统计量T是数据的一个函数,不依赖于任何未知参数(即我们可以根据数据计算得到它)。这意味着给定数据值x1,x2,⋯,xn,统计量T就是一个”数字”。
然而,在观察到数据之前,“数据”是随机变量X1,X2,⋯,Xn,而我们的统计量T作为随机变量的函数,也是一个随机变量。T的分布被称为”抽样分布”。
例如,如果我们有以下数据:
可下载资源
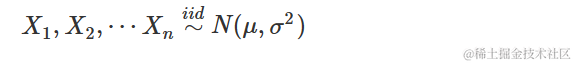
感兴趣的统计量是X¯=1/n∑ni=1Xi,我们知道
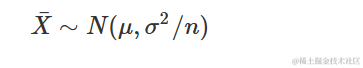
这就是X¯的抽样分布。统计量的抽样分布并不总是容易找到。让我们考虑两种抽样分布更难以通过解析方法找到的情况。
情况1
假设我们有来自一个倾斜分布的40个数据点。下面给出了数据的直方图。
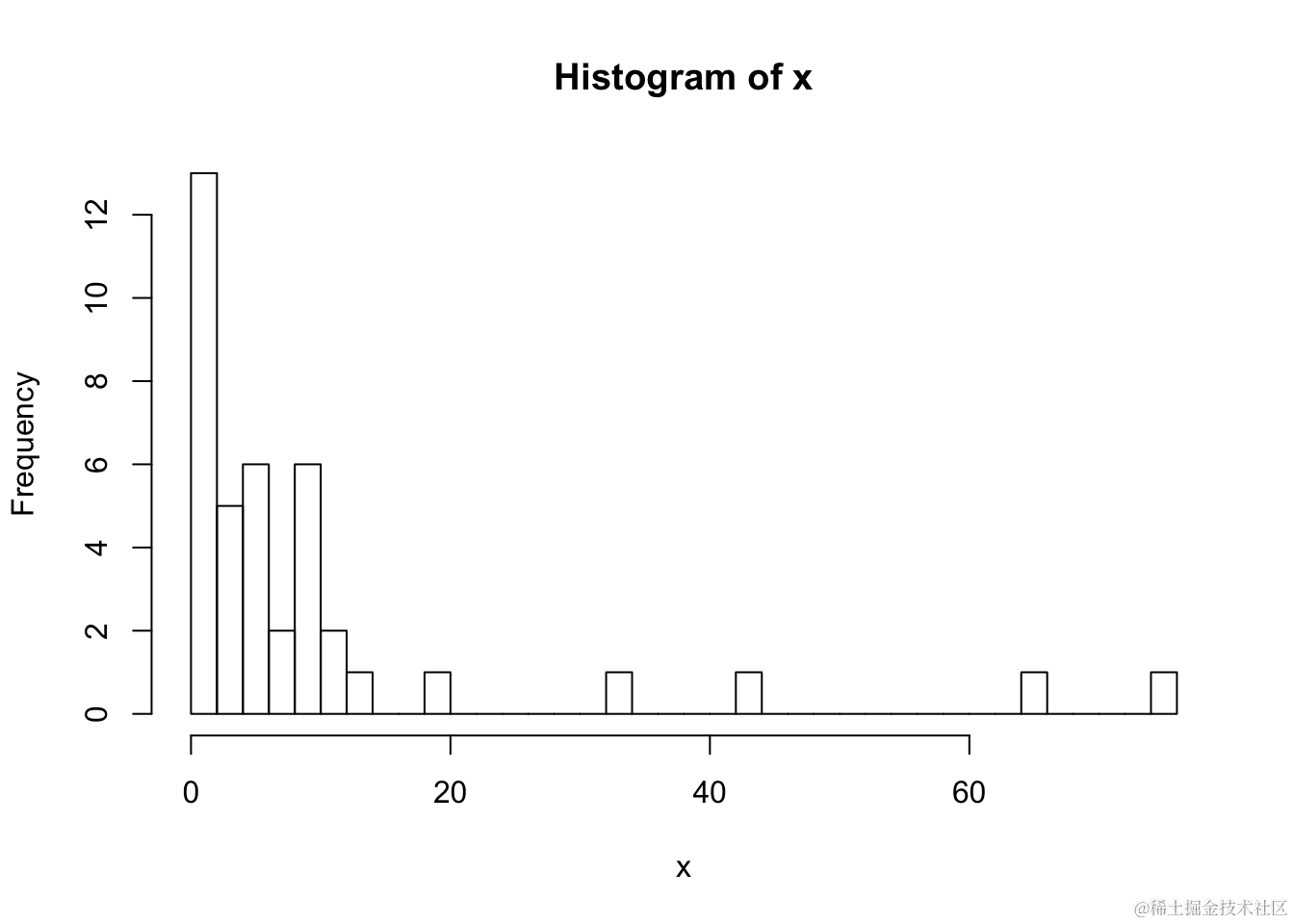
我们首先计算样本均值和样本标准差。
#数据的平均值
mean(x)

#数据的方差
var(x)
中心极限定理告诉我们,当n很大时,样本均值将服从正态分布。但是这里有一个重要问题:我们怎么知道n是否足够大呢?尽管数据倾斜严重,我们应该相信CLT的近似吗?
情况2
考虑一组新的200个数据点(我们将这些数据称为yi)。直方图如下所示
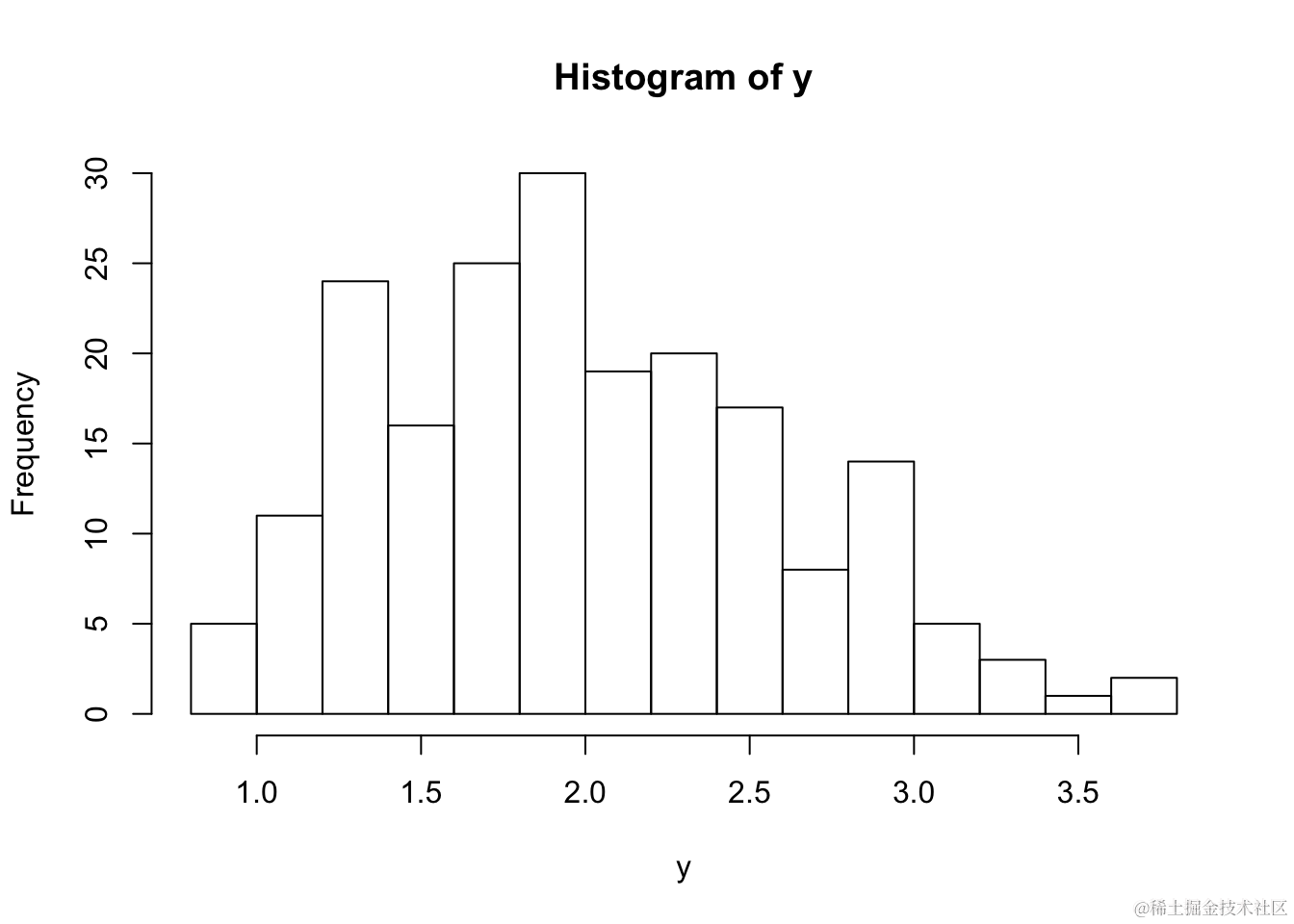
这个分布是右偏的还是对称的?很难说。回想一下,分布的总体偏度定义为
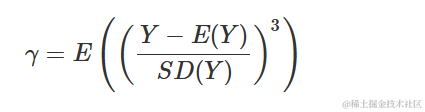
这个参数的一个简单估计量(统计量)是下面给出的”样本偏度”
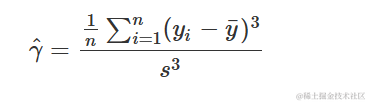
基本思想是,如果样本数据准确反映了总体,我们可以”重新采样”数据并构建统计量T的抽样分布的近似值。这个近似值有时被称为T的”Bootstrap分布”。需要记住的是,像大多数统计方法一样,当样本量非常小时,Bootstrap可能会失败。
随时关注您喜欢的主题
算法其实相当简单,步骤如下:
- 通过从原始数据中(有放回地)抽样,创建一个“新”数据集,直到你有一个大小为 n 的新数据集。
- 计算这个新数据集的检验统计量,并将其称为 T1。
- 重复步骤 1 和 2 多次(比如说 B 次),这样你就得到了一系列的估计值 T1,T2,⋯,TB。这是对 T 的抽样分布的数值近似。
情况1 – 使用自助法
在这个例子中,我们可以使用自助法来近似样本均值 X¯ 的抽样分布。如果自助法的分布看起来近似正态分布,那么我们可以合理地认为中心极限定理(CLT)会给出一个不错的近似结果。
如果不是,我们应该怀疑是否能够信任CLT对于这个数据的适用性。
B <- 1000 #设置 B 为一个较大的数值
boot......) #创建一个向量来存储自助法的估计值
for(i in 1:B){
x_new <......ce=T) #创建新数据集
boot_......(x_new) #存储自助法的估计值
}
现在,我们已经构建了自助法的分布,我们可以绘制它并检查其是否服从正态分布。
par(m......1,2)) #将图形放置在一行的两个子区域中
#绘制带有叠加正态密度曲线的自助法分布直方图
hist(boo......)), add=T, col='red', lwd=2)
#创建自助法分布的 QQ 图
qqnorm(......从这些图中可以明显看出,样本均值 X¯ 的抽样分布稍微右倾。
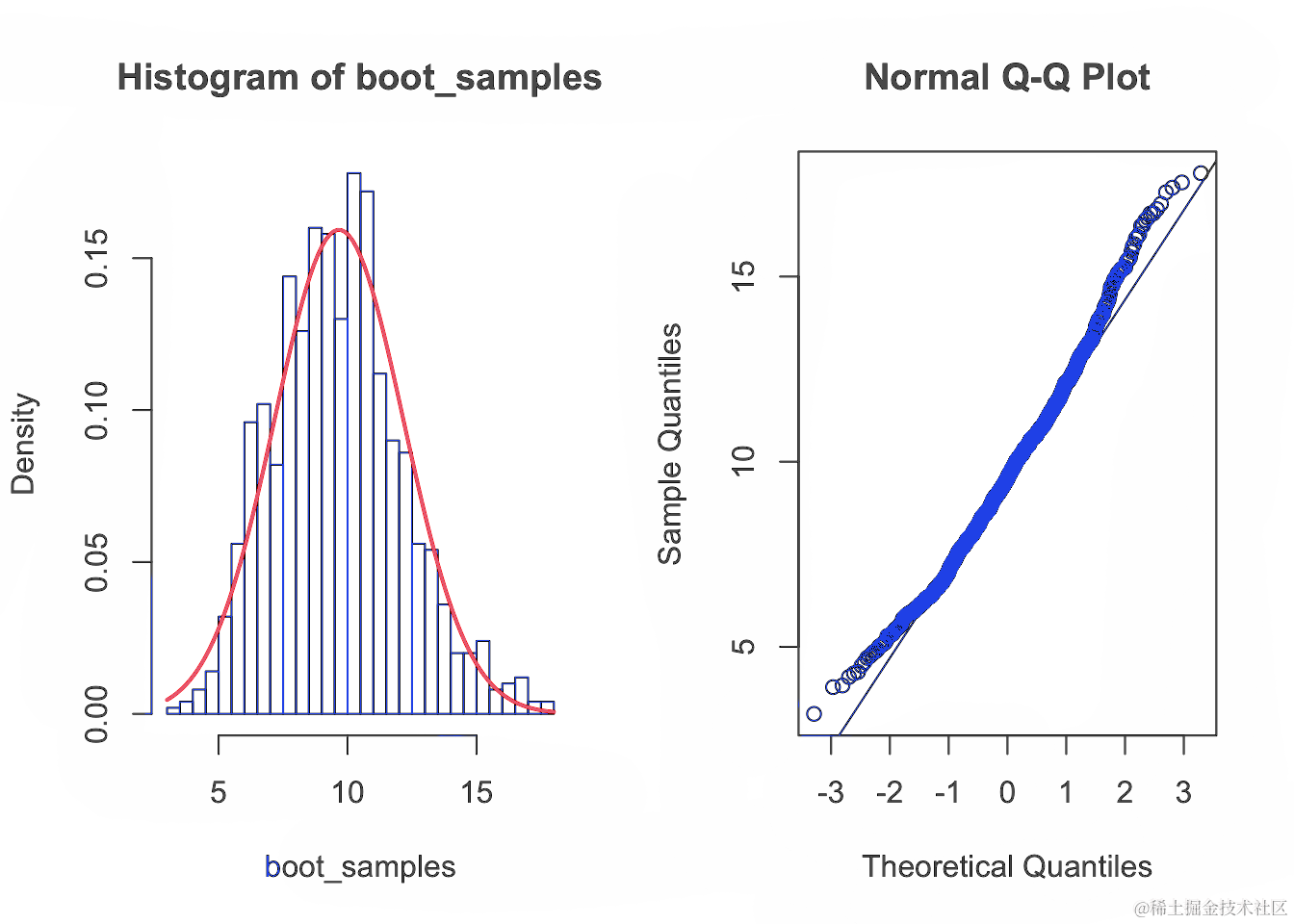
严格来说,在我们完全相信CLT之前,可能需要更多的样本。不过,自助法的分布近似正态分布,因此CLT可能会给出合理的答案。
情况2 – 使用自助法
我们可以首先计算原始数据的样本偏度。
#计算样本偏度
n = len(y)
......

我们可以观察到,偏度是正的,表明数据略微向右倾斜。但这个结果有多显著呢?由于样本大小相当大,这是一个很好的自助法(bootstrap)的应用场景。让我们使用以下方法来近似估计 γ̂。
n = len(y) # 获取样本大小
B = 1000 # 设置一个较大的B
boot_sample......
NA, B) # 创建一个向量来存储自助法估计值
for i in 1:B:
y_new = sam......
ace=T) # 创建新的数据集
boot_sam......
) / sd(y_new)^3 # 存储自助法估计值
hist(boot_s......
s=20) # 显示自助法分布
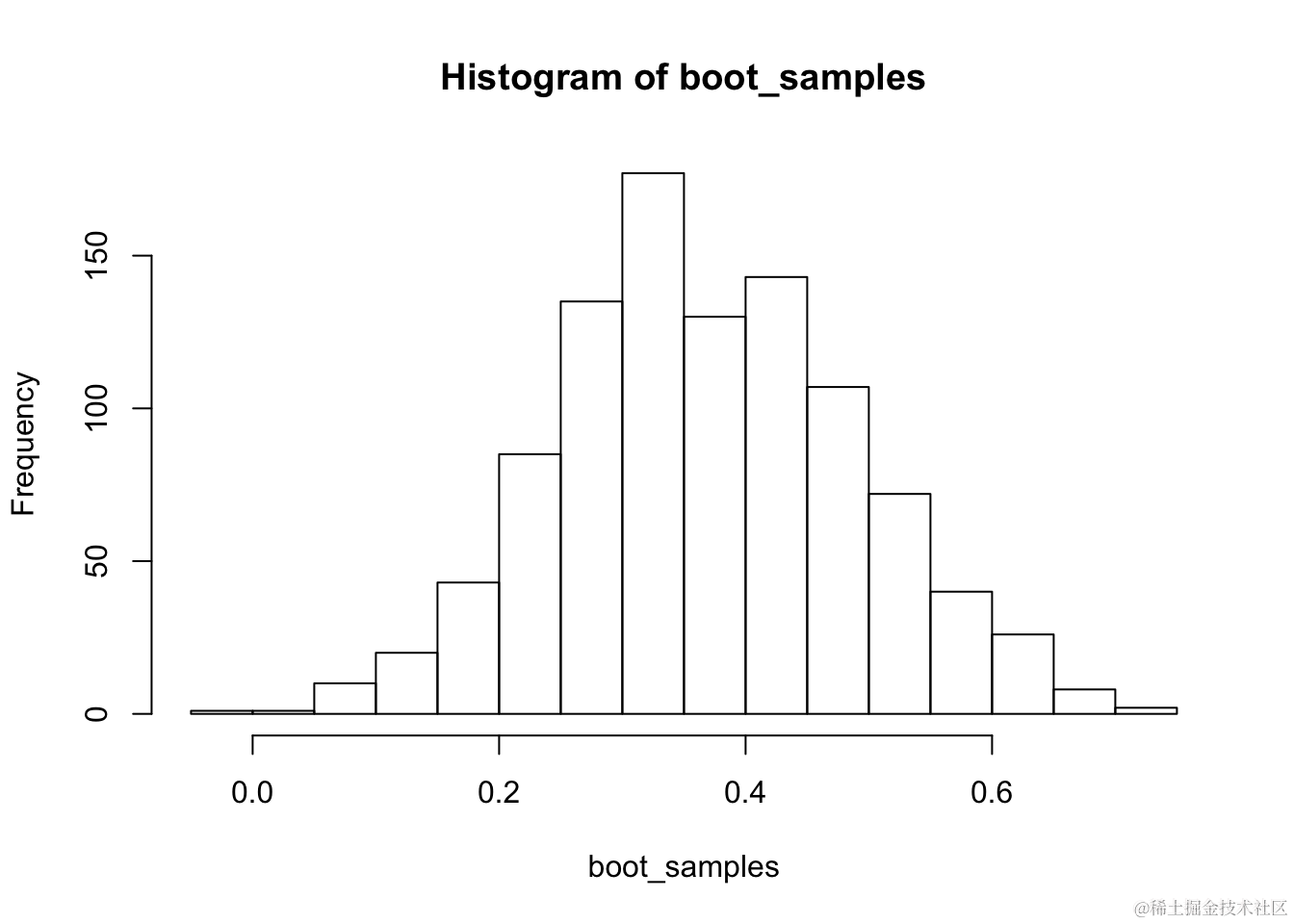
现在,我们已经得到了对抽样分布的近似,我们可以找到一个自助置信区间来表示 γ̂。对于给定的置信水平 C ∈ (0,1),我们可以找到包含中间 C×100% 的自助法估计值的区间 (a,b)。在R中,可以通过以下方式轻松完成。
# 将置信水平设置为0.95
C = 0.95
alpha = 1 - C
# 获取置信区间
CI = quantile(boot_s......
2))
CI
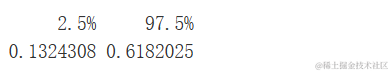
# 绘制自助法分布并显示置信区间
hist(boot_sampl......
ty=3)
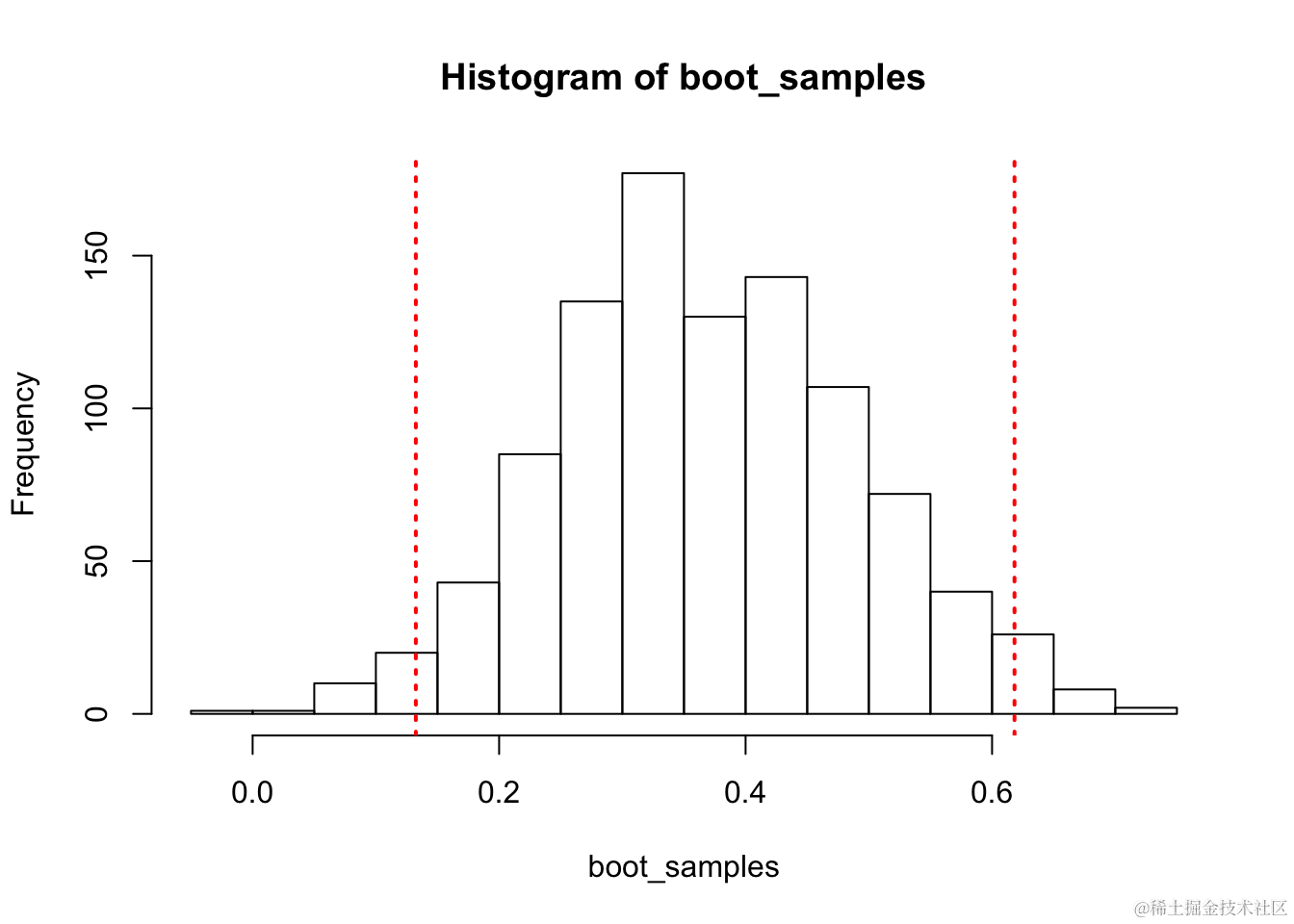
对于这个区间的解释大致如下:我们有95%的置信度,真实的总体偏度在 0.132 和 0.618 之间。因此我们在某种程度上可以相信这个分布的偏度是正的。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 专题|Python梯度提升实例合集:GBM、XGBoost、SMOTE重采样、贝叶斯、逻辑回归、随机森林分析信贷、破产数据
专题|Python梯度提升实例合集:GBM、XGBoost、SMOTE重采样、贝叶斯、逻辑回归、随机森林分析信贷、破产数据 【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现
【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现 R语言广义线性混合模型(GLMM)bootstrap预测置信区间可视化
R语言广义线性混合模型(GLMM)bootstrap预测置信区间可视化



