本文使用的数据集记录了 1236 名新生婴儿的体重,以及他们母亲的其他协变量。
最近我们被客户要求撰写关于线性模型的研究报告,本研究的目的是测量吸烟对新生儿体重的影响。
研究人员需要通过控制其他协变量(例如母亲的体重和身高)来隔离其影响。
可下载资源
这可以通过使用多元回归模型来完成,例如,通过考虑权重 Y_i 可以建模为
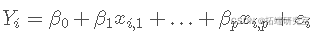
Y\_i = beta\_0 + beta\_1 x\_{i,1} + ldots + beta\_p x\_{i,p} + varepsilon_i
str(babis)
视频
线性混合效应模型(LMM,Linear Mixed Models)和R语言实现案例
视频
非线性模型原理与R语言多项式回归、局部平滑样条、 广义相加模型GAM分析

数据集的描述如下:
bwt是因变量,新生儿体重以盎司为单位。数据集使用 999 作为缺失值。gestation是怀孕的时间,以天为单位。999 是缺失值的代码。parity第一胎使用 0,否则使用 1,缺失值使用 9。age是母亲的年龄,整数。99 是缺失值。height是母亲的身高。99 是缺失值。weight是母亲的体重,以磅为单位。999 是一个缺失值。smoke是一个分类变量,表示母亲现在是否吸烟 (1) (0)。9 是缺失值。
这个问题的研究人员想要判断以下内容:
- 吸烟的母亲会增加早产率。
- 吸烟者的新生儿在每个胎龄都较小。
- 与母亲的孕前身高和体重、产次、既往妊娠结局史或婴儿性别(这最后两个协变量不可用)相比,吸烟似乎是出生体重的一个更重要的决定因素。
我们将专注于第二个判断
从str()命令中注意到,所有的变量都被存储为整数。我将把缺失值转换为NAs,这是R中缺失值的正确表示。
bwt == 999\] <- NA # 有多少观察结果是缺失的? sapply(babies, couna)

每当您在 R 中使用函数时,请记住,默认情况下它可能有也可能没有 na-action。例如,该 mean() 函数没有,并且 NA 在将缺少值的参数传递给它时简单地返回:
sapply(babies, mean)
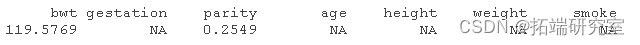
您可以通过检查 mean() 函数帮助来纠正它,通过一个参数 na.rm=TRUE,它删除了 NAs。
sapply(babies, mean, na.rm = TRUE)
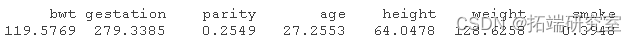
另一方面, 默认情况下summary() 会删除 NAs,并输出找到的 NAs 数量,这使其成为汇总数据时的首选。
summary(babies)
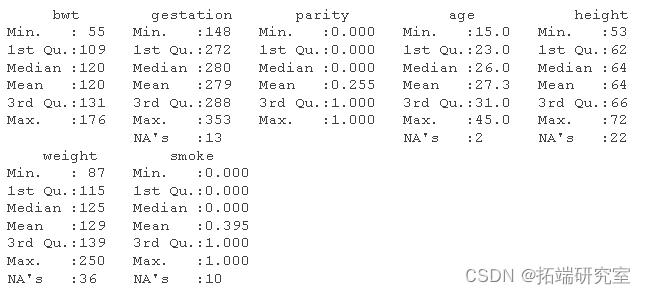
我们可以看到转换因子显示了不同的摘要,因为 summary() 操作根据变量类型而变化:

parity <- factor(parity, levels )

绘制数据是您应该采取的第一个操作。我将使用 lattice 包来绘制它,因为它的最大优势在于处理多变量数据。
随时关注您喜欢的主题
require(lattice) xyplot
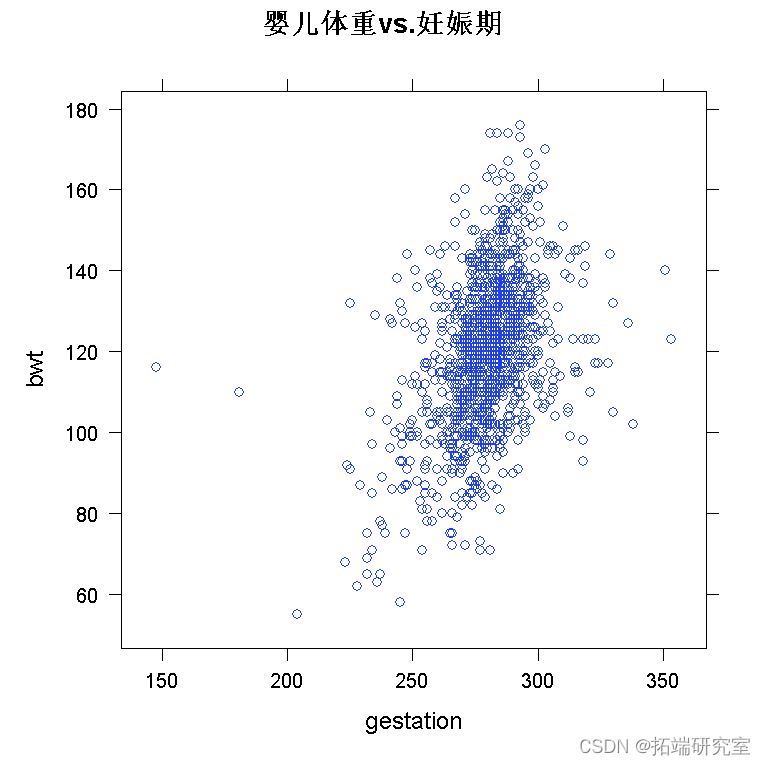
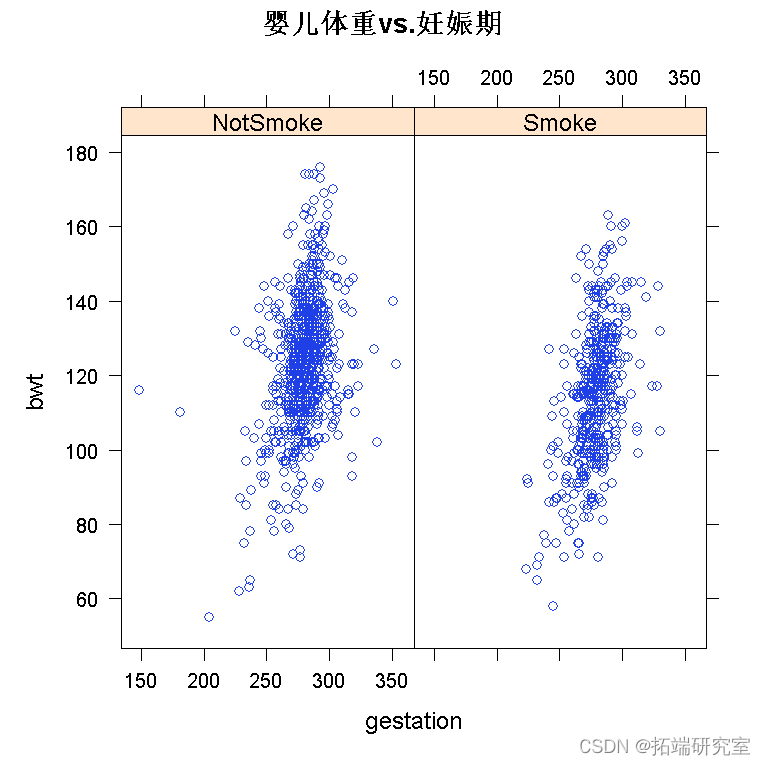
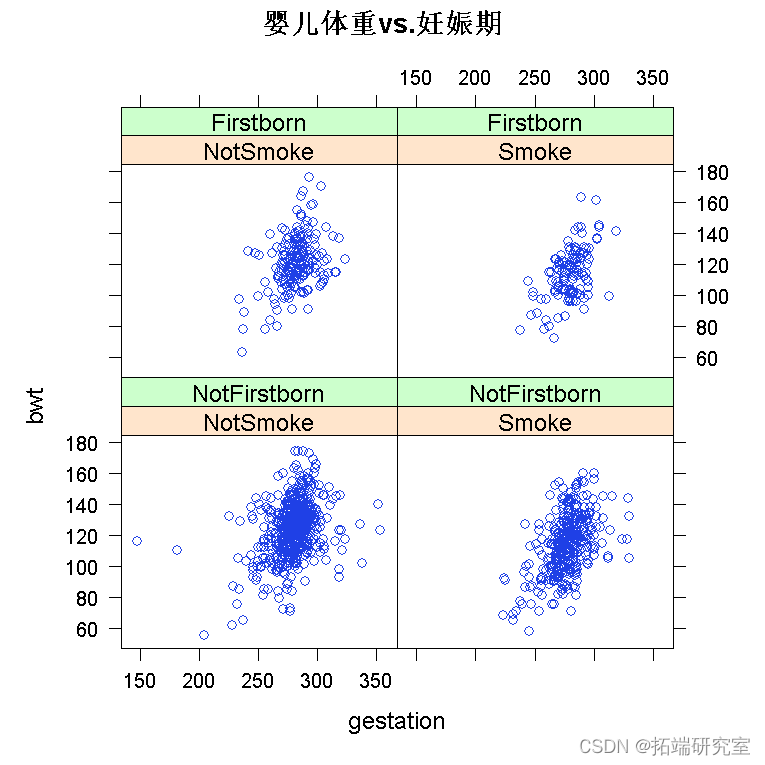
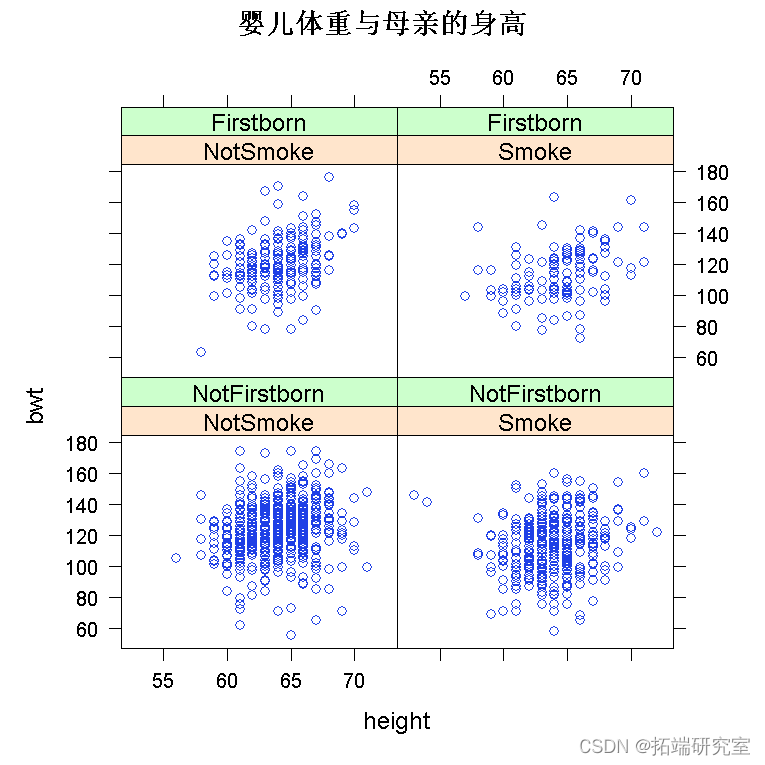

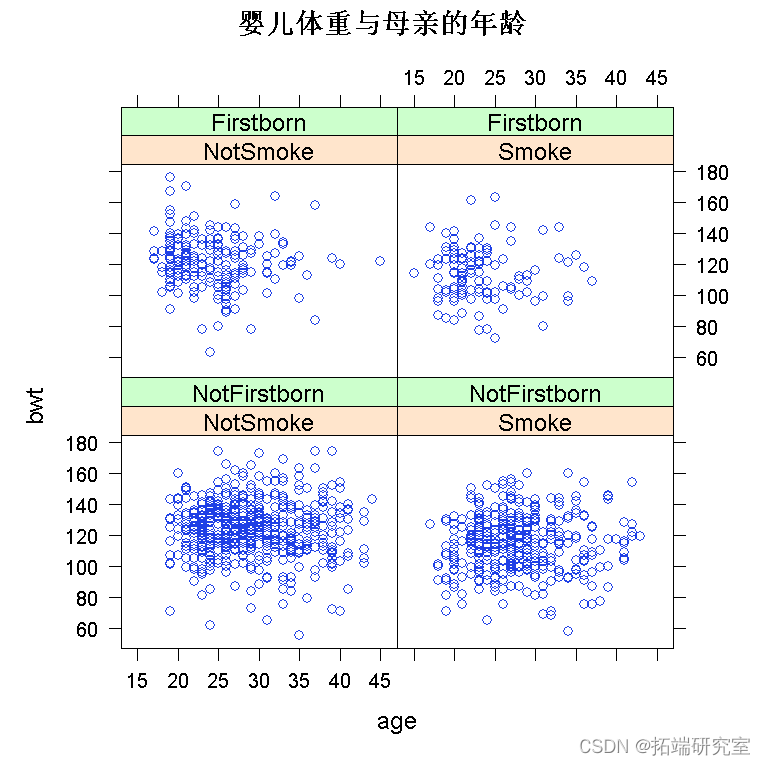
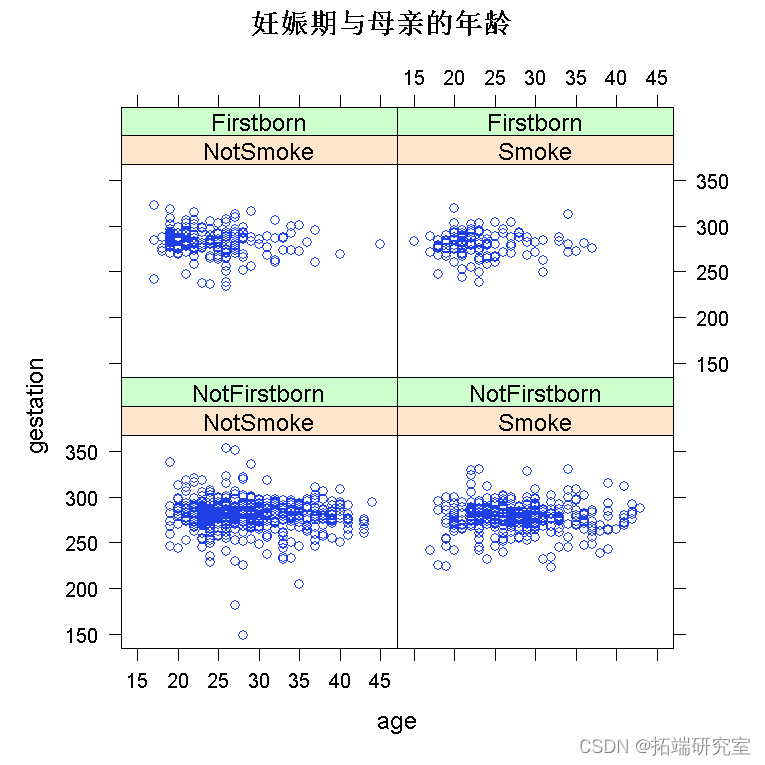
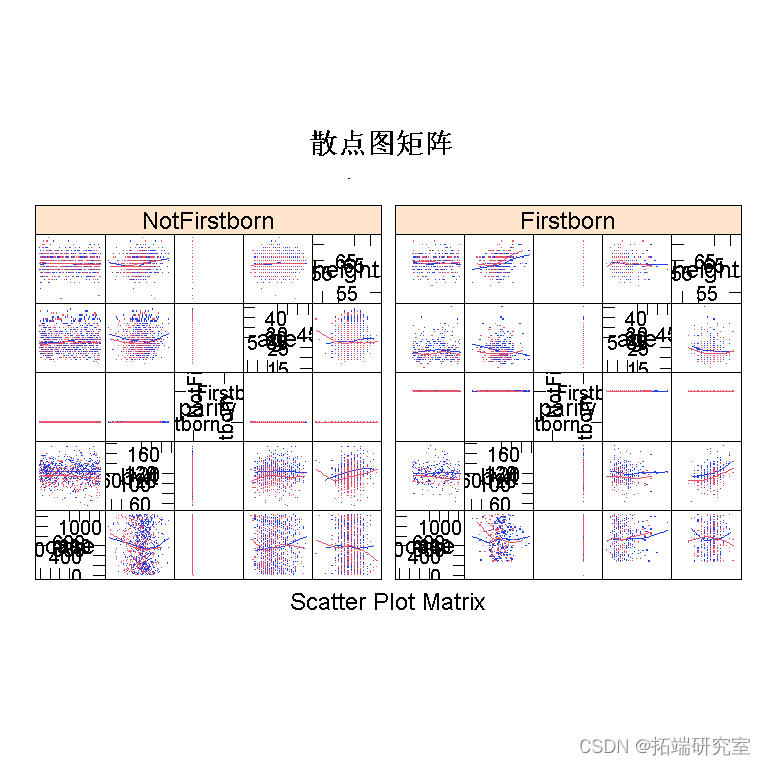
为了拟合多元回归模型,我们使用命令 lm()。
model <- lm(bwt ~ ., data = babies)
这是总结:
summary(model)
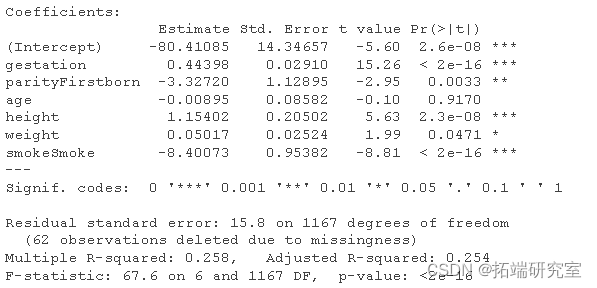
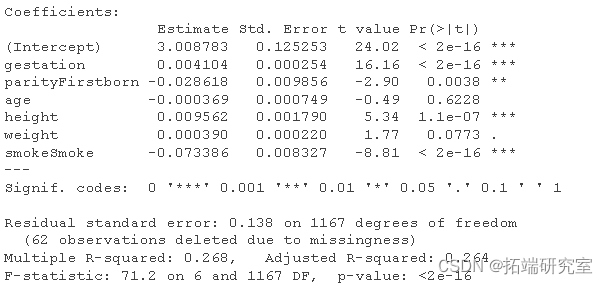
注意R的默认动作是删除信息缺失的行。不过,如何解释这些系数呢?
如果j协变量xj是实值,那么系数βj的值就是在其他协变量不变的情况下,将xij增加1个单位对Yi的平均影响。
如果j协变量xj是分类的,那么系数βj的值是对Yi从参考类别到指定水平的平均增量影响,而其他协变量保持不变。参考类别的平均值是截距(或参考类别,如果模型中有一个以上的分类协变量)。
为了验证这些假设,R有一个绘图方案。
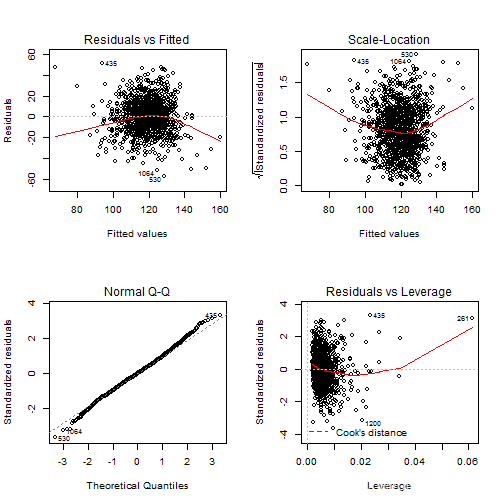
残差中的曲率表明,需要进行一些转换。尝试取bwt的对数,以获得更好的拟合(与妊娠期相比)。
summary(model.log)
为了简单起见,我会保留线性模型。给妊娠期增加一个二次项可能有用。
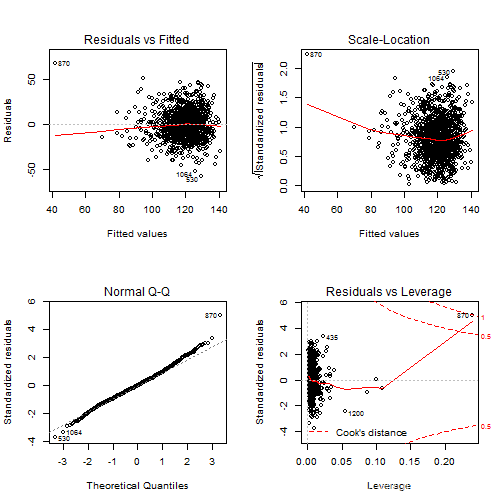
公式通常保存^作为交互作用的快捷方式,所以(妊娠期+烟)^2与妊娠期*烟或妊娠期+烟+妊娠期:烟相同。二次项。


改进仍然很小,但它现在确实将观察 261 显示为异常值。这个观察有什么问题?
babies\[261, \]

我们可以看到,而母亲的身高、年龄等都非常合理;这个婴儿异常早产。因此,将他/她剔除出模型。
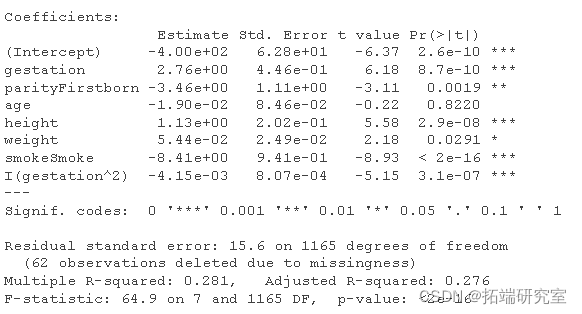
拟合度有所提高,但现在870号婴儿显示为异常值……这可以继续下去,直到我们都满意为止。你还会做哪些转化?将吸烟和妊娠期交互作用会更好吗?
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言非参数回归预测摩托车事故、收入数据:局部回归、核回归、LOESS可视化
R语言非参数回归预测摩托车事故、收入数据:局部回归、核回归、LOESS可视化 【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现
【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现 Python个人收入影响因素模型构建:回归、决策树、梯度提升、岭回归
Python个人收入影响因素模型构建:回归、决策树、梯度提升、岭回归 【视频讲解】滚动回归Rolling Regression、ARIMAX时间序列预测Python、R实现应用
【视频讲解】滚动回归Rolling Regression、ARIMAX时间序列预测Python、R实现应用


