
最近我们被客户要求撰写关于预测股票的研究报告,只要有金融经济学家,金融经济学家一直在寻找能够预测股票收益的变量。
对于最近的一些例子,想想Jegadeesh和Titman(1993)表明股票的当前收益是由前几个月的股票收益预测的。
可下载资源
Hou(2007)表明一个行业中最小股票的当前回报是通过行业中最大股票的滞后回报预测,以及Cohen和Frazzini(2008)表明股票的当前回报是由其主要客户的滞后回报预测的。
在金融行业中用于拟合广义线性模型的 LASSO 回归就是其中之一。
LASSO 回归的特点是在拟合广义线性模型的同时进行变量筛选(variable selection)和复杂度调整(regularization)。 因此,不论目标因变量(dependent/response varaible)是连续的(continuous),还是二元或者多元离散的(discrete),都可以用 LASSO 回归建模然后预测。 这里的变量筛选是指不把所有的变量都放入模型中进行拟合,而是有选择的把变量放入模型从而得到更好的性能参数。 复杂度调整是指通过一系列参数控制模型的复杂度,从而避免过度拟合(overfitting)。 对于线性模型来说,复杂度与模型的变量数有直接关系,变量数越多,模型复杂度就越高。 更多的变量在拟合时往往可以给出一个看似更好的模型,但是同时也面临过度拟合的危险。此时如果用全新的数据去验证模型(validation),通常效果很差。 一般来说,变量数大于数据点数量很多,或者某一个离散变量有太多独特值时,都有可能过度拟合。
LASSO 回归复杂度调整的程度由参数 来控制, 越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。 LASSO 回归与 Ridge 回归同属于一个被称为 Elastic Net 的广义线性模型家族。 这一家族的模型除了相同作用的参数 之外,还有另一个参数 来控制应对高相关性(highly correlated)数据时模型的性状。 LASSO 回归 ,Ridge 回归 ,一般 Elastic Net 模型 0<α<1。
目前最好用的拟合广义线性模型的 R package 是 glmnet,由 LASSO 回归的发明人,斯坦福统计学家 Trevor Hastie 领衔开发。 它的特点是对一系列不同 值进行拟合,每次拟合都用到上一个 值拟合的结果,从而大大提高了运算效率。 此外它还包括了并行计算的功能,这样就能调动一台计算机的多个核或者多个计算机的运算网络,进一步缩短运算时间。
使用LASSO预测收益
1.示例
两步流程。当你考虑时,找到这些变量实际上包括两个独立的问题,识别和估计。首先,你必须使用你的直觉来识别一个新的预测器,然后你必须使用统计来估计这个新的预测器的质量:
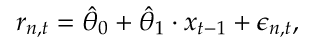
但是,现代金融市场庞大。可预测性并不总是发生在易于人们察觉的尺度上,使得解决第一个问题的标准方法成为问题。例如,联邦信号公司的滞后收益率是2010 年10月一小时内所有纽约证券交易所上市电信股票的重要预测指标。你真的可以从虚假的预测指标中捕获这个特定的变量吗?
2.使用LASSO
LASSO定义。LASSO是一种惩罚回归技术,在Tibshirani(1996)中引入。它通过投注稀疏性来同时识别和估计最重要的系数,使用更短的采样周期 – 也就是说,假设在任何时间点只有少数变量实际上很重要。正式使用LASSO意味着解决下面的问题,如果你忽略了惩罚函数,那么这个优化问题就只是一个OLS回归。
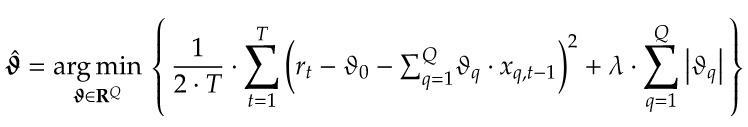
惩罚函数。
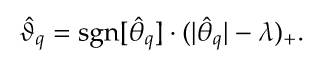
但是,这个惩罚函数是LASSO成功的秘诀,允许估算器对最大系数给予优先处理,完全忽略较小系数。为了更好地理解LASSO如何做到这一点,当右侧变量不相关且具有单位方差时 。一方面,这个解决方案意味着,如果OLS估计一个大系数,那么LASSO将提供类似的估计。另一方面,解决方案意味着,如果OLS估计了足够小的系数,那么LASSO将会选择。因为LASSO可以将除少数系数之外的所有系数设置为零,即使样本长度比可能的预测变量的数量短得多,它也可用于识别最重要的预测变量。如果只有预测变量非零,那么你应该只需要几个 观察选择然后估计这几个重要系数的大小。
3.模拟分析
我运行模拟来展示如何使用LASSO来预测未来的回报。您可以在文末找到所有相关代码。
数据模拟。每次模拟都涉及为期间的股票产生回报。每个时期,所有股票的回报都受到一部分股票的回报,以及特殊冲击的影响
使模型拟合数据。这意味着使用时间段来估计具有潜在变量的模型。我估计了一个OLS回归真正的预测因子是右侧变量。显然,在现实世界中,你不知道真正的预测变量是什么,但是这个规范给出了你可以达到的最佳拟合的估计。在将每个模型拟合到先前的数据之后,然后我在st期间进行样本外预测。
预测回归。然后,我通过分析一系列预测回归分析调整后的统计数据,检查这些预测与第一个资产的实现回报的紧密程度。例如,我将LASSO的回报预测用于估算下面的回归
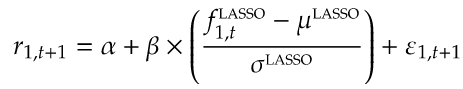
4.调整参数
惩罚参数选择。使LASSO拟合数据涉及选择惩罚参数。我这样做是通过选择在数据的第一个时段期间具有最高样本外预测的惩罚参数。这就是为什么上面的预测回归仅使用从而不是使用数据开始的原因。下图显示了模拟中惩罚参数选择的分布。

预测数量。最后,如果你看一下调整后数字中标有“Oracle”的面板,你会发现LASSO的样本外预测能力大约是真实模型预测能力的三分之一。这是因为LASSO没有完美地选择稀疏信号。下图的右侧面板显示LASSO通常只选出这些信号中最重要的信号。更重要的是,左侧面板显示LASSO还锁定了大量的虚假信号。这一结果表明,您可以通过选择更高的惩罚参数来提高LASSO的预测能力。
5.什么时候失败?
测试。我通过研究两个模拟来结束这篇文章,其中LASSO不应该增加任何预测能力。也就是说,使用下面的模型模拟股票的收益,
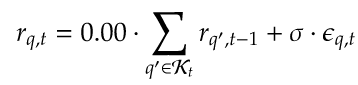
下图显示,在这两种情况下,LASSO都不会增加任何预测能力。因此,运行这些模拟提供了一对不错的测试,显示LASSO确实在返回的横截面中拾取稀疏信号。
obj.gg2.PLOT <- obj.gg2.PLOT + scale_y_continuous(limits = c(0, 0.40),
breaks = c(0, 0.10, 0.20, 0.30, 0.40),
labels = c("$0.00$","$0.10$", "$0.20$", "$0.30$", "$0.40$")
)
obj.gg2.PLOT <- obj.gg2.PLOT + theme(plot.margin = unit(c(1,0.15,-0.85,0.15), "lines"),
axis.text = element_text(size = 10),
axis.title = element_text(size = 10),
plot.title = element_text(vjust = 1.75),
panel.grid.minor = element_blank(),
legend.position = "none"
)
obj.gg2.PLOT <- obj.gg2.PLOT + ggtitle("Adjusted $R^2$ Distribution: Dense Shocks")
print(obj.gg2.PLOT)
dev.off()随时关注您喜欢的主题
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python与Ollama、LangGraph本地小语言模型智能体构建:ReAct推理与工具集成|附代码数据
Python与Ollama、LangGraph本地小语言模型智能体构建:ReAct推理与工具集成|附代码数据 Python与HermesAgent多工具协同的自托管智能自动化工作流构建研究|附配置代码
Python与HermesAgent多工具协同的自托管智能自动化工作流构建研究|附配置代码 Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码
Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码 Python用XGBoost、梯度提升树、Lasso与极端随机树ETR功率变换器磁芯损耗建模及SLSQP优化 | 附数据代码
Python用XGBoost、梯度提升树、Lasso与极端随机树ETR功率变换器磁芯损耗建模及SLSQP优化 | 附数据代码

