
如今DT(Data technology)时代,数据变得越来越重要,其核心应用”预测“也成为互联网行业以及产业变革的重要力量。
对于零售行业来说,预测几乎是商业智能(BI)研究的终极问题,单纯从机器学习的角度来说,做到精准预测很容易,但是结合业务提高企业利润却很难。
预测精确性是核心痛点。
热门视频
业务挑战
针对服装这类的时尚产业的客户需求,tecdat(a)参考ZARA,将产品粗略分为: 基本款和时装。对于基本款,每年都没什么大变化,国际流行的影响也不大,那么可以进行长计划生产。
机器学习是常用的日常分析的方法,另一方面机器学习在海量数据中挖掘其中的规律效果非常好。
首先,销售预测的现状和痛点。销售只是一个商业问题,要做的是满足用户的需求,同时对后续的运营做主导。
而且它的目的并不仅是增加企业的销量,而是能够让企业能够获利,利润增加,所以它是一个商业问题。
对于这样一个商业问题,它在商业环境里面地位是显而易见的,这里面有物流、库存、促销、财务等等四个方面的作用。
对于销售预测的痛点,有三方面:
①商业环境变化莫测,要做到预测非常准确可能会比较困难;
②销售预测并不是一个纯粹的销售预测,它与企业的整体的反应链相关的;
③有企业产品比较单一,或者是服务比较单一,想要通过这个销售预测来做这个指导,来指导研发新的产品,或者是通过价格进行动态定价。
对于时装,决定潮流走向的决策权不在某个区域,一个地方的买手们也没有成长到可以准确预判国际流行趋势,所以需要结合不同区域的各种因素,进行预测。对应的,在新货构成中,销量预测策略为:基本款计划生产,时尚款机动调整。
解决方案
任务/目标
根据服装零售业务营销要求,运用多种数据源分析实现精准销量预测。
数据源准备
沙子进来沙子出,金子进来金子出。无数据或数据质量低,会影响模型预测效果。
在建立的一个合理的模型之前,对数据要进行收集,搜集除已有销量数据之外的额外信息(比如天气、地点、节假日信息等),再在搜集的数据基础上进行预处理。
有了数据,但是有一部分特征是算法不能直接处理的,还有一部分数据是算法不能直接利用的。
特征转换
把不能处理的特征做一些转换,处理成算法容易处理的干净特征。举例如下:
销售日期。就时间属性本身来说,对模型来说不具有任何意义,需要把日期转变成到年份、月份、日、周伪变量。
产品特征。从产品信息表里面可以得到款式、颜色、质地以及这款产品是否是限量版等。然而并没有这些变量。这就需要我们从产品名字抽取这款产品的上述特征。
以上例举的只是部分特征。
构造
以上说明了如何抽取相关特征,我们大致有如下训练样本(只列举部分特征)。
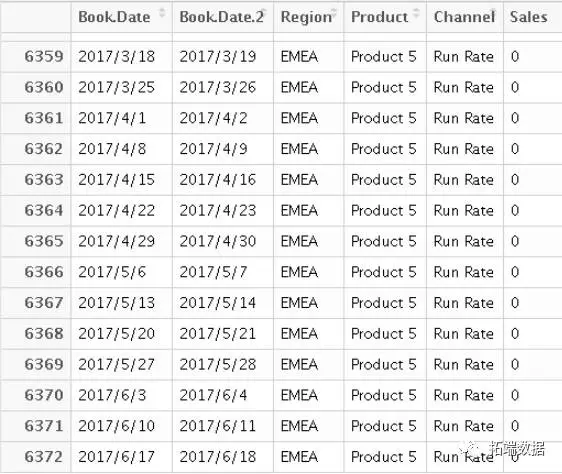
划分训练集和测试集
考虑到最终模型会预测将来的某时间段的销量,为了更真实的测试模型效果,以时间来切分训练集和测试集。
具体做法如下:假设我们有2014-02-01 ~ 2017-06-17的销量相关数据。以2014-02-01 ~ 2016-03-19的销量数据作为训练,2016-03-20~2017-06-17的数据作为测试。
建模
ARIMA
ARIMA,一般应用在股票和电商销量领域
ARIMA模型是指将非平稳时间序列转化为平稳时间序列,然后将结果变量做自回归(AR)和自平移(MA)。

随机森林
用随机的方式建立一个森林,森林由很多决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
支持向量回归(SVR)
SVR最本质与SVM类似,都有一个margin,只不过SVM的margin是把两种类型分开,而SVR的margin是指里面的数据会不会对回归有帮助。
随时关注您喜欢的主题
模型优化
1.上线之前的优化:特征提取,样本抽样,参数调参。
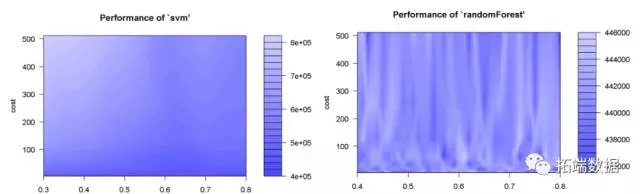
2.上线之后的迭代,根据实际的A/B testing和业务人员的建议改进模型
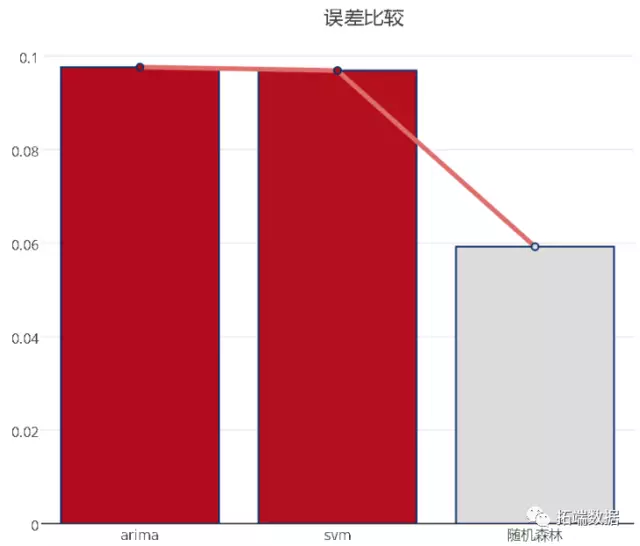
从上图可以看出,在此案例中,svm和随机森林算法模型的预测误差最小,运用3种方法预测某商品的销量,其可视化图形如下:
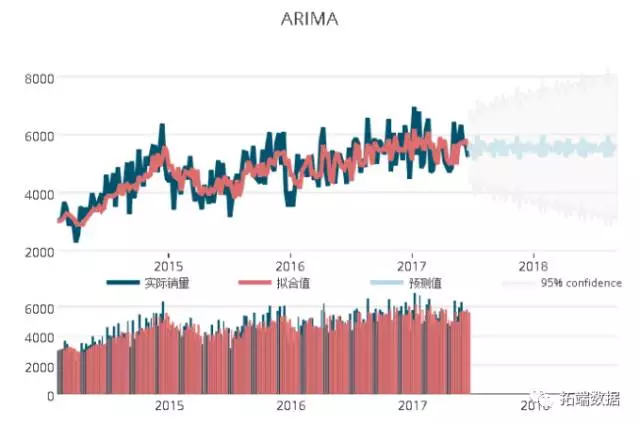
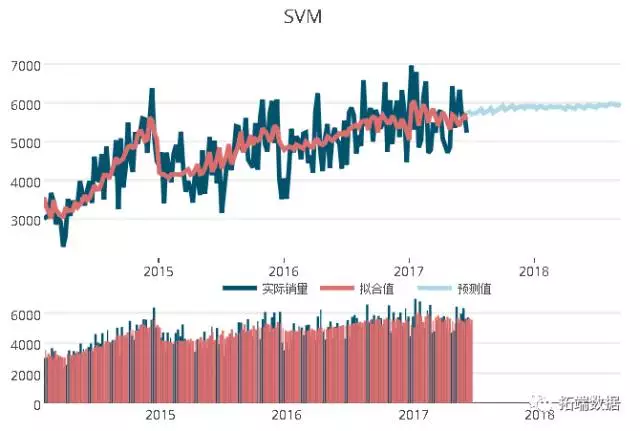
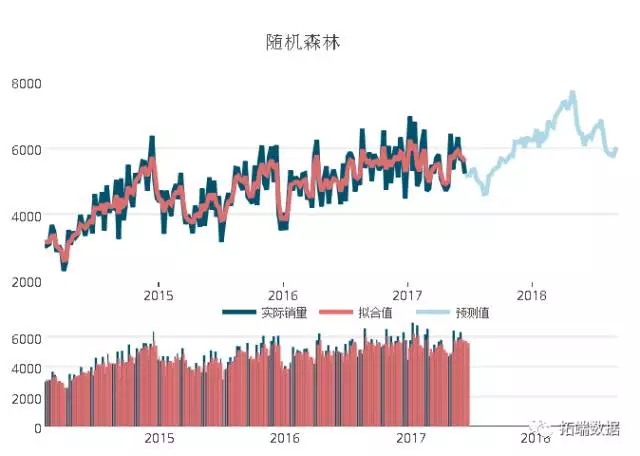
可以看出,销量的预测值的趋势已经基本与真实销量趋势保持一致,但是在预测期较长的区间段,其预测值之间的差别较大。
评估效果不能只看销量,要综合考虑,需要参考业务对接、预测精度、模型可解释性和产业链整体能力等因素综合考虑;不能简单作为企业利润增加的唯一标准。我们的经验是,预测结果仅作为参考一个权重值,还需要专家意见,按照一定的权重来计算。
展望
除了以上列举的一些方法,tecdat(a)已经在尝试更复杂的销售预测模型,如HMM、深度学习(Long Short-Term Memory网络、卷积神经网络(CNN))等;同时需要考虑到模型的可解释性、可落地性和可扩展性、避免“黑箱”预测;还在尝试采用混合的机器学习模型,比如GLM+SVR,ARIMA + NNET等。
销售预测几乎是商业智能研究的终极问题,即便通过机器学习算法模型能够提高测试集的预测精度,但是对于未来数据集的预测,想做到精准预测以使企业利润最大化,还需要考虑机器学习模型之外的企业本身因素。
比如,企业的整体供应链能力等,如何将企业因素加入到机器学习模型之中,是未来预销售预测的一个难点与方向。因此,要想解决销售预测终极问题还有一段路要走。
 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



