零膨胀泊松回归用于对超过零计数的计数数据进行建模。
此外,理论表明,多余的零点是通过与计数值不同的过程生成的,并且可以独立地对多余的零点进行建模。
因此, zip 模型有两个部分,泊松计数模型和用于预测多余零点的 logit 模型。
ZIP模型,即零通货膨胀泊松模型(Zero-Inflated Poisson Model),是一个用于描述计数数据的统计模型。它特别适用于处理数据中过多的零计数情况。ZIP模型结合了泊松分布和逻辑回归(logit模型)来处理这种情况。
泊松分布是一种常见的统计学模型,用于描述在一定时间或空间内某事件发生的次数。它基于泊松分布的假设,即事件发生的概率是固定的,并且事件之间是相互独立的。在ZIP模型中,泊松部分用于描述非零计数的分布特性。
而logit模型(也称作“评定模型”,“分类评定模型”,或“逻辑回归”)是一种离散选择法模型,常用于处理二元分类问题。在ZIP模型中,logit部分用于预测那些额外的零计数。具体来说,它可以帮助确定一个观测值是否应该被归为零计数,而不是由泊松分布生成的。

零膨胀泊松回归示例
示例 。野生动物生物学家想要模拟公园的渔民捕获了多少鱼。游客会被问到他们逗留了多长时间,团队中有多少人,团队中是否有儿童以及捕获了多少鱼。一些游客不钓鱼,但没有关于一个人是否钓鱼的数据。一些钓鱼的游客没有钓到任何鱼,因此数据中存在多余的零,因为人们没有钓鱼。
1.零膨胀现象:在计数数据中,若0的个数明显多于泊松、负二项等标准离散分布隨机产”生的个数,称此现象为零过多现象(zero-inflated, ZI)
2.零膨胀模型:伯努利分布与普通计数分布(泊松等)的混合分布,分为零数据部分及非零计数部分。
3.结构零&抽样零:零膨胀模型零数据部分-部分来自于普通计数分布产生的抽样零,另一部分来自于额外得到的结构零。实际上,结
构零可以看成由取值为零的退化总体产生,抽样零则是由非退化总体(Poisson分布等) 产生。
例如:在调查一种药物的吸食状况数据时,且该药物吸食数据已经通过Poisson分布检验,则可以认为,抽样零表示Poisson分布中产生的
零数据,结构零表示在调研过程中吸食过该类药物却表示从未吸食过的受访者所产生的额外零数据。
数据说明
让我们从上面的示例开始。
我们有 250 个去公园的团体的数据。每个小组都被询问他们捕获了多少鱼(count),小组中有多少孩子(child),小组中有多少人(persons),以及他们是否带露营者到公园(camper)。
让我们看一下数据。
summary(zib)

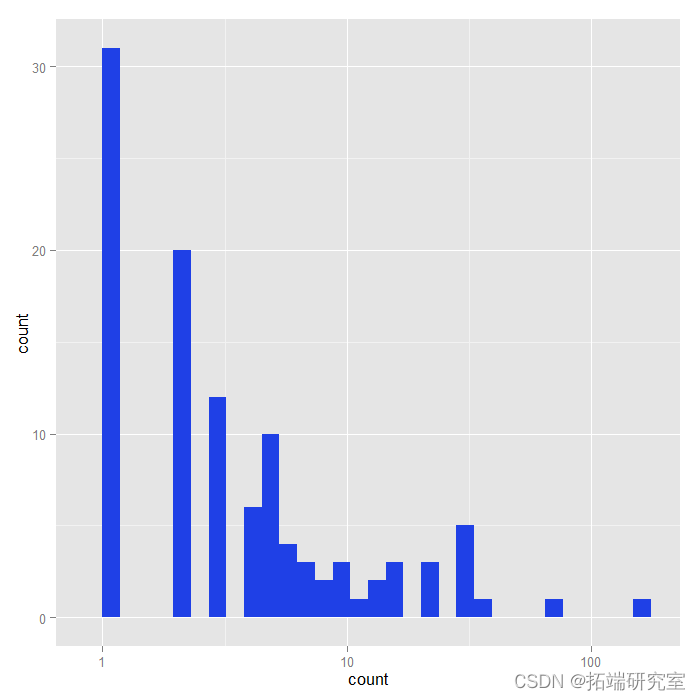
## 直方图的X轴为对数10标 ggplot(znb, aes(ount))
您可能会考虑的分析方法
以下是您可能遇到的一些分析方法的列表。列出的一些方法是相当合理的,而另一些方法要么失宠,要么有局限性。
- 零膨胀泊松回归。
- 零膨胀负二项式回归——负二项式回归在分散数据时表现更好,即方差远大于平均值。
- 普通计数模型 。
- OLS 回归——您可以尝试使用 OLS 回归分析这些数据。然而,计数数据是高度非正态的,并且不能通过 OLS 回归很好地估计。
零膨胀泊松回归
summary(m1)

输出看起来非常像 R 中两个 OLS 回归的输出。在模型调用下方,您会发现一个输出块,其中包含每个变量的泊松回归系数以及标准误差、z 分数和 p 值系数。接下来是对应于通货膨胀模型的第二个块。这包括用于预测多余零点的 logit 系数及其标准误差、z 分数和 p 值。

模型的计数和膨胀部分中的所有预测变量都具有统计显着性。该模型对数据的拟合显着优于空模型,即仅截距模型。为了证明情况确实如此,我们可以使用对数似然差异的卡方检验将当前模型与没有预测变量的空模型进行比较。
mnl <- update(m1, . ~ 1)
随时关注您喜欢的主题

由于我们在完整模型中有三个预测变量,因此卡方检验的自由度为 3。这会产生较高的显着 p 值;因此,我们的整体模型具有统计学意义。
请注意,上面的模型输出并没有以任何方式表明我们的零膨胀模型是否是对标准泊松回归的改进。我们可以通过运行相应的标准 Poisson 模型然后对这两个模型进行 Vuong 检验来确定这一点。

vuong(p, m)
Vuong 检验将零膨胀模型与普通泊松回归模型进行比较。
在这个例子中,我们可以看到我们的检验统计量是显着的,表明零膨胀模型优于标准泊松模型。
我们可以使用自举获得参数和指数参数的置信区间。对于泊松模型,这些将是事件风险比,对于零通胀模型,优势比。此外,对于最终结果,可能希望增加重复次数以帮助确保结果稳定。
dt(coef(m1, "count"))

dpt(coef(m1, "zero"))

结果是交替的参数估计和标准误差。
res <- boot(znb, f, R = 1200, pralel = "snow", ncus = 4) ## 输出结果 res

也就是说,第一行具有我们模型的第一个参数估计值。第二个具有第一个参数的标准误差。第三列包含自举的标准误差。
现在我们可以得到所有参数的置信区间。我们从原始比例开始,使用百分位数和偏差调整的 CI。我们还将这些结果与基于标准误差的置信区间进行比较。
## 带百分位数和偏差调整的CI的基本参数估计值 ## 添加行名 row.names(pms) <- names(coef(m)) ## 输出结果 parms

## 与基于正常的近似值相比 confint(m1)

bootstrap置信区间比基于正态的近似值要宽得多。使用稳健标准误差时,自举 CI 与来自 Stata 的 CI 更加一致。
现在我们可以估计泊松模型的事件风险比 (IRR) 和逻辑(零通胀)模型的优势比 (OR)。
## 带百分位数和偏差调整的CI的指数化参数估计值
exps <- t(sapply(c(1, 3, 5, 7, 9), function(i) {
out <- boot.ci
为了更好地理解我们的模型,我们可以计算预测变量的不同组合所捕获的鱼的预期数量。事实上,由于我们基本上使用的是分类预测,我们可以使用函数来计算所有组合的期望值来创建所有组合。最后我们创建一个图表。
ggplot(neda1, aes(x = cld, y = pat, colour = factor(pos))) + geom_point() + geom_line() + facet_wrap(~cmp)

需要考虑的事项
- 由于 zip 同时具有计数模型和 logit 模型,因此这两个模型中的每一个都应该具有良好的预测器。这两个模型不一定需要使用相同的预测变量。
- 零膨胀模型的逻辑部分可能会出现完美预测、分离或部分分离的问题。
- 计数数据通常使用暴露变量来指示事件可能发生的次数。
- 不建议将零膨胀泊松模型应用于小样本。

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据
Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据 Python电动汽车充电网络优化研究——泊松过程、排队、贪心算法、模拟退火、聚类、差分演化DE、双目标动态规划、滚动时域预测控制MPC分析储能调度、电网负荷数据|附代码数据
Python电动汽车充电网络优化研究——泊松过程、排队、贪心算法、模拟退火、聚类、差分演化DE、双目标动态规划、滚动时域预测控制MPC分析储能调度、电网负荷数据|附代码数据 Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究 Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究
Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究
