本文使用R语言进行了贝叶斯模型预测电影评分,并对数据进行了可视化和分析。
文章创建了五个新的特征变量,包括电影类型、导演获奖情况、电影票房、评论数量和影评人数量等,并分析了这些变量对电影评分的影响。
通过模型预测和系数解释,发现imdb_rating具有最高的后验概率,且截距和运行时对观众评分有积极影响,而评论数量和影评人数量对观众评分的影响较小。
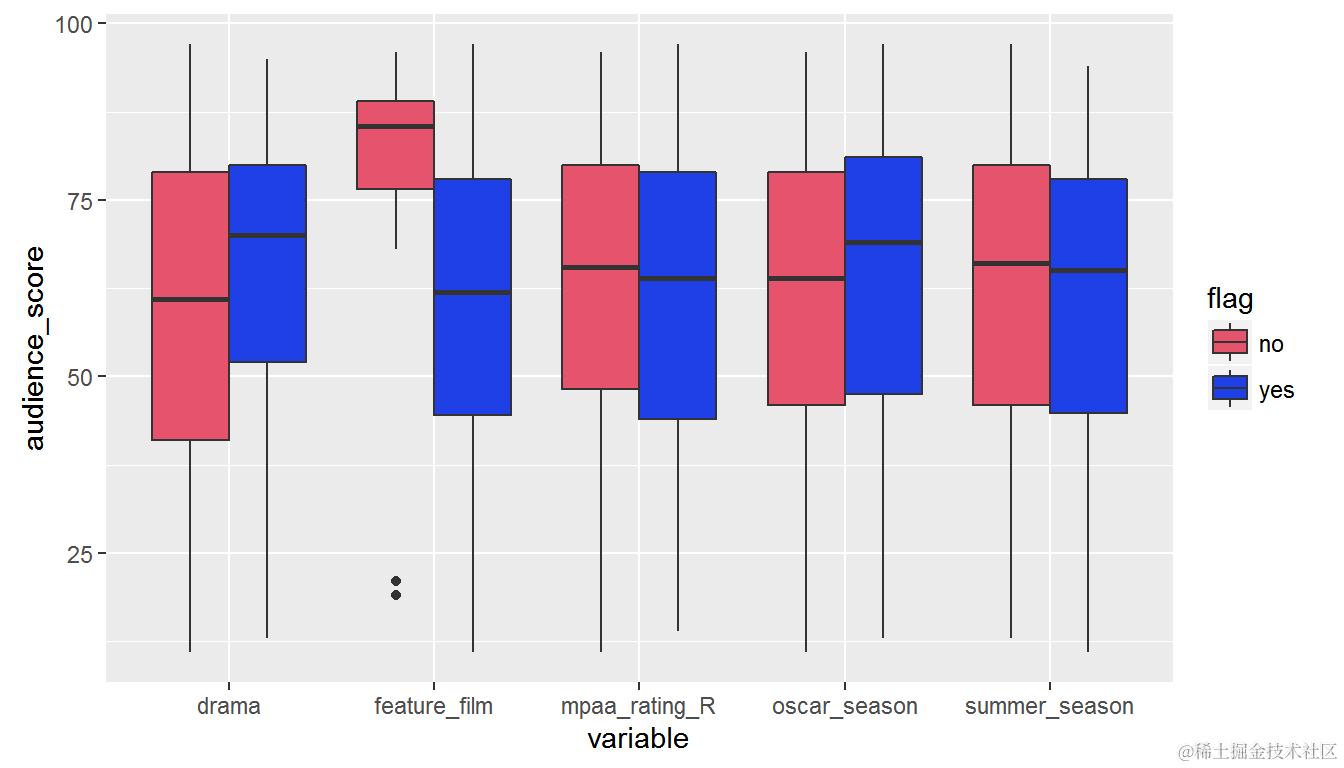
文章还提供了对数据的探索性分析,并得出了某些见解,如舞蹈电影更受欢迎,较长的电影通常会让观众感到无聊等。
可下载资源
movies_ed <- gath7)
然后我们创建一个箱线图。
ggplot(moviegag)) + geom_bxplot()
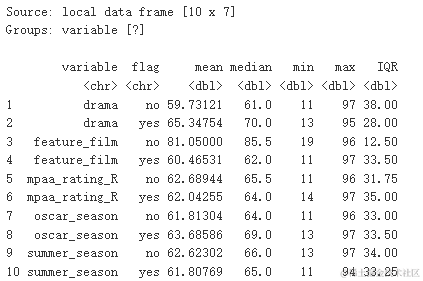
进行数据摘要统计。
summarise(mean=mean(audience_scoence_score))
随时关注您喜欢的主题
model <- bam(datdienc_score ~ feature_film + drama + runtime +
......
+ best_dir_win + top200_box, prior = 'BIC', mo
让我们为每个变量输出边际后验概率。

我们可以看到imdb_rating具有1.00的后验概率,这在电影工业的背景下听起来很合理。 同时critics_score和runtime也有很高的概率。
然后让我们看看模型的总结。

我们看到,最好的模型包括截距,运行时的imdb_rating和critics_score是与上述发现一致。
我们拟合最好的模型并解释它的系数。

我们看到imdb_rating具有14.95的系数,意味着对于imdb_rating的每增加1个额外的分数,我们期望audience_score会增加14.95。 由于IMDB得分以0到10的衡量量表给出,并且audience_score以0到100的衡量量表给出,并且考虑截距= -32.90,这个结论是有道理的。
类似地,对于critics_score上的每增加1个额外得分,我们期望audience_score会增加0.075。 显然,这不像imdb_rating那样有影响力。
最后,对于电影运行时间每增加一分钟,我们预计在audience_score中将减少0.058。 这意味着一般来说,人们不喜欢冗长的电影。
预测
现在使用我们的最终模型来预测X-MEN的观众分数 。
predict(finew_movie)
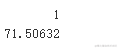
该模型预测观众分数为71.5,接近真实值71。
结论
事实上,imdb_rating具有最高的后验概率,并且我们五个新创建的变量中有两个不包括在最佳模型中,这是需要改进的。 因为IMDB评级与观众分数有些同步,因此事先来预测变量是欠妥的,critics_score也是同样道理。
然而,我们确实有一些见解可能是有用的。 舞蹈电影更受欢迎; 特征/非特征电影在观众分数方面具有突出的优势; 较长的电影通常会让观众感到无聊等。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践
视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践 Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证
Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据


