
回归数据可以用Keras深度学习API轻松拟合。
在本教程中,我们将简要地学习如何通过使用R中的Keras神经网络模型来拟合和预测回归数据。
在这里,我们将看到如何创建简单的回归数据,建立模型,训练它,并最终预测输入数据。该教程包括
- 生成样本数据集
- 建立模型
- 训练模型并检查准确性
- 预测测试数据
- 源代码列表
可下载资源
我们将从加载R的Keras库开始。
library(keras)生成样本数据集
首先,本教程的样本回归序列数据集。
plot( c )
points( a )
points( b )
points( y )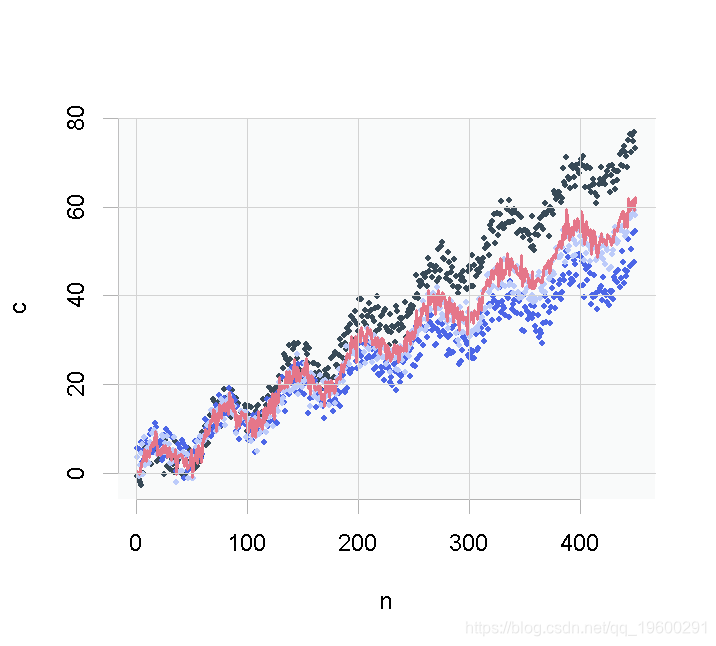
红线是y输出,其余的点是x输入的序列。
我们需要将x输入数据转换成矩阵类型。
x = as.matrix(data.frame(a,b,c))
y = as.matrix(y)
建立模型
接下来,我们将创建一个keras序列模型。
loss = "mse",
optimizer = "adam",
metrics = list("mean\_absolute\_error")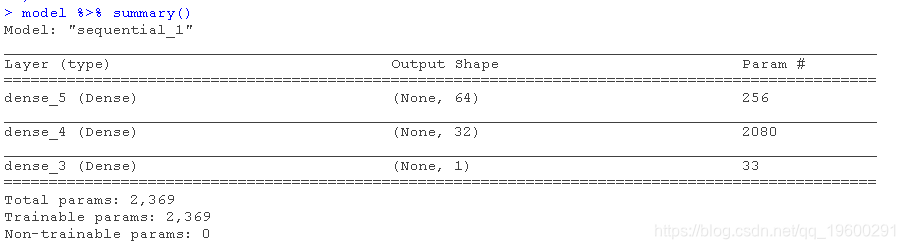
训练模型和检查准确性
接下来,我们将用x、y数据来拟合模型,并检查其准确性。
evaluate(x, y, verbose = 0)
print(scores)
接下来,我们将预测x数据,并在图中与原始y值进行比较。
plot(x, y)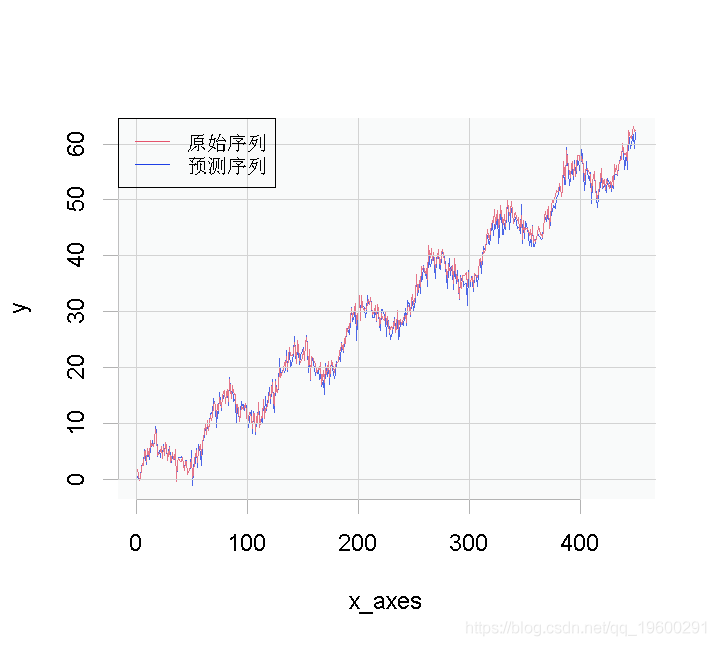
预测测试数据
接下来,我们将把数据集分成训练和测试两部分,再次训练模型,预测测试数据。
fit(train\_x,train\_y)
predict(test_x)
最后,我们将绘制原始测试数据的Y值和预测值。
plot(x, test_y)
lines(x, y_pred)随时关注您喜欢的主题
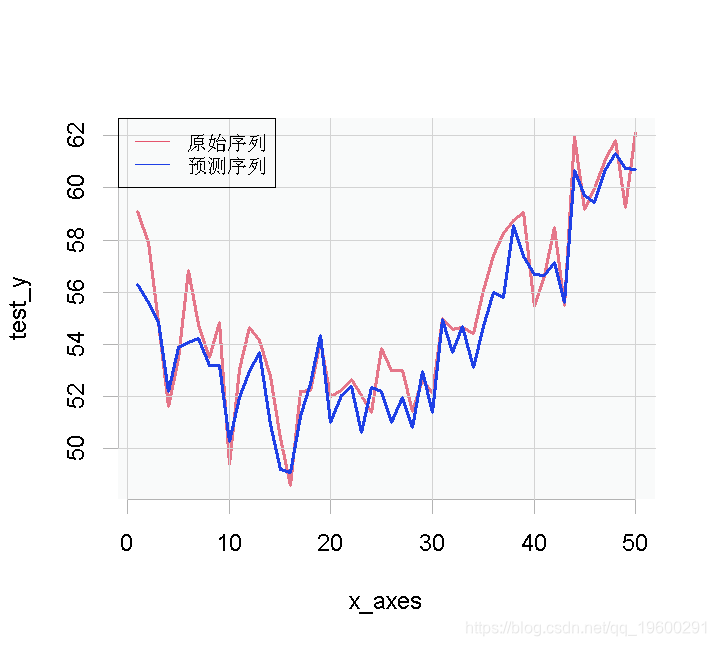
在本教程中,我们已经简单了解了如何在R中用keras神经网络模型拟合回归数据。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python随机矩阵理论RMT算法实现ADRB1受体药物虚拟筛选高精度AUC预测|附数据代码
Python随机矩阵理论RMT算法实现ADRB1受体药物虚拟筛选高精度AUC预测|附数据代码 Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据
Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据



