
在这篇文章中,我将从一个基本的线性模型开始,然后从那里尝试找到一个更合适的线性模型。
由于空气质量数据集包含一些缺失值,因此我们将在开始拟合模型之前将其删除,并选择70%的样本进行训练并将其余样本用于测试:
可下载资源
数据预处理
由于空气质量数据集包含一些缺失值,因此我们将在开始拟合模型之前将其删除,并选择70%的样本进行训练并将其余样本用于测试:
data(airquality)
ozone <- subset(na.omit(airquality),
select = c("Ozone", "Solar.R", "Wind", "Temp"))
set.seed(123)
N.train <- ceiling(0.7 * nrow(ozone))
N.test <- nrow(ozone) - N.train
trainset <- sample(seq_len(nrow(ozone)), N.train)
testset <- setdiff(seq_len(nrow(ozone)), trainset)
普通最小二乘模型
作为基准模型,我们将使用普通的最小二乘(OLS)模型。在定义模型之前,我们定义一个用于绘制线性模型的函数:
rsquared <- function(test.preds, test.labels) {
return(round(cor(test.preds, test.labels)^2, 3))
}
plot.linear.model <- function(model, test.preds = NULL, test.labels = NULL,
test.only = FALSE) {
r.squared <- NULL
if (!is.null(test.preds) && !is.null(test.labels)) {
# store predicted points:
test.df <- data.frame("Prediction" = test.preds,
"Outcome" = test.labels, "DataSet" = "test")
# store residuals for predictions on the test data
test.residuals <- test.labels - test.preds
test.res.df <- data.frame("x" = test.labels, "y" = test.preds,
"x1" = test.labels, "y2" = test.preds + test.residuals,
"DataSet" = "test")
# append to existing data
plot.df <- rbind(plot.df, test.df)
plot.res.df <- rbind(plot.res.df, test.res.df)
# annotate model with R^2 value
r.squared <- rsquared(test.preds, test.labels)
}
#######
library(ggplot2)
p <- ggplot()
return(p)
}现在,我们使用lm并研究特征估计的置信区间来建立OLS模型:
confint(model)
## 2.5 % 97.5 %
## (Intercept) -1.106457e+02 -20.88636548
## Solar.R 7.153968e-03 0.09902534
## Temp 1.054497e+00 2.07190804
## Wind -3.992315e+00 -1.24576713我们看到模型似乎对截距的设置不太确定。让我们看看模型是否仍然表现良好:
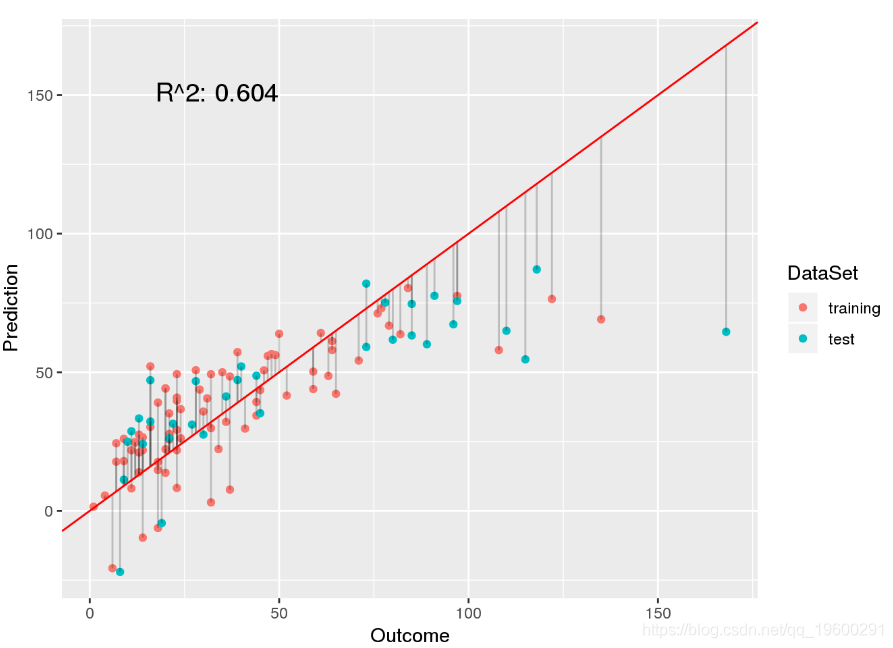

查看模型的拟合度,有两个主要观察结果:
- 高臭氧水平被低估
- 预计臭氧含量为负
下面让我们更详细地研究这两个问题。
高臭氧水平被低估
从图中可以看出,当臭氧在[0,100]范围内时,线性模型非常适合结果。但是,当实际观察到的臭氧浓度高于100时,该模型会大大低估该值。
我们应该问一个问题,这些高臭氧含量是否不是测量误差的结果。考虑到典型的臭氧水平,测量值似乎是合理的。最高臭氧浓度为168 ppb(十亿分之一),美国城市的典型峰值浓度为150至510 ppb。这意味着我们确实应该关注离群值。低估高臭氧含量将特别有害,因为高含量的臭氧会危害健康。让我们调查数据以确定模型为何存在这些异常值的问题。
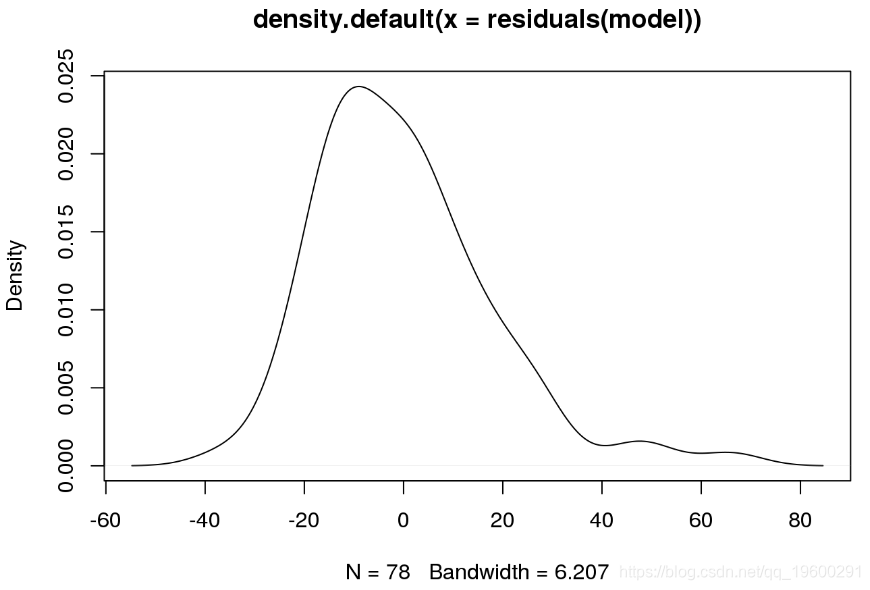

直方图表明残差分布右尾的值确实存在问题。由于残差不是真正的正态分布,因此线性模型不是最佳模型。实际上,残差似乎遵循某种形式的泊松分布。为了找出最小二乘模型的拟合对离群值如此之差的原因,我们再来看一下数据。
## Ozone Solar.R Wind Temp
## Min. :110.0 Min. :207.0 Min. :2.300 Min. :79.00
## 1st Qu.:115.8 1st Qu.:223.5 1st Qu.:3.550 1st Qu.:81.75
## Median :120.0 Median :231.5 Median :4.050 Median :86.50
## Mean :128.0 Mean :236.2 Mean :4.583 Mean :86.17
## 3rd Qu.:131.8 3rd Qu.:250.8 3rd Qu.:5.300 3rd Qu.:89.75
## Max. :168.0 Max. :269.0 Max. :8.000 Max. :94.00summary(ozone)

## Ozone Solar.R Wind Temp
## Min. : 1.0 Min. : 7.0 Min. : 2.30 Min. :57.00
## 1st Qu.: 18.0 1st Qu.:113.5 1st Qu.: 7.40 1st Qu.:71.00
## Median : 31.0 Median :207.0 Median : 9.70 Median :79.00
## Mean : 42.1 Mean :184.8 Mean : 9.94 Mean :77.79
## 3rd Qu.: 62.0 3rd Qu.:255.5 3rd Qu.:11.50 3rd Qu.:84.50
## Max. :168.0 Max. :334.0 Max. :20.70 Max. :97.00从两组观测值的分布来看,我们看不到高臭氧观测值与其他样本之间的巨大差异。但是,我们可以使用上面的模型预测图找到罪魁祸首。在该图中,我们看到大多数数据点都以[0,50]臭氧范围为中心。为了很好地拟合这些观察值,截距的负值为-65.77,这就是为什么该模型低估了较大臭氧值的臭氧水平的原因,在训练数据中臭氧值不足。
该模型预测负臭氧水平
如果观察到的臭氧浓度接近于0,则该模型通常会预测负臭氧水平。当然,这不可能是因为浓度不能低于0。再次,我们调查数据以找出为什么模型仍然做出这些预测。
为此,我们将选择臭氧水平在第5个百分位数的所有观测值,并调查其特征值:
# compare observations with low ozone with whole data set
summary(ozone[idx,])
## Ozone Solar.R Wind Temp
## Min. :1.0 Min. : 8.00 Min. : 9.70 Min. :57.0
## 1st Qu.:4.5 1st Qu.:20.50 1st Qu.: 9.85 1st Qu.:59.5
## Median :6.5 Median :36.50 Median :12.30 Median :61.0
## Mean :5.5 Mean :37.83 Mean :13.75 Mean :64.5
## 3rd Qu.:7.0 3rd Qu.:48.75 3rd Qu.:17.38 3rd Qu.:67.0
## Max. :8.0 Max. :78.00 Max. :20.10 Max. :80.0summary(ozone)

## Ozone Solar.R Wind Temp
## Min. : 1.0 Min. : 7.0 Min. : 2.30 Min. :57.00
## 1st Qu.: 18.0 1st Qu.:113.5 1st Qu.: 7.40 1st Qu.:71.00
## Median : 31.0 Median :207.0 Median : 9.70 Median :79.00
## Mean : 42.1 Mean :184.8 Mean : 9.94 Mean :77.79
## 3rd Qu.: 62.0 3rd Qu.:255.5 3rd Qu.:11.50 3rd Qu.:84.50
## Max. :168.0 Max. :334.0 Max. :20.70 Max. :97.00我们发现,在低臭氧水平下,平均太阳辐射要低得多,而平均风速要高得多。要了解为什么我们会有负面的预测,现在让我们看一下模型系数:
coefficients(model)

## (Intercept) Solar.R Temp Wind
## -65.76603538 0.05308965 1.56320267 -2.61904128因此,对于较低的臭氧水平,的正系数Solar.R不能弥补截距,Wind因为对于较低的臭氧水平,的值Solar.R较低,而的值Wind较高。
处理负面的臭氧水平预测
让我们首先处理预测负臭氧水平的问题。
截短的最小二乘模型
处理负面预测的一种简单方法是将其替换为尽可能小的值。这样,如果我们将模型交给客户,他就不会开始怀疑模型有问题。我们可以使用以下功能来做到这一点:
现在让我们验证这将如何改善我们对测试数据的预测。请记住,[R2[R2 最初的模型是 0.6040.604。
nonnegative.preds <- predict.nonnegative(model, ozone[testset,])
# plot only the test predictions to verify the results
plot.linear.model(model, nonnegative.preds, ozone$Ozone[testset], test.only = TRUE)
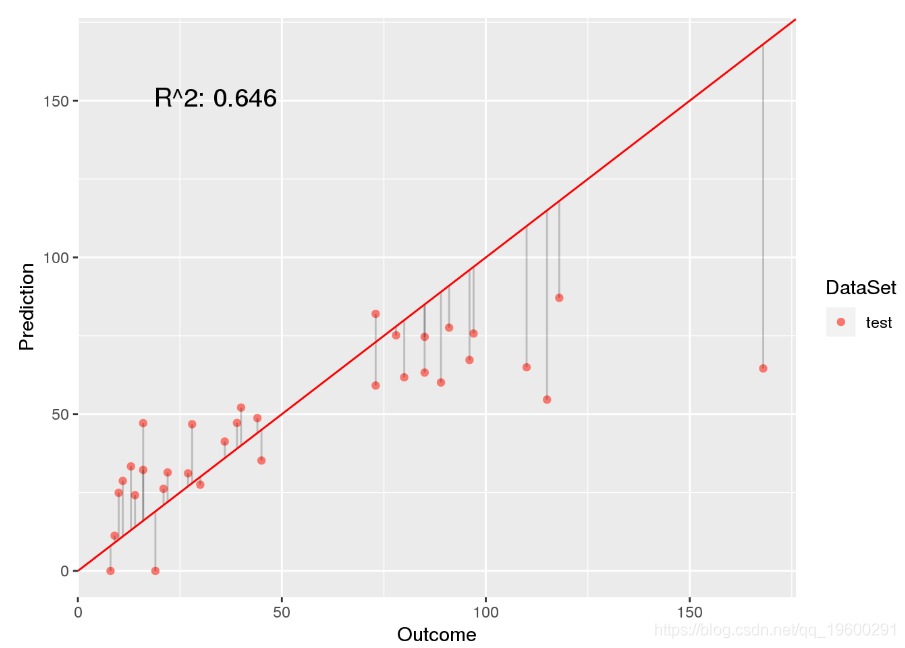

如我们所见,此hack可以抑制问题并增加 [R2[R2 至 0.6460.646。但是,以这种方式校正负值不会改变我们的模型错误的事实,因为拟合过程并未考虑到负值应该是不可能的。
泊松回归
为了防止出现负估计,我们可以使用假定为泊松分布而非正态分布的广义线性模型(GLM):
plot.linear.model(pois.model, pois.preds, ozone$Ozone[testset])


的 [R2[R2值0.616表示泊松回归比普通最小二乘(0.604)稍好。但是,其性能并不优于将负值为0(0.646)的模型。这可能是因为臭氧水平的方差比泊松模型假设的要大得多:
# mean and variance should be the same for Poisson distribution
mean(ozone$Ozone)
## [1] 42.0991var(ozone$Ozone)

## [1] 1107.29对数转换
处理负面预测的另一种方法是取结果的对数:
print(rsquared(log.preds, test.labels))
## [1] 0.616请注意,尽管结果与通过Poisson回归得出的结果相同,但这两种方法通常并不相同。
应对高估臭氧水平的低估
理想情况下,我们将在臭氧水平较高的情况下更好地进行测量。但是,由于我们无法收集更多数据,因此我们需要利用已有的资源。应对低估高臭氧水平的一种方法是调整损失函数。
加权回归
使用加权回归,我们可以影响离群值残差的影响。为此,我们将计算臭氧水平的z得分,然后将其指数用作模型的权重,从而增加异常值的影响。
plot.linear.model(weight.model, weight.preds, ozone$Ozone[testset])
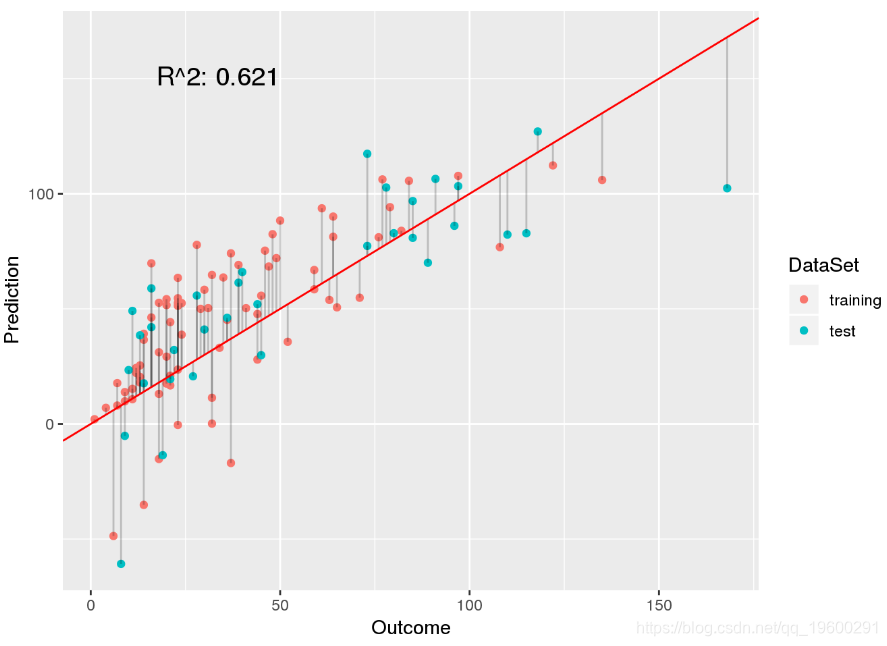

该模型绝对比普通的最小二乘模型更合适,因为它可以更好地处理离群值。
采样
让我们从训练数据中进行采样,以确保不再出现臭氧含量过高的情况。这类似于进行加权回归。但是,我们没有为低臭氧水平的观测值设置较小的权重,而是将其权重设置为0。
print(paste0("N (trainset before): ", length(trainset)))
## [1] "N (trainset before): 78"
print(paste0("N (trainset after): ", length(trainset.sampled)))
## [1] "N (trainset after): 48"现在,让我们基于采样数据构建一个新模型:
rsquared(sampled.preds, test.labels)
## [1] 0.612如我们所见,基于采样数据的模型的性能并不比使用权重的模型更好。
结合
看到泊松回归可用于防止负估计,加权是改善离群值预测的成功策略,我们应该尝试将两种方法结合起来,从而得出加权泊松回归。
加权泊松回归
p.w.pois
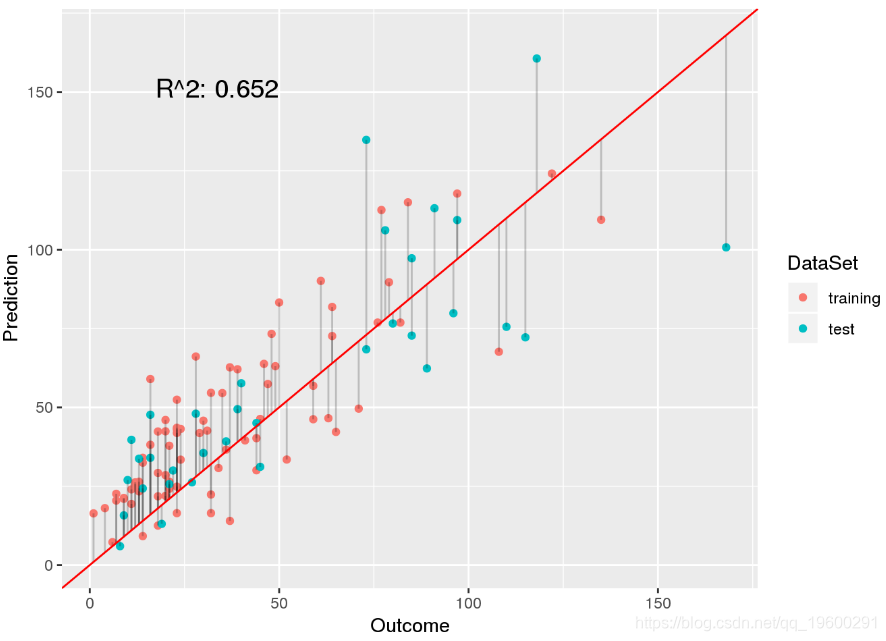

如我们所见,该模型结合了使用泊松回归(非负预测)和使用权重(低估离群值)的优势。确实,[R2[R2该模型的最低价(截断线性模型为0.652 vs 0.646)。让我们研究模型系数:
coefficients(w.pois.model)

## (Intercept) Solar.R Temp Wind
## 2.069357230 0.002226422 0.029252172 -0.104778731该模型仍然由截距控制,但现在是正数。因此,如果所有其他特征的值为0,则模型的预测仍将为正。
但是,假设均值应等于泊松回归的方差呢?
print(paste0(c("Var: ", "Mean: "), c(round(var(ozone$Ozone), 2),
round(mean(ozone$Ozone), 2))))## [1] "Var: 1107.29" "Mean: 42.1"该模型的假设绝对不满足,并且由于方差大于该模型假设,因此我们遭受了过度分散的困扰。
加权负二项式模型
因此,我们应该尝试选择一个更适合过度分散的模型,例如负二项式模型:
plot.linear.model(model.nb, preds.nb, test.labels)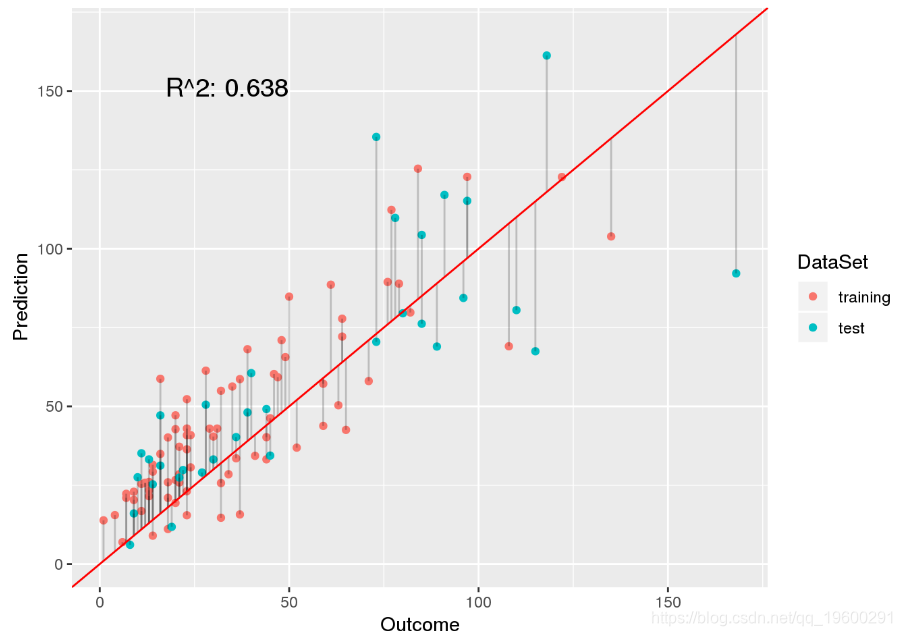

因此,就测试集的性能而言,加权负二项式模型并不比加权泊松模型更好。但是,在进行推断时,该值应该更好,因为其假设没有被破坏。查看这两个模型,很明显它们的p值相差很大:
coef(summary(w.pois.model))
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.069357230 0.2536660583 8.157801 3.411790e-16
## Solar.R 0.002226422 0.0003373846 6.599061 4.137701e-11
## Temp 0.029252172 0.0027619436 10.591155 3.275269e-26
## Wind -0.104778731 0.0064637151 -16.210295 4.265135e-59coef(summary(model.nb))

## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.241627650 0.640878750 1.937383 5.269853e-02
## Solar.R 0.002202194 0.000778691 2.828071 4.682941e-03
## Temp 0.037756464 0.007139521 5.288375 1.234078e-07
## Wind -0.088389583 0.016333237 -5.411639 6.245051e-08虽然泊松模型声称所有系数都非常显着,但负二项式模型表明截距并不显着。 负二项式的置信带可以通过以下方式找到:
CI.int <- 0.95
# calculate CIs:
df <- data.frame(ozone[testset,], "PredictedOzone" = ilink(preds.nb.ci$fit), "Lower" = ilink(preds.nb.ci$fit - ci.factor * preds.nb.ci$se.fit),
"Upper" = ilink(preds.nb.ci$fit + ci.factor * preds.nb.ci$se.fit))使用包含测试集中的特征值以及带有其置信带的预测的构造数据框,我们可以绘制估计值如何根据独立变量而波动:
# plot estimates vs individual features in the test set
plots <- list()
grid.arrange(plots[[1]], plots[[2]], plots[[3]])
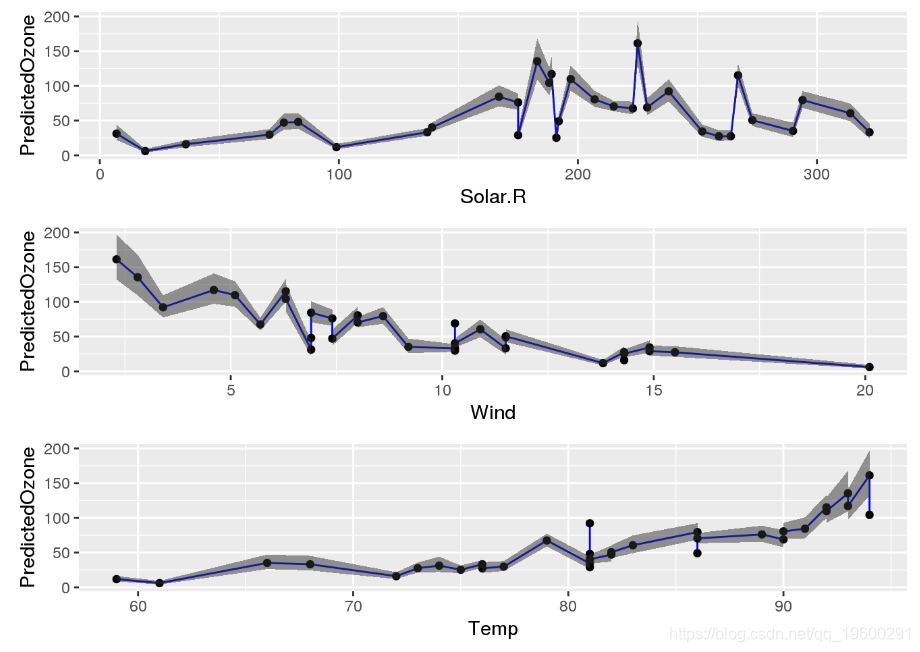
这些图说明了两件事:
- 有清晰的线性关系
Wind和Temperature。估计的臭氧水平Wind随增加而下降,而估计的臭氧水平随增加而Temp增加。 - 该模型对低臭氧水平最有信心,但对高臭氧水平不太有信心
数据集扩充
优化模型后,我们现在返回初始数据集。还记得我们在分析开始时就删除了所有缺失值的观察结果吗?好吧,这是不理想的,因为我们已经舍弃了有价值的信息,这些信息可以用来获得更好的模型。
调查缺失值
让我们首先调查缺失的值:
# ratio of missing values
ratio.missing <- length(na.idx) / nrow(ozone)
print(paste0(round(ratio.missing * 100, 3), "%"))## [1] "27.451%"# which features are missing most often?
nbr.missing <- apply(ozone, 2, function(x) length(which(is.na(x))))
print(nbr.missing)
## Ozone Solar.R Wind Temp
## 37 7 0 0# multiple features missing in one observation?
nbr.missing <- apply(ozone, 1, function(x) length(which(is.na(x))))
table(nbr.missing)## nbr.missing
## 0 1 2
## 111 40 2调查显示,由于缺少值,以前排除了相当多的观察值。更具体地说,唯一缺少的功能是Ozone(37次)和Solar.R(7次)。通常,只有一项功能缺失(40次),很少有两项功能缺失(2次)。
调整训练和测试指标
为了确保与以前使用相同的观测值进行测试,我们必须 映射到完整的空气质量数据集:
trainset <- c(trainset, na.idx)
testset <- setdiff(seq_len(nrow(ozone)), trainset)估算缺失值
为了获得缺失值的估计值,我们可以使用插补。这种方法的想法是使用已知特征来形成预测模型,以便估计缺失的特征。
summary(as.numeric(imputed.data$Ozone))
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 16.00 30.00 41.66 59.00 168.00请注意,aregImpute使用不同的引导程序样本进行多个插补,可以使用n.impute参数指定。由于我们要使用所有运行的推算而不是单个运行,因此我们将使用fit.mult.impute函数定义模型:
# compute new weights
plot.linear.model(fmi, fmi.preds, ozone$Ozone[testset])
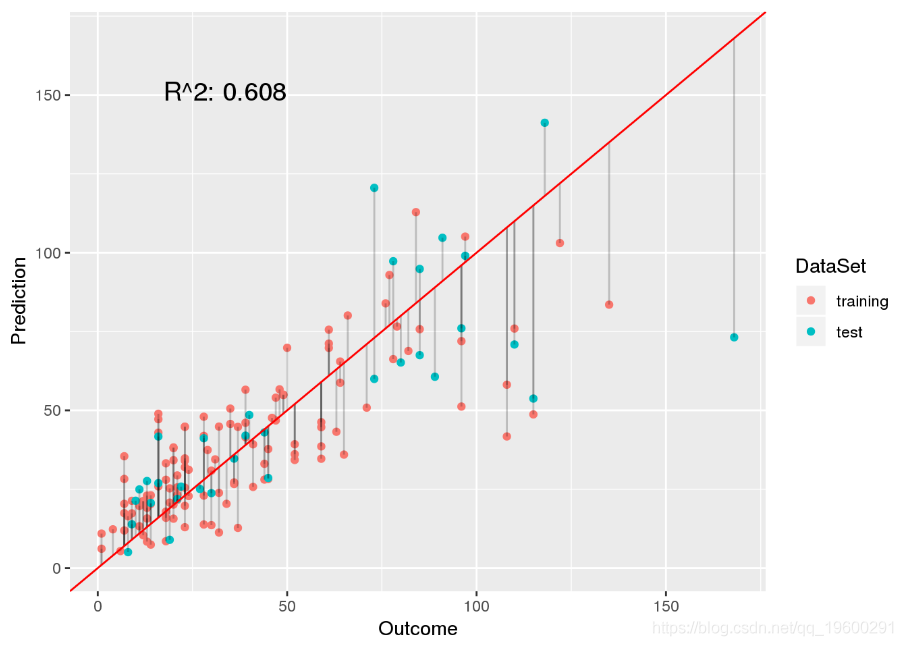

让我们仅使用一个插补以便再次指定权重:
rsquared(w.pois.preds.imputed, imputed.data$Ozone[testset])
## [1] 0.431在这种情况下,基于估算数据的加权泊松模型的性能不会比仅排除丢失数据的模型更好。这表明对缺失值的估算比将噪声引入数据中要多得多,而不是我们可以使用的信号。可能的解释是,具有缺失值的样本具有不同于所有测量可用值的分布。
摘要
我们从OLS回归模型开始([R2= 0.604[R2=0.604),并试图找到一个更合适的线性模型。第一个想法是将模型的预测截断为0([R2= 0.646[R2=0.646)。为了更准确地预测离群值,我们训练了加权线性回归模型([R2= 0.621[R2=0.621)。接下来,为了仅预测正值,我们训练了加权Poisson回归模型([R2= 0.652[R2=0.652)。为了解决泊松模型中的过度分散问题,我们制定了加权负二项式模型。尽管此模型的表现不如加权Poisson模型([R2= 0.638 ),则在进行推理时可能会更好。
此后,我们尝试通过使用Hmisc包估算缺失值来进一步改进模型。尽管生成的模型比初始OLS模型要好,但是它们没有获得比以前更高的性能([R2= 0.627[R2=0.627)。
那么,最好的模型到底是什么?就模型假设的正确性而言,这是加权负二项式模型。就决定系数而言,[R2[R2,这是加权Poisson回归模型。因此,出于预测臭氧水平的目的,我将选择加权Poisson回归模型。
您可能会问:所有这些工作值得吗?实际上,初始模型和加权泊松模型的预测在5%的水平上存在显着差异:
##
## Wilcoxon signed rank test
##
## data: test.preds and w.pois.preds
## V = 57, p-value = 1.605e-05
## alternative hypothesis: true location shift is not equal to 0当我们 比较它们时,模型之间的差异变得显而易见:
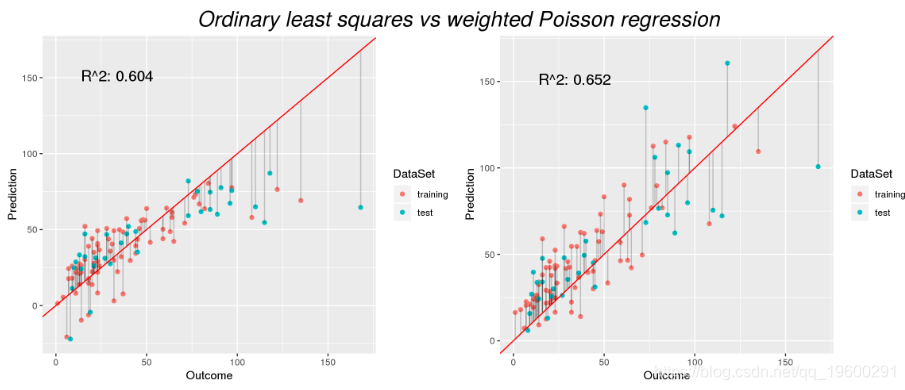
总之,我们从预测负值和低估高臭氧水平的模型(左侧显示OLS模型)到没有此类明显缺陷的模型(右侧加权Poisson模型)。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



