环境应激源往往表现出时间上的滞后效应,这就要求使用足够灵活的统计模型来描述暴露-反应关系的时间维度。
最近我们被客户要求撰写关于分布滞后非线性模型(DLNM)的研究报告,这是一个可以同时代表非线性暴露-反应依赖性和滞后效应的建模框架。在数据分析领域,特别是在流行病学研究和环境健康效应评估中,我们经常需要考虑到变量间的非线性关系以及时间滞后效应。分布滞后非线性模型(DLNM)正是一种能有效处理这类复杂关系的建模框架。本报告旨在深入探讨DLNM的原理、构建方法以及其在实践中的应用,以期为客户提供更全面、深入的理解。DLNM是一种建模框架,它结合了非线性暴露-反应依赖性和滞后效应,能够更准确地描述时间序列数据中潜在的非线性和滞后影响的关联。该模型通过引入交叉基函数,对暴露-反应和暴露-滞后效应两个维度进行灵活建模,从而允许我们同时评估暴露因素的滞后效应和非线性效应。
可下载资源
作者

这种方法是基于 “交叉基准 “的定义,这是一个双维的函数空间,它同时描述了沿预测空间和其发生的滞后维度的关系形状。
DLNM的理论进行简单解释(笔者学识尚浅,在学习模型时感觉理论的学习非常依赖 R 语言中 DLNM 包的介绍,一边写程序一边读原文献会对学习模型有很大帮助),分布滞后非线性模型公式如下:
其中, 代表时间,
,
是连接函数族,
为多种可选概率分布(gammma、Poission等),因变量
通常是整形变量(如每日死亡人数,每日患病人数等), 自变量
通常是同期的空气污染物浓度、温度、相对湿度、药物剂量等环境因素,
表示其他混杂因素的线性效应,
、
为相应的系数。
表示各种解释变量的交叉基函数,即对自变量与因变量的关系、滞后效应的分布分别选择合适的基函数,常用的基函数有正交函数、线性阈值函数和样条函数等,具体理论请参看文献
。(笔者这部分看原文献没完全搞清楚,后续会继续研究)
虽然作者在原文献中说 DLNM 的代数理论非常复杂,但感觉复杂的部分实际上就在交叉基那里,整体的建模流程简单来说就两步:
-
利用交叉基进行特征转换,得到新的数据。
-
用广义线性模型对变换后的数据进行建模。
通过这种方式,该方法为以前用于该环境的一系列模型提供了一个统一的框架。为了说明这个方法,我们用DLNMs的例子来表示温度和死亡率之间的关系,使用1987-2000年期间国家发病率、死亡率和空气污染研究中的数据。
简介
有时特定暴露事件的影响并不局限于观察到的那段时间,而是在时间上有所滞后。这就带来了一个问题,即对暴露事件与未来一系列结果之间的关系进行建模,指定事件发生后不同时间的影响分布(定义的滞后期)。最终,这一步需要定义暴露-反应关系的额外滞后维度,描述影响的时间结构。
在评估环境应激源的短期影响时,这种情况经常发生:一些时间序列研究报告称,暴露在高水平的空气污染或极端温度下,会在发生后的几天内影响健康。此外,当一个应激源主要影响一批脆弱的个体时,就会出现这样的现象,这些个体的事件只因暴露的影响而提前了短暂的时间。
在已经提出的处理之后效应的各种方法中,分布式滞后模型(DLM)发挥了主要作用,最近在空气污染和温度研究中被用来量化健康效应。这种方法的主要优点是,它允许模型包含暴露-反应关系的时间过程的详细表述,这反过来又提供了对存在滞后贡献或收获的总体效应的估计。
虽然传统的DLMs适合于描述线性效应的滞后结构,但在用于表示非线性关系时,它们显示出一些局限性。我们提出了一个解决方案,进一步放宽对关系的假设,并将这种方法扩展到分布式滞后非线性模型(DLNM),这是一个模型家族,可以以灵活的方式描述沿预测器空间和其发生的滞后维度同时变化的效应。通过这种方式,DLNM类也为现有的较简单的方法提供了一个统一的框架。
DLNMs以前只在流行病学方面进行过简单的描述:本文的目的是严格地发展这种方法,并描述在统计软件R中专门编写的软件包dlnm中的实现,提供一个使用真实数据集的应用实例。我们简要描述了时间序列分析中使用的基本模型,并介绍了基础的概念,作为描述变量和因变量之间非线性关系的一般方法。我们概述了在时间上滞后效应的复杂性,并提供了一个简单的DLMs的一般表示。然后说明了这种方法在温度对死亡率影响的建模中的应用。最后我们提供了一些讨论并提出了可能的进一步发展。
基本模型
一般的表示法
描述结果Yt的时间序列(t=1,…,n)的一般模型表示方法为

其中,≡E(Y ),g是一个单调的函数,Y被假定来自属于指数族的分布。函数sj表示变量x j和线性预测器之间的平滑关系,由参数向量bj定义。变量uk包括其他预测因子,其线性效应由相关系数k指定。函数sj也可以通过基于广义加性模型的非参数方法来指定。然而,在目前的发展中,我们依靠的是一种完全的参数化方法。
在环境因素的时间序列分析中,结果Yt通常是每日计数,假定来自所谓的过度分散泊松分布。这些研究利用了过去几年中统计方法的重大改进,来量化空气污染的短期影响。通常,这些方法包括一个平滑的时间函数,以识别随时间缓慢变化的混杂因素的影响,表现为季节性或长期趋势。也包括温度和湿度等气象因素的非线性影响。分类变量,如一周中的几天或年龄组被作为因素进行模拟。尽管空气污染通常用线性关系来描述,但为了评估非线性效应,这一假设可以放宽。
在这里,我们关注的是一个一般的函数s,它指定了预测因子x的潜在非线性和滞后效应,通常指的是空气污染或温度,但不失一般性。
基函数
x和g()之间的关系由s(x)表示,它作为一个线性项的总和包含在广义线性模型的线性预测器中。这可以通过选择一个基数来实现,基数是一个函数空间,我们认为s是其中的一个元素。相关的基函数包括一组完全已知的原始变量x的变换,产生一组新的变量,称为基变量。估计关系的复杂性取决于基数的类型和它的维度。几个不同的基础函数被用来描述环境因素对健康的潜在非线性影响,其选择取决于对关系形状的假设、调查的具体目的所要求的近似程度以及解释问题。在完全参数化的方法中,主要的选择通常依赖于描述平滑曲线的函数,如多项式或样条函数,或使用线性阈值参数化,由截断的线性函数(x-)+表示,当x>时等于(x-),否则等于0。上述简单模型的一般表示方法为

滞后效应
额外维度
在存在滞后效应的情况下,在给定时间t的结果可以用过去的暴露xt-来解释,滞后代表暴露和反应之间所经过的时间。一个相对简单的方法是对有序暴露的原始向量x进行转换,得出n×(L+1)矩阵Q,如


这一步规定了暴露-反应关系的额外滞后维度。最终,这里提出的建模框架的目的是同时描述两个维度的依赖关系:通常的预测器空间和新的滞后维度。
分布滞后模型
当假设有线性关系时,滞后效应可以自然地用分布式滞后模型(DLM)来描述。这种方法允许将单一暴露事件的影响分布在一个特定的时间段内,用几个参数来解释不同滞后期的贡献。这些模型已被广泛用于评估环境因素的滞后效应。最简单的表述是无约束的DLM,通过为每个滞后期加入一个参数来指定。不幸的是,由于相邻天数的暴露之间的高度相关性以及由此产生的模型中的串联性,对特定滞后期效应的估计精度往往非常差。
随时关注您喜欢的主题
为了使分布式滞后曲线的估计更加精确,可以施加一些限制条件,例如假设滞后区间内的效应不变,或者使用连续函数如多项式或样条来描述平滑曲线。一个以前L天暴露量的移动平均数为预测因子的简单模型可以被视为DLM的一个特例:这样的模型已被广泛用于空气污染流行病学领域,有时也被用于量化温度的影响。这类模型以前只给过多项式 DLMs。有可能制定一个更简单和通用的DLM定义,其中沿滞后期的分布效应的形状由一个适当的基础指定。在矩阵记号中

我们可以定义

通过构建每个滞后期的隐含线性效应b,可以帮助解释估计的参数gˆ,具体如下。


想了解更多关于模型定制、咨询辅导的信息?
分布式滞后非线性模型
有完善的方法来描述简单滞后模型的灵活暴露-反应关系,或者是简单线性效应的灵活DLM,但很少同时对这两个部分进行建模。已经提出了描述非线性效应的扩展方法,通过对阈值或分段函数的每个项或对线性和二次项分别应用约束矩阵C,可以构建一个DLM。尽管如此,这些方法在描述这种复杂的依赖关系的能力方面仍然有些局限。
通过产生一个新的模型框架,可以描述预测器空间和滞后期的非线性关系,从而实现一个有用的概括,这就是DLNM家族。
交叉基的概念
虽然DLNM的代数符号可能相当复杂,涉及到三维数组,但基本概念是建立在交叉基数的定义上的,是很简单的。交叉基点可以被描绘成一个双维的函数空间,同时描述沿x的关系的形状及其分布的滞后效应。选择交叉基点相当于选择两组基函数,它们将被组合起来产生交叉基函数。
DLNM
为了对我们所考虑的两个空间的关系形状进行建模,我们需要同时应用描述的两个转换。首先,如(2)所述,我们为x选择一个基础来定义预测器空间中的依赖关系,指定Z。然后,如(3)所述,我们为存储在Z中的x的每个派生基变量创建额外的滞后维度。该结构是对称的,即两个转换的顺序可以颠倒,将基函数直接应用于矩阵Q的每一列。
预测网格,用预测效果E的m×(L+1)矩阵和相关的标准误差Esd矩阵表示,可以使用估计系数的向量gˆ,从包括交叉基函数矩阵W的拟合模型中计算得出。

解释DLNM
尽管参数化很复杂,但对DLNM参数的估计和推断并不比任何其他广义线性模型产生更多的问题,而且在指定交叉基变量后,可以用普通的统计软件进行。然而,虽然(4)中较简单的DLM的解释是直接的,包括报告(6)中每个滞后的估计线性效应bˆ,但更复杂的DLNM的结果与平滑的非线性依赖关系很难总结。一个解决方案是为每个滞后期和适当的暴露值建立一个预测网格,使用三维图来提供沿两个维度变化的影响的总体情况。

并且,给定V(gˆ)为估计系数的方差矩阵

这个网格对于计算滞后p的暴露效果或滞后x p的暴露效果的估计很有用,只需分别取e-p和ex p-。最后,通过将不同滞后期的所有贡献相加,可以计算出总体效应的估计值。矢量etot和相关的标准误差esd tot,由每个滞后期的贡献相加得到,说明整个滞后期的暴露效果。


应用
数据和模型选择
我们应用DLNMs来研究1987-2000年期间温度对总体死亡率的影响。数据集来自国家发病率、死亡率和空气污染研究。
它包括5114个总体和特定病因的死亡率、天气和污染数据的每日观测。
分析基于(1)中的模型,通过准泊松族的广义线性模型进行拟合,在控制混杂因素方面有以下选择:每年有7个自由度(df)的时间自然立体样条,以描述长期趋势和季节性;每周一天的指标变量;滞后0-1的露点温度平均值有3个自由度的自然立体样条;滞后0-1的臭氧和CO的平均值的线性项。
glm(death ~ ns.basis + ns(dp01,df=3) + dow + o301 + co01 + ns(date,df=14*7),family=quasipoisson(), data)
这些选择是根据几篇关于时间序列分析的方法学和实质性论文。通过选择两个基点来描述温度和滞后期空间的关系,研究了平均温度的影响;我们说明了一个灵活的模型,用自然立体样条来描述每个维度的关系。结点被放置在温度范围内等距的数值上,以便在尾部有足够的灵活性,而在滞后期的对数尺度上等距放置,以便在分布式滞后期曲线的第一部分有更多的灵活性,因为在那里预计会有更多的变化。最大的滞后期L被设定为30天。为了比较,我们用前几天温度的移动平均数拟合了比较简单的模型。
我们根据修改后的赤池和贝叶斯信息标准来选择结的数量,它定义了每个维度上的df,用于通过准似然法拟合的具有过度分散反应的模型,具体内容如下。

所有的分析都是用R软件进行的。
# 3-D 图 plot(ns.pred,label="Temperature")
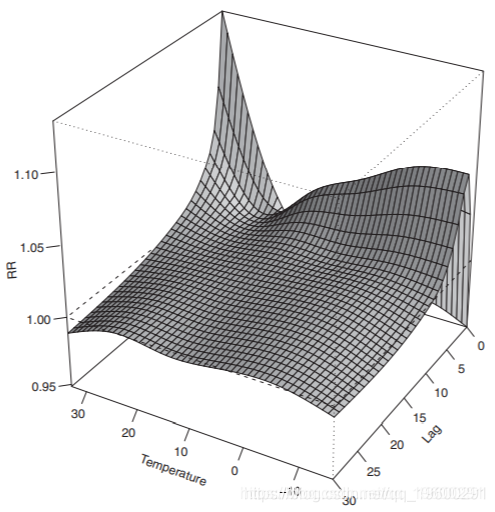
结果
当用于比较不同的建模选择时,QAIC导致了一个相对复杂的模型,预测器空间有11df,滞后维度有5df,总共有55个参数用于定义关系。相比之下,QBIC表明是一个5×5df的模型,用25df来描述总体效果。由于对DLNM框架内这些标准的表现没有任何了解,我们选择了后者作为我们的最终模型。
图1提供了温度对死亡率影响的总体情况,显示了与参考值21◦C(总体最低死亡率点)相比,沿着温度和滞后的相对风险(RR)的三维图。该图显示了热的非常强烈和直接的影响,并表明对极热的温度有更多的滞后影响。寒冷温度的最大影响大约在滞后2-3年达到。
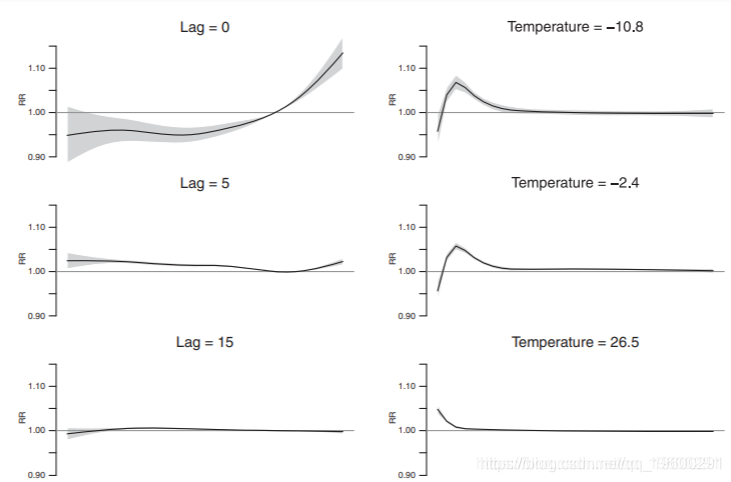
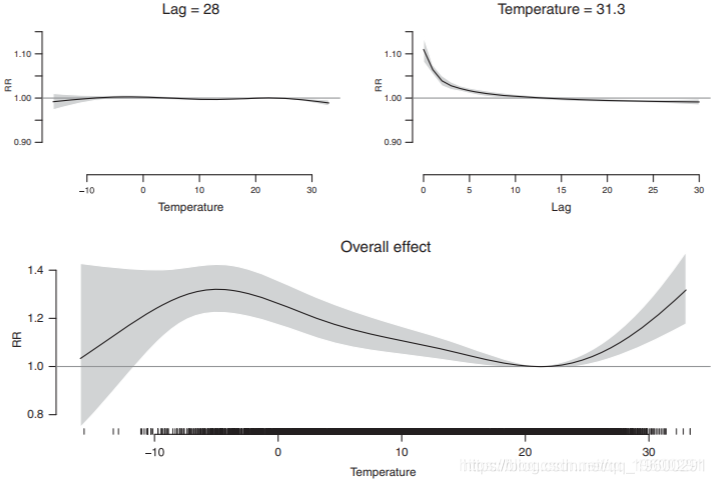
尽管3-D图是总结两个维度的总体关系的有用工具,但不能包括估计的不确定性。为了对这种关系进行更具体的评估,我们可以绘制特定温度或滞后期的影响。图2显示了特定滞后期(0、5、15和28)的温度和特定温度(-10.8、-2.4、26.5和31.3◦C)的滞后期的RR,大约对应于温度分布的第0.1、5、95和99.9百分位数(称为中度和极端寒冷和炎热)。温度的总体影响,将分析中考虑的30天滞后期的贡献相加,包括在下面。温度-死亡率关系似乎随着滞后期而变化,滞后期0和5的最低死亡率点不同(左上角的前两个图)。该图证实,如果与中度高温相比,极端高温的影响更为滞后,其显著风险分别持续10天和3天(右上角第三和第四张图)。尽管如此,只有极端高温表明可能存在收获效应,在滞后15天后开始。相对于21◦C的总体估计RR是1.24(95%CI:1.13-1.36)和1.07(95%CI:1.03-1.11),对于极端和中度高温来说。寒冷的温度显示出完全不同的模式,中度寒冷的影响持续到滞后25天(右上角的前两个图)。此外,寒冷的影响似乎趋于平缓,中度寒冷的总体RR略高,为1.30(95%CI:1.20-1.40),而极度寒冷的RR为1.20(95%CI:1.04-1.39)(如下图)。
plot(ns.pred,"overall"
为了将这一DLNM与更简单的替代方法进行比较,对滞后0-1和滞后0-30的移动平均和温度空间的相同样条函数的模型进行了拟合。前者对高温的影响提供了类似的估计,但显示低温的影响较弱,中度寒冷的估计RR为1.06(95%CI:1.03-1.09)。这一差异可能是由于低估了,因为低温产生的影响持续时间超过2天。相反,滞后0-30的移动平均模型对寒冷的影响相似,但对高温的估计较低,对中度和极端高温的RR分别为1.01(95%CI:0.97-1.04)和1.06(95%CI:0.97-1.17)。考虑到滞后期内的每一个先前的暴露都被假定为对每一天的影响提供了相同的贡献,平均31天的估计值可能会造成一些偏差,这是可信的。上述标准表明DLNM的拟合效果更好,如果与滞后0-1和0-30移动平均模型相比,QAIC的差异为571和517,QBIC为468和445。
已经进行了敏感性分析,以评估模型选择的影响。特别是,我们评估了与改变用于指定交叉基函数(沿两个维度)以及季节性和长期趋势部分的df有关的估计总体效果的变化。增加温度空间的结数,产生的平滑曲线要少得多,可能是由于过度拟合,而在滞后维度上选择不同的样条,没有明显的变化。使用更多的df来控制季节和长期趋势并不影响估计值,除了在非常低的温度下温度-死亡率曲线有不太明显的下降。
此外,对滞后和特定温度曲线的检查显示,当增加季节性控制时,在长滞后期的负面效应完全消失了。因为具有较长滞后期的模型的效果对季节性成分更敏感。
讨论
在本文中,我们描述了DLNMs的类别,可以用来模拟同时显示非线性依赖和滞后效应的因素的影响。DLNM在概念上是简单的,但又足够灵活,允许有广泛的模型,包括以前使用的简单模型和更复杂的新变体。
概念上的简单性允许构建一个R包来拟合这种广泛的模型。这种丰富的选择(基础类型、结的数量和位置、最大滞后)所强调的一个困难是,可以用什么标准来选择替代品。
在上面的例子中,我们用信息标准来指导结点数量的选择,但在选择基类型和最大滞后时,我们用的是先验论证。以前从流行病学的角度对DLNM的选择进行了讨论,由于对什么是 “最佳 “模型没有共识,敏感性分析特别重要,可以评估关键结论对模型选择的依赖性。
DLMN的范围很广,这有助于实现这一目标。回归诊断,如残差和部分自相关图,也可能有帮助。此外,我们已经讨论了DLNM的选择,假设它集中在感兴趣的变量上(在我们的例子中是温度)。还有一个协变量的模型选择问题,其中的一些部分也可能是DLNMs。
这个问题,有时被称为调整的不确定性。同样,在什么方法是最佳的问题上还没有形成共识,对模型选择的这一部分的敏感性分析也很重要。
参考文献
1. Zanobetti A, Schwartz J, Samoli E, Gryparis A, Touloumi G, Atkinson R, Le Tertre A, Bobros J, Celko M, Goren A, Forsberg B, Michelozzi P, Rabczenko D, Aranguez Ruiz E, Katsouyanni K. The temporal pattern of mortality responses to air pollution: a multicity assessment of mortality displacement. Epidemiology 2002; 13(1):87–93.
2. Braga AL, Zanobetti A, Schwartz J. The time course of weather-related deaths. Epidemiology 2001; 12(6):662–667.
3. Schwartz J. Is there harvesting in the association of airborne particles with daily deaths and hospital admissions? Epidemiology 2001; 12(1):55–61.
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R分布滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
R分布滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读 R语言Stan贝叶斯空间条件自回归CAR模型分析死亡率多维度数据可视化
R语言Stan贝叶斯空间条件自回归CAR模型分析死亡率多维度数据可视化 R语言NIMBLE、Stan和INLA贝叶斯平滑及条件空间模型死亡率数据分析:提升疾病风险估计准确性
R语言NIMBLE、Stan和INLA贝叶斯平滑及条件空间模型死亡率数据分析:提升疾病风险估计准确性 R基于贝叶斯加法回归树BART、MCMC的DLNM分布滞后非线性模型分析母婴PM2.5暴露与出生体重数据及GAM模型对比、关键窗口识别
R基于贝叶斯加法回归树BART、MCMC的DLNM分布滞后非线性模型分析母婴PM2.5暴露与出生体重数据及GAM模型对比、关键窗口识别



