
在心理学研究中,个人主体的模型正变得越来越流行。原因之一是很难从人之间的数据推断出个人过程。另一个原因是,由于移动设备无处不在,从个人获得的时间序列变得越来越多。
所谓的个人模型建模的主要目标是挖掘潜在的内部心理现象变化。考虑到这一目标,许多研究人员已经着手分析个人时间序列中的多变量依赖关系。
对于这种依赖关系,最简单和最流行的模型是一阶向量自回归(VAR)模型,其中当前时间点的每个变量都是由前一个时间点的所有变量(包括其本身)预测的(线性函数)。
Vector autoregressive model 是多元时间序列分析中最基础的一族模型之一,我们可以从两个角度来理解它,
从纵向比较来看,它是单变量时间序列Autoregressive(AR)模型在多元时间序列上的衍生;
从横向比较来看,它和它的其他小伙伴VMA,VARMA等都是在用线性关系刻画一个平稳的系统;
下面我们主要阐述 VAR的性质,内生变量与外生变量,VAR的应用(厉害在哪里)
1)VAR的性质
向量自回归模型的数学表达如下,Zt是多元变量在t时刻的取值,通过时间推移算子可以将向量自回归的过程紧凑的表达出来;
就像我们可以轻易的从单变量回归走向多变量回归,从AR过程走向VAR过程的数学推导也是类似的;
我们在做参数估计的时候也需要用到 Yule-walker 方程:
当然,最小二乘也是可以的,并且当模型不平稳时最小二乘法估计出来的参数还可以保持一致性;
2) 内生变量与外生变量
内生变量就是参与模型并由模型体系内决定的变量,外生变量时由模型外的因素决定的变量,我们举一个例子便于理解:
下图是一个VARMA模型的部分表达形式,公式本身经过了变换不易于理解,但是我们从图中可以看到Z2是由Z1决定而Z1仅仅由a(随机扰动决定),那么在这个方程组里,Z1是外生的,Z2是内生的;
VAR模型本身,从数学角度上来说并没有强制要求所有的变量均为内生变量
你可以选择一部分变量作为exog,其实质是在进行参数估计前早已经将那一部分参数设置为0;
当然,在大部分日常模型中,既然用VAR,就假定是一个相互影响的关系,都是内生或者用模型估计参数时没有绝对的0出现也是很正常的。
3)VAR 的应用
多元时间序列分析在现实中有很多应用,比如经济,商业,社会科学,地球物理,环境科学,工程学等等;
标准VAR模型的一个关键假设是其参数不随时间变化。然而,人们往往对这种随时间的变化感兴趣。例如,人们可能对参数的变化与其他变量的关系感兴趣,例如一个人的环境变化。可能是一份新的工作,季节,或全球大流行病的影响。在探索性设计中,人们可以研究某些干预措施(如药物治疗或治疗)对症状之间的相互作用有哪些影响。
在这篇博文中,我非常简要地介绍了如何用核平滑法估计时变VAR模型。这种方法是基于参数可以随时间平滑变化的假设,这意味着参数不能从一个值 “跳 “到另一个值。然后,我重点介绍如何估计和分析这种类型的时变VAR模型。
通过核平滑估计时变模型
核平滑法的核心思想如下。我们在整个时间序列的持续时间内选择间隔相等的时间点,然后在每个时间点估计 “局部 “模型。所有的局部模型加在一起就构成了时变模型。对于 “局部 “模型,我们的意思是,这些模型主要是基于接近研究时间点的时间点。这是通过在参数估计过程中对观测值进行相应的加权来实现的。这个想法在下图中对一个数据集进行了说明。
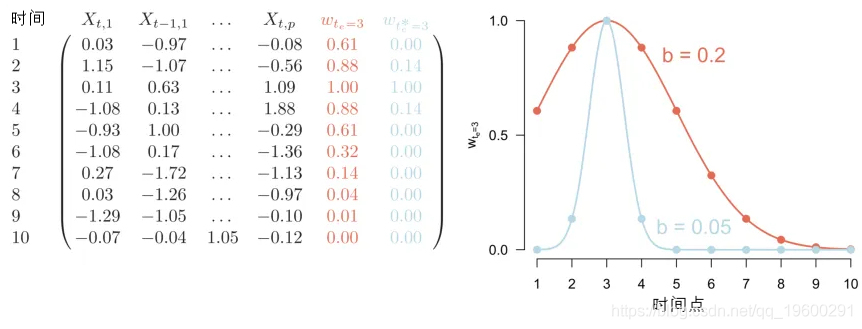
这里我们只说明在t=3时对局部模型的估计。我们在左边的面板上看到这个时间序列的10个时间点。红色的一列w\_t\_e=3表示我们在t=3时估计局部模型可能使用的一组权重:接近t=3的时间点的数据得到最高的权重,而更远的时间点得到越来越小的权重。定义这些权重的函数显示在右图中。左图中的蓝色柱子和右边相应的蓝色函数表示另一种可能的加权。使用这种加权,我们结合了更少的时间上接近的观测值。这使我们能够在参数中检测到更多的 “时间可变性”,因为我们对更少的时间点进行了平滑处理。然而,另一方面,我们使用的数据较少,这使得我们的估计值不太可靠。因此,选择一个加权函数,在对 “时变性 “的敏感性和稳定的估计之间取得良好的平衡是很重要的。在这里介绍的方法中,我们使用了一个高斯加权函数(也称为核),它是由其标准差(或带宽)定义的。我们将在下面讨论如何选择一个好的带宽参数。
加载和检查数据
为了说明估计时变VAR模型,我使用了12个情绪相关变量的ESM时间序列,这些变量每天最多测量10次,连续测量238天。这些问题是 “我感到放松”、”我感到沮丧”、”我感到烦躁”、”我感到满意”、”我感到孤独”、”我感到焦虑”、”我感到热情”、”我感到怀疑”、”我感到高兴”、”我感到内疚”、”我感到犹豫不决”、”我感到坚强”。每个问题都用7分的李克特量表回答,范围从 “不 “到 “非常”。
我们看到数据集有1476个观察样本:
## \[1\] 1476 12head(data)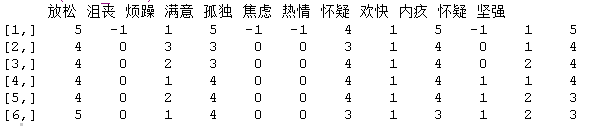
time_data包含每个测量的时间信息。我们将利用测量发生的日期、测量提示和时间戳(time)。

选择最佳带宽
选择好的带宽参数的方法之一是在训练数据集上用不同的候选带宽参数拟合时变模型,并在测试数据集上评估它们的预测误差。此外,数据驱动的带宽选择可能需要相当长的时间来运行。因此,在本文中,我们只是将带宽固定为已经选择的最佳值。
bandwidth <- .26
估计时变var模型
我们现在可以指定时间变化的VAR模型的估计。我们提供数据作为输入,并通过type和level参数指定变量的类型以及它们有多少个类别。在我们的例子中,所有的变量都是连续的,因此我们设置type = rep(“g”)表示连续高斯。我们选择用lambdaSel = “CV “的交叉验证法来选择正则化参数,并且我们指定VAR模型应该包括一个滞后期=1的单滞后期。参数bee和day提供了每个测量的日期和某一天的通知数量。此外,我们还提供了所有测量的时间戳,时间点=time,来说明缺失的测量。然而,请注意,我们仍然假设滞后期大小为1。时间戳只是用来确保加权确实给那些最接近当前估计点的时间点最高的权重。
对于时变模型,我们需要指定两个额外的参数。首先,用 seq(0, 1, length = 20)我们指定我们想在整个时间序列的持续时间内估计20个局部模型(被归一化为[0,1])。估计点的数量可以任意选择,但在某些时候,增加更多的估计点意味着增加了不必要的计算成本,因为后续的局部模型基本上是相同的。最后,我们用带宽参数指定带宽。
# 完整数据集的估算模型
tvvar(data,
type = rep("g"),
lambdaSel = "CV",
lags = 1,
estpoints = seq(0, 1, length = 20),
bandwidth = bandwidth,随时关注您喜欢的主题
我们可以输出对象
# 检查使用了多少数据
obj
其中提供了模型的摘要,也显示了VAR设计矩阵中的行数(876)与数据集中的时间点数量(1476)。前者的数量较少,因为只有在给定的时间点也有滞后1年的时间点时,才能估计VAR(1)模型。
计算时变预测误差
与标准VAR模型类似,我们可以计算预测误差。从模型对象中提供新数据和变量可以计算新样本的预测误差。
参数errorCon = c(“R2”, “RMSE”)指定解释方差的比例(R^2)和均方根误差(RMSE)作为预测误差。最后一个参数Method指定了如何计算时间变化的预测误差。选项Method = “closestModel “使用最接近的局部模型对一个时间点进行预测。这里选择的选项tvMethod = “weighted”,提供了所有局部模型预测的加权平均值,使用以当前时间点的位置为中心的加权函数进行加权。通常情况下,这两种方法得到的结果非常相似。
pred_obj <- predict(object = obj,
data = data,
errorCon = c("R2", "RMSE"),
Method = "weighted")主要的输出是以下两个对象。
tverrors是一个列表,包括每个估计点局部模型的估计误差;errors包含整个估计点的平均误差。
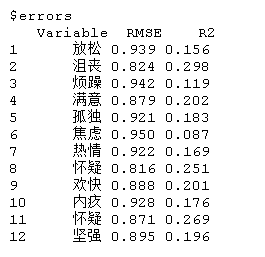
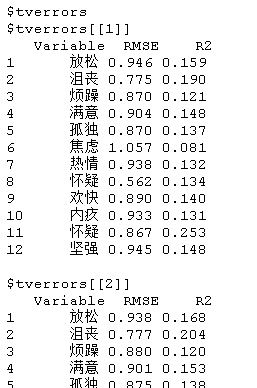
将模型的部分内容可视化
在这里,我们选择了两种不同的可视化方式。首先,我们来检查估计点1、10和20的VAR交互参数。
for(tp in c(1,10,20))igraph(wadj\[, , 1,tp \],
layout = "circle",
paste0("估计点 = "))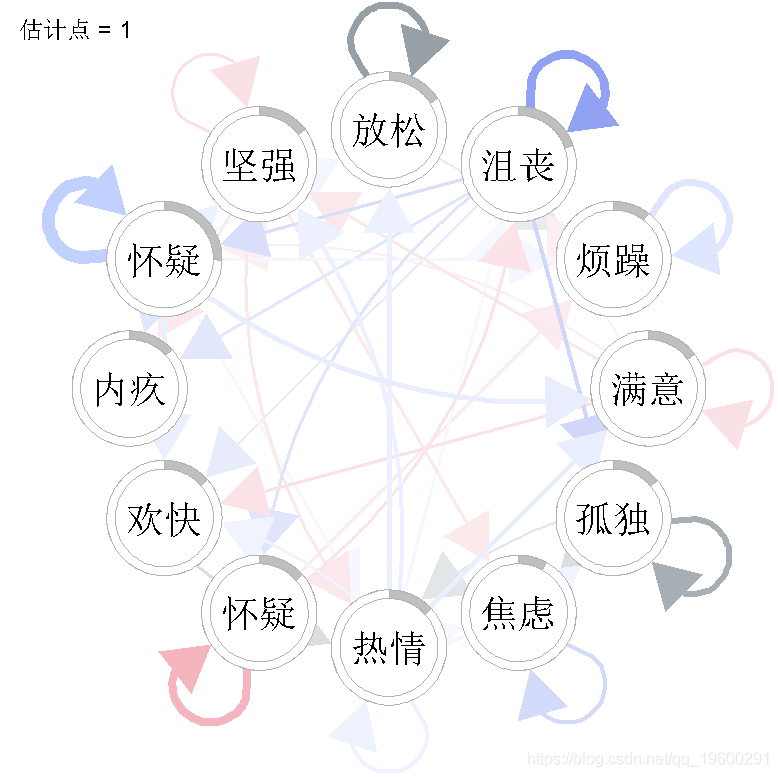
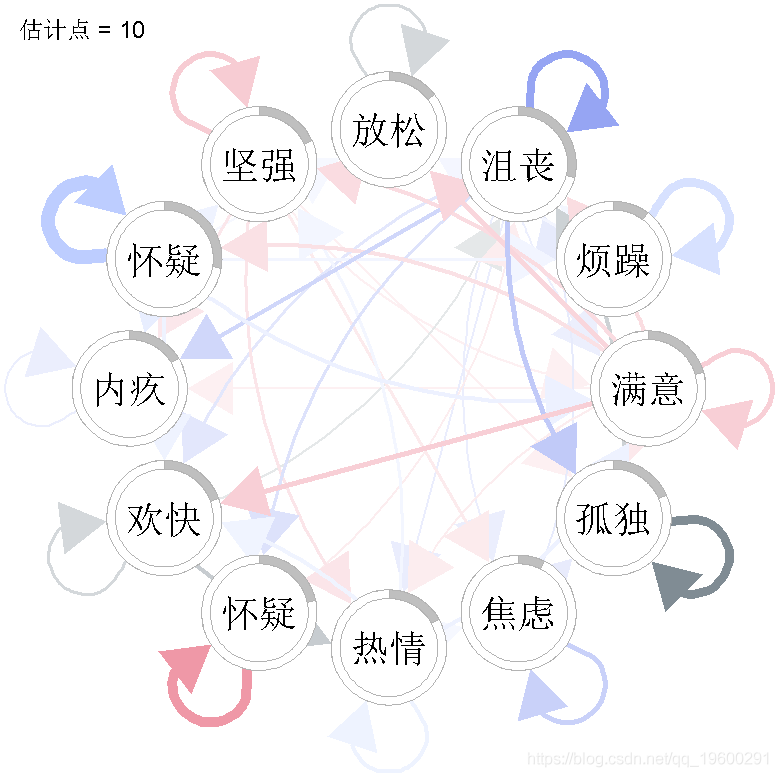
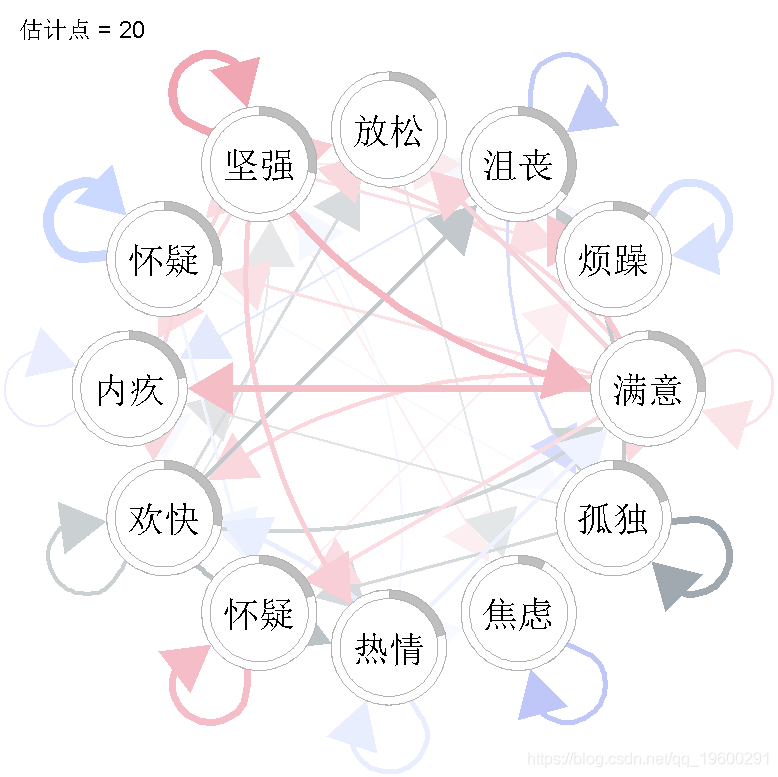
我们看到,VAR 模型中的一些参数随时间变化很大。例如,”放松 “的自相关效应似乎随着时间的推移而减少,”强烈 “对 “满意 “的正效应只出现在估计点20,”满意 “对 “有罪 “的负效应也只出现在估计点20。
我们可以通过绘制这些单个参数与时间的函数来放大它们。
# 画图
title(xlab = "估计点", cex.lab = 1.2)
title(ylab = "参数估计", cex.lab = 1.2)
for(i in 1:nrow(display)) {
lines(1:20, ests\[par_row\[1\], \], lty = i)
legend<- c(expression("轻松"\["t-1"\] %->% "轻松"\["t"\]),
expression("强烈"\["t-1"\] %->% "满意"\["t"\]),
expression("满意"\["t-1"\] %->% "惭愧"\["t"\]))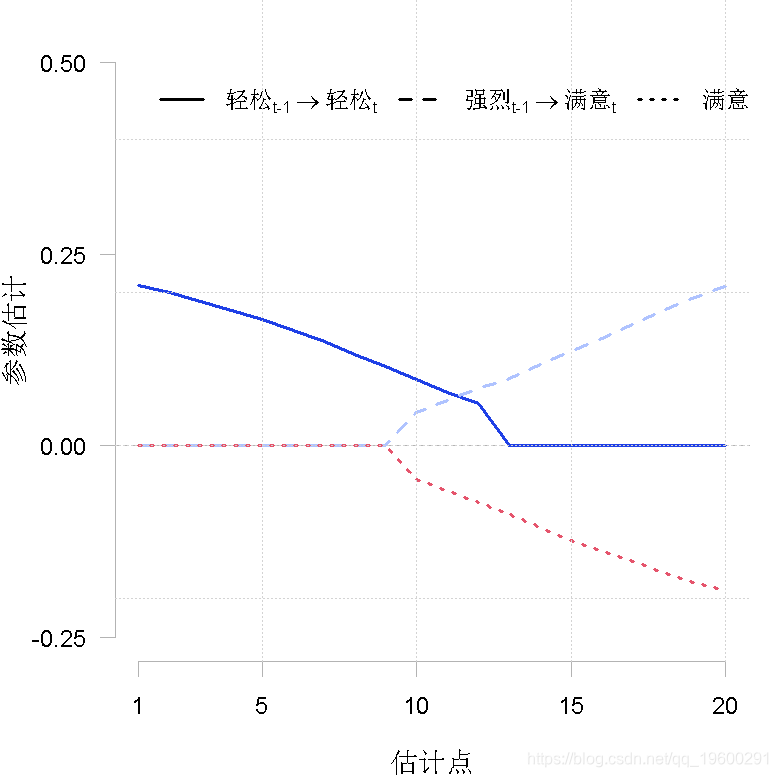
我们看到,在时间序列的开始阶段,”放松 “对其本身的影响是比较强的,但随后会向零下降,并在估计点13左右保持零。“强烈”对“满意”对下一个时间点的交叉滞后效应在估计点9之前等于零,但随后似乎单调地增加。最后,”满意 “对 “惭愧 “的交叉滞后效应也等于零,直到估计点13附近,然后单调地减少了。
估计的稳定性
与标准模型类似,可以使用bootstrap采样分布来评估时变参数的稳定性。
是否有时间变化?
在某些情况下,可能需要决定一个VAR模型的参数是否具有可靠的时变性。为了做出这样的决定,我们可以使用一个假设检验,其原假设是模型不具有时变性。下面是进行这种假设检验的一种方法。首先对数据进行标准的VAR模型的拟合,然后反复模拟这个估计模型的数据。对于每个模拟的时间序列数据集,我们计算出时变模型的集合预测误差。这些预测误差的分布可作为原假设下预测误差的抽样分布。现在我们可以计算时变VAR模型在经验数据上的集合估计误差,并将其作为一个测试统计量。
总结
在本文中,我展示了如何用核平滑法估计一个时变VAR模型,该方法是基于所有参数是时间的平滑函数的假设。除了估计模型外,我们还讨论了选择适当的带宽参数,如何计算(时变的)预测误差,以及如何将模型的不同方面可视化。最后,介绍了如何通过bootstrap法评估估计值的稳定性,以及如何进行假设检验,人们可以用它来选择标准的和时变的VAR模型。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载 2025-2026食品饮料行业全景洞察报告:婴童零辅食、量贩零食、东南亚出海 | 附180+份报告PDF、数据、可视化模板汇总下载
2025-2026食品饮料行业全景洞察报告:婴童零辅食、量贩零食、东南亚出海 | 附180+份报告PDF、数据、可视化模板汇总下载



