最近,我们使用隐马尔可夫模型开发了一种解决方案,并被要求解释这个方案。
HMM用于建模数据序列,无论是从连续概率分布还是从离散概率分布得出的。它们与状态空间和高斯混合模型相关,因为它们旨在估计引起观测的状态。状态是未知或“隐藏”的,并且HMM试图估计状态,类似于无监督聚类过程。
可下载资源
视频
R语言中的隐马尔可夫HMM模型实例
例子
在介绍HMM背后的基本理论之前,这里有一个示例,它将帮助您理解核心概念。有两个骰子和一罐软糖。B掷骰子,如果总数大于4,他会拿几颗软糖再掷一次。如果总数等于2,则他拿几把软糖,然后将骰子交给A。现在该轮到A掷骰子了。如果她的掷骰大于4,她会吃一些软糖,但是她不喜欢黑色的其他颜色(两极分化的看法),因此我们希望B会比A多。他们这样做直到罐子空了。
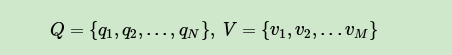

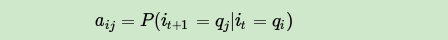
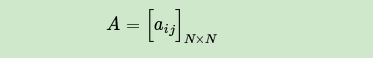
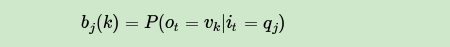
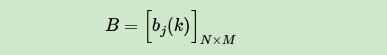


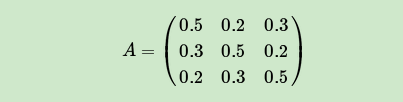
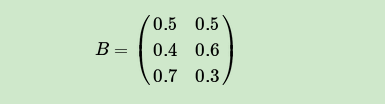



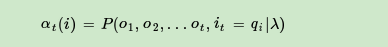

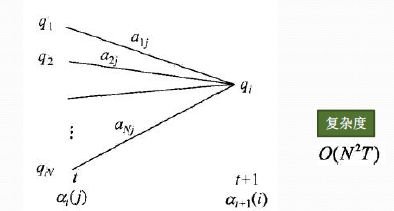


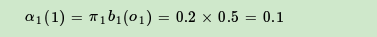
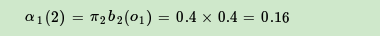
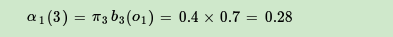
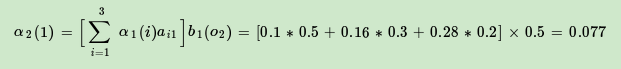

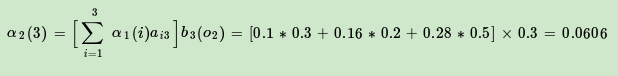


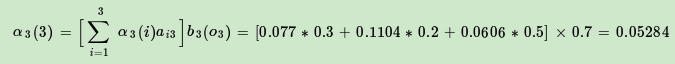


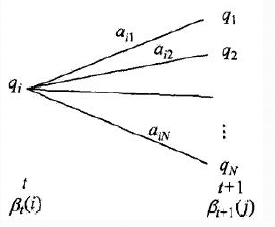
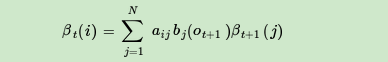









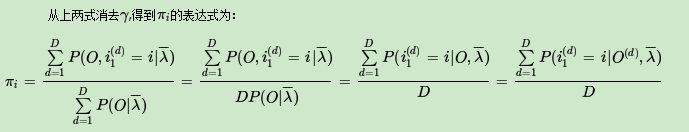
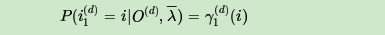
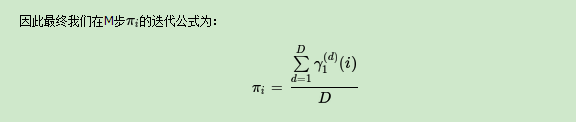
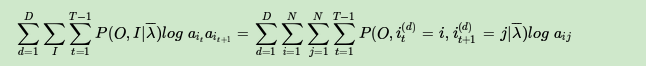

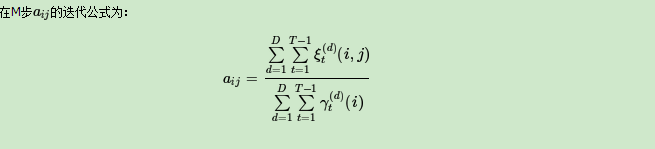
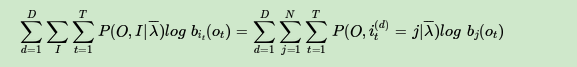

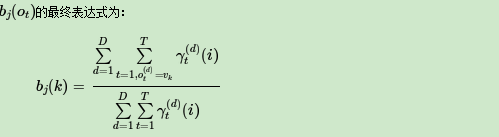



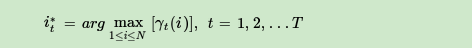



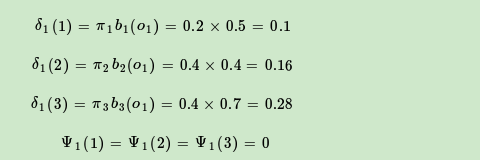


现在假设A和B在不同的房间里,我们看不到谁在掷骰子。取而代之的是,我们只知道后来吃了多少软糖。我们不知道颜色,仅是从罐子中取出的软糖的最终数量。我们怎么知道谁掷骰子?HMM。
在此示例中,状态是掷骰子的人,A或B。观察结果是该回合中吃了多少软糖。如果该值小于4,骰子的掷骰和通过骰子的条件就是转移概率。由于我们组成了这个示例,我们可以准确地计算出转移概率,即1/12。没有条件说转移概率必须相同,例如A掷骰子2时可以将骰子移交给他,例如,概率为1/36。
模拟
首先,我们将模拟该示例。B平均要吃12颗软糖,而A则需要4颗。
# 设置
simulate <- function(N, dice.val = 6, jbns, switch.val = 4){
#模拟变量
#可以只使用一个骰子样本
#不同的机制,例如只丢1个骰子,或任何其他概率分布
b<- sample(1:dice.val, N, replace = T) + sample(1:dice.val, N, replace = T)
a <- sample(1:dice.val, N, replace = T) + sample(1:dice.val, N, replace = T)
bob.jbns <- rpois(N, jbns[1])
alice.jbns <- rpois(N, jbns[2])
# 状态
draws <- data.frame(state = rep(NA, N), obs = rep(NA, N),
# 返回结果
return(cbind(roll = 1:N, draws))
# 模拟场景
draws <- simulate(N, jbns = c(12, 4), switch.val = 4)
# 观察结果
ggplot(draws, aes(x = roll, y = obs)) + geom_line()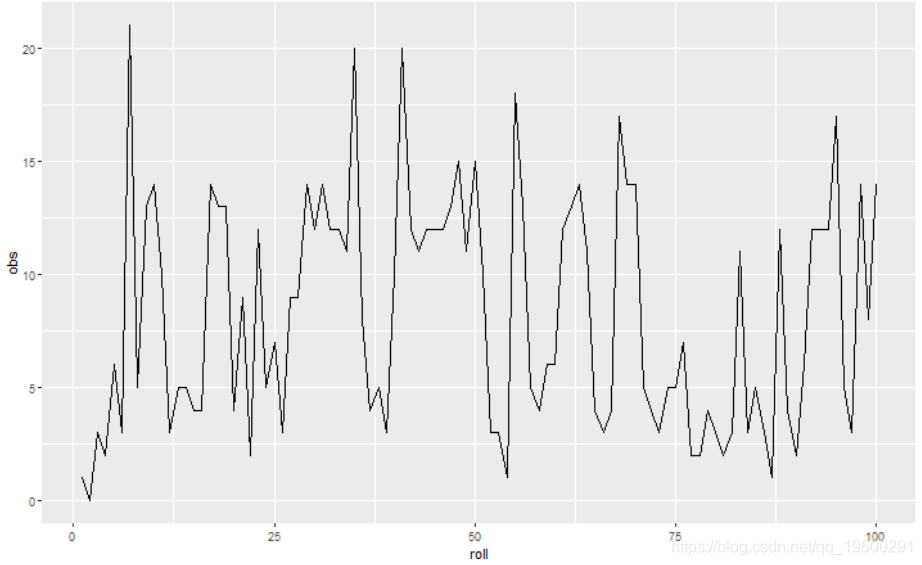
如您所见,仅检查一系列计数来确定谁掷骰子是困难的。我们将拟合HMM。由于我们正在处理计数数据,因此观察值是从泊松分布中得出的。
fit.hmm <- function(draws){
# HMM
mod <- fit(obs ~ 1, data = draws, nstates = 2, family = poisson()
# 通过估计后验来预测状态
est.states <- posterior(fit.mod)
head(est.states)
# 结果
hmm.post.df <- melt(est.states, measure.vars =
# 输出表格
print(table(draws[,c("state", "est.state.labels")]))## iteration 0 logLik: -346.2084
## iteration 5 logLik: -274.2033
## converged at iteration 7 with logLik: -274.2033
## est.state.labels
## state alice bob
## a 49 2
## b 3 46模型迅速收敛。使用后验概率,我们估计过程处于哪个状态,即谁拥有骰子,A或B。要具体回答该问题,我们需要更多地了解该过程。在这种情况下,我们知道A只喜欢黑软糖。否则,我们只能说该过程处于状态1或2。下图显示了HMM很好地拟合了数据并估计了隐藏状态。
# 绘图输出
g0 <- (ggplot(model.output$draws, aes(x = roll, y = obs)) + geom_line() +
theme(axis.ticks = element_blank(), axis.title.y = element_blank())) %>% ggplotGrob
g1 <- (ggplot(model.output$draws, aes(x = roll, y = state, fill = state, col = state)) +
g0$widths <- g1$widths
return(grid.arrange(g0, g1
plot.hmm.output(hmm1)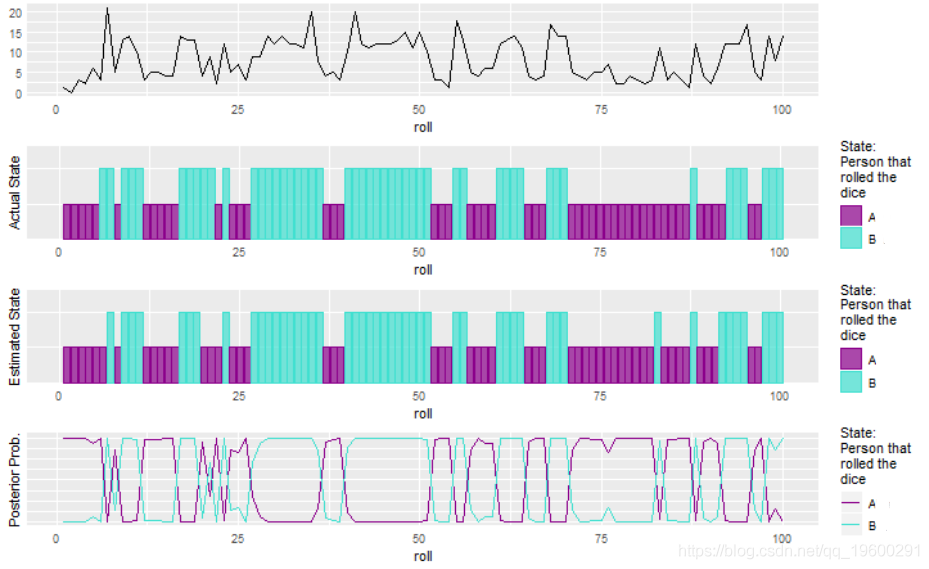
令人印象深刻的是,该模型拟合数据和滤除噪声以估计状态的良好程度。公平地说,可以通过忽略时间分量并使用EM算法来估计状态。但是,由于我们知道数据形成一个序列,因为观察下一次发生的概率取决于前一个即\(P(X_t | X_ {t-1})\),其中\(X_t \ )是软糖的数量。

考虑到我们构造的问题,这可能是一个相对简单的案例。如果转移概率大得多怎么办?
simulate(100, jbns = c(12, 4), switch.val = 7)
## iteration 0 logLik: -354.2707
## iteration 5 logLik: -282.4679
## iteration 10 logLik: -282.3879
## iteration 15 logLik: -282.3764
## iteration 20 logLik: -282.3748
## iteration 25 logLik: -282.3745
## converged at iteration 30 with logLik: -282.3745
## est.state.labels
## state alice bob
## alice 54 2
## bob 5 39plot(hmm2)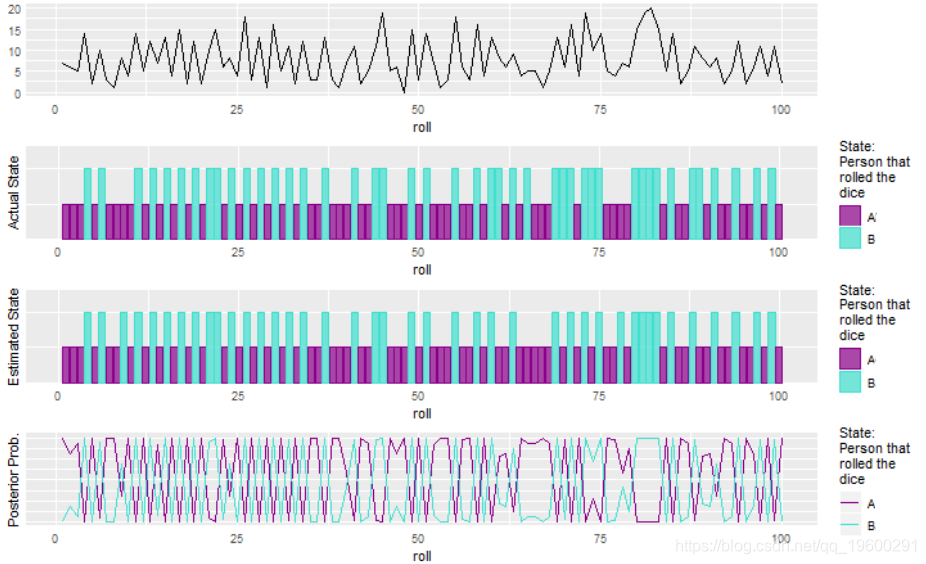 这有很多噪音数据,但是HMM仍然做得很好。性能的提高部分归因于我们对从罐中取出的软糖数量的选择。分布越明显,模型就越容易拾取转移。公平地讲,我们可以计算中位数,并将所有低于中位数的值都归为一个状态,而将所有高于中位数的值归为另一状态,您可以从结果中看到它们做得很好。这是因为转移概率非常高,并且预计我们会从每个状态观察到相似数量的观察结果。
这有很多噪音数据,但是HMM仍然做得很好。性能的提高部分归因于我们对从罐中取出的软糖数量的选择。分布越明显,模型就越容易拾取转移。公平地讲,我们可以计算中位数,并将所有低于中位数的值都归为一个状态,而将所有高于中位数的值归为另一状态,您可以从结果中看到它们做得很好。这是因为转移概率非常高,并且预计我们会从每个状态观察到相似数量的观察结果。
当转移概率不同时,我们会看到HMM表现更好。
如果观察结果来自相同的分布,即A和B吃了相同数量的软糖怎么办?
hmm3 <- fit.hmm(draws)
plot(hmm3)随时关注您喜欢的主题
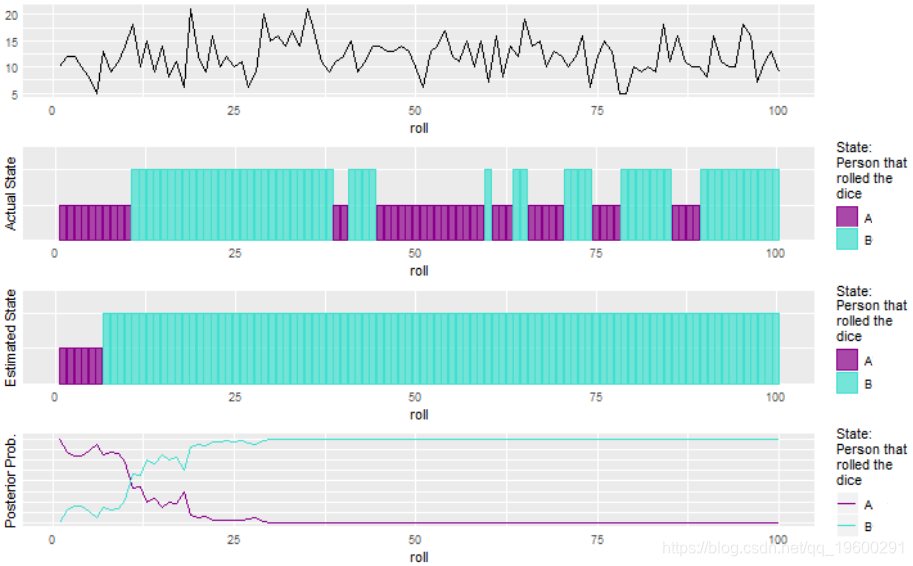
不太好,但这是可以预期的。如果从中得出观察结果的分布之间没有差异,则可能也只有1个状态。
实际如何估算状态?
首先,状态数量及其分布方式本质上是未知的。利用对系统建模的知识,用户可以选择合理数量的状态。在我们的示例中,我们知道有两种状态使事情变得容易。可能知道确切的状态数,但这并不常见。再次通过系统知识来假设观察结果通常是合理的,这通常是合理的。
从这里开始,使用 Baum-Welch算法 来估计参数,这是EM算法的一种变体,它利用了观测序列和Markov属性。
除了估计状态的参数外,还需要估计转移概率。Baum-Welch算法首先对数据进行正向传递,然后进行反向传递。然后更新状态转移概率。然后重复此过程,直到收敛为止。
在现实世界
在现实世界中,HMM通常用于
- 股票市场预测,无论市场处于牛市还是熊市
- 估计NLP中的词性
- 生物测序
- 序列分类
仅举几例。只要有观察序列,就可以使用HMM,这对于离散情况也适用。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据
Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据 Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据
Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据 Python梯度提升树、SHAP与递归特征消除构建血栓风险分级预测模型|附代码数据
Python梯度提升树、SHAP与递归特征消除构建血栓风险分级预测模型|附代码数据

