
在数据分析领域,当我们面对一组数据时,通常会有已知的分组情况,比如不同的治疗组、性别组或种族组等。
然而,数据中还可能存在未被观测到的分组,例如素食者与非素食者、经常锻炼者与不锻炼者,或者有某种疾病家族史与无家族史的人群(假设这些数据未被收集)。
针对这种情况,有相应的分析方法,本文将帮助客户围绕潜在类别分析(Latent Class Analysis,LCA)和混合建模(Mixture Modeling,MM,有时也指有限混合建模Finite MM)展开讨论,并通过实例展示其在纵向数据中的应用。


作者

Kaizong Ye
可下载资源
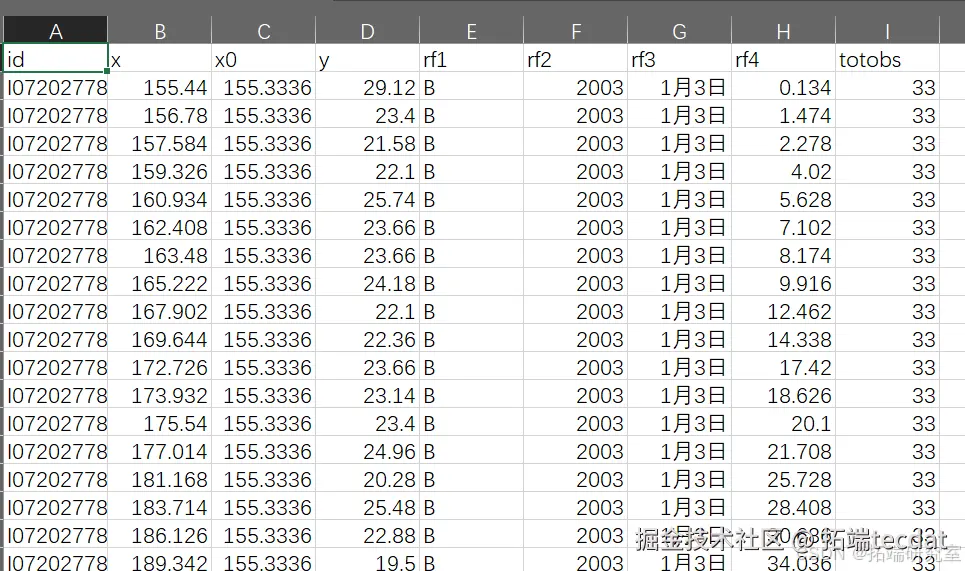
数据量较大,有超过2000个受试者,每个受试者最多有80个时间点。首先绘制所有数据,结果如图1所示。
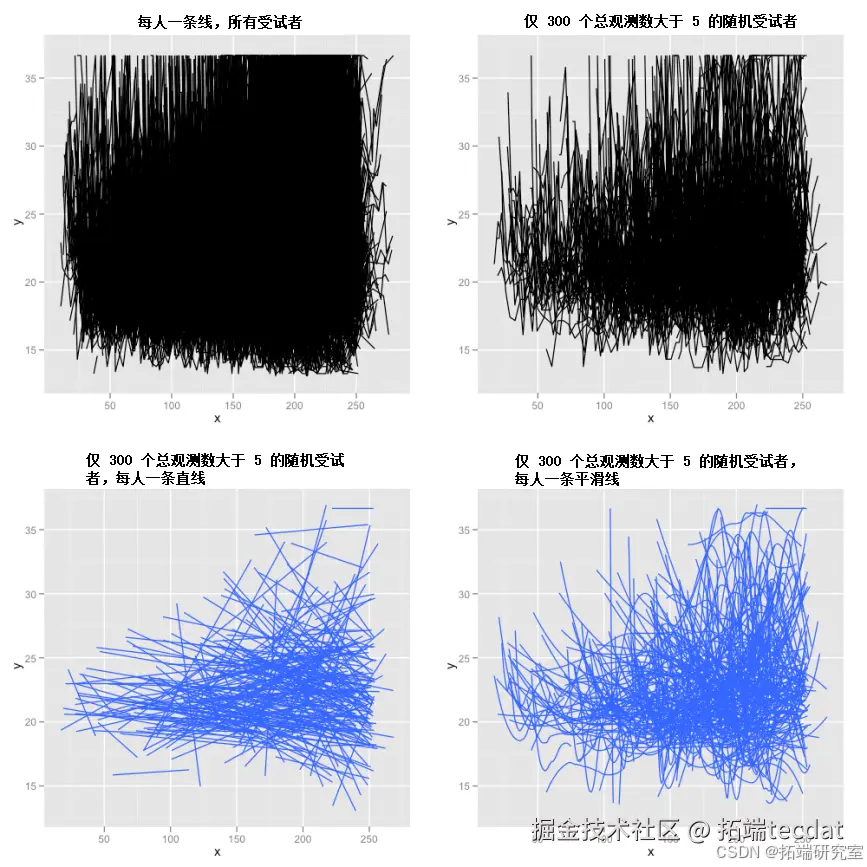
图1 所有数据图
有人可能认为第一个图(左上角)没有展示出有效信息,但实际上可以明显看出右上角部分的数据密度远高于左上角,即更多人最终的值高于起始值。接下来的三个图展示了300个随机选择且至少有5个时间点的受试者数据,以避免数据过于杂乱。右上角是原始数据图,左下角是为每个人拟合的直线,右下角是使用ggplot2软件包中geom_smooth()函数默认设置为每个人拟合的平滑曲线(loess)。进一步去除杂乱数据后,更能突出图右侧与左侧相比数据分布的增加。
平滑算法展示
这里简单直观地展示loess平滑算法的工作原理。图2展示了3个有较多数据的受试者,包括他们的原始(锯齿状)图、平滑曲线以及二者结合,突出该算法如何准确描绘趋势并去除噪声,使我们能轻松识别趋势路径。
图2 loess平滑算法示例
模型构建与分析
用户能够指定希望算法找到的潜在类别(未观测到的组)数量。以下代码用于在数据中寻找2个潜在类别:
# 寻找2个潜在类别
result2 <- lcmm(y_variable ~ x
这里使用自变量x_variable对因变量y_variable进行建模,允许x_variable因人而异(随机斜率),并使用(线性)x_variable作为混合项中的变量。目前先保持简单,后续会考虑更合适的模型。在输出结果中,从摘要的主要部分可以看到,“x 1”和“x 2”行表明每个类别有不同的斜率,一个略为正,一个略为负,且截距(见“intercept 2”)也有很大差异。
同时,模型还提供了拟合优度统计量。其中,组隶属的后验概率很重要,每个受试者被分配到每个(2个)类别的概率如下:
# 查看后验概率随时关注您喜欢的主题

可以看到一个类别中有62%的受试者,另一个有38%。属于类别1的受试者,其属于类别1的平均后验概率为0.93,属于类别2的平均后验概率为0.09。类似地,属于类别2的受试者,其属于类别2的平均后验概率为0.90,属于类别1的平均后验概率为0.07。通过以下代码进一步查看,最小值接近0.5,说明一些受试者的轨迹可能确实属于任意一个类别,令人欣慰的是两个下四分位数都大于0.80。
进一步查看后验概率统计



想了解更多关于模型定制、咨询辅导的信息?
由于处理的是趋势和轨迹,我们可能希望可视化其对数据的意义。通过以下代码,提取受试者所属类别,并根据类别对数据进行绘图:
结果如图3所示。
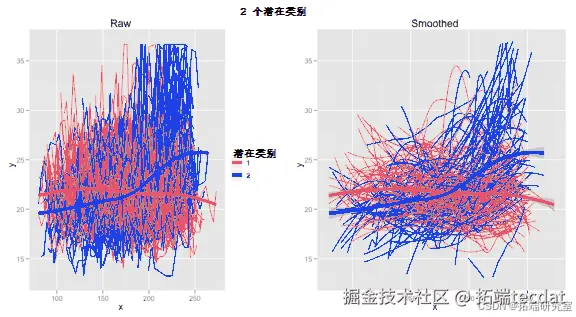
图3 2个潜在类别数据图
从图中可以看到预期结果
首先,对一个类别内所有数据进行平滑处理时,线相交,表明类别确实产生了实际影响。如果看到两条平行线,可能意味着每个人都有相同“类型”的轨迹,那么类别可能只是算法为了“找到两个类别”而产生的人为结果。这里特别的是,可以看到类别2中的一组受试者在x达到200时,y值迅速上升,而类别1中的受试者y值通常保持稳定。
尝试3个类别时,结果如图4所示。
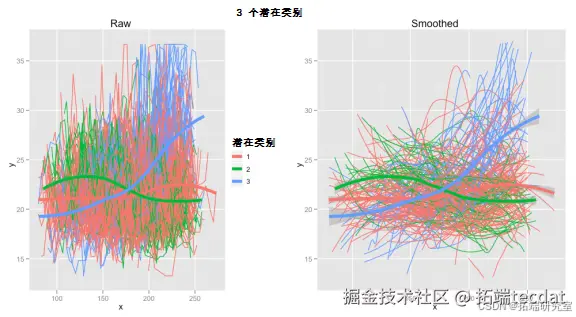
图4 3个潜在类别数据图
尝试4个类别时,结果如图5所示。
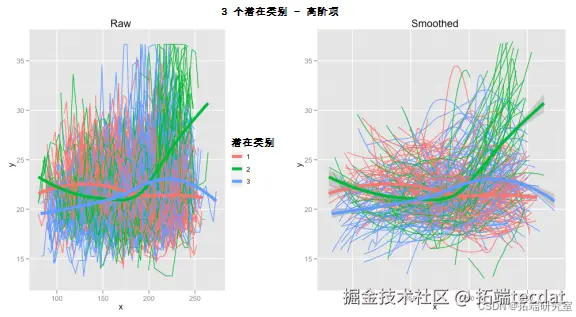
在选择合适的类别数量时,普遍接受的方法是使用贝叶斯信息准则(BIC),而不是赤池信息准则(AIC),BIC值越低,模型越好。对于此数据,4个类别的BIC为32941,3个类别的BIC为32972,2个类别的BIC为33084,这表明4个类别比3个类别拟合得稍好。实际上,5个类别能使BIC更低,但如同所有建模一样,需要人为(或到2035年非常智能的AI机器人)干预。在4个类别中,第4个类别仅包含10%的受试者,在本研究的数据子集中,即25人。需要根据数据情况决定是否合适,这里认为不应低于10%。
模型优化
如前所述,线性效应可能不是对该数据建模的最佳方式。这里选择3个类别,并引入二次项,结果如图6所示。与之前3个潜在类别的图相比,有一些细微差异。
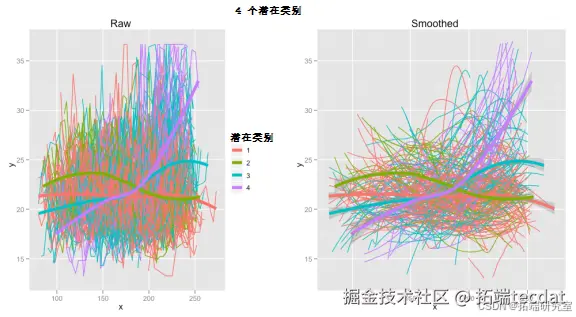
图6 含二次项3个潜在类别数据图
在考虑后验概率和类别成员百分比时,仅含线性项的模型和含二次项的模型有很大差异。似乎二次项在确定每个受试者属于哪个类别时更困难。具体如下:
仅含线性项

含二次项
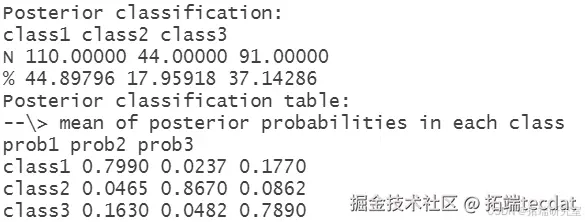
然而,BIC实际上从32972降至32594,这一差异比改变类别数量时看到的差异大得多。在这种情况下,一方面需要进一步探索模型;另一方面,如果必须做出选择,会倾向于仅基于线性项的模型,因为其在确定受试者所属类别时,后验概率表现优于基于BIC的模型 。
结论
未来的研究可以在此基础上,进一步探索不同的模型设定和参数选择,以更好地适应各种复杂的数据结构和研究问题。例如,可以尝试结合其他变量或考虑不同的混合分布形式,以提高模型的解释能力和预测精度。此外,对于处理纵向数据中缺失值的方法,也可以进行更深入的研究和比较,以确保分析结果的可靠性和稳定性。同时,随着数据量的不断增大和数据维度的增加,如何提高算法的计算效率和可扩展性也是值得关注的问题。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言生存分析模型因果分析:非参数估计、IP加权风险模型、结构嵌套加速失效(AFT)模型分析流行病学随访研究数据
R语言生存分析模型因果分析:非参数估计、IP加权风险模型、结构嵌套加速失效(AFT)模型分析流行病学随访研究数据 R语言潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
R语言潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据 R语言估计多元标记的潜过程混合效应模型(lcmm)分析心理测试的认知过程
R语言估计多元标记的潜过程混合效应模型(lcmm)分析心理测试的认知过程 R语言如何用潜类别混合效应模型(lcmm)分析抑郁症状
R语言如何用潜类别混合效应模型(lcmm)分析抑郁症状



