机器学习算法可用于找到最佳值来交易您的指标。
相对强弱指标(RSI)是最常见的技术指标之一。它用于识别超卖和超买情况。
传统上,交易者希望RSI值超过70代表超买市场状况,而低于30则代表超卖市场状况。但是,这些主张是否有效?为什么70,为什么30?此外,不同的趋势市场如何影响RSI信号?
可下载资源
在本文中,我们将使用一种功能强大的机器学习算法-支持向量机(SVM),在考虑到市场整体趋势的同时,探索您实际需要的RSI值。
首先,我们将简要概述SVM,然后根据算法发现的模式来构建和测试策略。
机器学习和量化交易这个方向是没有问题的,就像无人驾驶,没人会否认将来的某一时间会成功,但终究多久后成功就不好说了。80年代的人工智能或者机器学习从业者们也很高兴,结果由于计算力的限制,坐了几十年冷板凳。
金融或者交易的本质是啥?金融的本质是时间和空间,股价是长期的公司价值和短期的供需 关系共同决定的,后者如同两军博弈,money就是武器。人们对股价的认识不仅取决于未来现金流的折现,还受人们预期的影响,所以超预期通常是涨的。同时,市场也不是独立同分布的,参与投资的人在进化,市场也相应的在进化。
那机器学习的本质是啥,找到一种范式,也就是从大量数据中找到某种规律。某种程度上其不是智能的,随着环境而变化,而是自动化,把工厂的流水线自动化。
金融是要为实体经济服务,满足经济社会发展和人民群众需要,同时防范重大的金融风险。以此为基础,我们探讨一下现行的主要策略的机器学习的用途。
一是基本面,基本面其实有两个流派,一个是价值派,一个是事件驱动派,也就是看新闻炒股派。
首先价值派,是分析财报为基础的,因而诞生很多自动读财报公司。其次,人工智能在价值派里面最重要的用途其实是不规则的数据,比如有人成天蹲在茅台仓库门口查茅台运走了多少箱,一跌就去查,机器做的更好更仔细啊。
其次是看新闻炒股派,极端点叫内幕消息派,实际上内幕消息的影响远不如想象中的大,最重要的是听党的指挥,炒题材。党领导一讲话,就要立即判断出新闻的重要性,哪只股要涨,已经涨了的,还有没空间,这个其实可以预先分类,人工智能也可以做,因为实际投资过程中要开会讨论搞不搞,机器就快多了,真是非常好的题材,就比谁下手快了。
二是趋势派,这里面的鼻祖是里弗莫尔,他把价格和时间结合到了一起,等待关键点,继而一次大的运动,这其实也是最适合散户的操作方法,大部分时间都在等,可以干别的。这其实不仅是关键点位的问题,有可能是假的,要对之前的股票进行监控,就如古代的斥候,撒豆成兵,赛马,看看哪个好,像啥,像不像群体智能,遗传算法啦,PSO啦,都可以搞搞。乃至于模糊数学也可以搞,因为技术分析里面有很多是是而非的东西,用隶属度来表示要比单纯的算数好。
三是短线投机派,极致是高频交易。他的理论依据是短线交易是人可以训练的,或者一种叫做盘感的东西。这个是有实证依据的,既然可以训练人,大幅度重复工作没有比机器更合适的了。
四是另类一点的了,比如券商有大规模的成交单,包括雪球上有组合的成交单,可以直接学习人的成交单。
五是技术派。学习一个K线图形或者模式,模式识别就派上用场了,同花顺有图形选股,如果用神经网络的话有很好的松弛性和泛化性。
六是作为监管科技,比如资金流向,这是央行干的活。如果做空的话,可以拿自己监测到的数据去和他公布的数据比对,揭穿骗局,从而获利。
如果单纯的把所有数据都输入进去,噪音太多,学不好,要提取特征,这里涉及到金融原理和数学知识,单纯的瞎组合也是可以的,效率比较低。但即使不缩减股票本身的数据量很少,美国的数据比中国多得多,但加特征维度很高,就用到降维,典型的是PCA,这个多元分析里有,机器学习里面也有,所以有的老师说机器学习只是在统计的基础上起了好听的名字。还有一个输入是缺失值处理,单纯的填充效果可能不如k近邻方法好。
所以输入问题但从二级市场数据来讲是个小样本高维问题。另外一个输入问题是我们不能仅仅局限于二级市场的数据,要从非结构的难以通过原始人工采集的更好的去衡量公司的价值,比如公司卖多少张电影票。
支持向量机
支持向量机基于其发现非线性模式的能力,是较流行且功能强大的机器学习算法之一。SVM通过找到一条称为“决策边界”或“超平面”的线来工作,该线可以根据类别(在我们的情况下为“看涨”或“看跌”)最好地分离数据。
SVM的强大功能是可以使用一组称为“核”的数学函数将数据重新排列或映射到多维特征空间,在该空间中数据可以线性分离。

然后,SVM在较高维度的空间中绘制一条线,以最大化两个类之间的距离。将新的数据点提供给SVM后,它会计算该点落在线的哪一边并进行预测。
SVM的另一个优点是,在可以使用它之前,必须选择的参数相对较少。首先,您必须选择用于将数据转换到更高维度空间的核或映射功能。径向基函数是一种流行的选择。接下来,您需要选择gamma参数。gamma确定单个训练示例可以对决策边界产生多少影响。较低的值表示单个点将对画线的位置产生较大的影响,而较高的值表示每个点将仅对较小的影响。将gamma参数选择为模型输入数量(1 /(输入数量))是一个经验法则。最后,您需要选择正则化参数C。C确定了训练集中分类错误的示例与决策边界的简单性之间的权衡。低C会创建更平滑的决策边界并减少过度拟合,而高C会尝试正确分类训练集中的每个数据点,并可能导致过度拟合。我们希望减少模型的过拟合量,因此我们将选择一个值1。
现在,我们对支持向量机的工作原理以及如何选择其参数有了基本的了解,让我们看看是否可以使用它来计算如何交易RSI。
交易RSI
相对强弱指标(RSI)将“上涨”移动的平均大小与“下跌”移动的平均大小进行比较,并将其归一化为0到100。传统的逻辑是,一旦股价有更多的,显着的上升趋势,它已经变得超买或被高估,并且价格可能会下降。超买通常由RSI值超过70来确定,相反的情况表示RSI值为30时出现超卖或低估。
在强劲的上升趋势中,RSI值超过70可能表示趋势的延续,而在下降趋势期间的RSI值70可能意味着一个很好的切入点。问题是要找出要考虑这两个因素的确切条件。
我们可以收集成千上万个数据点,然后尝试自己找到这些关系,也可以使用支持向量机为我们完成工作。
让我们看看我们可以使用AUD / USD 每小时数据将开盘价与50期简单移动平均线(SMA)比较,从而在3期RSI中找到模式并定义趋势。
加载历史价格。
#*****************************************************************
# 载入历史数据
#******************************************************************
AUDUSD = read.xts('AUDUSD.csv', format='%m/%d/%y %H:%M', index.class = c("POSIXlt", "POSIXt"))
建立模型
使用R建立我们的模型,分析它能够找到的模式,然后进行测试以查看这些模式在实际的交易策略中是否成立。
创建指标并训练SVM:
#*****************************************************************
# 代码策略
#******************************************************************
load.packages('e1071,ggplot2')
indicators = as.xts(list(
RSI3 = RSI(Cl(AUDUSD), 3),
SMA50 = SMA(Op(data$AUDUSD), 50)
# 删除缺失
DataSet = DataSet[-(1:49),]
#将数据分为60%的训练集以构建模型,20%的测试集以测试我们发现的模型,以及20%的验证集将我们的策略应用于新的数据
Training = DataSet[1:4528,]
#使用径向基函数作为核,将成本或C设置为1,构建支持向量机
svm(
data=Training,
kernel="radial",
cost=1,gamma=1/2)
#在训练集中再次运行算法以可视化找到的模型
predict(SVM,Training,type="class")
# 绘图
ggplot(TrainingData, aes(x=Trend,y=RSI3))

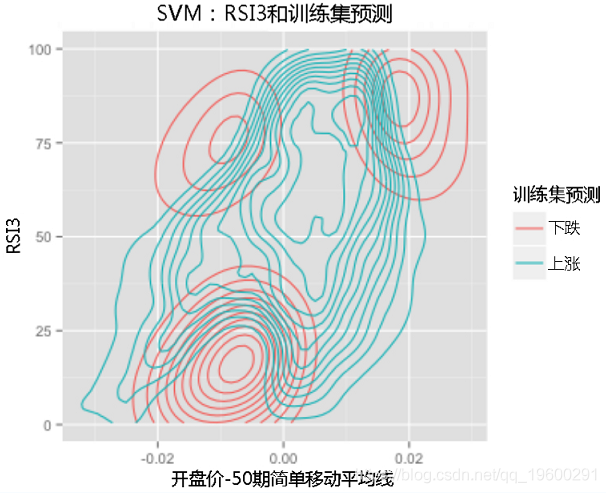
我们可以看到算法在三个不同的区域预测空头,而在中间的一个区域预测多头。
让我们进一步探索。
| 多头 | 空头 |
|---|---|
| RSI低于25,价格比SMA 50低20(准确度为56%,交易36次) | RSI小于25,且价格比SMA 50低10至5个点(准确度为54%,交易81次) |
| RSI3在50到75之间,价格比SMA 50高5到10个点之间(准确度为58%,交易104) | RSI大于70,价格比SMA 50低5个点以上(准确度为59%,交易37次) |
| RSI大于75,价格比SMA 50高出15个点(准确度为59%,交易34次) |
随时关注您喜欢的主题
首先是左下角区域。在这里,价格刚刚跌破50期SMA,RSI跌破25,表明跌势突破。
但是,如果价格跌破50周期SMA下方20个点,而RSI仍低于25点,则该算法会发现有较强的信号可以转换为均值,并预测多头交易。
接下来,图左上方的短暂机会代表了RSI的传统观点。我们希望RSI超过70,而价格比50周期均线高出15点以上,以表示“超买”情况,这表明我们做空了。
左上方的区域有些不同。当价格刚刚跌破50期SMA以下且RSI超过70时,它发现了一个短暂的机会。这与第一种情况相似,但我们正在寻找看跌突破进入信号,而不是传统的“超买”条件。
最终,存在一个区域的RSI在50到75之间,而价格已经超过了50期均线,该算法发现了强烈的买入信号。
现在,我们找到了SVM发现的一组基本规则,让我们测试一下它们对新数据(测试集)的支持程度。
# 我们找到了SVM发现的一组基本规则,测试一下它们在新数据(测试集)的正确程度。
# 模式在测试集中的表现:
sum(ShortTrades$Direction == -1)/nrow(ShortTrades)*100
[1] 57.82313
sum(LongTrades$Direction ==1)/nrow(LongTrades)*100
[1] 57.14286
我们的空头交易为58%(147笔交易中的85笔正确),而我们的多头交易为57%(140笔交易中的80笔正确)。
使用支持向量机(一种功能强大的机器学习算法),我们不仅能够了解RSI的传统知识在什么条件下成立,而且还能够创建可靠的交易策略。
此过程称为从机器学习算法中得出规则,使您可以结合自己的交易经验来使用机器学习算法。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 Python糖尿病数据分析:深度学习、逻辑回归、K近邻、决策树、随机森林、支持向量机及模型优化训练评估选择
Python糖尿病数据分析:深度学习、逻辑回归、K近邻、决策树、随机森林、支持向量机及模型优化训练评估选择
