对于庞大的公交地铁路线信息的数据挖掘,一般软件遇到的问题主要有两点:1.对于文本信息的挖掘,特别是中文词汇的挖掘,缺乏成熟的工具或者软件包,2.对于大数据量,一般软件的读取和处理会遇到问题。
即使一个月的部分区域路线信息也会达到几百m以上,因此,对于这类数据,无论从算法运行还是数据读取来说普通的SQL语言或者matlab软件处理起来都乏善可陈。
对于这类数据,我们一般用r软件可以轻松实现读取,数据挖掘以及可视化的过程。即使一个月的部分区域路线信息也会达到几百m以上,因此,对于这类数据,无论从算法运行还是数据读取来说普通的SQL语言或者matlab软件处理起来都乏善可陈。
可下载资源
对于这类数据,我们一般用r软件可以轻松实现读取,数据挖掘以及可视化的过程。
1.常见的客流统计
日常地铁的客流统计一般统计三个数据:进站客流、出站客流、换乘客流。
2.接下来是车站、线路、线网的日客运量计算
1)非换乘站日客运量
即本站的日进站客流总数。
2)换乘客流
乘客在整个坐车的过程中换乘的次数都计入换乘客流。至于换乘客流,假设某站为A线与B线换乘站,则该站的换乘客流由两部分组成,A线换B线客流加B线换A线客流,三线换乘站同理。
3)换乘站日客运量
假设某站为A线与B线换乘站,则该站的客运量为A线所辖日进站客流总数加 B线所辖日进站客流总数再加换乘客流。一般换乘站包括AFC、信号等各类设备都分线路进行管辖。
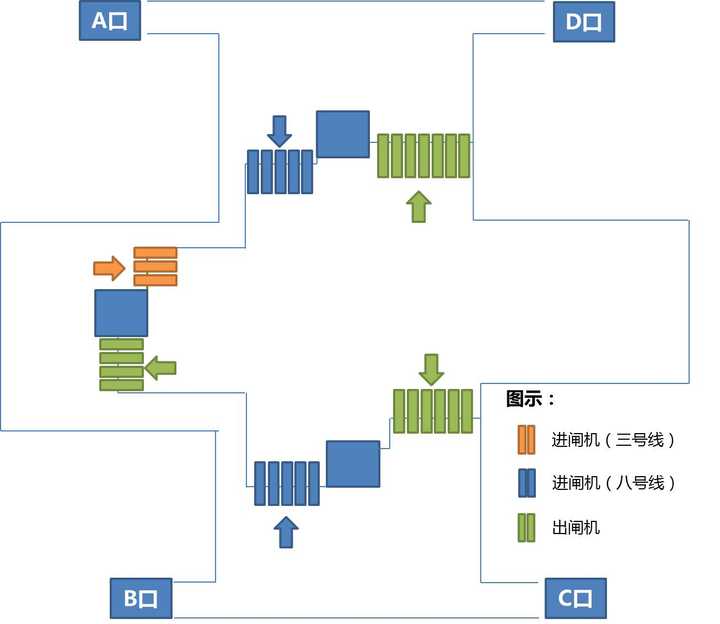
例如广州地铁客村站作为三、八号线的换乘站,其A/D、B/C口下来的进站客流多数通过的是八号线的进闸机计为八号线的客流,每日约6万左右;而北端站厅中部羊城通客服中心位置对应的四台进闸机客流才计为三号线客流,每日仅有几百人左右。
4)单线日客运量
这个就是该问题问到的如何计算线路客运量。一条线路的日客运量等于线路所辖车站的总进站客流加上所有邻线换乘本线总换乘客流。
例如要广州地铁1号线的客运量就等于1号线16个车站的进站客运量加上7个换乘站内其他线路换乘1号线的客运量。
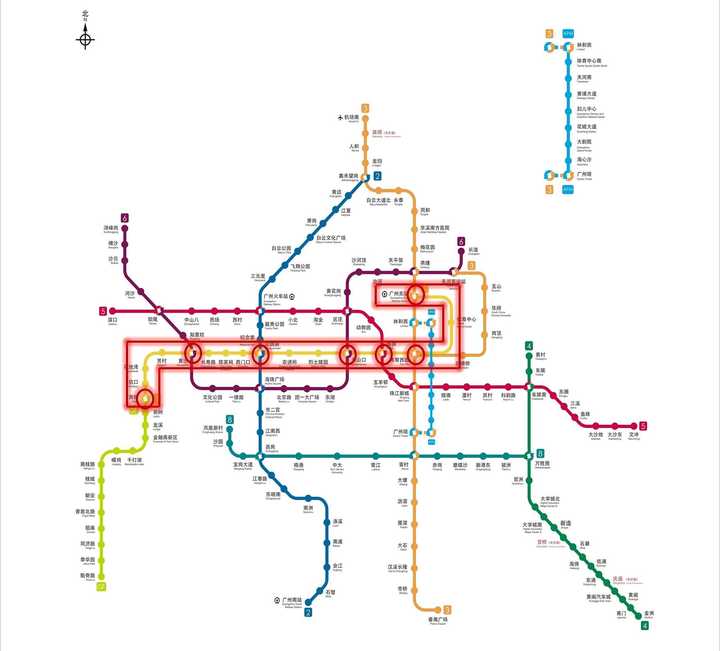
5)线网总客运量
即每日地铁官方微博发布的客运量,即为线网所辖所有线路客运量的总合,由线网所有进站客流量与换乘量的总合计算得出。
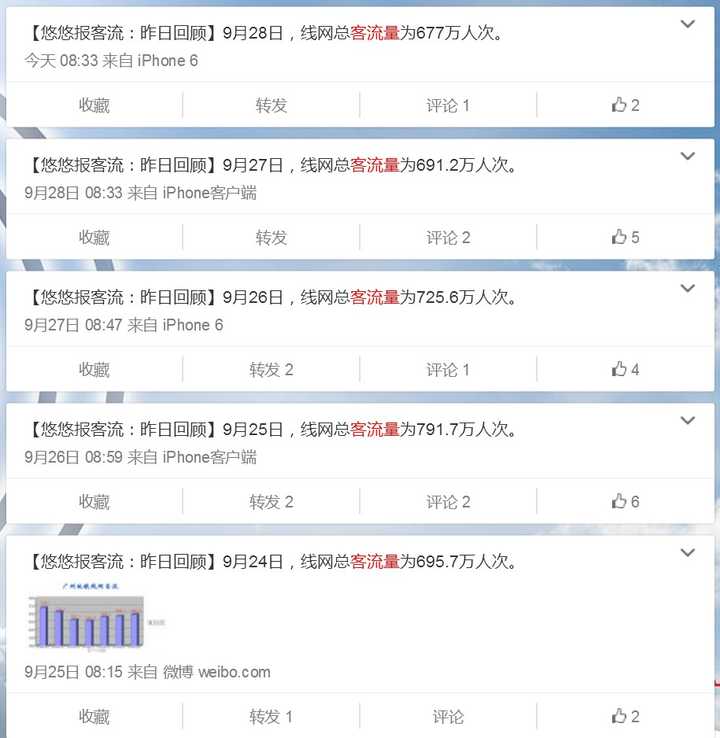
例如对于下面这样的车站数据:
和近600M的进出站信息的数据, 如果要实现每隔一段时间的对应路线的进出站人数整理以及可视化的过程,我们可以进行一下的步骤进行分析:

首先我们进行数据的读取和预处理
install.packages("dplyr")
library("dplyr")#读取dplyr包用以排序
###对数据读取
data=read.table("E:\\\201501一卡通进出站.txt",stringsAsFactors=F)
##对数据列进行命名
colnames(data)=c("逻辑卡号",
"交易日期" ,
"交易时间",
"票种",
"交易代码",
"交易车站",
"上次交易车站")
###对数据进行预处理
for( ii in 20150101:20150131){#每天的数据
data1=data\[which(data\[,2\]==ii),\]#筛选出日期为20150101这天的数据
data2=data1\[,c(2,3,6,7)\]#筛选出"交易日期" ,"交易时间", "交易车站","上次交易车站"的数据
data2#查看数据
data2=data2\[order(data2$交易车站),\]
line1=data2\[substr(data2$交易车站,1,1)=="1",\]#1号线
line2=data2\[substr(data2$交易车站,1,1)=="2",\]#2号线
###筛选出车站为243
bus=unique(data2\[,3\])####################每个站的数据
for(busi in 1:length(bus)){
index=which(data2\[,3\]==bus\[busi\])#筛选出车站为243的数据行号
data3=data2\[index,\]#获取交易车站为243的数据
###data3=data2\[order(data2$交易车站),\]#如果不筛选车站,直接按交易车站递增排序
data4=arrange(data3,交易日期,交易时间)#对时间排序,先按年份递增排序,然后按照时间递增排序
###按每十分钟时间分割
for (time in 6:21){
for(i in 1:6){
index=intersect(which(data4\[,2\]>time\*10000+(i-1)\*1000),which(data4\[,2\]<=time\*10000+1000\*i))
datat=data4\[index,\]
outnum=length(which(datat\[,4\]!=0))
innum=length(which(datat\[,4\]==0))
if(i!=6)cat(file=paste("E:\\\",bus\[busi\],"车站",ii,"日一卡通进出站时间.txt"),append=TRUE,ii,"日",time,"点",i-1,"0分到",i,"0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
else cat(file=paste("E:\\\",bus\[busi\],"车站",ii,"日一卡通进出站时间.txt"),append=TRUE,ii,"日",time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
#cat(file="E:\\\243车站一卡通进出站时间.txt",append=TRUE,time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
}
}
#筛选出出站人数
dataout=data3\[which(data3\[,4\]!=0),\]#上次交易车站不为0,为出站人数
datain=data3\[which(data3\[,4\]==0),\]
###将数据进行输出
write.table(data4,paste("E:\\\",ii,"日 ",bus\[busi\],"车站一卡通进出站整理.txt"))#将数据整理好输出到指定的目录文件名
}
}
####################################################################################3
################1,2号线##########
data2=data2\[order(data2$交易车站),\]
line1=data2\[substr(data2$交易车站,1,1)=="1",\]#1号线
line2=data2\[substr(data2$交易车站,1,1)=="2",\]#2号线
#########1号线
data4=arrange(line1,交易日期,交易时间)#对时间排序,先按年份递增排序,然后按照时间递增排序
###按每十分钟时间分割
cat(file="E:\\\1号线一卡通进出站时间.txt",append=TRUE, " 点", " 分"," 出站人数", " ","进站人数 " ,"\\n")
for (time in 6:21){
for(i in 1:6){
index=intersect(which(data4\[,2\]>time\*10000+(i-1)\*1000),which(data4\[,2\]<=time\*10000+1000\*i))
datat=data4\[index,\]
outnum=length(which(datat\[,4\]!=0))
innum=length(which(datat\[,4\]==0))
if(i!=6)cat(file="E:\\\1号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 "," ",outnum," "," ",innum,"\\n")#cat(time,"点",i-1,"0分到",i,"0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
else cat(file="E:\\\1号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 "," ",outnum," "," ",innum,"\\n")#cat(time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n") #
#cat(file="E:\\\20150101日243车站一卡通进出站时间.txt",append=TRUE,time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
}
}
#筛选出出站人数
dataout=data3\[which(data3\[,4\]!=0),\]#上次交易车站不为0,为出站人数
datain=data3\[which(data3\[,4\]==0),\]
numout=dim(dataout)\[1\]#出站人数总和
numin=dim(datain)\[1\]#进站人数总和
###将数据进行输出
write.table(data4,"E:\\\1号线一卡通进出站整理.txt")#将数据整理好输出到指定的目录文件名
########2号线
data4=arrange(line2,交易日期,交易时间)#对时间排序,先按年份递增排序,然后按照时间递增排序
###按每十分钟时间分割
cat(file="E:\\\2号线一卡通进出站时间.txt",append=TRUE, " 点", " 分"," 出站人数", " ","进站人数 " ,"\\n")
for (time in 6:21){
for(i in 1:6){
index=intersect(which(data4\[,2\]>time\*10000+(i-1)\*1000),which(data4\[,2\]<=time\*10000+1000\*i))
datat=data4\[index,\]
outnum=length(which(datat\[,4\]!=0))
innum=length(which(datat\[,4\]==0))
if(i!=6)cat(file="E:\\\2号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 "," ",outnum," "," ",innum,"\\n")#cat(time,"点",i-1,"0分到",i,"0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
else cat(file="E:\\\2号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 ", " ",outnum," "," ",innum,"\\n")#cat(time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n") #
#cat(file="E:\\\TB related\\\Service\\\temp\\\20150101日243车站一卡通进出站时间.txt",append=TRUE,time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
}
}
#筛选出出站人数
dataout=data3\[which(data3\[,4\]!=0),\]#上次交易车站不为0,为出站人数
datain=data3\[which(data3\[,4\]==0),\]
###将数据进行输出
write.table(data4,"E:\\\2号线一卡通进出站整理.txt")#将数据整理好输出到指定的目录文件名
#########1,2总和
data4=arrange(line1,交易日期,交易时间)#对时间排序,先按年份递增排序,然后按照时间递增排序
data44=arrange(line2,交易日期,交易时间)#对时间排序,先按年份递增排序,然后按照时间递增排序
cat(file="E:\\\1,2号线一卡通进出站时间.txt",append=TRUE, " 点", " 分"," 出站人数", " ","进站人数 " ,"\\n")
for (time in 6:21){
for(i in 1:6){
index=intersect(which(data4\[,2\]>time\*10000+(i-1)\*1000),which(data4\[,2\]<=time\*10000+1000\*i))
index2=intersect(which(data44\[,2\]>time\*10000+(i-1)\*1000),which(data44\[,2\]<=time\*10000+1000\*i))
datat=data4\[index,\]
datat1=data44\[index2,\]
outnum=length(which(datat\[,4\]!=0))
outnum1=length(which(datat1\[,4\]!=0))
innum=length(which(datat\[,4\]==0))
innum1=length(which(datat1\[,4\]==0))
if(i!=6)cat(file="E:\\\1,2号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 "," ",outnum+outnum1," "," ",innum+innum1,"\\n")#cat(time,"点",i-1,"0分到",i,"0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
else cat(file="E:\\\1,2号线一卡通进出站时间.txt",append=TRUE,time," ",i-1,"0 ", " ",outnum+outnum1," "," ",innum+innum1,"\\n")#cat(time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n") #
#cat(file="E:\\\20150101日243车站一卡通进出站时间.txt",append=TRUE,time,"点",i-1,"0分到",time+1,"点0分的出站人数为",outnum," ","进站人数为",innum,"\\n")
}
}
}通过以上过程,我们可以将整理后的数据输出到对应的文件中:
以及交通路线的可视化过程;

对于交通路线的网络图来说,r中igraph包的确是实现利器:
#读取数据
ljhdat1=readLines("E:/ shanghai_1.txt" )
ljhdat2=readLines("E:/ shanghai_2.txt")
ljhdat3=readLines("E:/ shanghai_3.txt")
ljhdat4=readLines("E:/ shanghai_4.txt")
ljhdat5=readLines("E:/ shanghai_5.txt")
bus=""#建立巴士信息库
for(i in 1:length(ljhdat1)){
if(ljhdat1\[i\]=="")bus=c(bus,ljhdat1\[i-1\])#提取每个巴士的路线信息
}
for(i in 1:length(ljhdat2)){
if(ljhdat2\[i\]=="")bus=c(bus,ljhdat2\[i-1\])#提取每个巴士的路线信息
}
for(i in 1:length(ljhdat3)){
if(ljhdat3\[i\]=="")bus=c(bus,ljhdat3\[i-1\])#提取每个巴士的路线信息
}
for(i in 1:length(ljhdat4)){
if(ljhdat4\[i\]=="")bus=c(bus,ljhdat4\[i-1\])#提取每个巴士的路线信息
}
for(i in 1:length(ljhdat5)){
if(ljhdat5\[i\]=="")bus=c(bus,ljhdat5\[i-1\])#提取每个巴士的路线信息
}
bus;
bus=bus\[-1\]
route=list(0)#建立路线信息
#######################分割路线得到站点信息 #################################
route\[\[1\]\]=unlist(strsplit(bus\[1\],split=" "))\[-1\]
route\[\[1\]\]=route\[\[1\]\]\[-which(route\[\[1\]\]=="#")\]#删除#号
n=length(route\[\[1\]\])
library(igraph)
d = data.frame(route\[\[1\]\]\[1:n-1\] ,route\[\[1\]\]\[2:n \]#建立邻接矩阵
)
g = graph.data.frame(d, directed = TRUE)
plot(g )
################################分割所有路线得到站点信息###########################
library(igraph)
route1=character(0);随时关注您喜欢的主题
对于最后生成的网络图由于路线众多,在查看的过程中可以通过设置可视化参数来进一步优化。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据
Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据 2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载
2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载



