在许多网站上都可以找到一个流行的德国信贷数据集_german_credit_,其中包含了银行贷款申请人的信息。
该文件包含1000名申请人的20条信息。
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
下面的代码可以用来确定申请人是否有信用,以及他(或她)是否对贷款人有良好的信用风险。有几种方法被应用到数据上,帮助做出这种判断。在这个案例中,我们将看一下这些方法。
German Credit数据是根据个人的银行贷款信息和申请客户贷款逾期发生情况来预测贷款违约倾向的数据集,数据集包含24个维度的,1000条数据。
该数据集将通过一组属性描述的人员分类为良好或不良信用风险。
数据集将通过一组属性描述的人员分类为良好或不良信用风险。
有两种格式(全都是数字格式)。还带有成本矩阵。不好的时候将客户分类为好(5),而不是好的时将客户分类为坏(1)
数据说明
| 名称 | 类型 | 描述 |
|---|---|---|
| checking_account_status | string | 现有支票帐户的状态(A11:<0 DM,A12:0 <= x <200 DM,A13:> = 200 DM /至少一年的薪水分配,A14:无支票帐户) |
| duration | integer D | 持续时间(月) |
| credit_history | string | A30:未提取任何信用/已全额偿还所有信用额,A31:已偿还该银行的所有信用额,A32:已到期已偿还的现有信用额,A33:过去的还款延迟,A34:关键帐户/其他信用额现有(不在此银行) |
| purpose | string | A30:未提取任何信用/已全额偿还所有信用额,A31:已偿还该银行的所有信用额,A32:已到期已偿还的现有信用额,A33:过去的还款延迟,A34:关键帐户/其他信用额现有(不在此银行) |
| credit_amount | float | |
| savings | string | 账户/债券储蓄(A61:<100 DM,A62:100 <= x <500 DM,A63:500 <= x <1000 DM,A64:> = 1000 DM,A65:未知/无储蓄账户 |
| present_employment | string | 71:待业,A72:<1年,A73:1 <= x <4年,A74:4 <= x <7年,A75:..> = 7年 |
| installment_rate | float | 分期付款率占可支配收入的百分比 |
| personal | string | 个人婚姻状况和性别(A91:男性:离婚/分居,A92:女性:离婚/分居/已婚,A93:男性:单身,A94:男性:已婚/丧偶,A95:女性:单身) |
| other_debtors | string | A101:无,A102:共同申请人,A103:担保人 |
| present_residence | float | 至今居住 |
| property | string | A121:不动产,A122:如果不是,那么A121:建筑协会储蓄协议/人寿保险,A123:如果不是,则A121 / A122:不是属性6的汽车或其他,A124:未知/没有财产 |
| age | float | 年岁 |
| other_installment_plans | string | A141:银行,A142:商店,A143:无 |
| housing | string | A151:租房,A152:自有,A153:免费 |
| existing_credits | float | 该银行现有信贷的数量 |
| job | string | 1:失业/A171 : 非技术人员-非居民,A172:非技术人员-居民,A173:技术人员/官员,A174:管理/个体经营/高度合格的员工/官员 |
| dependents | integer | 承担赡养费的人数 |
| telephone | string | A191:无,A192:有,登记在客户名下 |
| foreign_worker | string | A201: 有, A202: 无 |
| customer_type | integer | 预测类别:1 =良好,2 =不良 |
请注意,本例可能需要进行一些数据处理,以便为分析做准备。
我们首先将数据加载到R中。
credit <- read.csv(credit, header = TRUE, sep = ',')
这段代码在数据上做了一个小的处理,为分析做准备。否则,就会出现错误,因为在某些文件的某一列中发现有四类因素。
基本上,任何4类因变量都被覆盖为3类。继续进行分析。
No.of.Credits\[No.of.Credits == 4\] <- 3
快速浏览一下数据,了解一下我们的工作内容。
str(credit)


你可能会立即注意到有几个变量很显眼。我们要排除它们。”信贷期限(月)”、”信贷金额 “和 “年龄”。
为什么?
我们在这个模型中试图把重点放在作为信用价值指标的数据分类或类别上。这些是分类变量,而不是数字变量。申请人有电话吗?申请人是否已婚?是否有共同签署人?申请人在同一地址住了多长时间?这类事情。
关于这些因素,重要的是我们知道它们与贷款决定的关系。良好的信用与某些因素的组合有关,从而使我们可以用概率将新的申请人按其特征进行分类。
在数据中,这些问题的答案不是 “是 “或 “不是 “或 “十年”。答案被分组为更广泛的分类。
我们需要做的是删除真正的数字数据(时间、金额和年龄),保留分类因素。我们排除选定列。
然后我们创建一个简短的函数,将整数转换成因子。
for(i in S) credit\[, i\] <- as.factor(credit\[, i\])
现在我们有了有用的数据,我们可以开始应用不同的分析方法。
方法一:_逻辑回归_(Logistic Regression)
第一步是创建我们的训练数据集和测试数据集。训练集用于训练模型。测试集则用于评估模型的准确性。
我们把数据集分成任何我们喜欢的大小,在这里我们使用三分之一,三分之二的分割。
(1:nrow(credit))\[-sample(1:nrow(credit), size = 333)\]

在这个阶段,我们将使用glm()函数进行Logistic回归。在这里,我们有选择地使用模型中的变量。但现在只是用五个变量来确定信用度的值。
LogisticModel<- glm(Credit ~ Account + Payment + Purp + Length.of.current + Sex, family = binomial, data = credit)
完成后,我们继续将我们刚刚创建的模型拟合到测试集i_test1上,并准备进行第一次预测。
我们已经拟合了模型。现在我们将使用ROCR包来创建预测,并以曲线下面积(AUC)来衡量性能。AUC越大,说明我们的模型表现越好。
perf1 <- performance(pred1, 'tpr', 'fpr')
随时关注您喜欢的主题
让我们描绘一下结果。
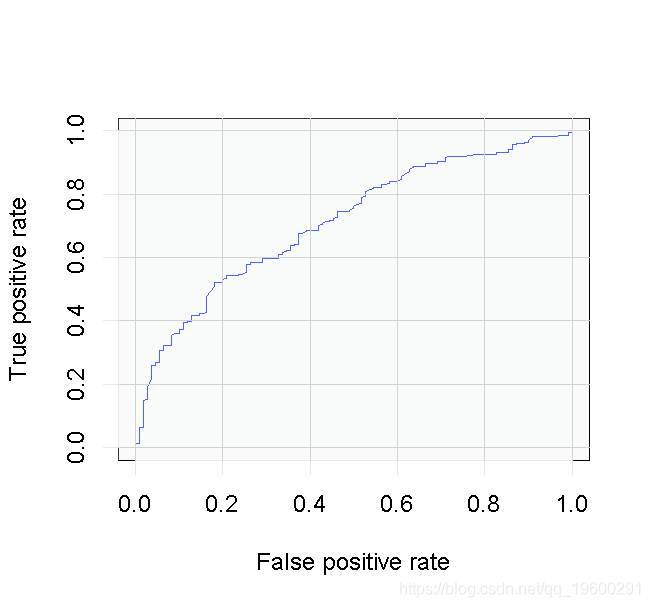
我们将通过寻找AUC来结束这一部分。
AUCLog1

这不是一个糟糕的结果,但让我们看看是否可以用不同的方法做得更好。
方法二:另一种Logistic模型
在这种方法中,我们将建立第二个Logistic逻辑模型来利用我们数据集中的所有变量。其步骤与上述第一个模型相同。
perf2 <- performance(pred2, 'tpr', 'fpr') plot(perf2)
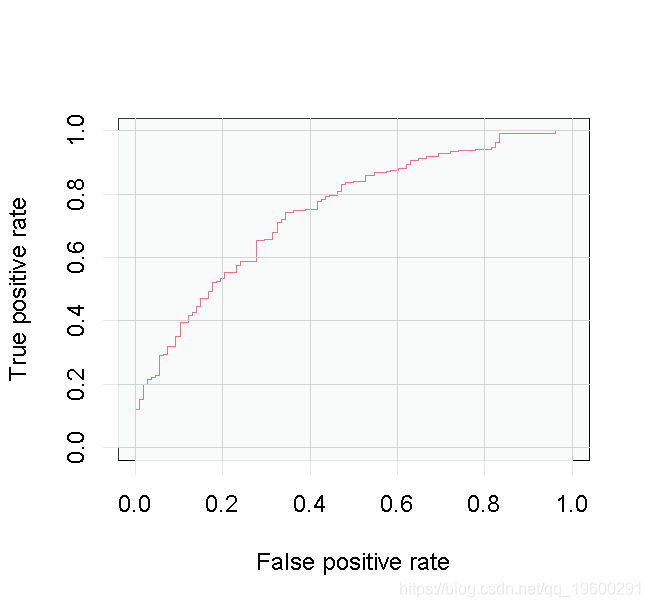
包括所有的变量,我们并没有得到多少改善。一个好的规则是尽可能保持模型的简单。
AUCLog2
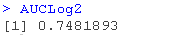
增加更多的变量会带来很少的改善,所以坚持使用更简单的模型。
方法三:回归树
接下来,让我们试着用回归树的方法来分析数据。我们的大部分代码与上述逻辑模型中使用的代码相似,但我们需要做一些调整。
请再次注意,我们正在研究我们模型中的所有变量,找到它们对我们感兴趣的变量–信用度的影响。
TreeModel <- rpart(Creditability ~ ., data = credit\[i_calibration1, \]) library(rpart.plot) prp(TreeModel, type = 2, extra = 1)
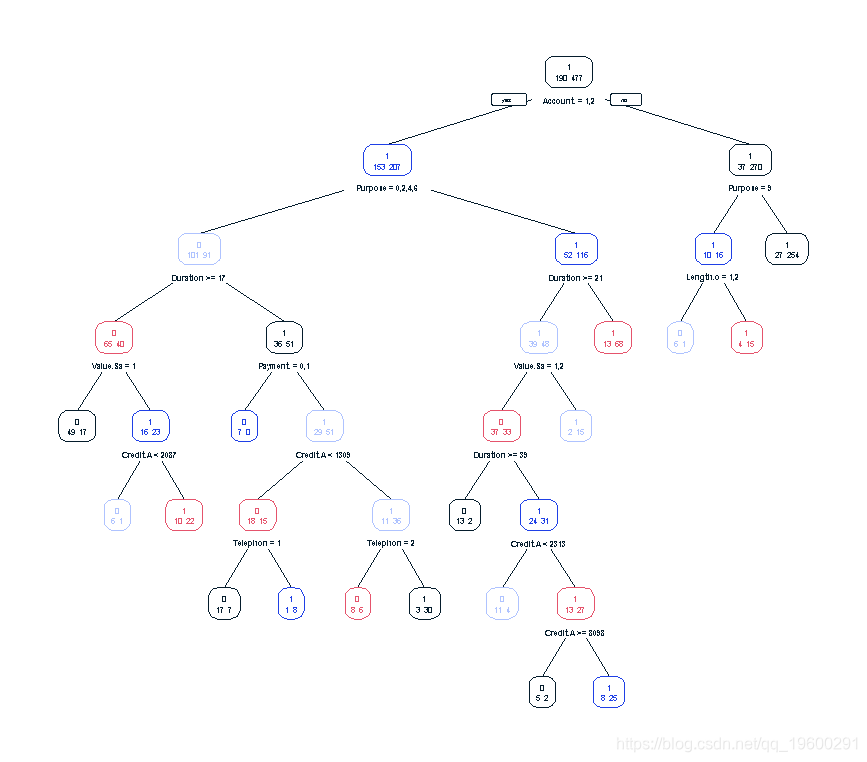
perf3 <- performance(pred3, 'tpr', 'fpr') plot(perf3)
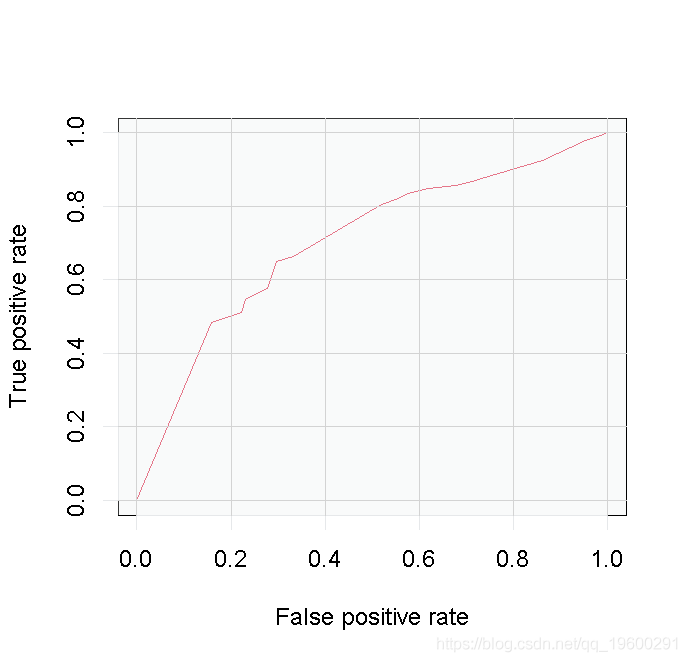

考虑到我们的树状模型的复杂性,这些结果并不令人满意,所以我们不得不再次怀疑第一个例子中更简单的Logistic Regression模型是否更好。
方法四:随机森林
与其建立一棵决策树,我们可以使用随机森林方法来创建一个决策树 “森林”。在这种方法中,最终结果是类的模式(如果我们正在研究分类模型)或预测的平均值(如果我们正在研究回归)。
随机森林背后的想法是,决策树很容易过度拟合,所以找到森林中的 “平均 “树可以帮助避免这个问题。
你可以想象,这比创建一棵决策树在计算上要求更高,但R可以很好地处理这一工作。
randomForest(Credit ~ )
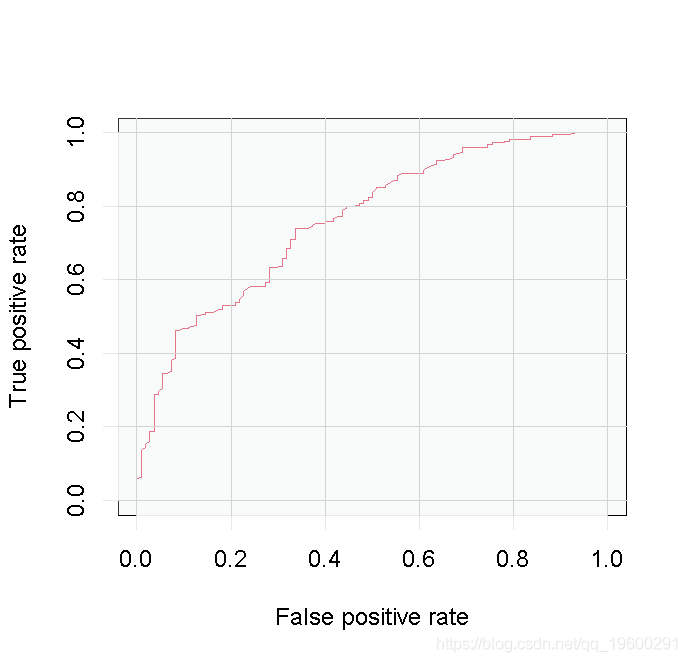
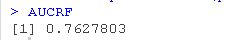
通过努力,我们得到了一个有点改进的结果。随机森林模型是我们所尝试的四个模型中表现最好的。但是,这需要判断结果是否值得付出额外的努力。
方法五:比较随机森林和Logistic模型
好了,我们已经看了使用两种基本分析方法的各种结果–逻辑回归和决策树。我们只看到了以AUC表示的单一结果。
随机森林方法要求我们创建一个决策树的森林,并取其模式或平均值。为什么不利用所有这些数据呢?它们会是什么样子呢?
下面的代码创建了一个图表,描述了我们的随机森林中每棵树的AUC分数和逻辑模型的数百种组合。
首先我们需要一个函数来进行分析。
function(i){
i_test2 <- sample(1:nrow(credit), size = 333)
summary(LogisticModel.3)
fitLog3 <- predict(LogisticModel.3, type = 'response', newdata = credit\[i_test2,
这部分代码的运行需要一段时间,因为我们要对数百个单独的结果进行列表和记录。你可以通过改变VAUC对象中的计数来调整模型中的结果数量。在这里,我们选择计算200个x-y对,或400个单独的结果。
plot(t(VC))
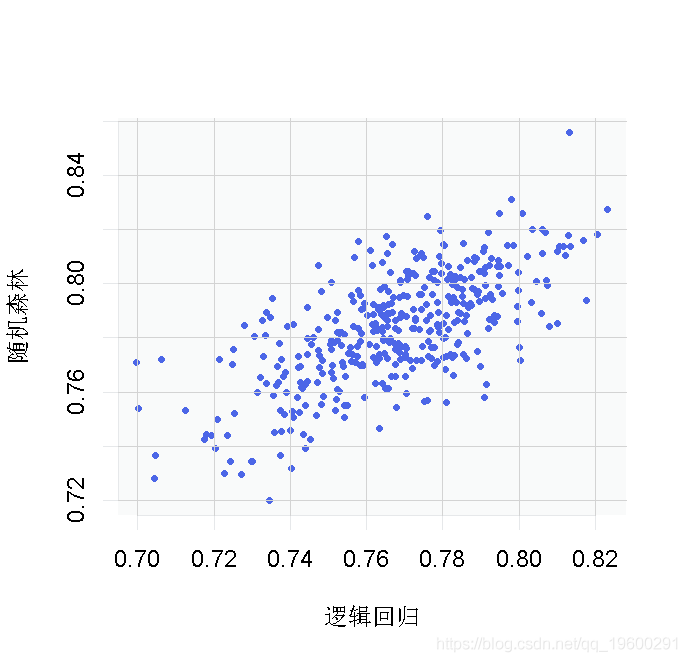
你可以看到,我们从前四个模型中得到的结果正好处于分布的中间。
这为我们证实了这些模型都是有可比性的。我们所希望的最好结果是AUC达到0.84,而且大多数人给我们的结果与我们已经计算的结果相似。
但是,让我们试着更好地可视化。
首先,我们将对象转换成一个数据框架。
我们创建几个新图。第一个是密度等高线图。
plot(AA, aes(x = V1, y = V2)
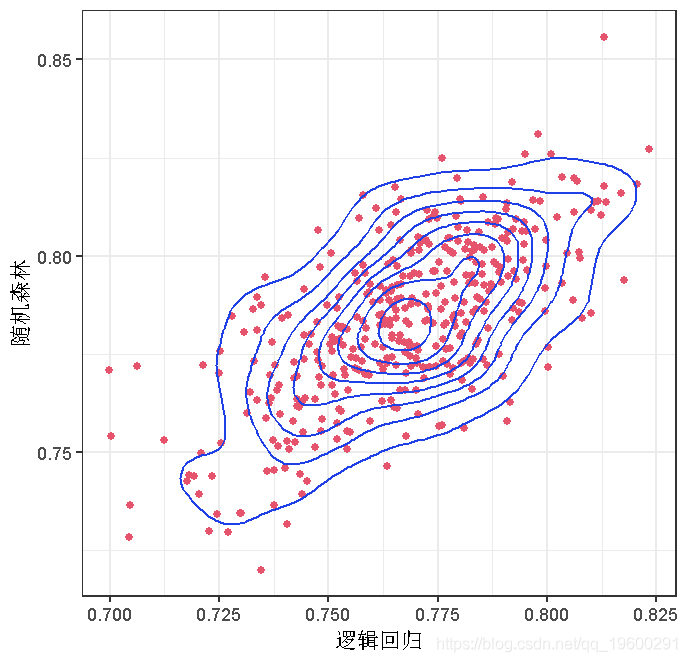
第二张是高密度等高线图,给我们提供了数据的概率区域。
with(AA, boxplot(V1, V2))
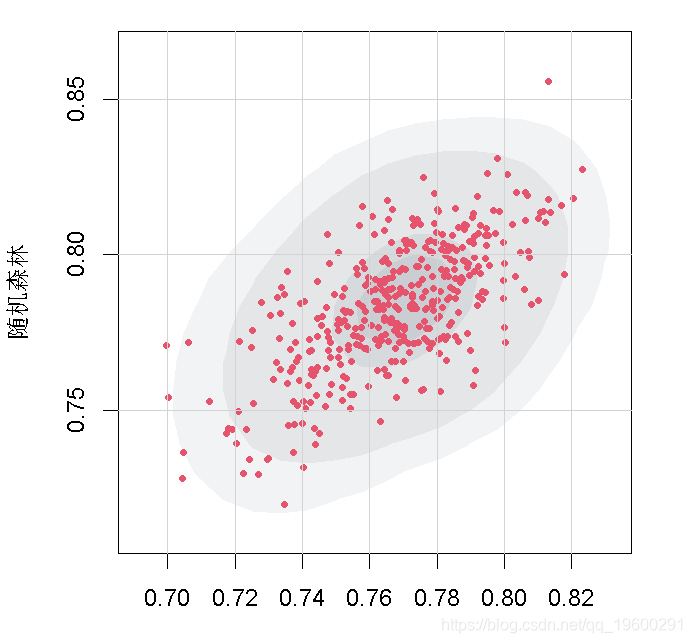
无论我们以何种方式描述我们的结果,都必须使用数据来做出合理的贷款决定。这里有一个问题?
这些可能是我们使用这些模型所能得出的最佳分数,但这些结果对于确定贷款申请人的信用价值是否可以接受?这取决于贷款机构所使用的信用标准。
在最好的情况下,看起来我们的模型给了82%的机会向良好的信用风险提供贷款。对于每100万元的贷款,我们最多可能期望得到82万元的偿还。平均而言,我们预计会收回大约78万元的本金。换句话说,根据我们的分析,有75%到80%的机会重新获得100万元的贷款,这取决于我们使用的建模方法。
当我们把贷款申请人加入我们的数据库时,如果我们要把他们视为良好的信贷风险,我们希望他们聚集在高密度图的最暗区域。
除非我们收取大量的利息来弥补我们的损失,否则我们可能需要更好的模型。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据

