
高度信息化的今天,社交媒体向我们提供直接认识外界的一个窗口,决定着大家对一个地区的认知,像是一双对地区形象“塑型”的“看不见”的手。
根据这个背景,tecdat对素有“塞上江南”之称的宁夏热门推文(hot tweet,推特中的热门推文是指被转推或被收藏过的推文,相比普通推文影响力更大)进行了分析。
可下载资源
根据这个背景,tecdat对素有“塞上江南”之称的宁夏热门推文(hot tweet,推特中的热门推文是指被转推或被收藏过的推文,相比普通推文影响力更大)进行了分析。
研究人员发现网友们关注的主题,同时倾听大家呈现出来的态度及情感。根据对135,592条推特用户自主在线发布消息的分析,我们发现了一些值得注意的内容。
“消费购物” 成为关注度最高主题, 超过十分之一的推文与饮食有关
可以看到,热门推文中有关的主题有4个,根据场景的不同分别为 “消费购物”、“工业经济”、“健康养生”、“休闲生活”。
有关消费购物的推文所占比例最高,推特用户中最关心的宁夏议题是消费购物。
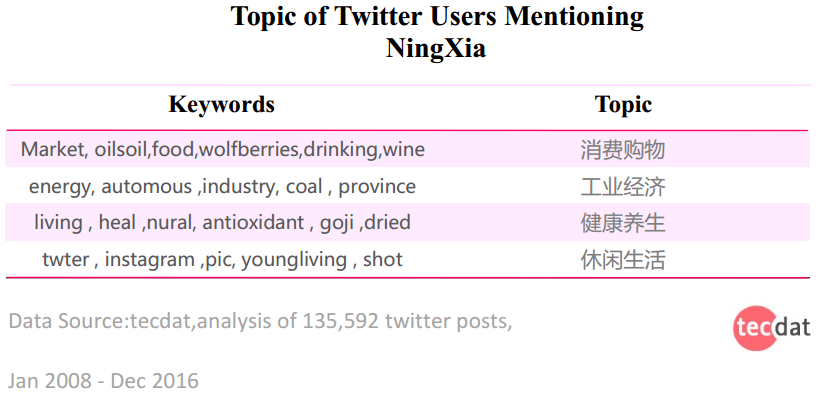
属于消费购物类的主题包括Market, oilsoil,food,wolf berries,drinking,wine,共6项,所占比例为32.6%;

属于工业经济的包括energy, automous ,industry, coal , province等5个主题, 所占比例为26.4%。

属于健康养生的主题包括 living , heal ,nural, antioxidant , goji ,dried,共计6个,所占比例为21%。

属于休闲生活的主题包括twter , instagram ,pic, youngliving , shot,共计5个,所占比例为20%。

从消费购物词云中,我们发现驴友爱买的宁夏特产,如干红葡萄酒、枸杞酒、贺兰石等。
从工业词云中,我们发现煤炭是宁夏的优势矿产资源。宁夏境内能源资源丰富,可利用的有石油、天然气、煤层气、水能、风能、光能等。这些资源为宁夏建设能源基地提供了强有力的保证。
从健康养生词云中我们发现作为宁夏特产的枸杞,具有一定的养生抗氧化功效。
从休闲生活词云中,我们发现宁夏作为旅游胜地,吸引了大量年轻人前来拍照游玩。
热门推文总体上以积极正向为主

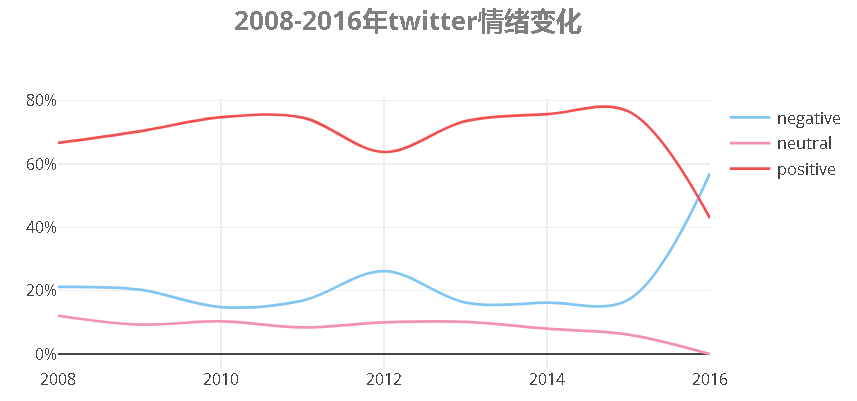
从变化的情况来看,2016年的推文积极正面的评价比例最低,为42%,消极负面评价的比例为58%,是历年来最高的。
通过2016年推特的关键词,我们发现负面的议题包括:驴友评论宁夏干燥的天气、宁夏部分地区牺牲环境换发展、以及导游强迫购物现象。
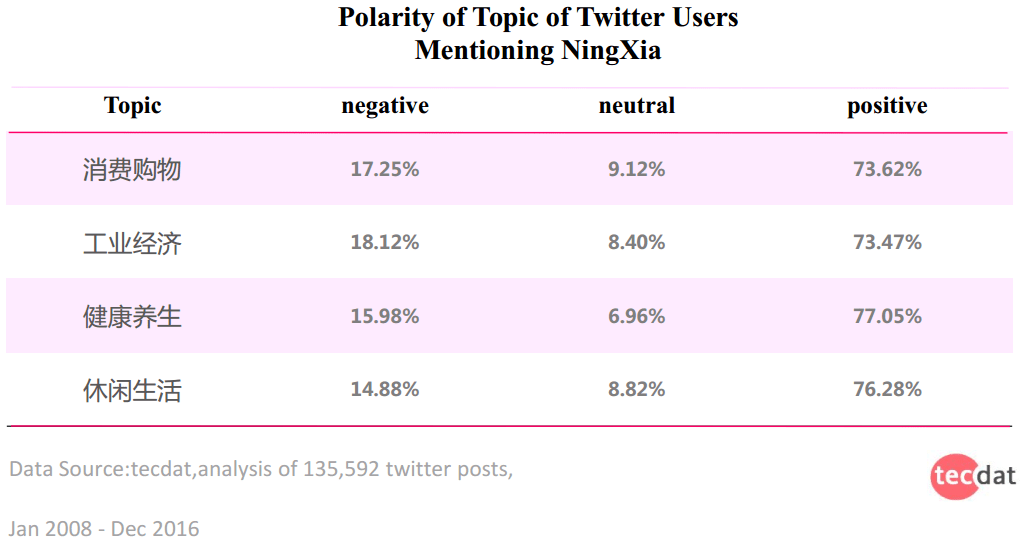
按照四个主题来看,在健康养生议题中,积极正面的评价为77.05%,略高于其他议题中正面评价的比例。同时可以看到休闲生活的负面评价比例最低。
热门推文中只有四分之一表现出了明显的情感
识别情感时,共有六种情感:anger(愤怒)、disgust(厌恶)、fear(恐惧)、joy(喜悦)、sadness(悲伤)和surprise(惊奇),在分析时会先为每条推文的每种可能情感打分。
如果六种情感可能性得分相差不大时,则情感类拟合为unknown(未知)。 如果某条推文被拟合得到某一类情感,该情感一定是强烈的情感。
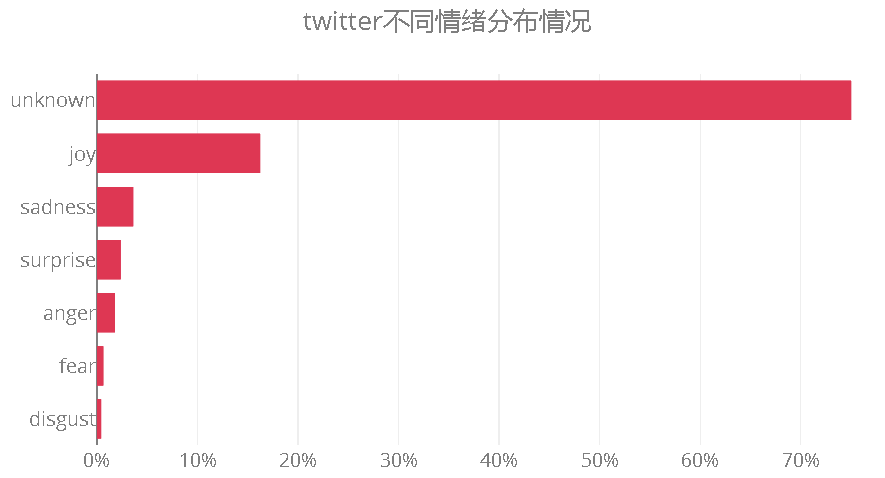
从情感分析的结果来看,只有25.54%的推文表现出了强烈的情感。近四分之三的推文都没有表现出强烈的情感,情感拟合为unknown。
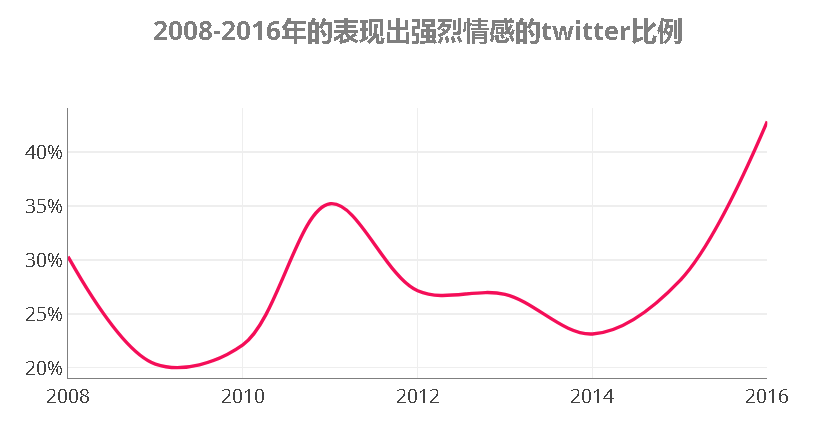
历时来看,随着时间的推移,热门推文表现出强烈情感的比例越来越多。在2008年,只有30.3%表达出了强烈的情感,而2016年,这个比例已经提升到42.8%。这表明,就宁夏地区议题而言,推特用户越来越倾向于表达出强烈的情感。
从情感的比例情况来看,喜悦高居第一位,且有上升的趋势
从所表达出来的情感来看,比例最高的情感是喜悦,占比16.19%;其次为悲伤,占4.49%。

joy呈现出逐年提高的趋势, 这说明热门推文中,含有喜悦情感的比例越来越多,而sadness呈现出小幅上下波动减小的态势。
数据样例
| fullname | like_num | reply_num | retweet_num | tweet_id | tweet_text | tweet_time | url | username |
|---|---|---|---|---|---|---|---|---|
| Ila Smith | 0 | 0 | 0 | 870401987724145024 | I may or may not have had two glasses of ningxia today, I was… https://www.instagram.com/p/BU0C3DvDyZxUkEJ0a_3dE61bnRiz2ES63fxCMc0/ … | 2017-06-01 22:09:39 | https://twitter.com/BoomKittie/status/870401987724144640 | BoomKittie |
| MeganHusson | 0 | 0 | 0 | 870340086411480960 | If you'd like to learn about how NingXia Red can benefit your health and wellness visit :… https://www.instagram.com/p/BUzmtStF3YJ/ | 2017-06-01 18:03:41 | https://twitter.com/MeganHusson/status/870340086411481088 | MeganHusson |
| Essentially Fit | 0 | 0 | 0 | 870338986992177024 | @michael_thrash running with @Michael_Thrash this morning! . Using NingXia Nitro for an added… https://www.instagram.com/p/BUzmNSHDX4n/ | 2017-06-01 17:59:19 | https://twitter.com/Michael_Thrash/status/870338986992177153 | Michael_Thrash |
| D.G. | 0 | 0 | 0 | 870323371023548032 | LOVE my FREE PRODUCT June's FREE PRODUCT 300PV Ningxia Nitro Pack 15 ML En-Er-Gee 15 ML Cypress 15 ML... http://fb.me/1s6LBYxB1 | 2017-06-01 16:57:16 | https://twitter.com/DanaDynamite1/status/870323371023548416 | DanaDynamite1 |
| Sherrie Mullins | 0 | 0 | 0 | 870322949785570944 | Check out Young Living's June promo! Spearming Vitality, Patchouli, Cypress, AromaEase, Ningxia Nitro, and... http://fb.me/65npFDzWQ | 2017-06-01 16:55:35 | https://twitter.com/aviatastic/status/870322949785571328 | aviatastic |
| TRACE RevOiLution | 0 | 0 | 0 | 870286020494987008 | What time is it!!! Time for your Ningxia fix.... bring on Thirsty Thursday!!! via http://ripl.com pic.twitter.com/CZNntXeqEX | 2017-06-01 14:28:51 | https://twitter.com/Trace_MyOilGal/status/870286020494987264 | Trace_MyOilGal |
| Tamara Higgins | 0 | 0 | 0 | 870282495039869056 | June promos are up! Never tried Ningxia Nitro. http://fb.me/8HSOzhnDS | 2017-06-01 14:14:50 | https://twitter.com/LivingWithScent/status/870282495039868928 | LivingWithScent |
| Bimal Pr. Mohapatra | 2 | 0 | 2 | 870250346970467968 | Like China is settling Han race people in its western Muslim dominated Xinjiang, Gansu, and Ningxia provinces. | 2017-06-01 12:07:05 | https://twitter.com/bimal_pr/status/870250346970468352 | bimal_pr |
| Cliff Huang | 4 | 0 | 0 | 870208384112280064 | Those are pepper buns 胡椒餅! For food definitely go to Ningxia, especially this 賴記蚵仔煎 (oyster omelette thingy) near one of the entrances. | 2017-06-01 09:20:21 | https://twitter.com/Dellaran_0611/status/870208384112279552 | Dellaran_0611 |
| China Daily | 6 | 0 | 7 | 870203275601035008 | For the past five years, more than 300 kinds of wines from Ningxia won awards both in China and overseas.https://cards.twitter.com/cards/18ce54hceff/4ah3k … | 2017-06-01 09:00:03 | https://twitter.com/ChinaDailyUSA/status/870203275601035265 | ChinaDailyUSA |
| BusinessCentralAsia | 1 | 0 | 0 | 870198894575010048 | Ningxia's heady with success in trading #wine; for more info kindly visit http://facebook.com/businesscentralasia …pic.twitter.com/inAwgLbLnM | 2017-06-01 08:42:38 | https://twitter.com/BCAmagazine/status/870198894575009792 | BCAmagazine |
| Xinhua Sports | 98 | 1 | 35 | 870170571148886016 | It's nice to see a #beachvolleyball game in summer. A total of 62 teams participate in the 2017 China Beach Volleyball Tournament in Ningxia pic.twitter.com/uxREFACYyE | 2017-06-01 06:50:05 | https://twitter.com/XHSports/status/870170571148886016 | XHSports |
| Jessica Bates | 1 | 0 | 0 | 869699516240454016 | My new favorite way to drink a Ningxia zyng!! #yleo #youngliving #energy #tired #energydrink #zyng #ningxia #toxinfreepic.twitter.com/1PTbb4zrhA | 2017-05-30 23:38:17 | https://twitter.com/ningrlpwr/status/869699516240453633 | ningrlpwr |
| Laura | 0 | 0 | 0 | 869629434428576000 | Who else loves their daily dose of #NingXia? Which NingXia product is your favorite? http://laurasessentials.org/ #fbpic.twitter.com/dXf1sk3dNT | 2017-05-30 18:59:48 | https://twitter.com/LaurasEssential/status/869629434428575744 | LaurasEssential |
| PositivParentSpecial | 1 | 0 | 1 | 868470294511579008 | Proof is in the pudding! #pps #youngliving I love my Ningxia Red pic.twitter.com/57zEWIc1cH | 2017-05-27 14:13:48 | https://twitter.com/Jennpositiviam1/status/868470294511579138 | Jennpositiviam1 |
| KQ GEO | 0 | 0 | 1 | 868290242947800960 | KQ cooperates with Ningxia University to leverage academic resources for GIS solutions for Smart City and Smart Agriculture. pic.twitter.com/c5aeHwEsSc | 2017-05-27 02:18:20 | https://twitter.com/KqGeo/status/868290242947801088 | KqGeo |
| China Xinhua News | 212 | 8 | 88 | 867971205394947968 | 8 ancient rock paintings of horses, believed to date back to Paleolithic or Neolithic Age, found in China's Ningxia http://xhne.ws/6qMCB pic.twitter.com/Ap7vPD1Btf | 2017-05-26 05:10:36 | https://twitter.com/XHNews/status/867971205394948096 | XHNews |
| Jim Baker | 7 | 0 | 1 | 867926967915380992 | Brad Bodenhausen discussing International Leadership and Training Center programs with Ningxia University officials. pic.twitter.com/0jRsS8mtcM | 2017-05-26 02:14:49 | https://twitter.com/Jimbaker48/status/867926967915380736 | Jimbaker48 |
| Jim Baker | 13 | 0 | 1 | 867923894719488000 | In Yinchuan signing two new agreements with our partner, Ningxia University. Long and very productive partnership. pic.twitter.com/uWOUDJOTwT | 2017-05-26 02:02:36 | https://twitter.com/Jimbaker48/status/867923894719488001 | Jimbaker48 |
| China News 中国新闻网 | 9 | 0 | 7 | 867909160804930048 | #ChinaCulture: Successor of intangible cultural heritage of Ningxia makes embroidery works http://bit.ly/2r1tOj3 pic.twitter.com/0NigbEtMGM | 2017-05-26 01:04:03 | https://twitter.com/Echinanews/status/867909160804929540 | Echinanews |
| jamie k | 3 | 1 | 0 | 865297350394294016 | i'm at the Ningxia Cabernet Sauvignon again, lads | 2017-05-18 20:05:39 | https://twitter.com/jkbloodtreasure/status/865297350394294272 | jkbloodtreasure |
| Kimberlasa | 2 | 0 | 0 | 865283005874654976 | Where are all my #ningxiared addicts at? #startingthisjourney #youngliving #essentialoils #wolfberry #ningxia | 2017-05-18 19:08:39 | https://twitter.com/kimberlasa/status/865283005874655234 | kimberlasa |
| Crystal Collins | 1 | 0 | 0 | 865255243982020992 | Today's deliscousness consists of mango, coconut water, and Ningxia along with a little pineapple sage flair. pic.twitter.com/EetXqJzE2w | 2017-05-18 17:18:20 | https://twitter.com/CrystalECollins/status/865255243982020609 | CrystalECollins |
| Silvennia Silsendrea | 0 | 0 | 0 | 865154062550839040 | much sleepiness...coffee ain't any help =w=; then again coffee's caffeine was never any help lol. I regret forgetting my NingXia Nitro... | 2017-05-18 10:36:16 | https://twitter.com/silvennia/status/865154062550839297 | silvennia |
| Zhaopin | 1 | 1 | 0 | 865043331897736960 | The #BeltandRoad initiative has improved labor market in Western #China. Job demand in Ningxia jumped 137% in 2016, from 6% in 2015. $ZPIN | 2017-05-18 03:16:16 | https://twitter.com/Zhaopin_com/status/865043331897737216 | Zhaopin_com |
| Aly | 0 | 0 | 0 | 864934124582093056 | Need a healthy alternative to sodas and sports drinks? NingXia Zyng™ is a refreshing boost, without artificial flavors and preservatives. pic.twitter.com/LIJC9VthXl | 2017-05-17 20:02:19 | https://twitter.com/AlyJacobs/status/864934124582092800 | AlyJacobs |
| Jess | 1 | 0 | 0 | 864928547546300032 | When the baby doesn't want to nap, you've gotta just roll with it. Ningxia, lime, and really… https://www.instagram.com/p/BUNJ1Bhg1OS/ | 2017-05-17 19:40:09 | https://twitter.com/iftheywouldnap/status/864928547546300417 | iftheywouldnap |
| Amber Mrs. Moto | 0 | 0 | 0 | 864854241076104960 | All this + diffuser + ningxia + the raddest oily tribe you'll ever meet AND $20 back ending Sunday Grab it up: http://dewdropcollective.com/order-oils-amber-iwamoto/ …pic.twitter.com/58q9Z8afdv | 2017-05-17 14:44:53 | https://twitter.com/Confidence101/status/864854241076105216 | Confidence101 |
| Kristi Madala, RN | 1 | 0 | 0 | 864791951660470016 | Look what Ningxia Red can do to an unhealthy patients blood cell in 15 minutes! pic.twitter.com/S0gr7kah21 | 2017-05-17 10:37:22 | https://twitter.com/KristiMadala/status/864791951660470272 | KristiMadala |
| PolymerMIS | 0 | 0 | 0 | 864739478631440000 | Shenhua Ningxia I shuts PP Unit. For more news and company offers Contact Us at:- http://www.polymermis.com Email:- sales@polymermis.com | 2017-05-17 07:08:52 | https://twitter.com/PolymerMIS/status/864739478631440385 | PolymerMIS |
| Brendan J. Micik | 0 | 0 | 0 | 864631670602968960 | I liked a @YouTube video http://youtu.be/yXrddCwUHWU?a Young Living Essential Oils Introduction- Oils, NingXia, Thieves Updated 2017 | 2017-05-17 00:00:29 | https://twitter.com/LilSamson7/status/864631670602969090 | LilSamson7 |
| T.Liston's Honeypot | 0 | 0 | 0 | 864630431026728960 | A host at 111.113.149.74 (CN, Ningxia - Yinchuan) tried to log into my honeypot's fake MSSQL Server... #netmenaces 1 | 2017-05-16 23:55:33 | https://twitter.com/netmenaces/status/864630431026728965 | netmenaces |
| Jim Boyce/Grape Wall | 1 | 0 | 0 | 864513646331703040 | Torres China's 20th birthday feat. magnums of Emma's Reserve, Silver Heights, Ningxia. SH w Torres since debut vintage in 2007. @TorresWinespic.twitter.com/U5XNMAQfvR | 2017-05-16 16:11:29 | https://twitter.com/grapewallchina/status/864513646331703296 | grapewallchina |
| Casey Beckett | 0 | 0 | 0 | 864497333215604992 | The pugs love when I share my Ningxia Red from Young Living. Rose the Pug is taking her time… https://www.instagram.com/p/BUKFu71lMeT/ | 2017-05-16 15:06:40 | https://twitter.com/oilyknitter/status/864497333215604736 | oilyknitter |
| Carolyn B. Heller | 1 | 0 | 0 | 864492971567271936 | There was a long line in front of this stand at the Ningxia Night Market, so of course we had to… https://www.instagram.com/p/BUKDvwKllA6/ | 2017-05-16 14:49:20 | https://twitter.com/CarolynBHeller/status/864492971567271937 | CarolynBHeller |
| #Wine Guru 🍷 | 5 | 0 | 5 | 864430947126595968 | #Wine #Vino #China: Ningxia Winemakers Challenge | Bottling Passes Halfway Point: By Jim Boyce… http://bit.ly/2pPYNx2 via @grapewallchina | 2017-05-16 10:42:52 | https://twitter.com/RealWineGuru/status/864430947126595585 | RealWineGuru |
| beijingboyce | 1 | 0 | 0 | 864367097215767040 | Bottling passes halfway point for #Ningxia Winemakers Challenge. USD100,000+ in cash prizes. #China #Ningxia #Wine http://www.grapewallofchina.com/2017/05/16/ningxia-winemakers-challenge-wine-bottling/ …pic.twitter.com/Wei0OF1IhM | 2017-05-16 06:29:09 | https://twitter.com/beijingboyce/status/864367097215766529 | beijingboyce |
| seriouslywine | 0 | 0 | 0 | 864366808010153984 | Ningxia Winemakers Challenge | Bottling Passes Halfway Point http://www.seriouslywine.com/2017/05/15/23/02/51/ningxia-winemakers-challenge-bottling-passes-halfway-point/ … | 2017-05-16 06:28:00 | https://twitter.com/seriouslywine/status/864366808010153987 | seriouslywine |
| Jim Boyce/Grape Wall | 0 | 0 | 0 | 864366279355911936 | Bottling past halfway point for #Ningxia Winemakers Challenge. #Wine judged later this year, USD100,000+ in prizes. http://www.grapewallofchina.com/2017/05/16/ningxia-winemakers-challenge-wine-bottling/ …pic.twitter.com/NCgtQyrTCE | 2017-05-16 06:25:54 | https://twitter.com/grapewallchina/status/864366279355912192 | grapewallchina |
| Jennifer Atkinson | 0 | 0 | 0 | 864206486452535040 | Day 1 (part B) -- Ningxia Red is off the charts when it comes to antioxidants scores. This is a… https://www.instagram.com/p/BUIBeQ8AUsc/ | 2017-05-15 19:50:57 | https://twitter.com/jennatk/status/864206486452535296 | jennatk |
| City Girl | 0 | 0 | 0 | 864195124326088960 | I'm never running out of Zyng, Ningxia Red or Nitro again. Most productive morning in ages and yes I woke up... http://fb.me/3oXjlKVTK | 2017-05-15 19:05:48 | https://twitter.com/sarahcheyanne/status/864195124326088705 | sarahcheyanne |
| Victor de la Serna E | 1 | 0 | 0 | 864151644187000960 | Interesting question - but not one I'll be answering! Unless you can make a Latour taste-like with native grapes in Ningxia! https://twitter.com/MUSTwinesummit/status/864147670629326848 … | 2017-05-15 16:13:01 | https://twitter.com/VictordelaSerna/status/864151644187000833 | VictordelaSerna |
| Digital Marketing | 0 | 0 | 0 | 864102742997873024 | We have own goji farm and factory In Ningxia,China,who offer High Quality Goji berry seeds. @ http://www.berrygoji.com/html_products/goji-berry-seeds-30.html …pic.twitter.com/ermo8fPFIU | 2017-05-15 12:58:42 | https://twitter.com/Jerywlson/status/864102742997872640 | Jerywlson |
| 寧霞 | 1 | 0 | 0 | 864081142906994944 | self reminderhttps://twitter.com/EresInteligente/status/863906858997862400 … | 2017-05-15 11:32:52 | https://twitter.com/Ningxia_/status/864081142906994688 | Ningxia_ |
| Amber Sonsalla | 0 | 0 | 0 | 863822510349058048 | Stress Away & NingXia Nitro- This dynamic duo helps curb the 2pm slump plus gives you an aromatic mini vacation to a tropical island! pic.twitter.com/LimQTt7Yzo | 2017-05-14 18:25:10 | https://twitter.com/asonsalla2012/status/863822510349058048 | asonsalla2012 |
| Dreamy Doll | 2 | 0 | 0 | 863820612808184064 | I can arrange that! Add some NingXia | 2017-05-14 18:17:37 | https://twitter.com/DankyDoll/status/863820612808183808 | DankyDoll |
| Sarah Brun | 0 | 0 | 0 | 863769015507862016 | Mother's Day at home Brunch from Joey & the girls, complete with NingXia mimosas https://www.instagram.com/p/BUE6iFdhTFD/ | 2017-05-14 14:52:36 | https://twitter.com/sarbrun/status/863769015507861504 | sarbrun |
| Jenny Eden Coaching | 0 | 0 | 0 | 863727879447817984 | Pinned to Holistic Health Topics on @Pinterest: Ningxia Red is a nutritious juice made from the antioxidant-pack… http://ift.tt/2pxYwmt | 2017-05-14 12:09:08 | https://twitter.com/coachjennyeden/status/863727879447818240 | coachjennyeden |
| Christee Brindzik | 0 | 0 | 0 | 863590724889181952 | Because ... #GirlsNightOut !! . . . #NingXia #Nitro #NingXiaNitro #NaturalEnergy #ChemicalFree https://www.instagram.com/p/BUDpdONjFgl/ | 2017-05-14 03:04:08 | https://twitter.com/Get_Oily/status/863590724889182208 | Get_Oily |
| HeavenlyGaits | 0 | 0 | 0 | 863555742456008960 | Sweet and tangy, Ningxia Red's formula includes wolfberry, which is touted for its health benefits. http://ow.ly/zFkQ30bxIbJ | 2017-05-14 00:45:07 | https://twitter.com/HeavenlyGaits/status/863555742456008705 | HeavenlyGaits |
| Stoner Mermaid | 3 | 0 | 0 | 863510977832247040 | Ningxia straight from the bottle and a joint #Saturdaze | 2017-05-13 21:47:15 | https://twitter.com/St0nerMermaid/status/863510977832247296 | St0nerMermaid |
| Vox Populi Sbc | 0 | 0 | 0 | 863396825386057984 | Have you done business with China Moslem in Ningxia? If not, join business trip to Ningxia on… https://www.instagram.com/p/BTvjC4eAnnU/ | 2017-05-13 14:13:38 | https://twitter.com/VoxSBC/status/863396825386057728 | VoxSBC |
| Nick Breeze | 0 | 0 | 0 | 863266184199889024 | Journey to the #China: 6 wines frm Ningxia paired w 6 pieces of Chinese classical music in #London Sun 14 http://www.bachmeetsbarolo.com/bookonline #wine | 2017-05-13 05:34:31 | https://twitter.com/NickGBreeze/status/863266184199888900 | NickGBreeze |
| CSEN | 5 | 0 | 6 | 863106066111906048 | Asia Society’s “Monks & Merchants: Silk Road Treasures from NW China, Gansu & Ningxia, 4th-7th Centuries”: http://bit.ly/2qbzZCl pic.twitter.com/kkEKZRd0Gb | 2017-05-12 18:58:16 | https://twitter.com/csen_nomads/status/863106066111905793 | csen_nomads |
| Govt Of The Punjab | 30 | 1 | 10 | 863004445264809984 | "Punjab’s relationship with provinces of China like Sichuan, Fujian, Jiangxi, Guangdong and Ningxia are growing day by day." CM #SSinChinapic.twitter.com/BjPzZOWoIT | 2017-05-12 12:14:28 | https://twitter.com/GovtOfPunjab/status/863004445264809984 | GovtOfPunjab |
| Qingdao Red Lions FC | 2 | 0 | 0 | 862951513261342976 | MATCH LOCATION | Coming to watch us on sunday? Haiyue East Road at Qingdao Uni East Campus (entrances at Ningxia Road & Xianggang East Road) | 2017-05-12 08:44:08 | https://twitter.com/qingdaoredlions/status/862951513261342720 | qingdaoredlions |
| stephanie finochio | 0 | 0 | 0 | 862882375868572032 | I liked a @YouTube video http://youtu.be/YSRNIEtJjQw?a Master Formula and NingXia Red | 2017-05-12 04:09:24 | https://twitter.com/actiontrinity/status/862882375868571648 | actiontrinity |
| Mary | 1 | 0 | 0 | 862728905102316032 | Biochar amendment reduces paddy soil nitrogen leaching but increases net global warming potential in Ningxia… http://dlvr.it/P6tJVV | 2017-05-11 17:59:34 | https://twitter.com/myearthproject/status/862728905102315520 | myearthproject |
| omar ali | 1 | 0 | 2 | 862726353392726016 | I think the stress is on splittism, not Quran per se..same verses may get shared in Ningxia without too much notice. For now.. https://twitter.com/IslamAndRF/status/862404248478285824 … | 2017-05-11 17:49:25 | https://twitter.com/omarali50/status/862726353392726016 | omarali50 |
| FeOM Research | 1 | 0 | 0 | 862717746613703040 | Biochar amendment reduces paddy soil nitrogen leaching but increases net global warming potential in Ningxia… http://dlvr.it/P6sR2Z | 2017-05-11 17:15:13 | https://twitter.com/FeOM_Research/status/862717746613702660 | FeOM_Research |
| Essentially Fit | 0 | 0 | 0 | 862691871713373952 | Essentially Fit Club approved! . Take the power of NingXia Red® anywhere you go with Young… https://www.instagram.com/p/BT9QtHXDn9e/ | 2017-05-11 15:32:24 | https://twitter.com/Michael_Thrash/status/862691871713374208 | Michael_Thrash |
| Essential Oils Life | 1 | 0 | 0 | 862680958398583040 | NingXia Nitro delivers a wide range of powerful cognitive enhancers in a proprietary Nitro… https://www.instagram.com/p/BT9LvZvlBjk/ | 2017-05-11 14:49:02 | https://twitter.com/abbeymcclure/status/862680958398582784 | abbeymcclure |
| T.Liston's Honeypot | 0 | 0 | 0 | 862508856957709952 | A host at 218.95.151.238 (CN, Ningxia - Yinchuan) tried to log into my honeypot's fake MSSQL Server... #netmenaces 1 | 2017-05-11 03:25:10 | https://twitter.com/netmenaces/status/862508856957710336 | netmenaces |
| Jamie Rhone | 0 | 0 | 0 | 862468265054011008 | Ningxia Red. Oh how I love thee. I can't imagine going without it and I like saving money. Sound like you? Well... http://fb.me/1ZxoeNyuR | 2017-05-11 00:43:52 | https://twitter.com/spajamie1/status/862468265054011392 | spajamie1 |
| The Oil Posse | 1 | 0 | 0 | 862429003084427008 | Can you think of a better way to host a business building class than to freeze Ningxia Red in these diamond ice... http://fb.me/1iK0DEHA4 | 2017-05-10 22:07:52 | https://twitter.com/theoilposse/status/862429003084427265 | theoilposse |
| VinusWineBlog | 3 | 1 | 0 | 862404957521268992 | I reiterate my offer to send you a bottle or two... I plan to be in #ningxia in June or July to blend/bottle my 2015 #CabernetSauvignon | 2017-05-10 20:32:19 | https://twitter.com/VinusWine/status/862404957521268737 | VinusWine |
| Kimmy | 0 | 0 | 0 | 862399398432711040 | "If you want to be energized, fortified, and replenished with abundance, you need to start living with NingXia... http://fb.me/AsruST1I | 2017-05-10 20:10:13 | https://twitter.com/Beanes1Baby/status/862399398432710658 | Beanes1Baby |
| VinusWineBlog | 2 | 1 | 0 | 862395083097767936 | A5: #ConoSurWineTalk I am defo laying down some #Ningxia wines @cielito_wine but I have one or two smaller French chateaux in Cab blends | 2017-05-10 19:53:04 | https://twitter.com/VinusWine/status/862395083097767937 | VinusWine |
| VinusWineBlog | 2 | 2 | 0 | 862385414258269952 | good evening all! Has to be a chinese wine: #ningxia #cabernetsauvignon 2012 #ChateauYuange @cielito_winepic.twitter.com/vqkytfk8vT | 2017-05-10 19:14:39 | https://twitter.com/VinusWine/status/862385414258270208 | VinusWine |
| Susan Hutchinson | 0 | 0 | 0 | 862258418018648064 | Good Morning! Happy Wednesday!! Extra coffee & Ningxia Red for me today... **yawn**... | 2017-05-10 10:50:01 | https://twitter.com/susanhutchinson/status/862258418018648065 | susanhutchinson |
| Forever Young EO | 0 | 0 | 0 | 862115758515662976 | Trust me...every body needs what NingXia Red has! Here's the challenge: Try it for 1 month… https://www.instagram.com/p/BT5KuF3A2NS/ | 2017-05-10 01:23:08 | https://twitter.com/lynene_young/status/862115758515662848 | lynene_young |
| Taunia May | 0 | 0 | 0 | 862080566585328000 | People ask me all the time how I keep my energy up with so many things going on. Ningxia Red is a natural... http://fb.me/5OhmakUrM | 2017-05-09 23:03:18 | https://twitter.com/Taunia1002/status/862080566585327616 | Taunia1002 |
| Caitlin Fisch | 0 | 0 | 0 | 862072238358528000 | Essential Rewards!!! I am so excited that my monthly order is here! We have all the Ningxia for… https://www.instagram.com/p/BT427fhgtM1/ | 2017-05-09 22:30:12 | https://twitter.com/thejoyofcaitlin/status/862072238358528000 | thejoyofcaitlin |
| Barnes Essentials | 0 | 0 | 0 | 861981570361699968 | NingXia Red® is a delicious superfruit beverage that combines whole Ningxia wolfberry puree; a superfruit blend... http://fb.me/7LL66lMjl | 2017-05-09 16:29:55 | https://twitter.com/barnesessential/status/861981570361700352 | barnesessential |
| Sandy Wieber | 0 | 0 | 0 | 861932831169293952 | Support your immune system all year! Start now sunny fall you're way ahead of the game 2oz NingXia Red 1 Shot... http://fb.me/2JOQzX94O | 2017-05-09 13:16:15 | https://twitter.com/wellnesswithoil/status/861932831169294336 | wellnesswithoil |
| Brandy Gates | 0 | 0 | 0 | 861922288547102976 | Get your day started with Ningxia Red. Keep your immune system above… https://www.instagram.com/p/BT3yvIBlLrp/ | 2017-05-09 12:34:21 | https://twitter.com/SBE_BrandyGates/status/861922288547102720 | SBE_BrandyGates |
| Kristina Montes | 0 | 0 | 0 | 861870235187638016 | NingXia is special! Nutrition=support 4 immune, energy, cardio, eye, healthy BP, hair/nails... #nutrition #antioxidants #nomoreenergydrinkspic.twitter.com/kSW52Iebi2 | 2017-05-09 09:07:31 | https://twitter.com/kristina_montes/status/861870235187638273 | kristina_montes |
| Amazing.Mom.SG | 0 | 0 | 1 | 861772549419618048 | Morning Routine Buddies GRAPEFRUIT VITALITY #ningxiared #ningxia #GrapefruitVitality #essentialoil... http://fb.me/11UfNzVDs | 2017-05-09 02:39:21 | https://twitter.com/QQFashionBeauty/status/861772549419618309 | QQFashionBeauty |
| Hari ng Lakbay | 0 | 0 | 0 | 861736140457595008 | Part 6 - Ningxia Night Market 寧夏夜市 - Taiwanese Street Food We are back in Taipei! After an amazing weekend in... http://fb.me/8CTmBJSAn | 2017-05-09 00:14:40 | https://twitter.com/JustinQueyquep/status/861736140457594880 | JustinQueyquep |
| Hari ng Lakbay | 0 | 0 | 0 | 861608312164494976 | After an amazing weekend in Chiayi, we headed back to Taipei. First stop, Ningxia Night Market! This market is... http://fb.me/3DOy1QvZi | 2017-05-08 15:46:44 | https://twitter.com/JustinQueyquep/status/861608312164495361 | JustinQueyquep |
| Amber Joy Olney | 4 | 0 | 0 | 861598216403522048 | This Monday needs COFFEE and OIL and NINGXIA and ARETHA and a LATE START amen?! | 2017-05-08 15:06:37 | https://twitter.com/amberjoyolney/status/861598216403521536 | amberjoyolney |
| Rebecca Pope | 0 | 0 | 0 | 861579824263048960 | NingXia Red Gummies Tutorial! We have a NingXia Red Challenge happening right now in our oils team and I wanted... http://fb.me/234otIH80 | 2017-05-08 13:53:32 | https://twitter.com/Beck_Pope/status/861579824263049217 | Beck_Pope |
| Crafty JBird | 0 | 0 | 0 | 861569485282488064 | When you're still out of Ningxia Red because the box you're waiting for has been sitting 2 hours… https://www.instagram.com/p/BT1STUPBKkU/ | 2017-05-08 13:12:27 | https://twitter.com/craftyjbird/status/861569485282488321 | craftyjbird |
| Roxanne #WeDigYLOils | 0 | 0 | 0 | 861568360709881984 | For sure!!! NINGXIA RED - whole body nutrient drink!! #ReapTheBenefits Order here http://yl.pe/4qp4 Read http://www.ningxiared.com pic.twitter.com/qDy7cdX19w | 2017-05-08 13:07:59 | https://twitter.com/DigTracsChick/status/861568360709881857 | DigTracsChick |
| SaltNPepper | 0 | 0 | 0 | 861555266009128960 | Need a little boost this Monday morning? Throw some En-R-Gee on your feet and drink down a Ningxia Nitro to start... http://fb.me/1jb4BkAOD | 2017-05-08 12:15:56 | https://twitter.com/n_pepper/status/861555266009128962 | n_pepper |
| Essentially Fit | 0 | 0 | 0 | 861369600398765952 | Essentially Fit Club approved! . Take the power of NingXia Red® anywhere you go with Young… https://www.instagram.com/p/BTz3Z-XDfPI/ | 2017-05-07 23:58:10 | https://twitter.com/Michael_Thrash/status/861369600398766080 | Michael_Thrash |
| Amber Sonsalla | 0 | 0 | 0 | 861295927054795008 | RC & NingXia Red- I love RC because it feels great to breathe in deeply + NingXia Red supports my overall wellness with antioxidant power! pic.twitter.com/gxkaaRDz2Y | 2017-05-07 19:05:25 | https://twitter.com/asonsalla2012/status/861295927054794752 | asonsalla2012 |
| Kristen Daschke | 0 | 0 | 0 | 861238624280563968 | #Sunday Ningxia Red wolfberry juice incorporates the benefits of Goji berry, aronia berry and therapeutic... http://fb.me/1n9l8d5SP | 2017-05-07 15:17:43 | https://twitter.com/kristendaschke/status/861238624280563713 | kristendaschke |
| Just A Drop | 0 | 0 | 0 | 861211265464749952 | NingXia Red is a delicious daily supplement that supports normal eye health, cellular function, and energy levels. http://buff.ly/2qJqIQ3 | 2017-05-07 13:29:00 | https://twitter.com/essentialoil5/status/861211265464750080 | essentialoil5 |
| GOIC | 0 | 0 | 0 | 861149873147698944 | GOIC and Ningxia team discuss cooperation http://www.marketstoday.net/news/goic-and-ningxia-team-discuss-cooperation/20245/en/ … via @MarketsTodayme @GOICGCC @AbdulazizAlage3 | 2017-05-07 09:25:03 | https://twitter.com/GOICGCC/status/861149873147699203 | GOICGCC |
| Taunia May | 0 | 0 | 0 | 861006117123620992 | Keeping my energy level up is very important! Lots of amazing stuff going on and gotta keep going! Ningxia Red... http://fb.me/30oaQQfmj | 2017-05-06 23:53:49 | https://twitter.com/Taunia1002/status/861006117123620864 | Taunia1002 |
| Bobbi Raffin | 0 | 0 | 0 | 860954535875031040 | My skeptical husband just tried a NingXia ZING! He loves it!! Even wants to take some to work.… https://www.instagram.com/p/BTw6p3ylDxz/ | 2017-05-06 20:28:51 | https://twitter.com/BobbiRaffin/status/860954535875031040 | BobbiRaffin |
| Alain Deloire | 0 | 0 | 0 | 860880159267856000 | Data from OIV presented a few days ago at the 10th international symposium of viticulture and oenology in Ningxia pic.twitter.com/wZccxbYM6H | 2017-05-06 15:33:19 | https://twitter.com/alaindeloire/status/860880159267856384 | alaindeloire |
| Emily Anderson | 0 | 0 | 0 | 860863912044002944 | Every morning, every body. #ningxia #youngliving #ningxiared #yleo #essentialoils #oilyemily… https://www.instagram.com/p/BTwRchYjrOA/ | 2017-05-06 14:28:45 | https://twitter.com/kadooper/status/860863912044003332 | kadooper |
| Essentially Fit | 0 | 0 | 0 | 860695377820995968 | pee_robi and lo_robi getting great support for body and mind wellness, use NingXia Nitro for… https://www.instagram.com/p/BTvEzD4jqT7/ | 2017-05-06 03:19:03 | https://twitter.com/Michael_Thrash/status/860695377820995585 | Michael_Thrash |
| Roil Oils | 0 | 0 | 0 | 860667534021885952 | Ningxia Red is so good! Add a daily shot of NingXia Red® to your diet to enjoy the benefits of… https://www.instagram.com/p/BTu4JKejOH2/ | 2017-05-06 01:28:25 | https://twitter.com/rcuozzo22/status/860667534021885952 | rcuozzo22 |
| Ashlee Wallace | 0 | 0 | 0 | 860644359733105024 | I wanted to go to bed ... the boys thought chugging Ningxia pouches was a better idea and no,… https://www.instagram.com/p/BTutmwKhVHO/ | 2017-05-05 23:56:20 | https://twitter.com/pastortomswife/status/860644359733104640 | pastortomswife |
| Zhao Li Ying 赵丽颖 HQ | 21 | 0 | 4 | 860530526821555968 | Couple more photos of Li Ying filming for #72FloorsofMystery today in Ningxia #七十二层奇楼 #趙麗穎 #赵丽颖 #จ้าวลี่อิง #zhaoliyingpic.twitter.com/2Phn3fG5c5 | 2017-05-05 16:24:00 | https://twitter.com/zhaoliying_hq/status/860530526821556224 | zhaoliying_hq |
| Erin Slocum | 1 | 0 | 0 | 860196939089837952 | All the sad feelings when my Ningxia bottle is empty. I personally love the glass bottles. I'm not fond of... http://fb.me/8QpAqAIsk | 2017-05-04 18:18:26 | https://twitter.com/erin_slocum/status/860196939089838080 | erin_slocum |
 2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载
2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据 2026年数字化数智化转型趋势报告:价值、AI落地与风险平衡 | 附200+报告、数据合集下载
2026年数字化数智化转型趋势报告:价值、AI落地与风险平衡 | 附200+报告、数据合集下载 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

