状态空间建模是一种高效、灵活的方法,用于对大量的时间序列和其他数据进行统计推断。本文介绍了状态空间建模,其观测值来自指数族,即高斯、泊松、二项、负二项和伽马分布。
最近我们被客户要求撰写关于状态空间模型的研究报告。在介绍了高斯和非高斯状态空间模型的基本理论后,提供了一个泊松时间序列预测的说明性例子。最后,介绍了与拟合非高斯时间序列建模的其他方法的比较。
状态空间模型为几种类型的时间序列和其他数据的建模提供了一个统一的框架。结构性时间序列、自回归综合移动平均模型(ARIMA)、简单回归、广义线性混合模型和三次样条平滑模型只是一些可以表示为状态空间模型的统计模型的例子。
可下载资源
最简单的一类状态空间模型是线性高斯状态空间模型(也被称为动态线性模型),经常被用于许多科学领域。
总的来说–与ARIMA相比,状态空间模型允许你对更复杂的过程进行建模,具有可解释的结构,并容易处理数据的不规则性;但为此你付出的代价是模型的复杂性增加,校准难度加大,社区知识减少。
ARIMA是一个通用的逼近器–你并不关心你的数据背后的真实模型是什么,你使用通用的ARIMA诊断和拟合工具来逼近这个模型。它就像一个多项式曲线拟合–你不关心什么是真正的函数,你总是可以用某种程度的多项式来近似它。
状态空间模型自然要求你为你的过程写下一些合理的模型(这很好–你用你的过程的先验知识来改进估计)。当然,如果你对你的过程没有任何概念,你也总是可以使用一些通用的状态空间模型–例如,用状态空间的形式表示ARIMA。但是,原始形式的ARIMA有更简明的表述–没有引入不必要的隐藏状态。
因为状态空间模型的表述有很多种类(比ARIMA模型的种类丰富得多),所有这些潜在模型的行为都没有得到很好的研究,如果你制定的模型很复杂,很难说它在不同情况下会有什么表现。当然,如果你的状态空间模型很简单或由可解释的成分组成,就不存在这样的问题。但是ARIMA始终是那个研究得很好的ARIMA,所以即使你用它来近似一些复杂的过程,也应该更容易预测其行为。
因为状态空间允许你直接准确地建立复杂/非线性模型,那么对于这些复杂/非线性模型,你可能会遇到滤波/预测的稳定性问题(EKF/UKF分歧,粒子过滤器退化)。你也可能有校准复杂模型参数的问题–这是一个难以计算的优化问题。ARIMA很简单,有更少的参数(1个噪声源而不是2个噪声源,没有隐藏变量),所以它的校准也更简单。
对于状态空间,统计学界的知识和软件比ARIMA要少。
高斯状态空间模型
本节将介绍有关高斯状态空间模型理论的关键概念。由于卡尔曼滤波背后的算法主要是基于Durbin和Koopman(2012)以及同一作者的相关文章。对于具有连续状态和离散时间间隔的线性高斯状态空间模型t=1, . . . ,n,我们有

其中t∼N(0,Ht),ηt∼N(0,Qt)和α1∼N(a1,P1)相互独立。我们假设yt是一个p×1,αt+1是一个m×1,ηt是一个k×1的向量。α = (α > 1 , . . . , α> n ) >,同样y = (y > 1 , . . , y> n ) >。

状态空间建模的主要目标是在给定观测值y的情况下获得潜状态α的知识。这可以通过两个递归算法实现,即卡尔曼滤波和平滑算法。从卡尔曼滤波算法中,我们可以得到先行一步的预测结果和预测误差

和相关的协方差矩阵
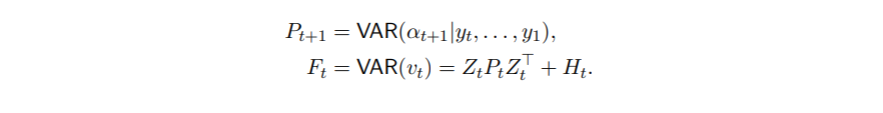
利用卡尔曼滤波的结果,我们建立了状态平滑方程,在时间上向后运行,产生了

对于干扰项t和ηt,对于信号θt = Ztαt,也可以计算类似的平滑估计。
高斯状态空间模型的例子
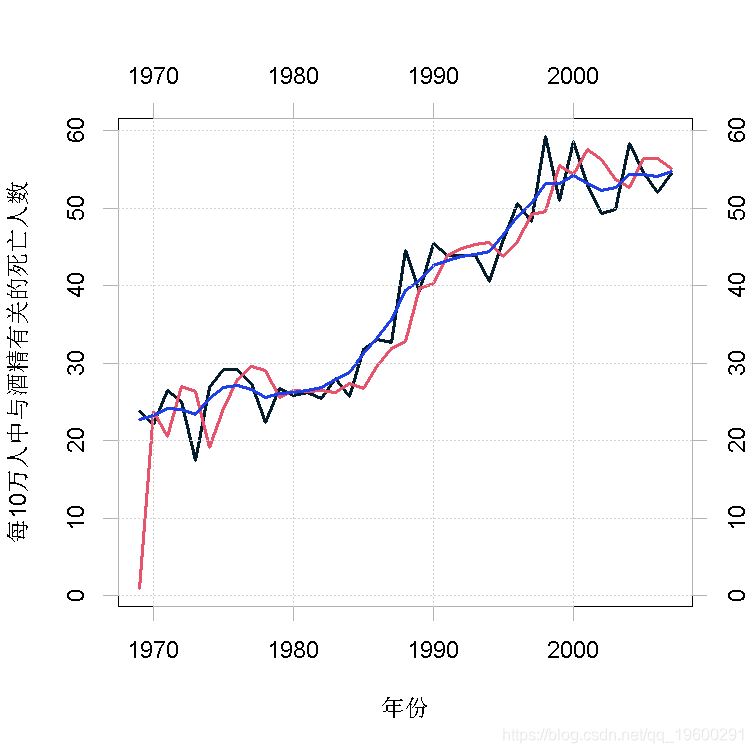
现在通过例子来说明。我们的时间序列包括1969-2007年40-49岁年龄组每年每10万人中酒精相关的死亡人数(图1)。数据取自统计局。对于观测值 y1, … . , yn,我们假设在所有t = 1, . . . , n,其中μt是一个随机游走的漂移过程
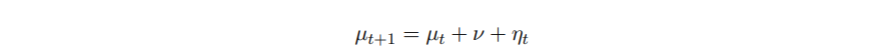
ηt∼N(0, σ2 η)。假设我们没有关于初始状态μ1或斜率ν的先验信息。这个模型可以用状态空间的形式来写,定义为

在KFAS中,这个模型可以用以下代码来写。为了说明问题,我们手动定义所有的系统矩阵,而不采用默认值。
R> Zt <- matrix(c(1, 0), 1, 2)
R> model_gaussian <-Model(deaths / population ~ -1 +custom(Z = Zt)第一个参数是定义观测值的公式(左侧~)和状态方程的结构(右侧)。这里死亡人数/人口是一个单变量时间序列,状态方程是用矩阵来定义的,为了保持模型的可识别性,截距项用-1省略。观测水平方差通过参数H定义,NA值代表未知方差参数σ 2和σ 2 η。估计之后,进行过滤和平滑递归。
KF(fit_gaussian)在这种情况下,最大似然估计值对于σ 2是9.5,对于σ 2 η是4.3。从卡尔曼滤波算法中,我们得到了对状态的一步超前预测,at = (µt , νt) 。请注意,即使斜率项ν在我们的模型中被定义为时间不变量(νt = ν),它也是由卡尔曼滤波算法递归估计的。因此,在每个时间点t,当新的观测值yt可用时,ν的估计值被更新,以考虑到yt所提供的新信息。在卡尔曼滤波结束时,an+1给出了我们对所有数据下恒定斜率项的最终估计。这里斜率项被估计为0.84,标准误差为0.34。对于µt,卡尔曼滤波给出了一步的预测,但是由于状态是时变的,如果我们对t=1, …, n的µt估计值感兴趣,我们还需要运行平滑算法。n的估计值。

图1显示了带有一步预测(红色)和平滑化(蓝色)的随机行走过程µt的估计值的观察结果。请注意典型的模型;在时间t,卡尔曼滤波器计算一步向前预测误差vt = yt – µt,并使用它和先前的预测来修正下一个时间点的预测。在这里,这在系列的开始阶段最容易看到,我们的预测似乎落后于观测值一个时间步长。另一方面,平滑算法同时考虑了每个时间点的过去和未来的数值,从而产生了更平滑的潜过程的估计。
随时关注您喜欢的主题
非高斯状态空间模型的例子
与酒精有关的死亡也可以自然地被建模为泊松过程。现在我们的观测值yt是第t年与酒精有关的死亡的实际计数,而变化的人口规模则由暴露项ut来考虑。状态方程保持不变,但观察方程现在的形式是p(yt |µt) = Poisson(ute µt)。
R> Model(deaths ~ -1 +
+ distribution = "poisson")与之前的高斯模型相比,我们现在需要用参数distribution(默认为 “高斯”)来定义观测数据的分布。我们还通过参数u来定义暴露项,并使用a1和P1的默认值。在这个模型中,只有一个未知参数,即σ 2 η。这个参数被估计为0.0053,但是高斯模型和泊松模型之间σ 2 η的实际值不能直接比较,因为不同模型对µt的解释不同。泊松模型的斜率项估计为0.022,标准误差为1.4×10-4,对应于死亡人数每年增加2.3%。
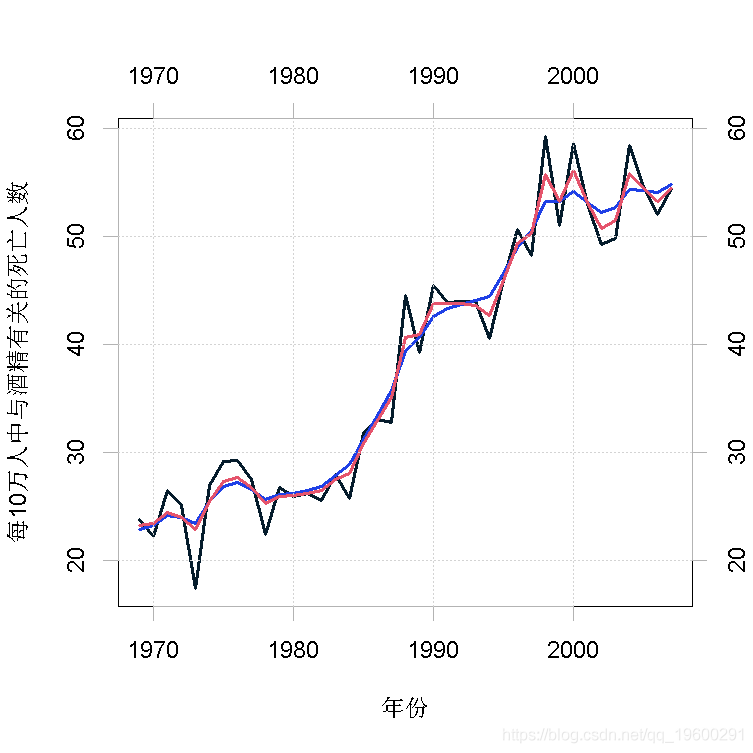
图2显示了以高斯过程(蓝色)和泊松过程(红色)为模型(每10万人的死亡人数)的平滑估计。
任意的状态空间模型
通过结合前面的方法,可以相对容易地构建大量的模型。对于这样做还不够的情况,可以通过直接定义系统矩阵来构建任意状态空间模型。作为一个例子,我们修改了之前的泊松模型,增加了一个额外的白噪声项,试图捕捉数据的可能的过度离散。现在我们的泊松强度模型是ut exp(µt + t),即
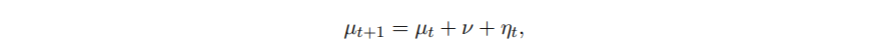
其中ηt∼N(0, σ2 η)如前,t∼N(0, σ2)。这个模型可以用状态空间的形式来写,定义为
Model(deaths ~ trend(2, Q = list(NA, 0)) +
distribution = "poisson")由于模型包含P1中的未知参数,我们需要提供一个特定的模型更新函数。
R> update <- function(pars, model) {
+ model\[ "custom"\] <- exp(pars)
+ } fit(model_poisson,method = "BFGS")
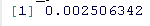
从图3中我们看到,高斯结构时间序列模型和带有额外白噪声的泊松结构时间序列模型对平滑趋势µt的估计几乎没有区别。这是由于泊松过程的强度相对较高。
例子
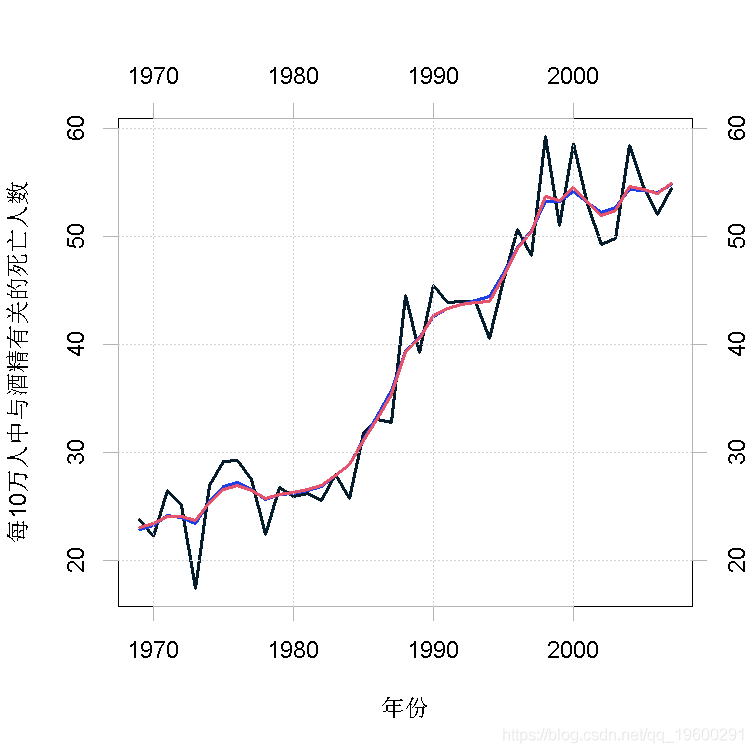
我现在用一个比前面的例子更完整的例子来说明KFAS的使用。数据还是由酒精有关的死亡组成,但现在有四个年龄组,即30-39岁、40-49岁、50-59岁和60-69岁,被一起作为一个多变量泊松模型来建模。
1969-2012年的死亡人数和相应年龄组的年人口规模都有,但作为说明,我们只使用2007年之前的数据,并对2008-2013年进行预测。图4显示了所有年龄组的每10万人的死亡人数。
ts.plot(window(data\[, 1:4\] / data\[, 5:8\], end = 2007)
这里我选择了之前使用的泊松模型的一个多变量扩展。
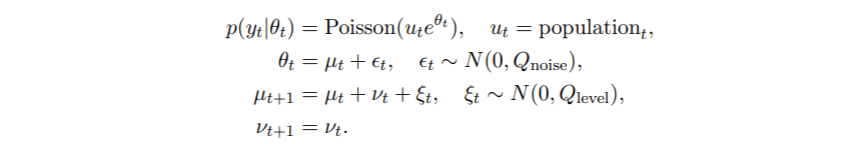
这里μt是带有漂移成分的随机游走,νt是一个恒定的斜率,t是一个额外的白噪声成分,用于捕捉序列的额外变化。我对水平和噪声成分的协方差结构不做限制。模型(4)可以用KFAS构建如下。
R> Model(Pred\[, 1:4\] ~
+ trend(2, Q = list(matrix(NA, 4, 4))
distribution = "poisson"更新函数为
R> updatefn <- function(pars, model, ...){
+ model\[ etas \] <- crossprod(Q)
+ crossprod(Q)
+ model
+ }我们可以先不通过模拟来估计模型参数,然后用这些估计值作为初始值再次运行重要性抽样的估计程序。在这种情况下,从重要性抽样步骤得到的结果实际上与从初始步骤得到的结果相同。
fit(model, update,
+ method = "BFGS")
R> fit <- fit(model, updatefn = updatefn, inits =optimpar)

使用拟合模型的提取方法,我们可以检查估计的协方差和相关矩阵。
R> varcordel\["Q", "level"\]
R> varcordel\["Q", "custom"\]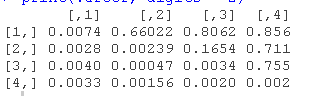
状态空间模型的参数估计通常工作量很大,因为似然面包含多个最大值,从而使优化问题高度依赖于初始值。通常情况下,未知参数与未观察到的潜在状态有关,如本例中的协方差矩阵,几乎没有先验知识。
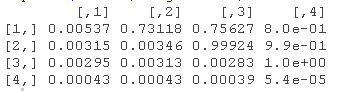
因此,要猜出好的初始值是很有挑战性的,特别是在更复杂的环境中。因此,在可以合理地确定找到适当的最优值之前,建议使用多种初始值配置,可能有几种不同类型的优化方法。这里我们使用观察到的系列的协方差矩阵作为协方差结构的初始值。在非高斯模型的情况下,另一个问题是,似然计算是基于迭代程序的,该程序使用一些终止条件(如对数似然的相对变化)停止,因此对数似然函数实际上包含一些噪声。这反过来又会影响BFGS等方法的梯度计算,在理论上可以得到不可靠的结果。因此,有时建议使用无导数的方法,如Nelder-Mead。另一方面,BFGS通常比Nelder-Mead快得多,因此我更愿意先尝试BFGS,至少在初步分析中。我们可以计算出状态的平滑估计。
R> out <- KF(model,)
我们看到残差之间偶尔有滞后的交叉相关,但总体上我们可以对我们的模型相对满意。现在我们可以用我们估计的模型预测2008-2013年每个年龄组与酒精有关的死亡强度e θt。由于我们的模型是时间变化的(u变化),我们需要通过newdata参数为未来的观察样本提供模型。
predict(model,
+ newdata +
+ interval = "confidence",)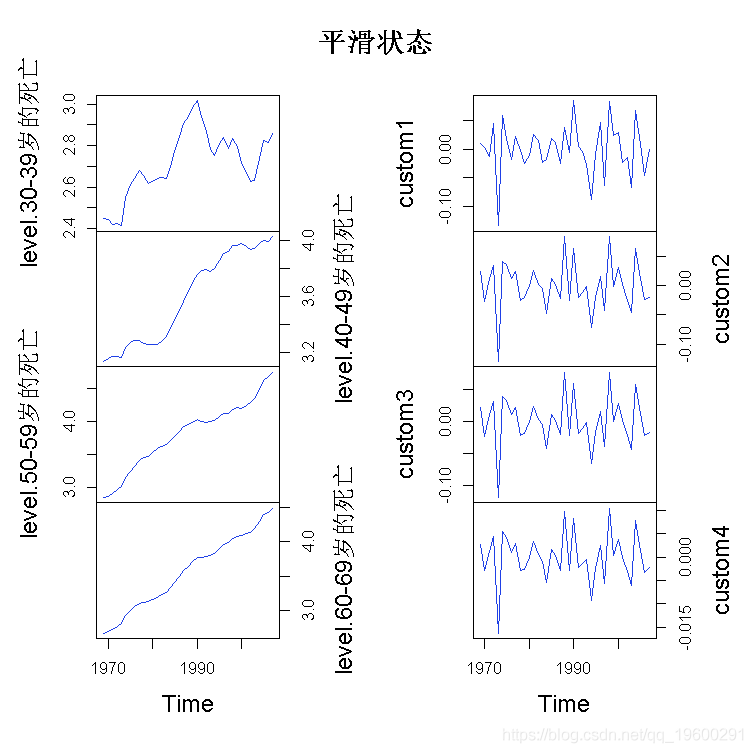
for (i in 1:4) ts.plot(data\[, i\]/data\[, 4 + i\], trend\[, i\], pred\[\[i\]\]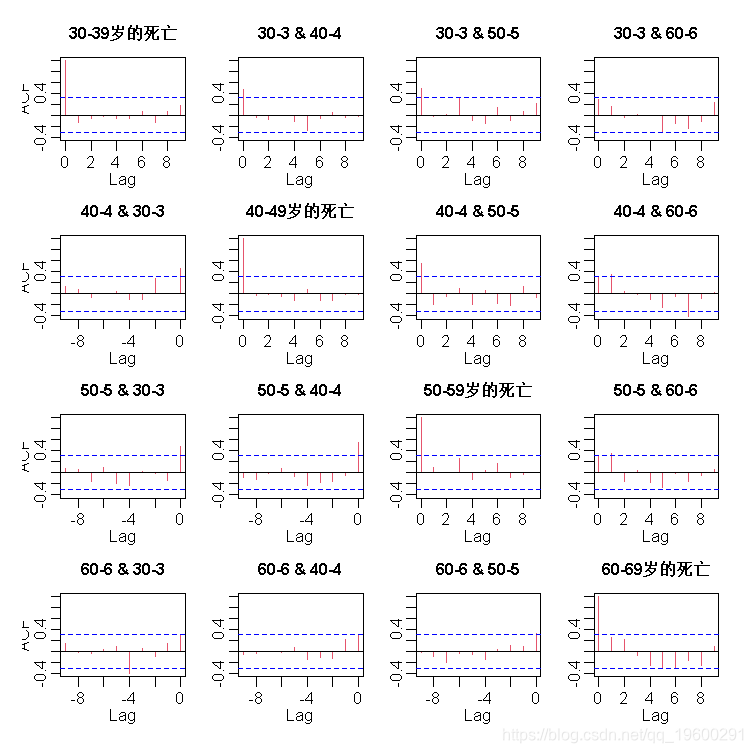
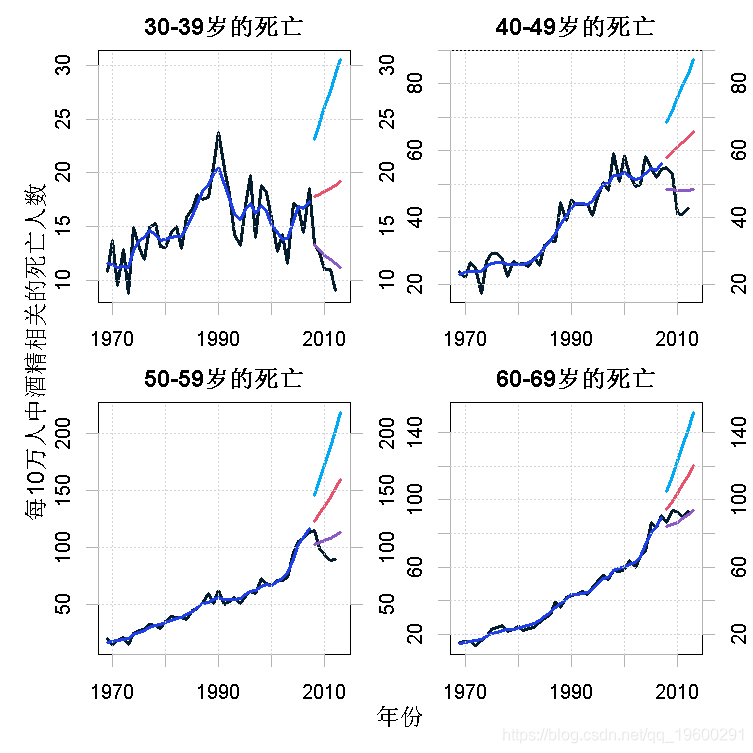
图7显示了观察到的死亡人数,1969-2007年的平滑趋势,以及2008-2013年的预测,还有95%的预测区间。当我们将我们的预测与真实的观察结果进行比较时,我们看到在现实中,最年长的年龄组(60-69岁)的死亡人数略有增加,而在预测期间,另一个年龄组的死亡人数大幅下降。部分原因是在此期间酒精消费总量几乎单调下降,而这又可能是由于2008年、2009年和2012年酒精税的增加造成的。
讨论
状态空间模型提供了解决一大类统计问题的工具。在这里,我介绍了一个用于线性状态空间建模的方法。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



