在这个项目中,我讨论了如何使用主成分分析 (PCA) 进行简单的预测。
出于说明目的,我们将对一个数据集进行分析,该数据集包含有关在 3 个不同价格组内进行的汽车购买信息以及影响其购买决定的一组特征。
首先,我们将导入数据集并探索其结构。
(1)标准化(Scale)
如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大。如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见。但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同。如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音。在这样的情形下,我们就不必做定标。
(2)特征值 (eigen value)
特征值与特征向量均为矩阵分解的结果。特征值表示标量部分,一般为某个主成分的方差,其相对比例可理解为方差解释度或贡献度 ;特征值从第一主成分会逐渐减小。
(3)特征向量(eigen vector)
特征向量为对应主成分的线性转换向量(线性回归系数),特征向量与原始矩阵的矩阵积为主成分得分。特征向量是单位向量,其平方和为1。特征向量主要起转换作用,其数值不能说明什么问题,解释力更强的是载荷loadings,但很多R输出中经常混用,egien vector与loadings。
head(caref)


众所周知,PCA 使用欧几里得距离来推导分量,因此输入变量需要是数字的。正如我们所看到的,除了“组”变量之外,所有数据都是数字格式,因此我们不必执行任何转换。
为了查看数字变量在 3 个价格组中的表现,我分别为每个数字变量生成箱线图。
ggplot(cr_e.m, aes(x = varle, y = vle, fill = Gup)) + geom_boxplot()
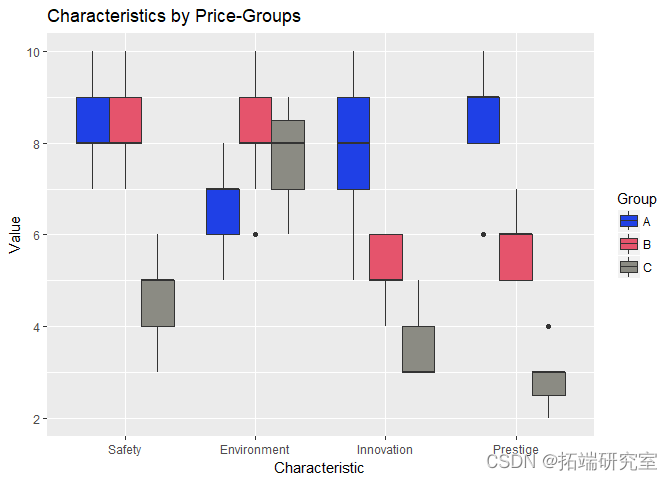
通过观察上图,我们可以了解到每个价格组的消费者对所考虑的特征有不同的看法(即,给出不同的评分)。(“安全”特征的变化较小,在所有 3 个价格组中具有更高的排名/重要性)
现在为了更好地可视化这 3 个价格组集群如何在 3D 空间中出现,我使用 3 个特征变量构建了一个 3D 图,显示给定评级之间的显着差异。
same3dpot <- with(carpef, scttro3d(Enirnmnt,Innoaon,Prtge
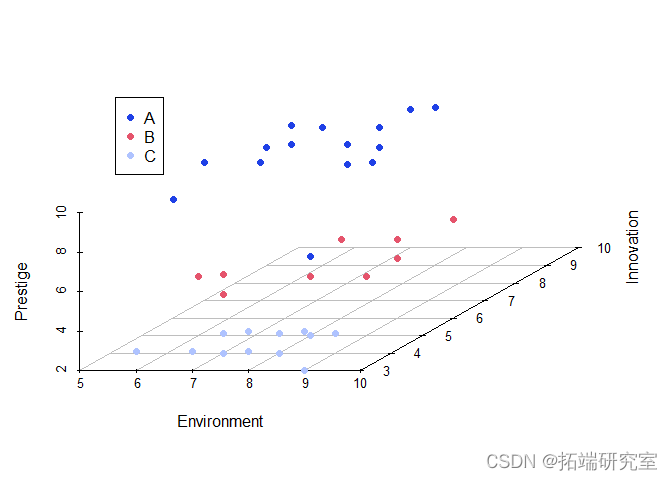
在上图中,我们可以看到来自每个价格组的数据点(集群)之间的明显差异。
在继续应用 PCA 之前,现在我将检查输入变量之间是否存在任何相关性。
corrplot(oras)
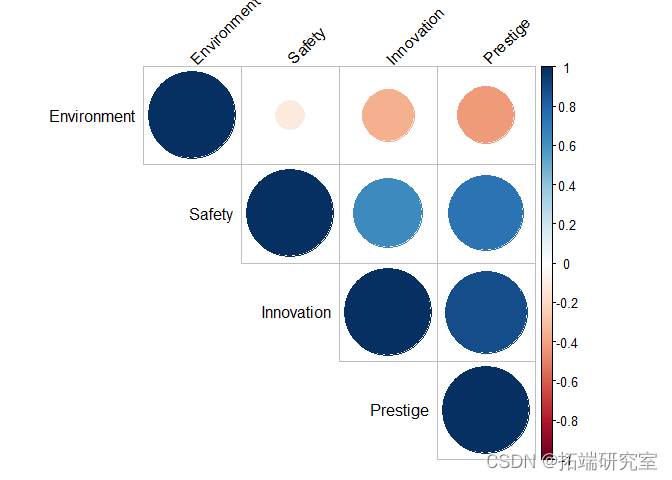
可以看出,“创新”、“安全”和“声望”特征之间似乎有明显的相关性。
通常在构建模型时,我们会删除一些(不必要的)相关预测变量而不包括模型,但鉴于我们正在执行 PCA,我们不会这样做,因为应用 PCA 的想法是生成新的主成分(它们不会相互关联)并用降低的维度替换当前的预测变量集。
pcmol <- prcomp(ca_eeued, scale. = TRUE, center = TRUE)
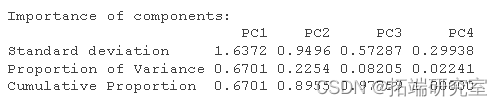
通过观察 PCA 的输出,我们可以看到前两个 PC 解释了数据中 89% 的可变性。
随时关注您喜欢的主题
通过包括 3 个 PC,该模型将解释 97% 的可变性,但由于 2 个 PC 可以解释大约 90% 的数据,因此我将只使用 2 个 PC。
此外,通过观察下面的碎石图和每个PC的重要性,我们也可以理解,只用两个PC是可以的。
sumacamel = summary(adel) plot(pc_el,type = "l")
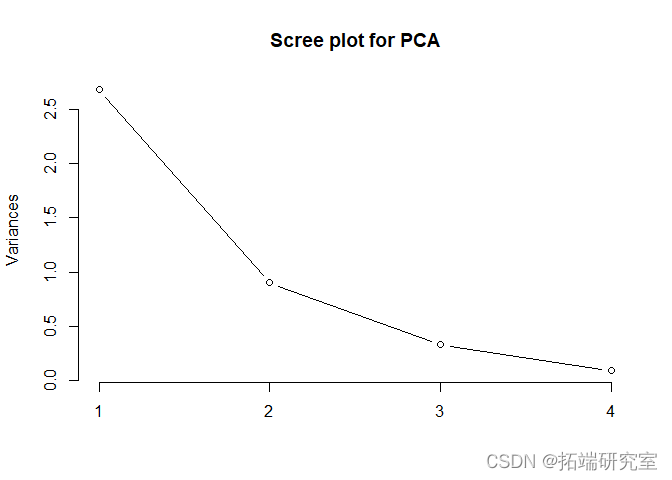
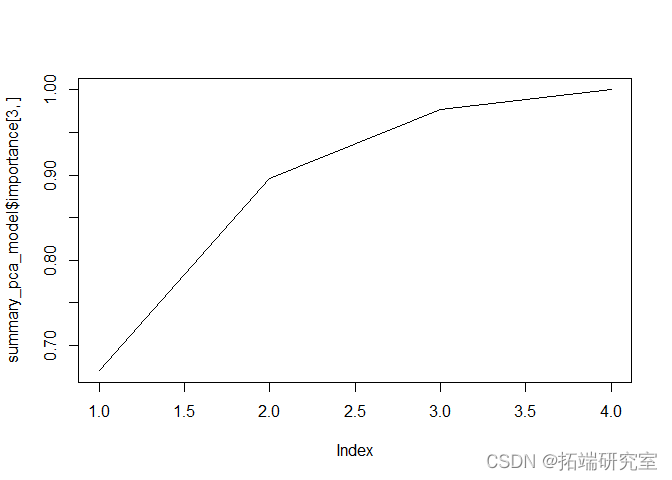
由于我们只坚持前两个主成分,现在我检查每个预测变量对每个主成分的影响量。
下面我根据它们对每个PC 的影响按降序排列了这些特性。
#对于PC 1 longScrsPC_1 <- pcael$roto\[,1\] faccore\_PC\_1 <- abs(odingcre\_PC\_1) fa\_scre\_PC\_1raked <- nmes(rt(fac\_cos1,decreasing = T))
pamod$roatn\[fa\_coC\_\_and,1\]


现在我们最终在这两个 PC 上绘制原始数据,并检查我们是否可以分别识别每个价格组的数据点。
#PC_n2 <- qplot(x=PC1, y=PC2
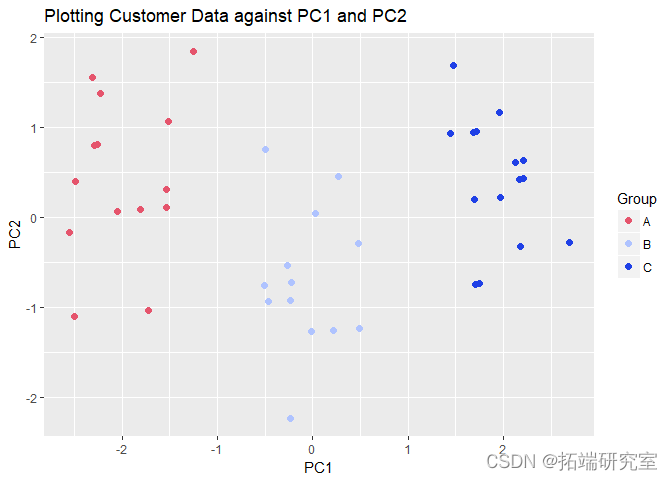
我们可以看到数据点是根据它们所在的每个价格进行聚类的!
使用上述特征,现在我们将尝试根据他/她对所考虑的特征给出的评级来预测一个人会购买哪种类型的汽车!
让我们假设一个客户对每个特征给出了以下评级:
安全:9 环境:8 创新:5 声望:4
现在让我们尝试预测该客户将属于哪个价格组:
new_ser <- c(9,8,5,4) new\_cus\_group <- predict(pcmdl, newdata = car\_pef\_ecew_c\[nrow(),\] lt\_3 <- pot\_2 + ge\_point(aes(x=newcus\_
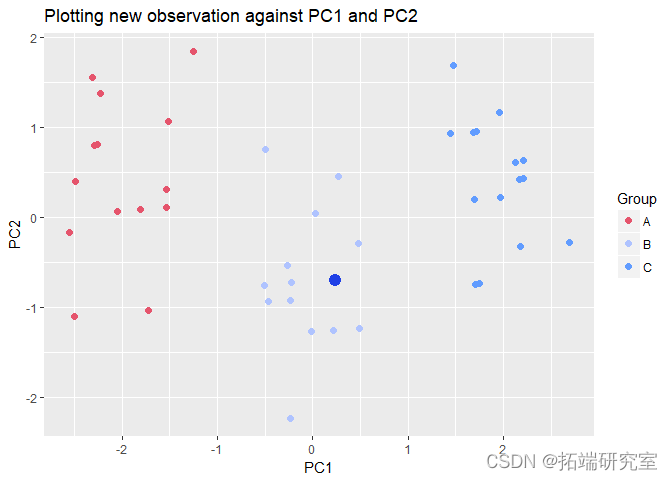
通过观察这个新观察值在 PC1 和 PC2 上的位置,我们可以得出结论,新客户更有可能购买价格组 B 的汽车!如果我需要做出一些不同的预测,我个人会使用这种方法,因为它非常快速且易于理解和解释。这种方法可以扩大规模以构建 PC 回归模型,尤其是当预测变量相关且需要正则化时。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 2026汽车行业全景洞察报告:智能座舱·线控底盘·城市NOA·出海·ESG|附600+份报告PDF、数据、可视化模板汇总下载
2026汽车行业全景洞察报告:智能座舱·线控底盘·城市NOA·出海·ESG|附600+份报告PDF、数据、可视化模板汇总下载 LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据
LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据 Python语义关键词异构图谱TF-IDF、GCN-GAE图卷积自编码器、PCA、t-SNE及KL散度分析中国发明专利数据
Python语义关键词异构图谱TF-IDF、GCN-GAE图卷积自编码器、PCA、t-SNE及KL散度分析中国发明专利数据
