当线性假设无法满足时,可以考虑使用其他方法。
在标准线性模型中,我们假设
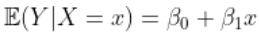
。当线性假设无法满足时,可以考虑使用其他方法。
可下载资源
多项式回归
扩展可能是假设某些多项式函数,
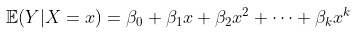
同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 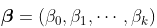
可以使用最小二乘法获得,其中
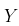
在
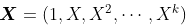
。
local likelihood and other models
局部回归和变系数模型的概念很广:任何参数模型,只要拟合方法中为观测点添加了权重均是。
这一节讲了局部似然,
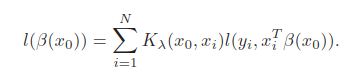
右边的 是
发生的概率。使用局部似然时,仍然只是估计某个点,如上面只估计
,要估计其它要重复局部似然过程。局部似然指只用了局部的点
的概率最大来进行参数估计。
kernel density estimation and classification
核密度估计是一种非监督学习。历史上发生在核回归之前,且还引出了一些非参数分类方法。
[1]核密度估计
从分布为 抽取 N 个样本
,想要估计
的值,一个自然的想法是看
,#表示数量,但样本中极可能没有重复的
,此时用到核的思想,认为
周围的点和
发生概率相同,于是,
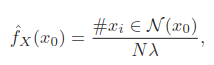
表示窗宽。
这个方法估计的函数会是崎岖的,于是正式用核,称为Parzen estimate,
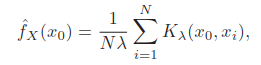
高斯核 是很流行的,
是均值,
是标准差,里面相当于在做标准化,代入进去为,
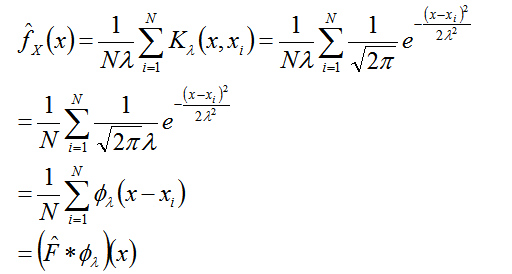
卷积的数学定义为, ,注意是对
积分。概率中为,
,则
经验分布函数, 。但上面的
是一个随机变量,概率均为1/N
从卷积看出 是使用高斯噪声对经验分布函数进行平滑化。
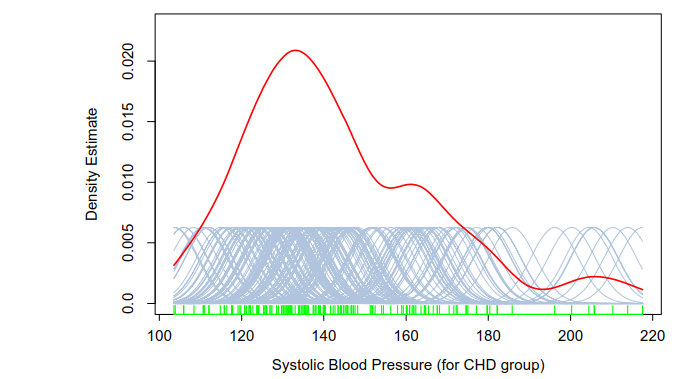
一个高斯核的密度估计例子,
更高维时,
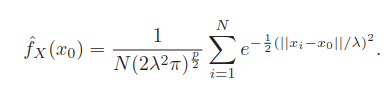
[2]核密度分类
对每个类别都拟合一个密度估计, ,j表示不同类别。先验概率估计
,直接使用样本的类别比例即可。则
为类别 j 的概率为,
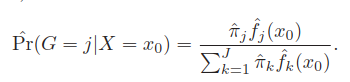
取个最大的即为预测类别。
说明下下图,
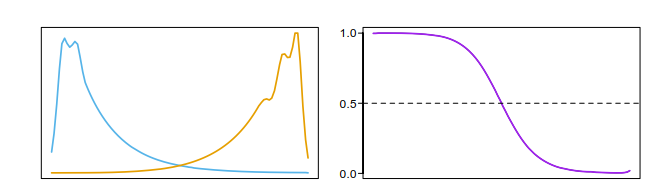
左边是两类别的核密度估计,右边是判为类蓝的概率。从 取值左到右判为类蓝的概率逐渐减小,这可以从左图的密度估计中看出,也在右图表现出来了。但类蓝的峰处有个小谷,这里虽然会判为类蓝,但概率理应有所跳动,然而在右图却没有表现出来。这也是这个方法的一个缺点。
当然仅仅为了分类,直接获得分类边界可能预测正确的类别即可,这个方法还是较好的。
[3]朴素贝叶斯分类
可用于维度高的数据。这个方法假设所有属性相互独立,
仍然表示为 j 类的核密度估计。计算时分别计算每个
;若有变量
是离散的,使用直方图进行密度估计。
显然这个假设过于乐观,但实际中这个方法却经常很有效。原因可看图6.15,虽然每个类别的密度估计可能是有偏的,这个偏差却不怎么影响后验概率,尤其是在决策边界,看图6.15左图的两类的交叉处。
得到各类的核密度估计后,就可以得到决策边界,
形式和广义加性模型一样。朴素贝叶斯和广义加性模型的关系类似于LDA和逻辑回归的关系。
radial basis functions and kernels(径向基函数和核)
看到本节标题,基函数和核,即使用核做为基函数。这样既转换了数据空间(基函数)又使用了局部化(核),
注意左边为 ,也就是说这不是非参数的核平滑方法,不是像上面一样逐个计算预测点的模型。
分别是位置参数,
形状参数。要估计的参数为
目标函数为,
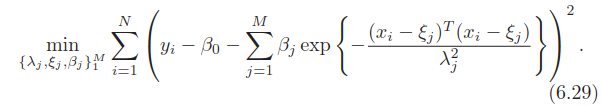
这实际是径向基函数网络的目标函数,是非凸的,有很多极小值点,训练方法和其它神经网络类似。
利用 X 的分布使用非监督方式选择 ,使用最小二乘计算
。其中可以使用混合高斯密度模型训练
局部获得
;还可以使用聚类方法决定
,
则作为聚类方法的超参数,在结果中获得。
这些方法的缺点是仅利用 X 无法准确确定 的集中处,所以上面的位置形状参数都可能是有问题的。
一个减少参数的想法是假定 均为常数,但这会有副作用,即产生洞,如下图中的上部分。解决办法是重标准化径向基函数,
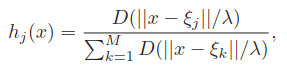
下图的下部分,
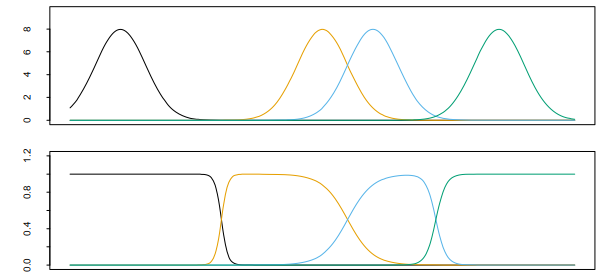
前面的N-W核回归估计也可看作重标准的径向基函数的扩展,
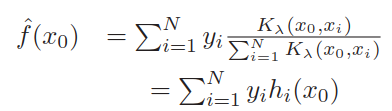
是径向基函数,
8.mixture models for density estimation and classification
直接看看式子,
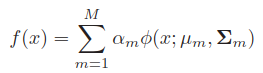
其中 ,后面为高斯分布,为高斯混合模型,x为高维的,则为多元高斯分布。当然后面也可以是其它分布。下标 m 是类别的意思。
使用MLE进行参数估计,使用EM算法进行计算。
类别概率,观察 i 分为 m 类的概率为,
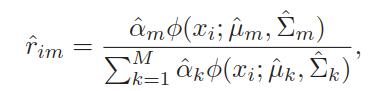
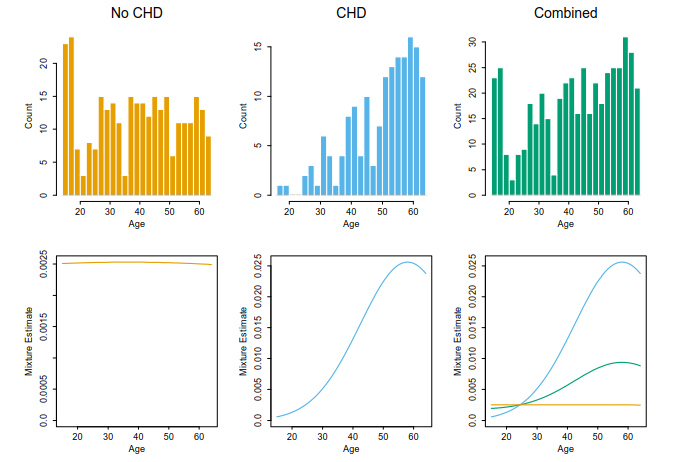
分别对每一类进行密度估计,然后合并。
即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 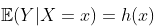
。实际上,根据 Stone-Weierstrass定理,如果
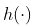
在某个区间上是连续的,则有一个统一的近似值

,通过多项式函数。
仅作说明,请考虑以下数据集
db = data.frame(x=xr,y=yr)
plot(db)
与标准回归线

与标准回归线
reg = lm(y ~ x,data=db)
abline(reg,col="red")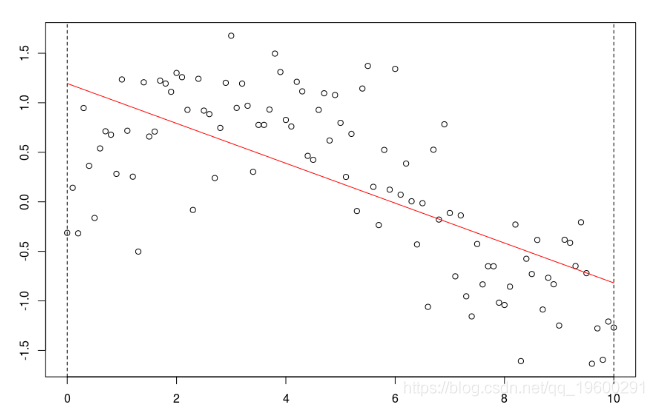
考虑一些多项式回归。如果多项式函数的次数足够大,则可以获得任何一种模型,
reg=lm(y~poly(x,5),data=db)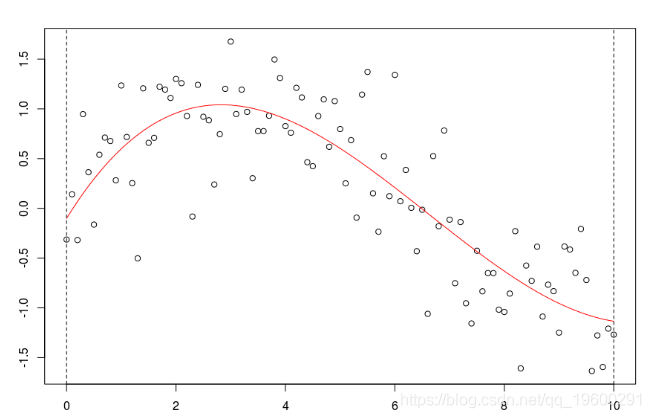
但是,如果次数太大,那么会获得太多的“波动”,
reg=lm(y~poly(x,25),data=db)
并且估计值可能不可靠:如果我们更改一个点,则可能会发生(局部)更改
yrm=yr;yrm[31]=yr[31]-2
lines(xr,predict(regm),col="red") 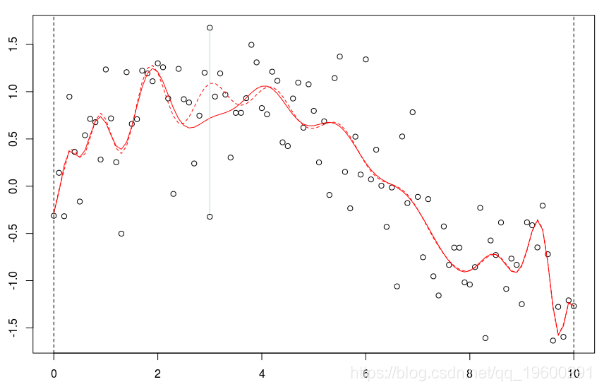
局部回归
实际上,如果我们的兴趣是局部有一个很好的近似值 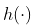
,为什么不使用局部回归?
使用加权回归可以很容易地做到这一点,在最小二乘公式中,我们考虑
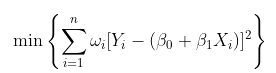
- 在这里,我考虑了线性模型,但是可以考虑任何多项式模型。在这种情况下,优化问题是
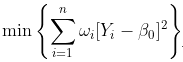
可以解决,因为
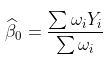

例如,如果我们想在某个时候进行预测 , 考虑 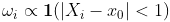
。使用此模型,我们可以删除太远的观测值,
更一般的想法是考虑一些核函数 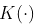
给出权重函数,以及给出邻域长度的一些带宽(通常表示为h),

这实际上就是所谓的 Nadaraya-Watson 函数估计器 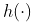
。
在前面的案例中,我们考虑了统一核 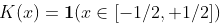
,
但是使用这种权重函数具有很强的不连续性不是最好的选择,尝试高斯核,
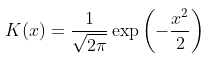
这可以使用
随时关注您喜欢的主题
w=dnorm((xr-x0))
reg=lm(y~1,data=db,weights=w) 在我们的数据集上,我们可以绘制
w=dnorm((xr-x0))
plot(db,cex=abs(w)*4)
lines(ul,vl0,col="red")
axis(3)
axis(2)
reg=lm(y~1,data=db,weights=w)
u=seq(0,10,by=.02)
v=predict(reg,newdata=data.frame(x=u))
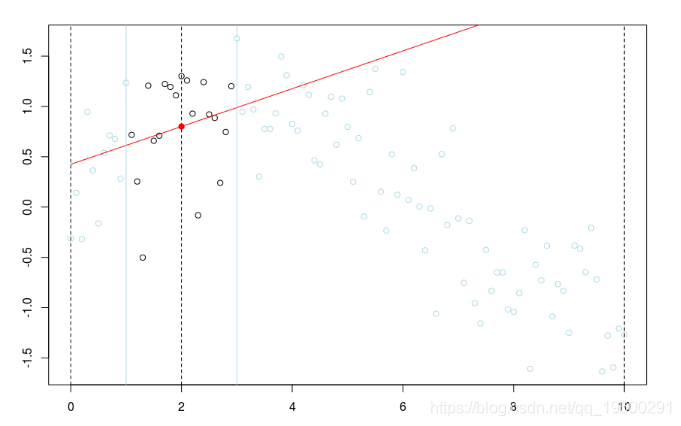
lines(u,v,col="red",lwd=2) 在这里,我们需要在点2进行局部回归。下面的水平线是回归(点的大小与宽度成比例)。红色曲线是局部回归的演变
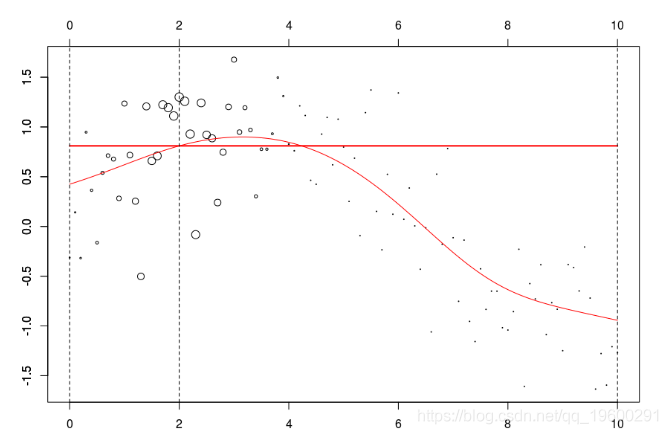
让我们使用动画来可视化曲线。
但是由于某些原因,我无法在Linux上轻松安装该软件包。我们可以使用循环来生成一些图形
name=paste("local-reg-",100+i,".png",sep="")
png(name,600,400)
for(i in 1:length(vx0)) graph (i)然后,我使用
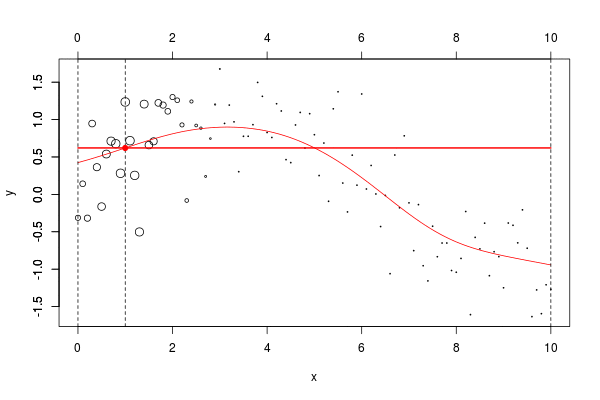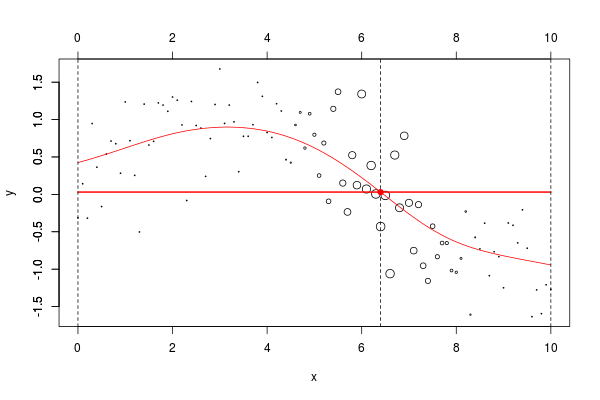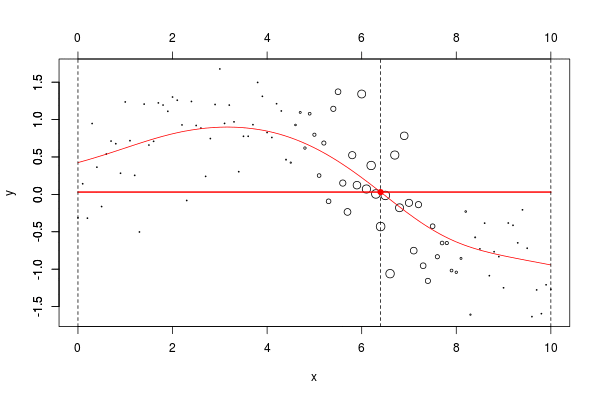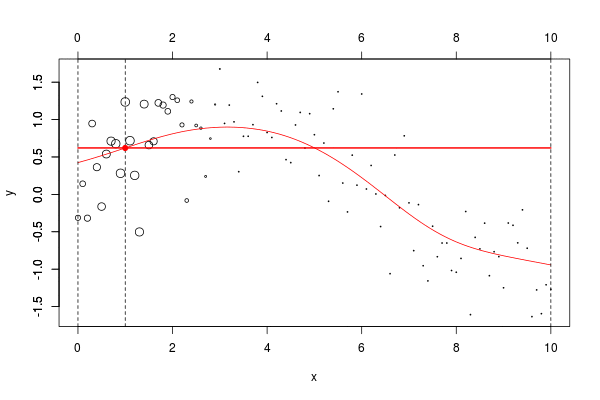
当然,可以考虑局部线性模型,
return(predict(reg,newdata=data.frame(x=x0)))}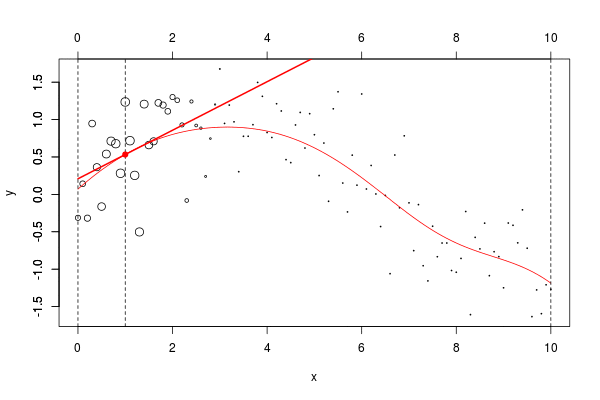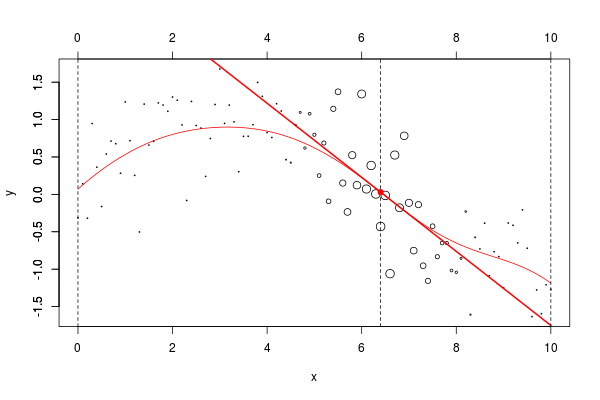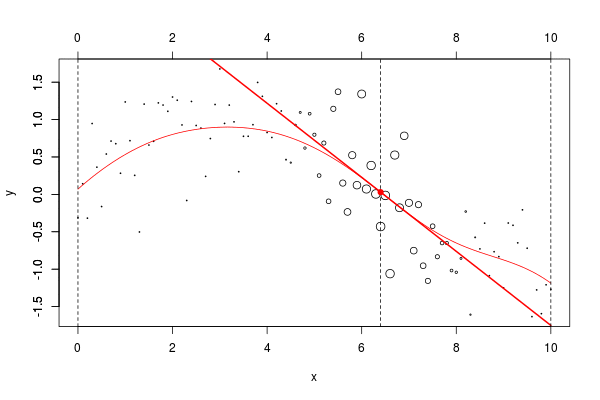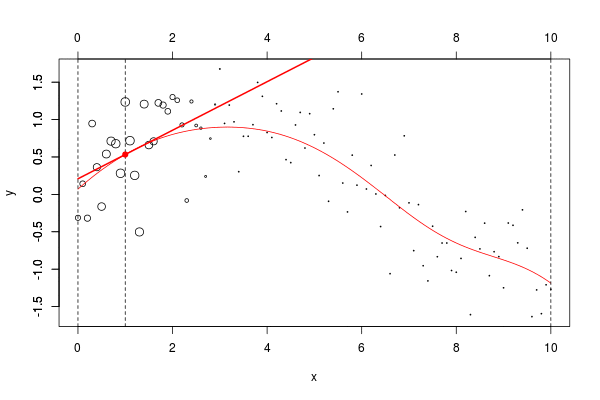
甚至是二次(局部)回归,
lm(y~poly(x,degree=2), weights=w) 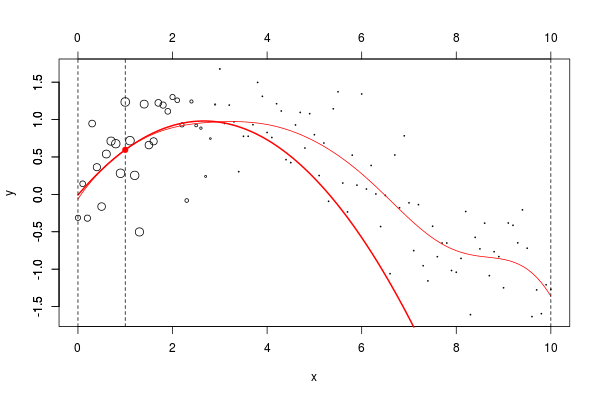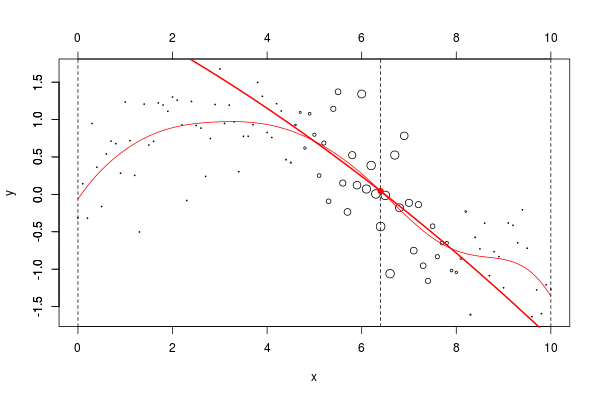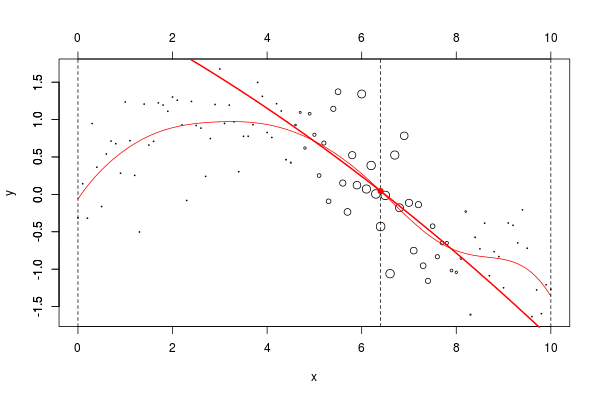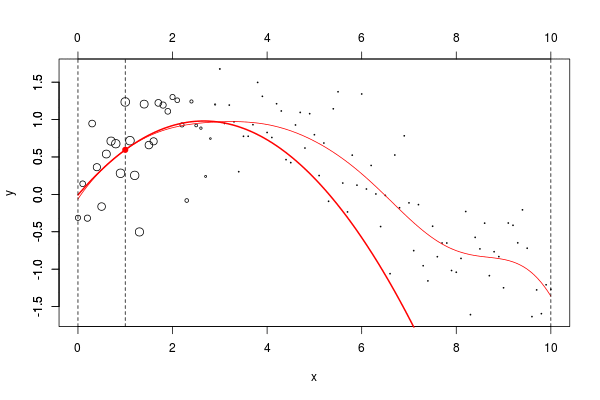
当然,我们可以更改带宽
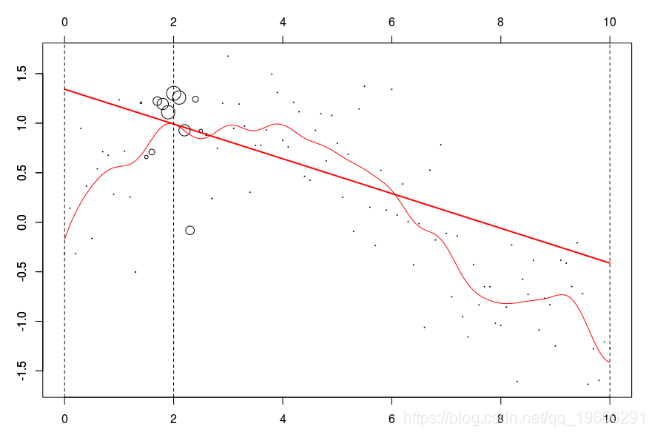
请注意,实际上,我们必须选择权重函数(所谓的核)。但是,有(简单)方法来选择“最佳”带宽h。交叉验证的想法是考虑
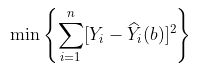

是使用局部回归获得的预测。
我们可以尝试一些真实的数据。
library(XML)
data = readHTMLTable(html) 整理数据集,
plot(data$no,data$mu,ylim=c(6,10))
segments(data$no,data$mu-1.96*data$se, 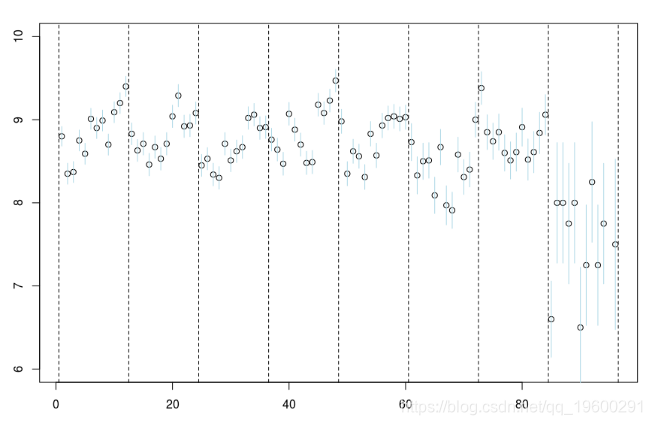
我们计算标准误差,反映不确定性。
for(s in 1:8){reg=lm(mu~no,data=db,
lines((s predict(reg)[1:12]
所有季节都应该被认为是完全独立的,这不是一个很好的假设。
smooth(db$no,db$mu,kernel = "normal",band=5)
我们可以尝试查看带宽较大的曲线。
db$mu[95]=7
plot(data$no,data$mu
lines(NW,col="red")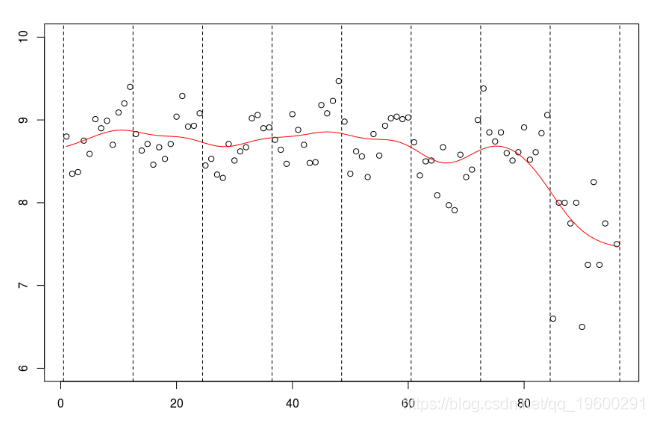
样条平滑
接下来,讨论回归中的平滑方法。假设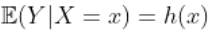
,
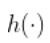
是一些未知函数,但假定足够平滑。例如,假设
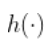
是连续的,
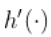
存在,并且是连续的,
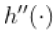
存在并且也是连续的等等。如果
足够平滑, 可以使用泰勒展开式。 因此,对于

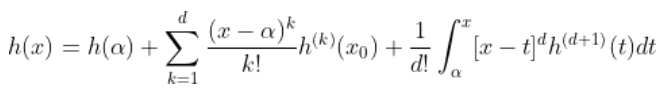
也可以写成
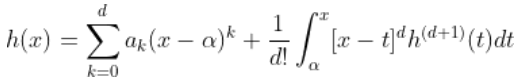
第一部分只是一个多项式。
使用 黎曼积分,观察到
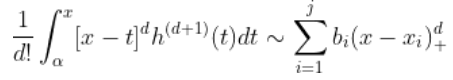
因此,
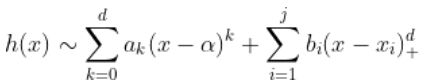
我们有线性回归模型。一个自然的想法是考虑回归 ,对于
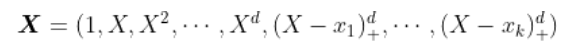
给一些节点 。
plot(db)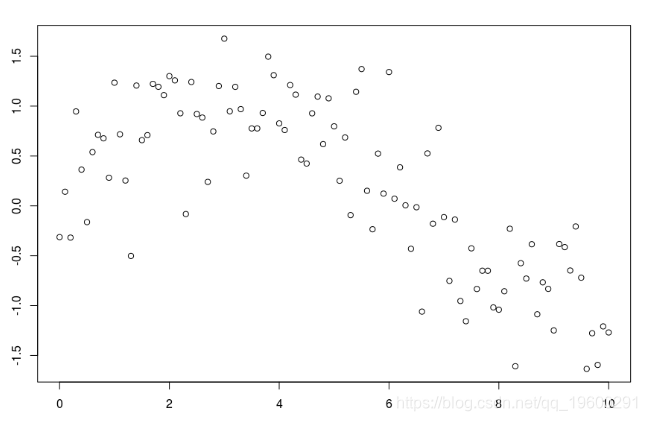
B=bs(xr,knots=c(3),Boundary.knots=c(0,10),degre=1)
lines(xr[xr<=3],predict(reg)[xr<=3],col="red")
lines(xr[xr>=3],predict(reg)[xr>=3],col="blue")可以将用该样条获得的预测与子集(虚线)上的回归进行比较。
如果我们考虑一个节点,并扩展阶数1,
lines(xr[xr<=3],predict(reg)[xr<=3
lm(yr~xr,subset=xr>=3) 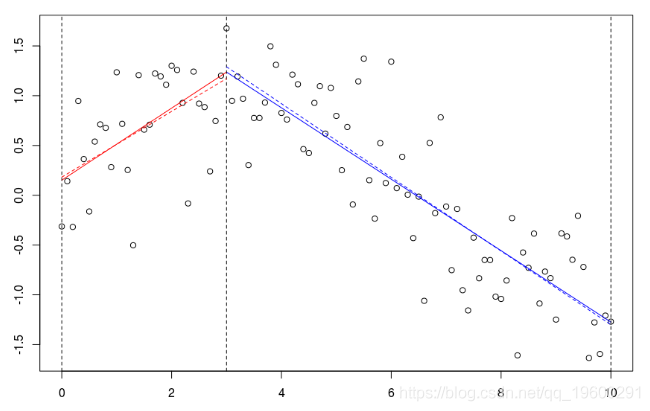
这是不同的,因为这里我们有三个参数(关于两个子集的回归)。当要求连续模型时,失去了一个自由度。观察到可以等效地写
lm(yr~bs(xr,knots=c(3),Boundary.knots=c(0,10) 回归中出现的函数如下
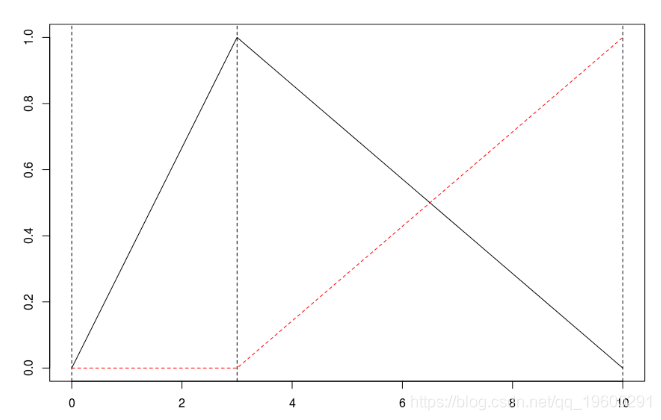
matplot(xr,B
abline(v=c(0,2,5,10),lty=2)如果加一个节点,我们得到

现在,如果我们对这两个分量进行回归,我们得到
预测是
lines(xr,predict(reg),col="red")
我们可以选择更多的节点
lines(xr,predict(reg),col="red")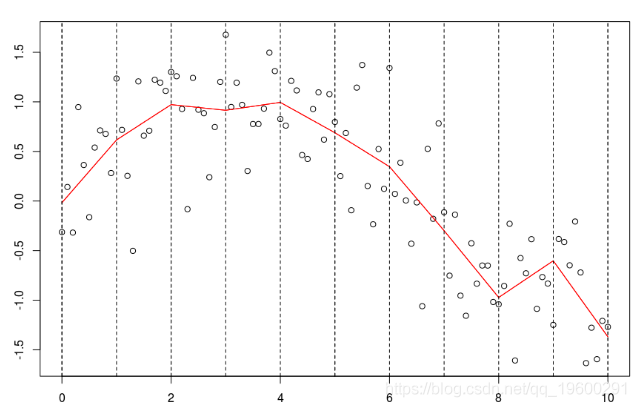
我们可以得到一个置信区间
polygon(c(xr,rev(xr)),c(P[,2],rev(P[,3]))
points(db) 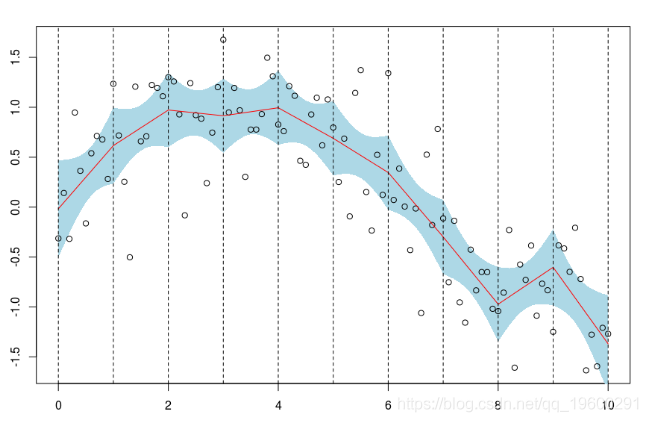
matplot(xr,B,type="l")
abline(v=c(0,2,5,10),lty=2)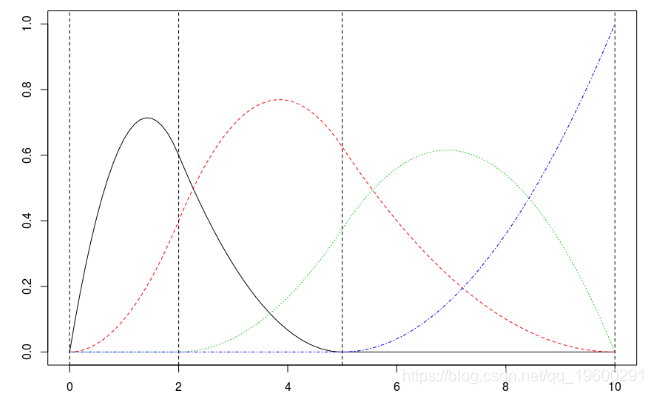
如果我们保持先前选择的两个节点,但考虑泰勒的2阶的展开,我们得到
如果我们考虑常数和基于样条的第一部分,我们得到
B=cbind(1,B)
lines(xr,B[,1:k]%*%coefficients(reg)[1:k],col=k-1,lty=k-1)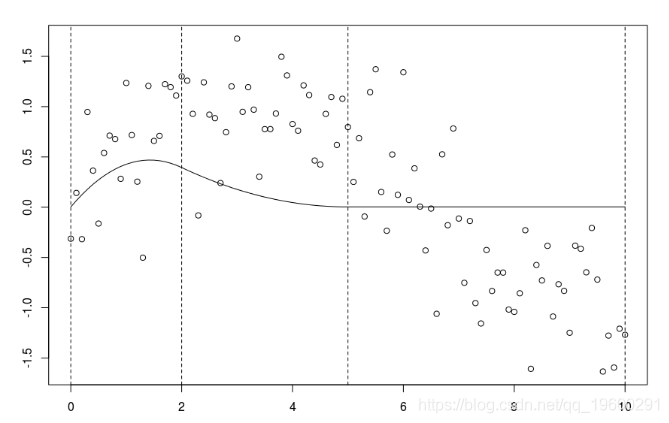
如果我们将常数项,第一项和第二项相加,则我们得到的部分在第一个节点之前位于左侧,
k=3
lines(xr,B[,1:k]%*%coefficients(reg)[1:k]
lines(xr,B[,1:k]%*%coefficients(reg)[1:k] 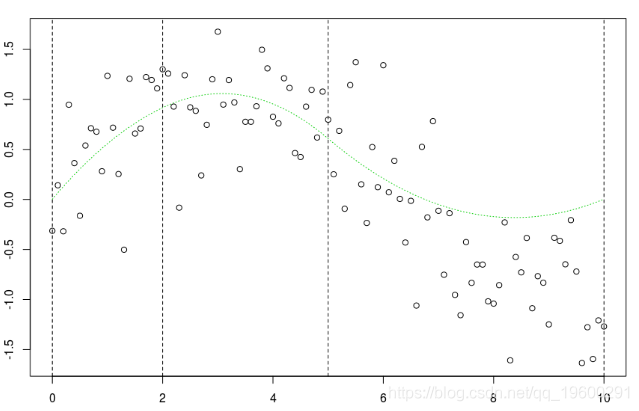
通过基于样条的矩阵中的三个项,我们可以得到两个节点之间的部分,
最后,当我们对它们求和时,这次是最后一个节点之后的右侧部分,
k=5 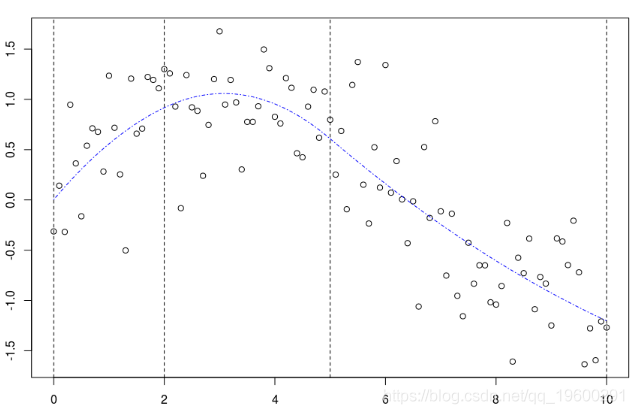
这是我们使用带有两个(固定)节点的二次样条回归得到的结果。可以像以前一样获得置信区间
polygon(c(xr,rev(xr)),c(P[,2],rev(P[,3]))
points(db)
lines(xr,P[,1],col="red") 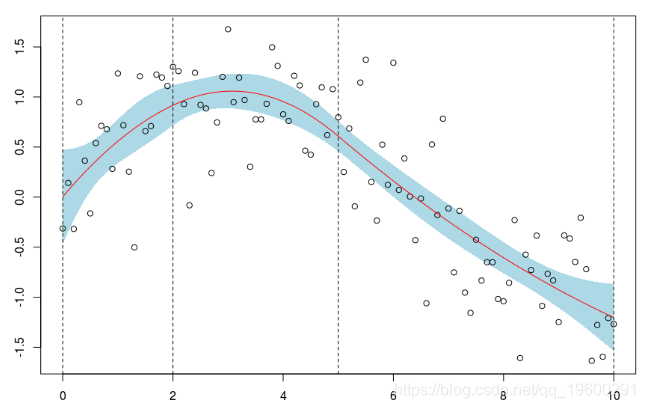
使用函数 ,可以确保点的连续性
。
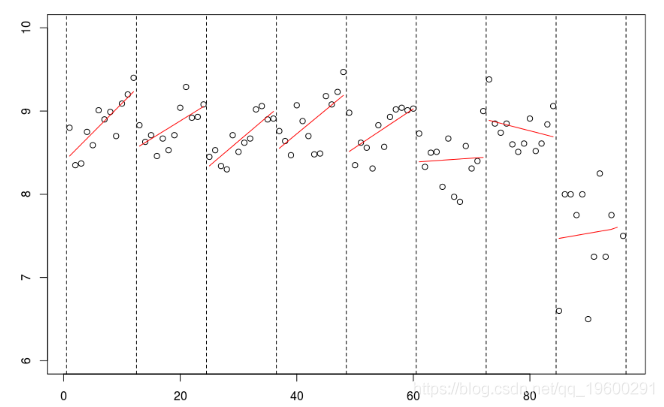
再一次,使用线性样条函数,可以增加连续性约束,
lm(mu~bs(no,knots=c(12*(1:7)+.5),Boundary.knots=c(0,97),
lines(c(1:94,96),predict(reg),col="red")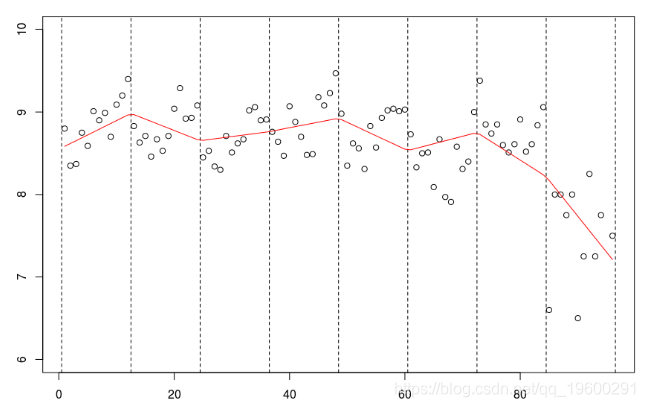
但是我们也可以考虑二次样条,
abline(v=12*(0:8)+.5,lty=2)
lm(mu~bs(no,knots=c(12*(1:7)+.5),Boundary.knots=c(0,97), 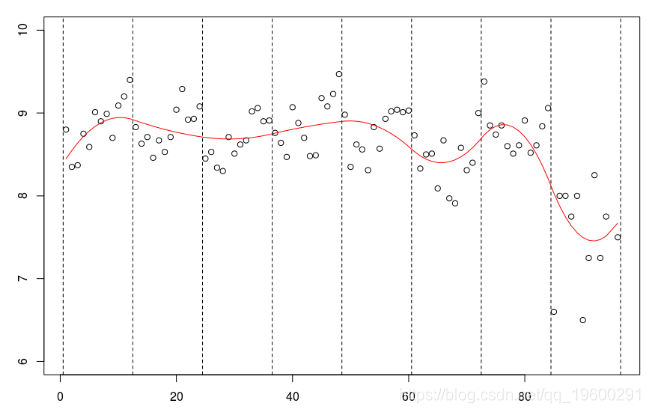
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究 Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究
Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究 Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享
Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享 R软件线性模型与lmer混合效应模型对生态学龙类智力测试数据层级结构应用
R软件线性模型与lmer混合效应模型对生态学龙类智力测试数据层级结构应用


