在这篇文章中,我们看看什么是渠道归因,以及它如何与马尔可夫链的概念联系起来。
我们还将通过一个电子商务公司的案例研究来理解这个概念如何在理论上和实践上运作(使用R)。
可下载资源
什么是渠道归因?
Google Analytics为归因建模提供了一套标准规则。根据Google的说法,“归因模型是决定销售和转化如何分配给转化路径中的接触点的规则或一组规则。例如,Google Analytics中的最后一次互动模型会为紧接销售或转化之前的最终接触点(即,点击次数)分配100%的功劳。相比之下,第一个互动模型为启动转化路径的接触点分配100%的功劳。“
多渠道归因分析有三个重要的方面,也是三个极具挑战的难题:
1.线上广告投放对线下渠道(店铺销售、品牌价值等)的影响。
2.营销活动的跨屏(台式或手提电脑、移动设备或手机、电视屏幕)影响。
3.转化或销售额对所有线上渠道的归因。
上面三个方面都是跨渠道分析非常重要的方面。我们今天就着重讲解第三个方面,也就是如何将整体转化/销售额在不同的线上渠道之间做出合理的分配。
先看一个例子。假设你在微信、百度以及导流网站(折800、卷皮等)都投放了广告。有767个消费者通过以下路径购买了你的产品:
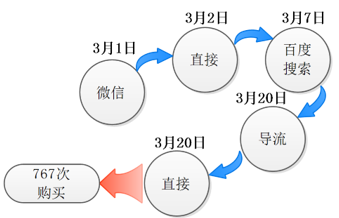
“直接”是指直接输入你的官网网址。
你有以下不同的模型可以完成跨渠道归因:
一、最后点击(Last Click)归因模型
这是一个最典型的归因方式,在所有的网页分析报告及报告工具中(Google Analytics例外),可能包括你们自己的分析系统报告中,都可以看到这样的归因结果。
你可以看到这样的归因模型是比较愚昧的(可是你确实天天在用它!)它会将上面的767个转化统统归因于“直接”渠道。尽管你花了大量的推广费用在微信、百度搜索及导流网站上,这些推广渠道也确实对这767个转化做出了贡献,但你现在使用的归因模型却并没有给它们记上一点功劳。
你可能会诉苦说:我没有办法给它们记上功劳, 因为我不知道在最后转化前,它们都经历了哪些渠道。好!这在过去是个很好的理由,但是现在已经不能成为理由了,因为现在已经有公司的软件可以帮你追踪所有的转化路径了。在不久的将来,如果你还使用这种“最后点击”的归因方式,你的工作恐怕就要保不住了,因为它会将归因结果带到错误的方向上,从而让你的公司白白损失大量广告费!
二、最后一次非直接点击模型
这是Google Analytics的报告中使用的标准模型,它把转化100%归因于最后一个“非直接”渠道上,在上述图示中,就是“导流”网站。
这种做法也是不准确的。首先,很多消费者最终通过“直接”渠道产生购买,原因或者是因为其他渠道的短期影响(例如,微信中的一个软文或展示广告的一个产品宣传让他记住了你公司的URL),或者是因为你的公司长期品牌价值使消费者对你公司的URL一直保持记忆状态(比如说人们直接输入http://JD.com进入京东官网点击购买)。这种情况下,将转化贡献完全归功于“直接”渠道前的“导流”显然是夸大了“导流”渠道的作用,因而也是不准确的。是的,我确实是在说: Google Analytics报告中的归因模型是有缺陷的!
三、首次点击(First Click)归因模型
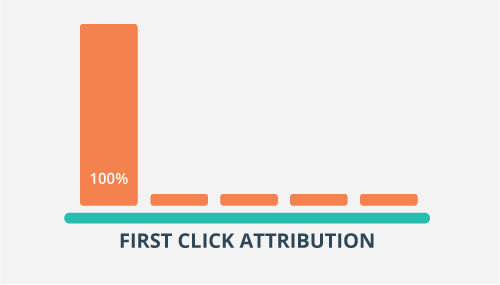
这个是最后点击归因的反向,它将所有的转化的功劳归功于消费者第一次点击的渠道。在上面的图示中,就是“微信”渠道。
这个模式初看起来也有一点道理,但仔细想想也会有很多漏洞:你的初次点击可能发生在两年前,然后你彻底地忘记了那个网站。两年后那家公司在“爱奇艺”上做了大量广告,你看到了并进入了官网产生了购买。这种模式完全忽略了让你购买的“爱奇艺”的广告效果。更为麻烦的是,在很多情况下,我们无法确切地知道哪一个渠道是消费者真正接触到的“第一个渠道”,就像没有人会知道他/她所有的朋友的第一个恋人是谁一样,尽管他/她可能可能会知道那些朋友现任的太太/丈夫的名字。
四、线性归因模型

假设你刚刚拿到了奥斯卡奖,奖金有100万(这只是个假设),你将要拿这些钱感谢帮助你拿到奖的人。为了简化模型,我们假设对你有帮助的人只有你的父亲、母亲、经纪人和导演。你将怎么分配这些钱呢?
有一个方法比较简单粗暴,给他们平分了。也就是说,他们给你的帮助都是等价的,没有人做特殊处理。这个方法虽然简单,也考虑了多方面的因素对你产生的影响,但是,很显然,这不够合理。
线性归因模型就像这样,把贡献率以等量权重赋值给所有影响因素/渠道。
五、基本位置归因模型

这种模型将40%转化归功于首次点击,另外40%归功于最后点击,剩余20%平均分配给中间渠道。该模型看上去比上面的几种更合理一些,而且简单实用。如果你的公司没有很好的统计分析师或者数据科学家,你可以尝试这种模型。
六、时间衰减模型
当一次广告展示或者点击行为离最终购买时间越久远,它在你记忆中留下的印象越模糊,对最终转化的贡献就越小。所以,时间衰减模型用时间衰减曲线来给不同的渠道触点分配权重。在此基础上得到一个合理的渠道贡献分配比例。如下图:

这种模型比上述其他模型要合理一些,困难点在于如何拟合不同的时间衰减曲线。这需要专业知识及对业务的充了解。
七、个性化的归因模型
事实上,不同的企业有不同的产品类别,不同的消费群体,采用不同的市场推广方式。这在很大程度上限制了上述模型,特别是后面几类模型的应用。并不是说上述模型不能用,主要原因是归因的准确度会有很大的影响。很多因素,例如市场状况、消费者类别、竞争对手状况、长期品牌价值的影响、地域情况等都会影响到归因的准确性。
多渠道归因分析可以说是在大数据分析领域少有的几个最具复杂性和挑战性的分析项目之一。目前,有少数公司投入了大量的人力物力开发了针对不同行业的专用的个性化归因模型。这样的专业模型在大数据的基础上考虑了尽可能多的因素的影响,在归因准确程度方面比一般的模型提升很多。例如北京目标科技责任有限公司就开发了这种专业模型,可以为电商、互联网金融、教育、游戏、汽车等行业提供专业的的渠道归因和优化服务。
渠道归因分析的好处是显而易见的。它能让很多企业把钱投在最有效的推广渠道上,在不增加市场推广费用的情况下,通过合理安排推广费用在不同渠道间的分配,显著提升销售额。
我们将在本文后面看到最后一个交互模型和第一个交互模型。在此之前,让我们举一个小例子,进一步了解渠道归因。假设我们有一个转换图,如下所示:
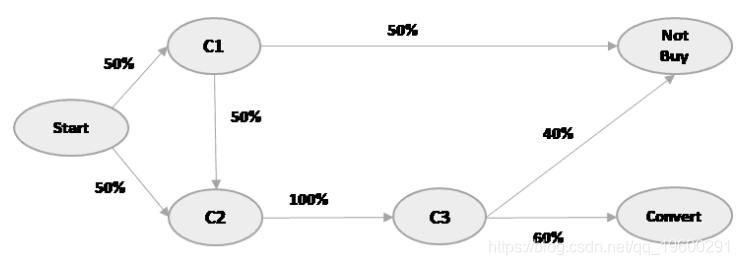
在上述情况下,客户可以通过渠道’C1’或渠道’C2’开始他们的旅程。以C1或C2开始的概率为50%(或0.5)。我们首先计算转换的总体概率,然后进一步查看每个渠道的影响。

P(转换)= P(C1→C2→C3→转换)+ P(C2→C3→转换)
= 0.5 * 0.5 * 1 * 0.6 + 0.5 * 1 * 0.6
= 0.15 + 0.3
= 0.45
马尔可夫链
马尔可夫链是一个过程,它映射活动并给出概率分布,从一个状态转移到另一个状态。马尔可夫链由三个属性定义:
状态空间 – 处理可能存在的所有状态的集合
转换操作 – 从一个状态转移到另一个状态的概率
当前状态概率分布 – 在过程开始时处于任何一个状态的概率分布
我们知道我们可以通过的阶段,从每条路径移动的概率以及我们知道当前状态的可能性。这看起来与马尔可夫链相似。
事实上,这是一个马尔可夫链的应用。如果我们要弄清楚渠道1在我们的客户从始至终转换的过程中的贡献,我们将使用去除效果的原则。去除效果原则说,如果我们想要在客户过程中找到每个渠道的贡献,我们可以通过删除每个渠道并查看在没有该渠道的情况下发生了多少次转化。
例如,我们假设我们必须计算通道C1的贡献。我们将从模型中删除通道C1,并查看图片中没有C1的情况下发生了多少次转换,即所有渠道完好无损时的总转换次数。我们计算渠道C1: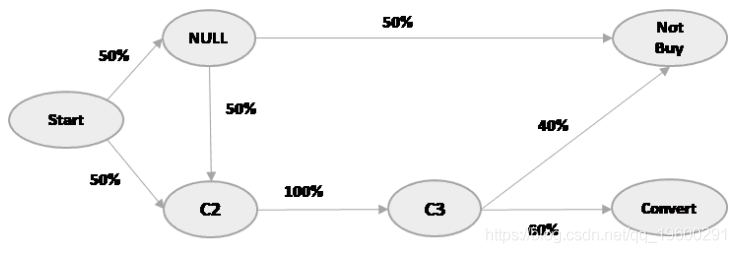
P(去除C1后的转换)= P(C2→C3→转换)
= 0.5 * 1 * 0.6
= 0.3
30%的客户互动可以在没有C1渠道的情况下进行转换; 而C1完好无损,45%的互动可以转换。所以,C1的去除效果是

0.3 / 0.45 = 0.666。
C2和C3的去除效果为1(您可以尝试计算,但直觉地认为,如果我们要删除或者C2或C3,我们将能够完成任何转换?)。
这是马尔可夫链的一个非常有用的应用。在上述情况下,所有渠道–C1,C2,C3(在不同阶段)被称为转换状态 ; 而从一个渠道移动到另一个渠道的概率称为转移概率。
客户旅程是一系列渠道,可以看作是一个有向马尔可夫图中的一个链,其中每个顶点都是一个状态(渠道/接触点),每条边表示从一个状态移动到另一个状态的转移概率。由于到达状态的概率仅取决于之前的状态,因此可以将其视为无记忆马尔可夫链。
随时关注您喜欢的主题
电子商务公司案例研究
让我们进行真实案例研究,看看我们如何实施渠道归因建模。
一家电子商务公司进行了一项调查并收集了客户的数据。这可以被认为是具有代表性的人群。在调查中,公司收集了有关客户访问各种触点的数据,最终在其网站上购买该产品。
总共有19个渠道,客户可以遇到产品或产品广告。在19个渠道之后,还有三种情况:
#20 – 客户决定购买哪种设备;
#21 – 客户已经做出最终购买;
#22 – 客户尚未决定。
渠道的总体分类如下:
| 类别 | 渠道 |
| 网站(1,2,3) | 公司的网站或竞争对手的网站 |
| 研究报告(4,5,6,7,8) | 行业咨询研究报告 |
| 在线/评论(9,10) | 自然搜索,论坛 |
| 价格比较(11) | 聚合渠道 |
| 朋友(12,13) | 社交网络 |
| 专家(14) | 在线或离线专家 |
| 零售店(15,16,17) | 实体店 |
| 其他 (18,19) | 其他,例如在各地的促销活动 |
现在,我们需要帮助电子商务公司确定投资营销渠道的正确策略。应该关注哪些渠道?公司应该投资哪些渠道?我们将在下一节中使用R来解决这个问题。
使用R的实现
我们读取数据,尝试在R中实现并检查结果。
> head(channel)输出:
R05A.01 R05A.02 R05A.03 R05A.04 ….. R05A.18 R05A.19 R05A.20
16 4 3 5 NA NA NA
2 1 9 10 NA NA NA
9 13 20 16 NA NA NA
8 15 20 21 NA NA NA
16 9 13 20 NA NA NA
1 11 8 4 NA NA NA我们将进行一些数据处理,将其带入一个阶段,我们可以将其用作模型中的输入。然后,我们将确定哪些客户已进行最终转换。
创建一个特定格式的变量’路径’,可以作为模型的输入。另外,我们将使用“dplyr”包找出每条路径的总发生次数。
路径转变
| 路径 | 转换 |
| 1 > 1 > 1 > 20 | 1 |
| 1 > 1 > 12 > 12 | 1 |
| 1 > 1 > 14 > 13 > 12 > 20 | 1 |
| 1 > 1 > 3 > 13 > 3 > 20 | 1 |
| 1 > 1 > 3 > 17 > 17 | 1 |
| > 1 > 6 > 1 > 12 > 20 > 12 | 1 |
> channel_fin = ddply(channel_fin,~path,summarise, conversion= sum(convert))
> head(channel_fin)输出:
路径转变
| 路径 | 转换 |
| 1 > 1 > 1 > 20 | 1 |
| 1 > 1 > 12 > 12 | 1 |
| 1 > 1 > 14 > 13 > 12 > 20 | 1 |
| 1 > 1 > 3 > 13 > 3 > 20 | 1 |
| 1 > 1 > 3 > 17 > 17 | 1 |
| 1 > 1 > 6 > 1 > 12 > 20 > 12 | 1 |
现在,我们将创建一个启发式模型和一个马尔科夫模型,将两者结合起来,然后检查最终结果。
输出:
Output:
| 渠道名称 | 首次接触转换 | ….. | 线性接触转换 | 线性接触值 |
| 1 | 130 | 73.773661 | 73.773661 | |
| 20 | 0 | 473.998171 | 473.998171 | |
| 12 | 75 | 76.127863 | 76.127863 | |
| 14 | 34 | 56.335744 | 56.335744 | |
| 13 | 320 | 204.039552 | 204.039552 | |
| 3 | 168 | 117.609677 | 117.609677 | |
| 17 | 31 | 76.583847 | 76.583847 | |
| 6 | 50 | 54.707124 | 54.707124 | |
| 8 | 56 | 53.677862 | 53.677862 | |
| 10 | 547 | 211.822393 | 211.822393 | |
| 11 | 66 | 107.109048 | 107.109048 | |
| 16 | 111 | 156.049086 | 156.049086 | |
| 2 | 199 | 94.111668 | 94.111668 | |
| 4 | 231 | 250.784033 | 250.784033 | |
| 7 | 26 | 33.435991 | 33.435991 | |
| 5 | 62 | 74.900402 | 74.900402 | |
| 9 | 250 | 194.07169 | 194.07169 | |
| 15 | 22 | 65.159225 | 65.159225 | |
| 18 | 4 | 5.026587 | 5.026587 | |
| 19 | 10 | 12.676375 | 12.676375 |
输出:
:
| 渠道名称 | 总体转换 | 总体转换值 | |
| 1 | 82.482961 | 82.482961 | |
| 20 | 432.40615 | 432.40615 | |
| 12 | 83.942587 | 83.942587 | |
| 14 | 63.08676 | 63.08676 | |
| 13 | 195.751556 | 195.751556 | |
| 3 | 122.973752 | 122.973752 | |
| 17 | 83.866724 | 83.866724 | |
| 6 | 63.280828 | 63.280828 | |
| 8 | 61.016115 | 61.016115 | |
| 10 | 209.035208 | 209.035208 | |
| 11 | 118.563707 | 118.563707 | |
| 16 | 158.692238 | 158.692238 | |
| 2 | 98.067199 | 98.067199 | |
| 4 | 223.709091 | 223.709091 | |
| 7 | 41.919248 | 41.919248 | |
| 5 | 81.865473 | 81.865473 | |
| 9 | 179.483376 | 179.483376 | |
| 15 | 70.360777 | 70.360777 | |
| 18 | 5.950827 | 5.950827 | |
| 19 | 15.545424 | 15.545424 |
在进一步讨论之前,我们先来了解一下我们上面看到的一些术语的含义。
第一次接触转换:当该渠道是客户的第一个触点时,通过渠道进行的转换。第一个触点获得100%的功劳。
上次接触转换:当该渠道是客户的最后一个接触点时,通过渠道发生的转化。100%功劳给予最后的接触点。
回到R代码,让我们合并这两个模型,并以可视化方式表示输出。
# 绘制总转换
ggplot(R1, aes(channel_name, value, fill = variable)) +
geom_bar(stat='identity', position='dodge') +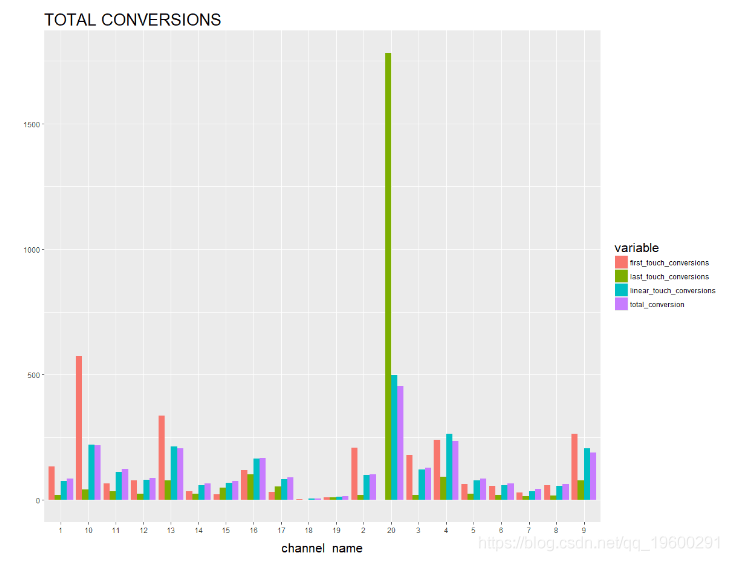
从上图中可以清楚地看到结果。从第一次接触转换角度来看,渠道10,渠道13,渠道2,渠道4和渠道9非常重要; 而从最后接触的角度来看,第20渠道是最重要的(因为在我们的例子中客户决定购买哪种产品)。就线性接触转换而言,渠道20、渠道4和渠道9是重要的。从总转换角度来看,渠道10,13,20,4和9非常重要。
结束
在上面的图表中,我们已经能够找出哪些是我们关注的重要渠道,哪些可以被忽略或忽视。这种情况使我们对客户分析领域马尔可夫链模型的应用有了很好的了解。电子商务公司现在可以更准确地创建他们的营销策略,并使用数据驱动的见解分配他们的营销预算。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年AI短剧发展研究报告:出海爆发、精品化转型、品牌营销重构 | 附100+份报告PDF、数据、可视化模板汇总下载
2026年AI短剧发展研究报告:出海爆发、精品化转型、品牌营销重构 | 附100+份报告PDF、数据、可视化模板汇总下载 中国AI+营销趋势洞察报告2026:生成式AI、代理AI、GEO营销|附400+份报告PDF、数据、可视化模板汇总下载
中国AI+营销趋势洞察报告2026:生成式AI、代理AI、GEO营销|附400+份报告PDF、数据、可视化模板汇总下载 2025中国快消市场发展趋势报告:数字化转型与营销|附500+份报告PDF、数据模板汇总下载
2025中国快消市场发展趋势报告:数字化转型与营销|附500+份报告PDF、数据模板汇总下载 2025母婴用品双11营销解码与AI应用洞察报告|附40+份报告PDF、数据、绘图模板汇总下载
2025母婴用品双11营销解码与AI应用洞察报告|附40+份报告PDF、数据、绘图模板汇总下载



