最近我们被客户要求撰写关于预测病人冠心病的研究报告。本文的目的是完成一个逻辑回归分析。使你对分析步骤和思维过程有一个基本概念。
这些数据来自一项正在进行的对镇居民的心血管研究。
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
library(tidyverse)
library(broom)其目的是预测一个病人是否有未来10年的冠心病风险。该数据集包括以下内容。
- 男性:0=女性;1=男性
- 年龄。
- 教育。1 = 高中以下;2 = 高中;3 = 大学或职业学校;4 = 大学以上
- 当前是否吸烟。0=不吸烟;1=吸烟者
- cigsPerDay: 每天抽的烟数量(估计平均)。
- BPMeds: 0 = 不服用降压药;1 = 正在服用降压药
- 中风。0 = 家族史中不存在中风;1 = 家族史中存在中风
- 高血压。0 =高血压在家族史上不流行;1 =高血压在家族史上流行
- 糖尿病:0 = 没有;1 = 有
- totChol: 总胆固醇(mgdL)
- sysBP: 收缩压(mmHg)
- diaBP: 舒张压(mmHg)
- BMI: 体重指数
- 心率
- 葡萄糖:总葡萄糖mgdL
- TenYearCHD: 0 = 患者没有未来10年冠心病的风险; 1 = 患者有未来10年冠心病的风险
逻辑回归(Logistic Regression)与线性回归(Linear Regression)都是一种广义线性模型(generalized linear model)。逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从高斯分布。 因此与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
假设函数(Hypothesis function)
首先我们要先介绍一下Sigmoid函数,也称为逻辑函数(Logistic function):
其函数曲线如下:
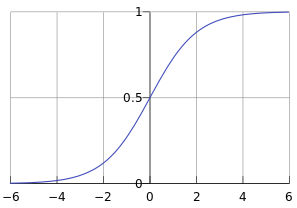
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,在远离0的地方函数的值会很快接近0或者1。它的这个特性对于解决二分类问题十分重要
逻辑回归的假设函数形式如下:
所以:
其中 是我们的输入,
为我们要求取的参数。
一个机器学习的模型,实际上是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。当然,我们还希望这组限定条件简单而合理。而逻辑回归模型所做的假设是:
这个函数的意思就是在给定 和
的条件下
的概率。
这里 就是我们上面提到的sigmoid函数,与之相对应的决策函数为:
-
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
加载并准备数据
read_csv("framingham.csv") %>%
drop_na() %>% #删除具有缺失值的观察值
ageCent = age - mean(age),
totCholCent = totChol - mean(totChol),可下载资源
拟合逻辑回归模型
glm(TenYearCHD ~ age + Smoker + CholCent,
data = data, family = binomial)
预测
对于新病人
data_frame(ageCent = (60 - 49.552),
totCholCent = (263 - 236.848),
预测对数几率
predict(risk_m, x0)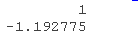
预测概率
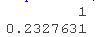
根据这个概率,你是否认为这个病人在未来10年内有患冠心病的高风险?为什么?
risk
混淆矩阵
risk_m %>%
group\_by(TenYearCHD, risk\_predict) %>%
kable(format="markdown")
mutate( predict = if_else(.fitted > threshold, "1: Yes", "0: No"))
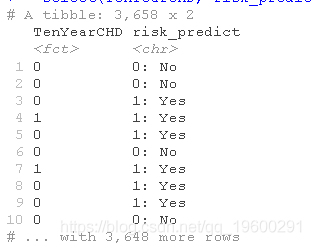
有多大比例的观察结果被错误分类?
依靠混淆矩阵来评估模型的准确性有什么缺点?
ROC曲线
ggplot(risk\_m\_aug,
oc(n.cuts = 10, labelround = 3) +
geom_abline(intercept = 0) +随时关注您喜欢的主题
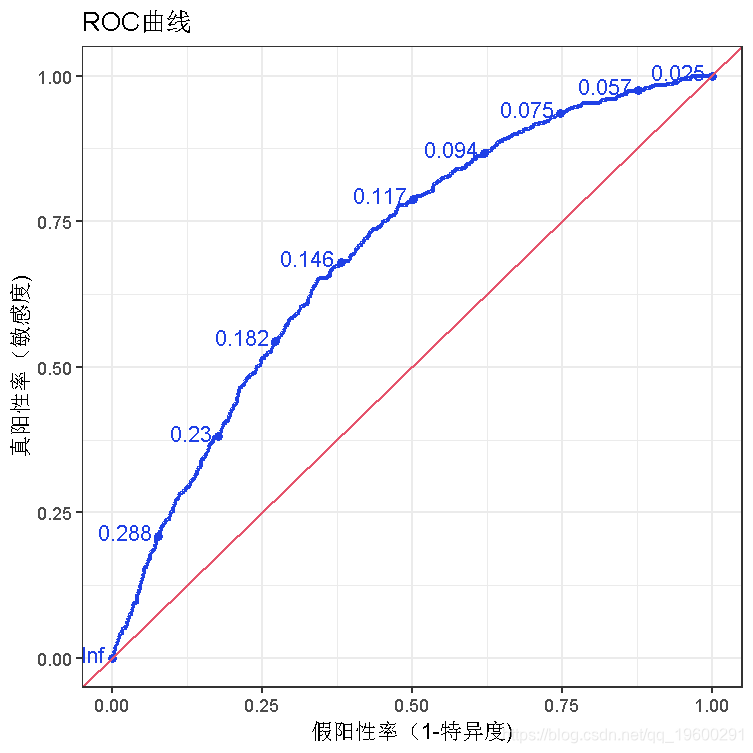
auc(roc )$AUC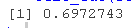
一位医生计划使用你的模型的结果来帮助选择病人参加一个新的心脏病预防计划。她问你哪个阈值最适合为这个项目选择病人。根据ROC曲线,你会向医生推荐哪个阈值?为什么?
假设
为什么我们不绘制原始残差?
ggplot(data = risk aes(x = .fitted, y = .resid)) +
labs(x = "预测值", y = "原始残差")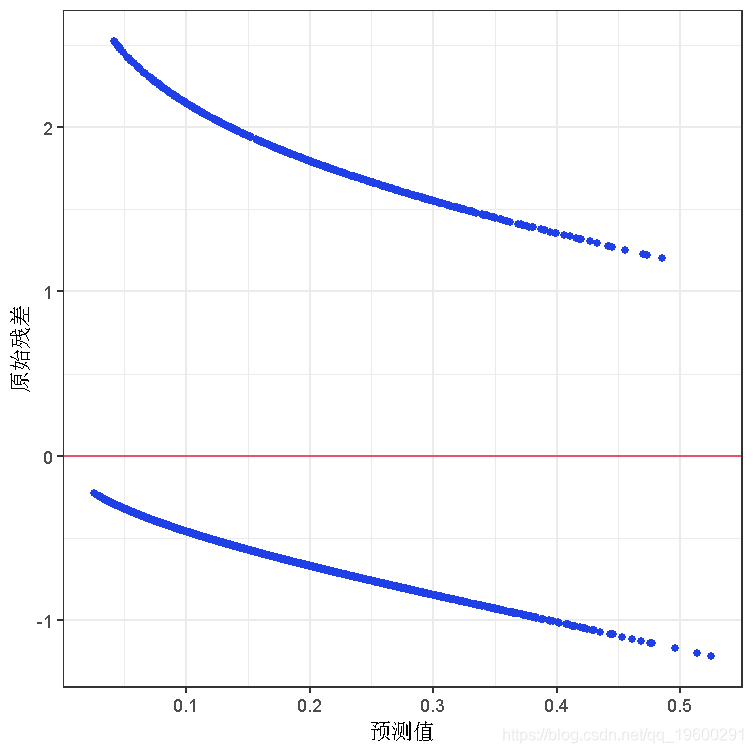
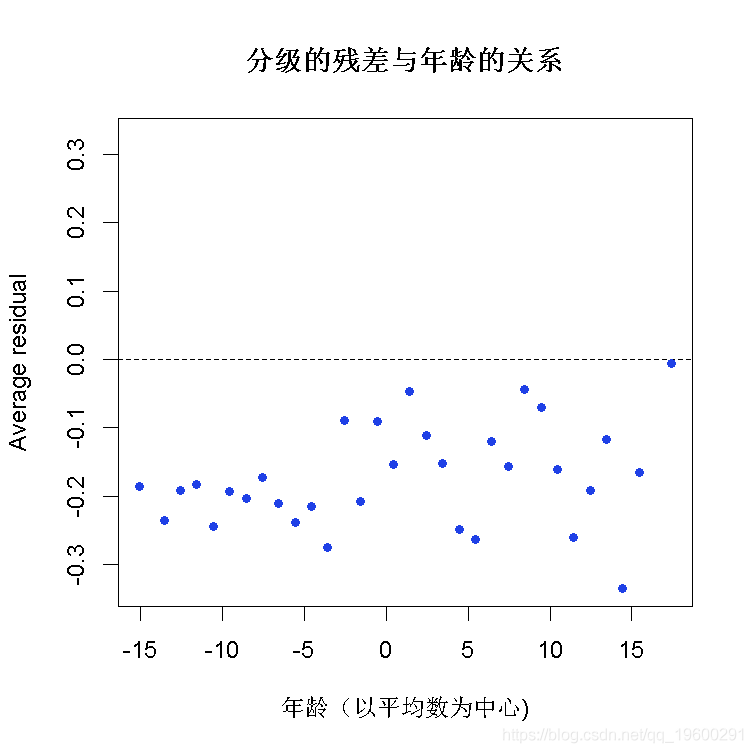
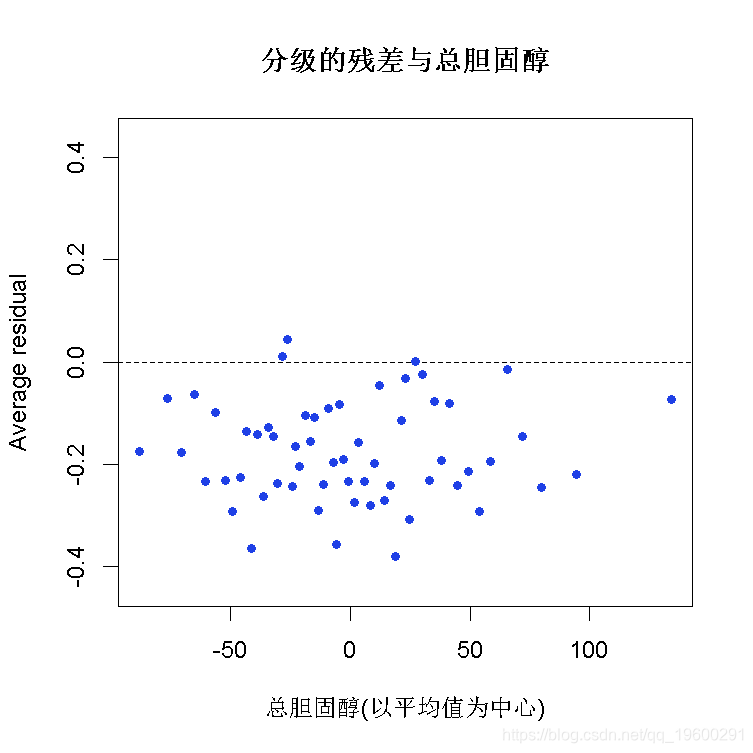
分级的残差图
plot(x = fitted, y = resid,
xlab = "预测概率",
main = "分级后的残值与预测值的对比",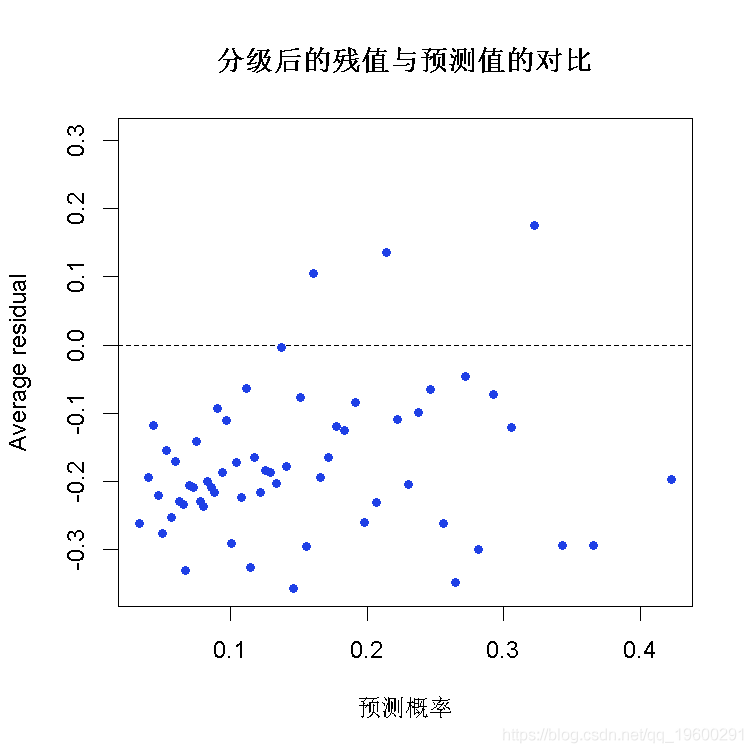
## # A tibble: 2 x 2
## currentSmoker mean_resid
## <fct> <dbl>
## 1 0 -2.95e-14
## 2 1 -2.42e-14检查假设:
– 线性?- 随机性?- 独立性?
系数的推断
currentSmoker1的测试统计量是如何计算的?在统计学上,totalCholCent是否是预测一个人患冠心病高风险的重要因素?
用检验统计量和P值来证明你的答案。
用置信区间说明你的答案。
偏离偏差检验
glm(TenYearCHD ~ ageCent + currentSmoker + totChol,
data = heart_data, family = binomial)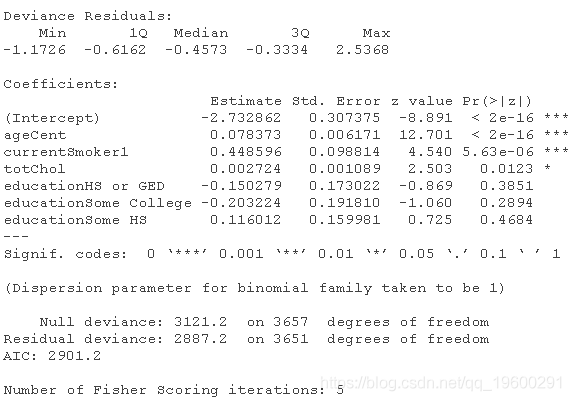
anova
AIC
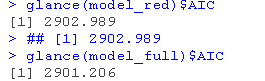
根据偏离偏差检验,你会选择哪个模型?基于AIC,你会选择哪个模型?
使用step逐步回归选择模型
step(full_model )

kable(format = "markdown" )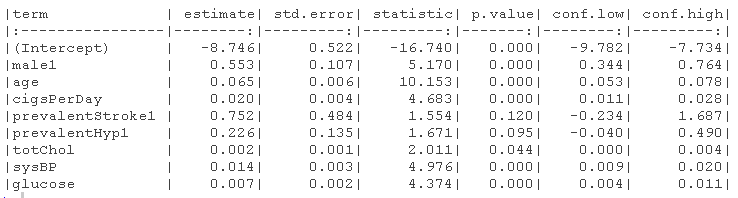
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据 Python梯度提升树GBT、随机森林、决策树对链家多城市二手房价格数据预测与区域差异可视化分析——基于数据爬取与特征工程优化|附代码数据
Python梯度提升树GBT、随机森林、决策树对链家多城市二手房价格数据预测与区域差异可视化分析——基于数据爬取与特征工程优化|附代码数据 Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据
Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据 Python用PSO优化SVM与RBFN在自动驾驶系统仿真、手写数字分类应用研究
Python用PSO优化SVM与RBFN在自动驾驶系统仿真、手写数字分类应用研究



