙相互作用。
我使用R包“randomForest”中的randomForest()函数,该函数使用非参数Breiman随机森林算法生成回归模型。
作为一个侧重点,它可以估计每个预测变量相对于其他预测变量对预测响应变量的重要性。这个输出是我用来确定我的五个变量中哪一个对整个飞行评级最重要的。以下是对我的数据运行时randomForest()函数的变量重要性输出的视觉效果:
ggplot(data = impact_comp, aes(x = feature, y = imp)) +
geom_bar(aes(fill = feature), stat = 'identity') +
scale_fill_brewer(palette = "RdPu") +
xlab("Feature") + ylab("Relative importance") + theme_minimal() +
ggtitle("Feature impact on overall rating: randomForest()") +
guides(fill=guide_legend(title="Feature")) +
theme(panel.spacing = unit(2, "lines"),
axis.text.x=element_text(angle=45,hjust=1),
plot.title = element_text(size = 20),
axis.text=element_text(size=12),
axis.title=element_text(size=14))根据Breiman算法,地面服务是预测客户飞行总体评分的最重要变量,其次是座椅舒适度,客舱服务,食品和饮料以及娱乐(按此顺序)。
分析了包含每个变量的评论比例。输入缺失值不可避免地会导致结果偏差,但是消除这些值会为我们带来潜在的宝贵信息。在这种情况下,我相信各方面的失踪倾向于属于“不随意丢失”的范畴,这意味着失踪的原因实际上与所讨论的变量的价值有关; 特别是,我认为,大量缺失的领域对于客户而言可能不那么重要,而缺少缺失的领域则更为重要。为了分析这一点,我绘制了包含每个变量的评论比例:
由此我们看到,机舱服务和座椅舒适度几乎包含在每个评论中,而地面服务仅包含在约55%的评论中。
问题2
美国航空公司如何在客户飞行体验的不同方面表现出色?
鉴于我们在问题1中的结果,航空公司现在可能希望将其自身与其他航空公司以及整个行业进行比较,涵盖机舱服务,娱乐,食品和饮料,地面服务和座椅舒适度等变量。为了分析这一点,我对每个航空公司以及整个行业的每个变量给予1,2,3,4,5和NA评级的评论数量进行了统计。对于座椅舒适性评级,我们有以下结果:
ggplot(data = temp_raw, aes_string(x = input$selected2, y = "percent")) +
geom_bar(aes_string(fill = input$selected2), width = 1, stat = 'identity') +
theme_minimal() + scale_fill_brewer(palette = "RdPu") +
guides(fill=guide_legend(title="Rating")) +
xlab(paste(c(input$selected2, "rating"), collapse = ' ')) +
ylab("Percent of total ratings") +
ggtitle("Feature percentages industry-wide") +
theme(plot.title = element_text(size = 20),
axis.text=element_text(size=12),
axis.title=element_text(size=14))
探索了机舱服务,娱乐,食品和饮料,地面服务和座椅舒适性五个变量中的每一个,并且通过所有这些有以下观察:
捷蓝航空对所有航空公司的座椅舒适度评分最高,因此应推崇自己作为座椅舒适性的行业领导者。同样,阿拉斯加航空公司应该推销自己作为机舱服务的行业领导者。根据问题1的结果,如果客户知道他们在座椅舒适性和客舱服务方面处于领先地位,那么JetBlue和阿拉斯加都可能获得销售增长,因为这些变量是迄今为止研究的五个变量(影响客户对a的总体印象)飞行最多。
Spirit Airlines一直主要收到1份评级,这表明在所有考虑的领域中,客户往往对他们的体验感到不满。然而,Spirit Airlines继续增长。这表明需要更多地探索航空公司客户的需求。
总体而言,美国航空业在机舱服务方面做得最好,在地面服务和座椅舒适度方面表现最差(在这些领域里,比任何其他评级都少了5秒)。另外,娱乐评级也很低。
问题3
正面评论中最常出现的词是什么?负面评论?
之前的问题旨在更好地了解航空公司客户对飞行体验(机舱服务,娱乐,食品和饮料,地面服务,座椅舒适度)五个具体方面的看法,但是由于这五个领域没有考虑到所有可能影响客户整体经验,我想分析他们的评论的实际文字。为此,我使用了由R中的“tm”,“wordcloud”和“memoise”软件包组合生成的词云。我分别分析了单个航空公司和整个行业的正面和负面评论。正面评价总体评分为6/10或更高,负面评价为总评分5/10或更差的评价。
以下是整个行业的正面和负面词云:
在正面和负面评论中,“时间”这个词都是最常用的三个词之一。
尽管如此,“座位”和“服务”这两个字仍然出现在前五个词中,因此对前面问题的分析得到了证实。
精神虽然在问题1和问题2中考虑的五个领域中的几乎每一个领域中都是航空公司中最差的,但它有一个负面词云,与其他负面词云不同。也就是说,Spirit的客户仍然在关于延迟和时间的文本评论中抱怨最多,
航空公司的客户写的时间比其他任何事都多,其次是服务和座位。鉴于Spirit Airlines的令人惊讶的发现,节省/浪费时间可能是客户整体飞行评级的预测指标。
结论和未来的方向
尽管影响飞行员乘坐飞机体验的因素有很多,但航空公司可以通过关注航班的几个主要方面 – 特别是时间,座位舒适性和机舱服务,来提高客户满意度。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据

