从广义上讲,我们可以将金融市场状况分为两类:牛市和熊市。
第一个是平稳且通常向上倾斜。第二个描述了一个低迷的市场,通常更不稳定。
可下载资源
在任何特定时刻,我们只能猜测自己所处的状态;因为这两个状态没有统一准确的定义。
在这篇文章中,我们将使用(有限)混合模型来尝试将每日股票收益分配给他们的牛\熊子组。
它本质上是一个无监督的聚类练习。我们创建自己的衰退指标,以帮助我们量化股市。我们使用最少的输入,只使用股票收益数据。从对有限混合模型的简短描述开始,然后给出一个实践的例子。
混合模型
不是每个观察都来自一个定义明确或熟悉的分布,例如高斯,现在的观察来自几个分布的混合。我们可以将两种分布的混合表示为:
![[g(x_i) = \sum_{j=1}^2 \big( \lambda_j f_j(x_i) \big),]](https://img-blog.csdnimg.cn/img_convert/e6110ae62298c277fe1d65475aca8eb2.png "[g(x_i) = \sum_{j=1}^2 \big( \lambda_j f_j(x_i) \big),]")
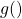 是整体分布,
是整体分布, 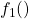 是例如具有一些均值和方差的正态分布,并且
是例如具有一些均值和方差的正态分布,并且 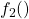 又是一个正态分布,但具有不同的均值和不同的方差。
又是一个正态分布,但具有不同的均值和不同的方差。 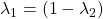 ,这样它们总和为一。所以,
,这样它们总和为一。所以, 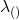 可以解释为来自每个分布的观察的概率。从理论上讲,如果我们有足够的
可以解释为来自每个分布的观察的概率。从理论上讲,如果我们有足够的 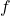 ,这意味着 ,无论在现实中多么复杂或灵活,都可以成功逼近。这是在如此多的应用领域中发现混合模型的原因。
,这意味着 ,无论在现实中多么复杂或灵活,都可以成功逼近。这是在如此多的应用领域中发现混合模型的原因。
R语言中的混合模型
1. 提取一些关于 SPY ,ETF 的数据并转换为每日收益。
da0 <- getSymbol
n <- NROW
dat <- array
prv <- matrix
for (i in 1:l) {
da0 <- getSymbols
w1 <- daiyRern
w0 <- cbind
}
2.使用R进行估算 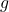 和 的。在下面的代码中
和 的。在下面的代码中 k 是成分数, lambda 是混合比例的初始值。
norEM(w0SPY) summary(mod)
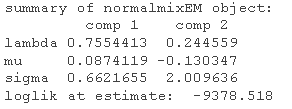
估计的方式是使用EM算法 Expectation–maximization algorithm。我们有两个分布,一个更稳定,波动性较低(~0.66)和正均值(~0.087),另一个分布具有更高的波动性(~2.0)和负均值(~-0.13)。此外,lambda 最终确定 75% 的时间我们处于稳定的环境中,而 25% 的时间观察属于更不稳定的状态。所以有了这个有限的信息集,我们得到了一些相当合理的东西。现在每次观察,您都有该观察来自第一个或第二个分量的后验概率。因此,要真正决定哪个观察属于哪个状态。如果观察结果有更高的概率来自更不稳定的状态,这就是它的类别,对概率进行四舍五入:
reg <- apply( round)
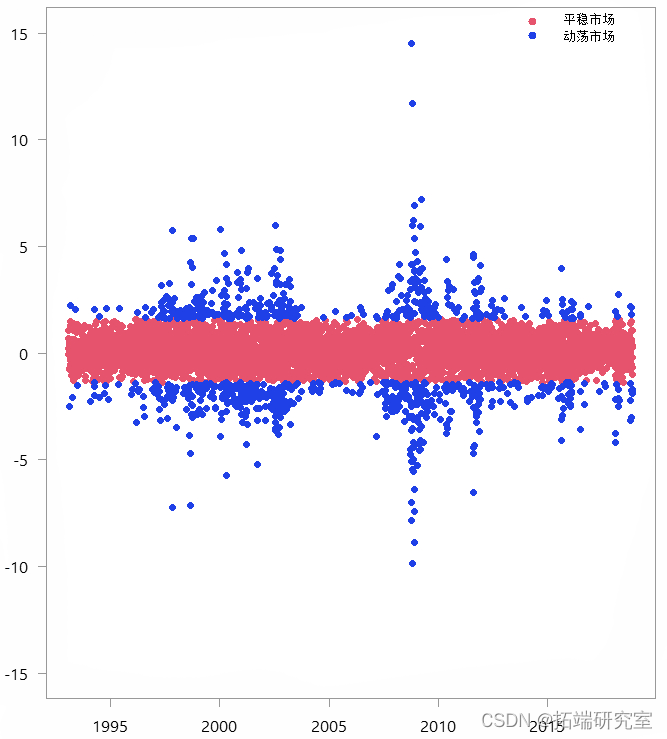
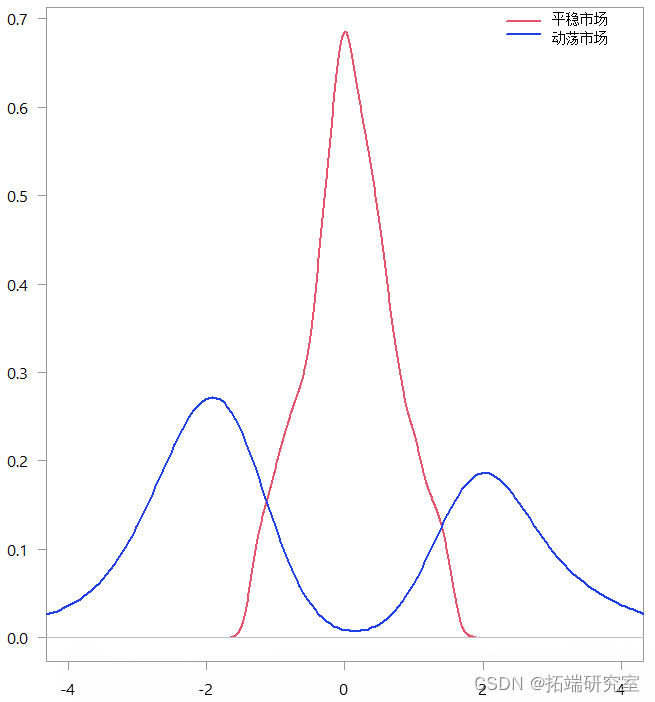
当我们查看分类观察结果时,这两种区制看起来是这样的:
每日 SPY 收益率 (%)

两种状态(区制)的密度估计
随时关注您喜欢的主题
因此,仅基于收益数据,数值算法就创建了这两种区制,非常直观。有了这些知识,我们现在可以创建自己的衰退指标。
创建自己的衰退指标
创建衰退指标的一种方法是计算在某个移动窗口内归类为熊市状态的观察次数。波动性聚类程式化的事实使这个想法变得有意义。我们使用 120 天的移动窗口,并将结果标准化以使所有历史都处于同一基础上。
# # 选择更不稳定的区制 rend <- mo(rege\[, 2\]) %>% scale
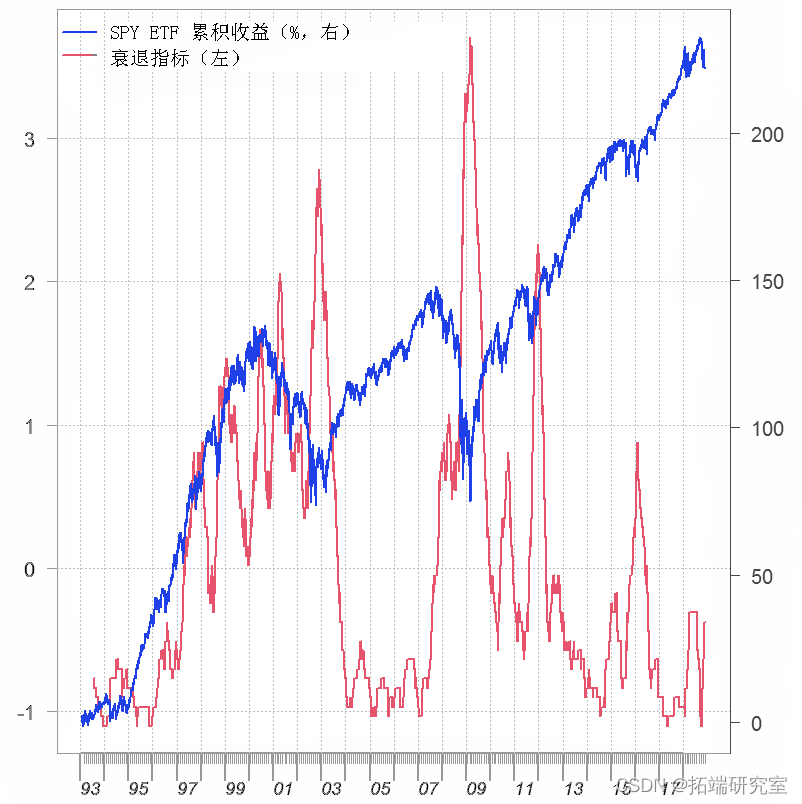
最好在左侧有衰退的可能性。我们可以使用 Sigmoid 映射轻松做到这一点:
reprob <- red %>% sigmoid

上图反映了更现实的情况
基金经理评估我们所处的区制或状态有多困难。将我们的衰退指标与其他更传统的衰退指标进行比较。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python与R语言用XGBOOST、NLTK、LASSO、决策树、聚类分析电商平台评论文本信息数据集
Python与R语言用XGBOOST、NLTK、LASSO、决策树、聚类分析电商平台评论文本信息数据集 Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享
Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享 专题|R语言、SPSS电信客户流失预测实例汇总:KNN、决策树、聚类、RFM分群、挽留策略研究
专题|R语言、SPSS电信客户流失预测实例汇总:KNN、决策树、聚类、RFM分群、挽留策略研究 Python用K-Means聚类、 LRFMC模型对航空公司客户数据价值可视化分析指标应用
Python用K-Means聚类、 LRFMC模型对航空公司客户数据价值可视化分析指标应用
