本文是在 R 中使用 Keras 的LSTM神经网络分类简单介绍。
软件包
library(tidyverse) #导入、清理、可视化 library(keras) # 用keras进行深度学习 library(data.table) # 快速读取csv数据
导入
让我们看一下数据
tst %>% head()

初步查看
让我们考虑几个 用户可能提出的“不真诚”问题的例子
可下载资源
trn %>% filter(tart == 1) %>% sme_n(5)
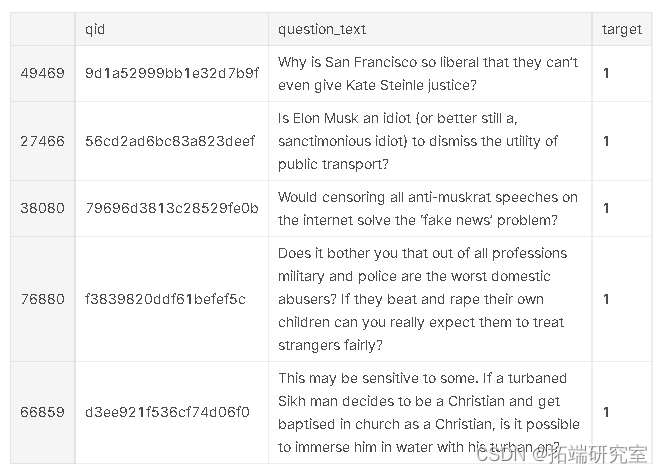
我可以理解为什么这些问题被认为是“不真诚的”:它们不是在寻求真正的答案,而是倾向于将提问者的信念陈述为事实,或者试图故意挑衅。想知道我们的模型会怎么样?
标记化
让我们从标记句子开始。
# 设置一些参数 mx_s <- 15000 # 考虑作为特征的最大词数 mxen <- 64 # 在n个词之后的文本截断 # 准备对文本进行标记 ful <- rbind(tin %>% select(qon\_t), test %>% select(quin\_ext)) tts <- full$qesio_tx toer <- text\_tokenizer(nu\_ors = m_wods) %>% >。 fi\_txt\_ner(txt # 符号化 - 即把文本转换成整数序列 seqnces <- tts_tseecs(toenze, txts) rd_idex <- toker$wordiex # 垫出文本,使所有内容都是相同的长度 daa = pad_sques(quecs, maxlen = aln)
数据拆分
# 分割回训练和测试 tri_mrx = data\[1:nrow(tan),\] # 分割回训练和测试。 ttmix = da\[(nrow(ran)+1):nrow(at),\] # 准备训练标签。 # 准备好训练标签 laes = trin$trgt # 准备一个验证集 set.seed(1337) traingsales = nrow(trinix)*0.90 inie = sample(1:nrow(tra_trix)) trining\_idies = indices\[1:training\_samples\] 。 valdaton\_inces = indices\[(ranng\_sples + 1): (trningmes + vliiopls)\] 。 xtrin = tainmax\[trinig_dces,\] 。 y_an = labels\[ainginies\] x\_vl = traimarix\[valito\_inces,\] y_val = labels\[traginces\]。 y_al = labels\[vlitnidies\]。 # 训练维度 dim(x_ran) table(y_tan)


这里非常严重的不平衡,我们需要稍后解决这个问题。
嵌入
我们的第一个模型将基于一个提供的词嵌入。我们从较小的嵌入文件开始。
随时关注您喜欢的主题
lis <- readLines('1M.vec')
fsti_emedisndx = nw.ev(hash = TRUE, parent = eptev())
ies <- lns\[2:legt(lie)\]
b <- tPrgssBr(min = 0, max = lenth(lns), style = 3)
for (i in 1:length(les)){
vaus <- strsplit(le, " ")\[\[1\]\]
wd<- vaus\[\[1\]\]
fsiemgndx\[\[word\]\] = as.double(vaes\[-1\])
etxPressar(pb, i)
}
# 创建我们的嵌入矩阵
faikimbddngim = 300
fawkiebiix = array(0, c(mx\_ords, faii\_mdig_m))
for (wrd in names(wrddex)){
idx <- wr_dx\[\[od\]\]
if (nex < ma_ds){
faiki\_embdg\_vctor =astwkedgdex\[\[word\]\]
if (!is.null(fasiembddigveor))
fatwki\_bednrix\[iex+1,\] <- faswiiedin\_vor # 没有嵌入的词都是零
}
模型架构
我们从一个简单的 LSTM 开始,顶层有一个用于预测的密集层。
# 设置输入 inpt <- layput( shape = list(NULL), # 模型层 embding <- input %>% layeing(input\_dim = maords, output\_dim = fasing_dim, name = "embedding") lstm <- eming %>% layer_lstm(units = maxn,drout = 0.25, recudroput = 0.25, reseques = FALSE, name = "lstm") dese <- lstm %>% ladese(units = 128, actin = "rlu", name = "dese") # 把模型集中起来 mol <- kmoel(input, preds) # 最初冻结嵌入权重,以防止更新的权重回传,破坏我们的嵌入。 getlar(ml, name = "embedding") %>% sehts(list(fasatrix)) %>% frehts() # 编译 print(model)
模型训练
保持对初始基准模型的快速训练。
看看训练结果
# 训练模型 history <- model %>% fit( x_train, y_train, print(hisy)

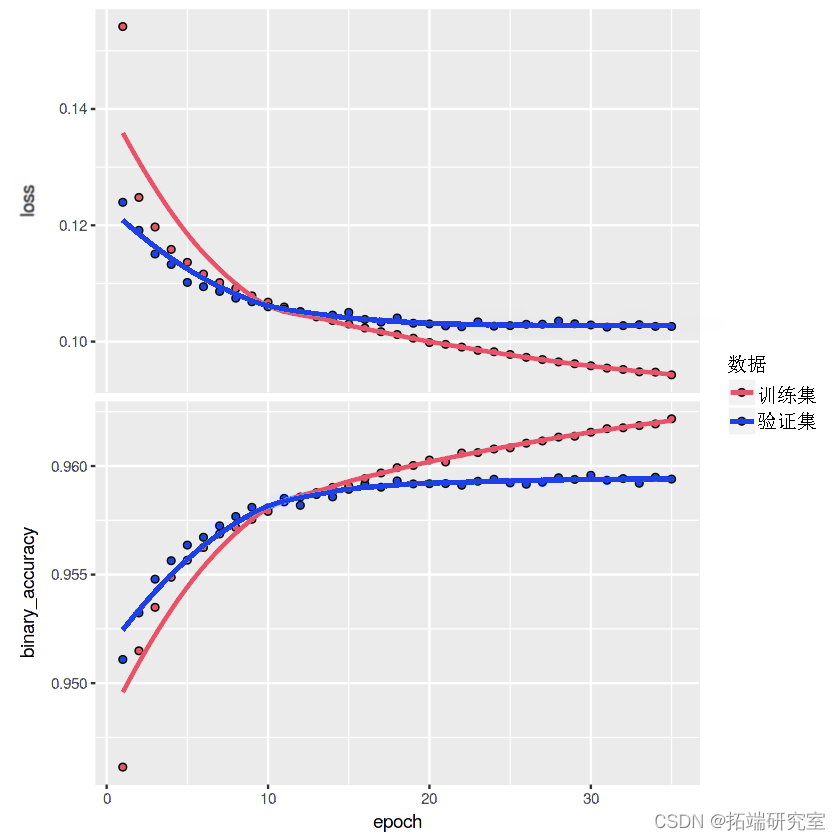
模型可以很容易地通过微调来改进:只需嵌入层并再训练模型几个 epoch,注意不要过度拟合。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 时序预测、深度强化学习与蒙特卡洛模拟融合:LSTM、GRU、Attention、DQN及多策略智能体的股票交易决策体系构建——以Google股价为例 | 附代码数据
时序预测、深度强化学习与蒙特卡洛模拟融合:LSTM、GRU、Attention、DQN及多策略智能体的股票交易决策体系构建——以Google股价为例 | 附代码数据 LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
