是什么让一个电影受欢迎? 也许是影片的总收入(影院条目和DVD sellings)。
我们选择的变量将是票房(gross) 或观众评分(movie_facebook_likes)。众所周知,关于IMDB和番茄的好评与高收益的电影有关。
我们的分析旨在回答以下研究问题:“我们能在仅知道它的类型,流派(流派变量),MPAA评级(MPAA_RATING变量),发布一个月(thtr_rel_month变量),发布日(thtr_rel_day变量),IMDB的票数(imdb_num_votes变量),评论家得分(critics_score变量)和最佳影片提名(best_pic_nom变量)等变量能否预测一部电影收入?
这篇文章帮助客户通过一些变量来预测电影的收入。文章提供了一个数据集,该数据集包括了1970年到2014年之间发布的美国电影的信息,使用随机抽样设计方法抽取。
文章选择使用票房(gross)或观众评分(movie_facebook_likes)作为响应变量来研究,最终选择观众评分作为响应变量。
在探索数据分析部分,文章使用了直方图和盒状图的方法来了解分类变量和响应变量之间的关联性,以及数值变量和响应变量之间的交互作用。文章还使用了随机森林算法建立模型,并通过调整参数来寻找最优模型。最终,文章发现IMDB票数、评论家得分和最佳影片提名等变量对于预测电影收入非常重要。
数据
抽样设计
该数据集的目标人群是从1970年和2014年,著名的互联网数据库IMDB随机抽取的电影数据 。
推理范围
“电影”的数据集,应考虑使用一个随机抽样设计,选择美国电影有代表性的样本观察性的回顾性研究,我们的结果应该推广到1970年和2014年间发布的所有美国电影。
data=read.csv("movie_metadata.csv")可下载资源
探索数据分析
响应变量的分布 首先,我们将检查两个潜在的响应变量之间有高度相关性:票房和观众的分数。
cor(movies$gross, movies$movie_facebook_likes)
由于这两个变量之间的相关性相当高。在我们的研究中,我们将选择movie_facebook_likes作为响应变量。
让我们先来绘制响应变量的直方图。
ot(movies2, aes(x = movie_facebook_likes)) + geom_histogram() + xlab("Audience Score") + ylab("Coun随时关注您喜欢的主题
分布分数变量左侧偏斜,可能是单向或双峰。
summary(movies2$movie_facebook_likes)

盒状图
现在,开始探索性数据分析,首先,我们将使用箱图来可视化我们感兴趣的分类变量与响应变量。
likes)) + geom_boxplot() + xlab("title_type") + ylab("movie_f
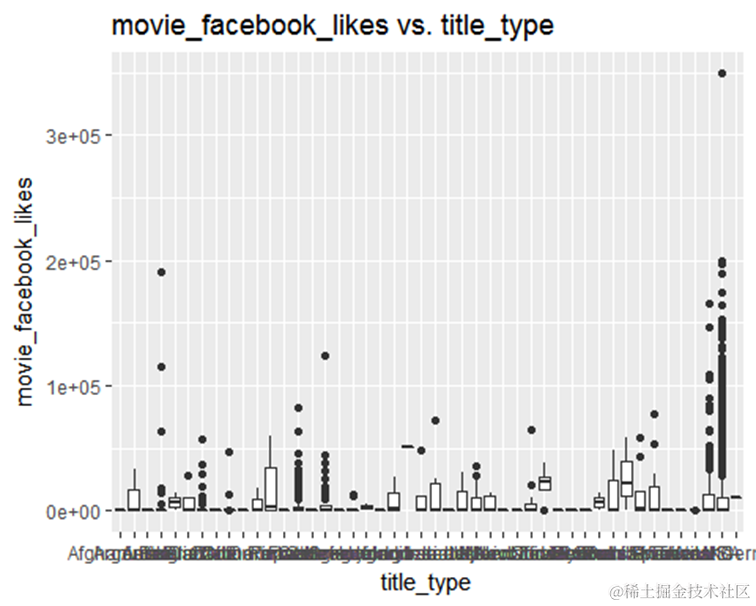
country和观众得分关联。
ikes)) + geom_boxplot() + xlab("content_

变量MPAA评级和观众得分关联不是那么明显。 content_rating评级可能不适合预测。
响应变量与数值变量的散点图
现在,我们将用散点图可视化我们感兴趣的数值变量如何与我们的响应变量相互作用。
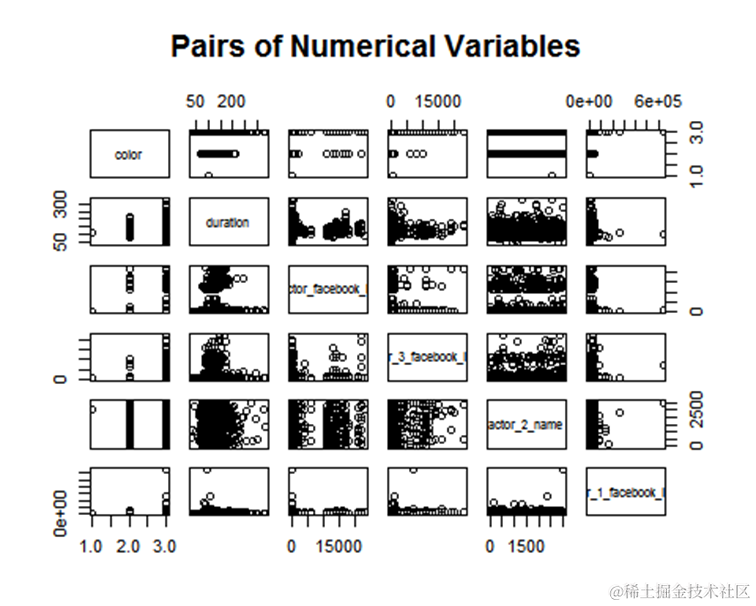
正如我们可以看到上面,预测变量之间的相关性不是很高,因为它有助于避免多重共线性。
随机森林建模
随机森林是一种常用的机器学习算法,用于建立预测模型。它基于多个决策树的集成,通过对每个决策树的预测结果进行综合,得出最终的预测结果。下面将介绍随机森林建模过程以及参数调优的方法。
在随机森林建模之前,我们需要先对数据进行预处理和特征选择。在这个示例中,我们以”gross-budget”作为因变量,其余列作为自变量进行建模。下面是建模代码:
randomForest( gross-budget~.-director_nam
上述代码中,”gross-budget~.-director_name”表示以”director_name”列为排除变量,其他列作为自变量进行建模。接下来,我们通过调用”randomForest”函数进行建模,其中”data”是输入的数据。
随机森林建模过程中,我们可以通过参数调优来提升模型性能。
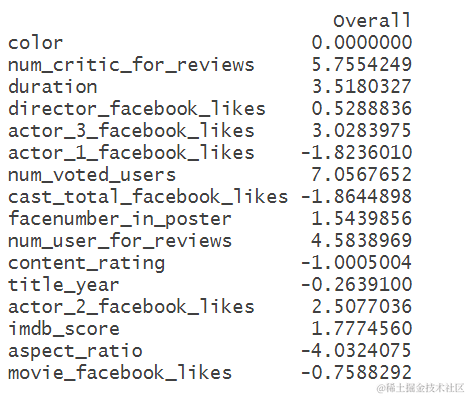
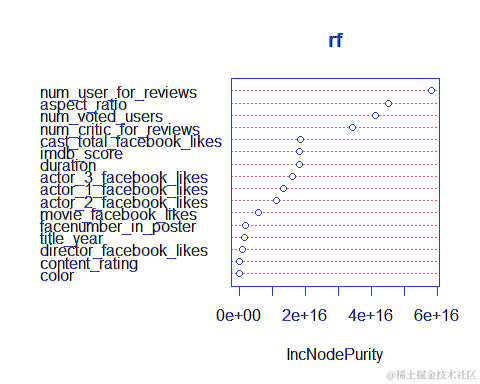
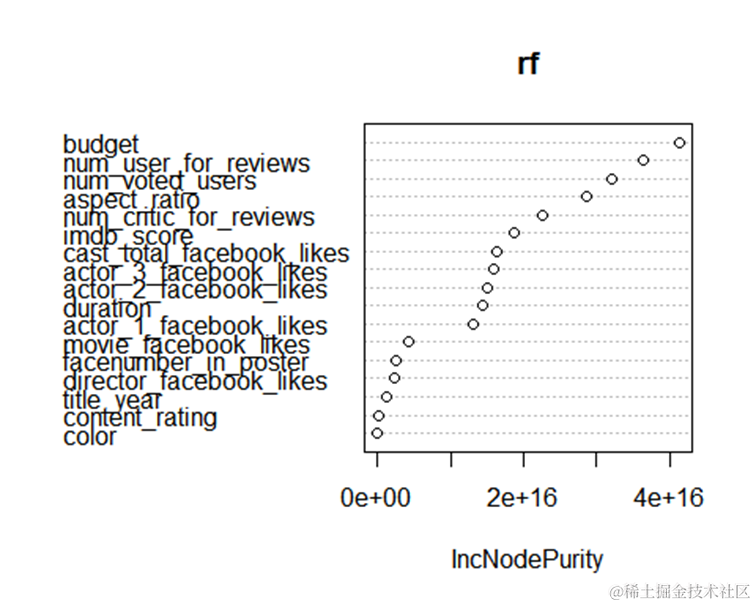
这个结果是随机森林模型对于每个变量的重要性排序。可以看到,num_voted_users(投票用户数)是最重要的变量,其次是num_critic_for_reviews(评论家评价数量)和num_user_for_reviews(普通用户评价数量),这些变量可能与电影的知名度和受欢迎程度有关。其他变量的重要性较低,例如color(颜色)、director_facebook_likes(导演的Facebook赞数)和title_year(发行年份)等。aspect_ratio(宽高比)的重要性为负数,说明这个变量对于模型预测结果的贡献是负面的。
需要注意的是,这里给出的变量重要性仅仅是针对随机森林模型而言,并不能保证在其他的机器学习算法或统计学方法中也是同样的重要性排序。此外,变量重要性也不一定意味着因果关系,只是表明这些变量对于模型预测结果的贡献比较大。
参数调优
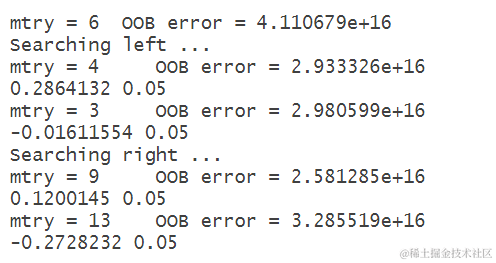
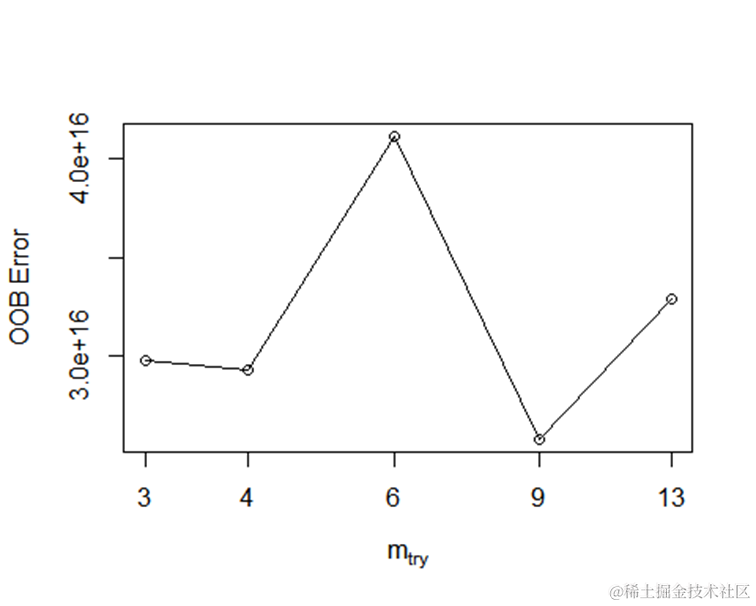
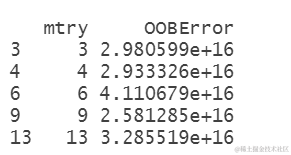
参数调优是指通过尝试不同的参数组合,找到最优的参数配置,以提高模型的准确性。在随机森林建模中,可以调整的参数包括ntree(决策树的数量)、mtry(每个决策树的特征选择数量)和nodesize(每个叶节点的最小观测数)等。
下面是参数调优的代码示例:
tueRF(data[1:10,-which(colnaata) %in% c("director_name","actor_2_name","genres","actor_
上述代码中,我们使用”tuneRF”函数来进行参数调优,其中”data[1:10,-which(colnames(data)) %in% c(“director_name”,“actor_2_name”,“genres”,“actor”)]“表示选择除了”director_name”、“actor_2_name”、”genres”和”actor”列之外的其他列作为自变量。ntreeTry表示尝试的决策树数量,stepFactor表示步进因子。
通过参数调优,我们可以得到最优的参数配置。
用最优参数建模
在得到最优的参数配置后,我们可以使用这些参数进行建模。下面是使用最优参数建模的代码示例:
randomForest( gross-budget, ntree=1000, mtry=6, nodesize=5,
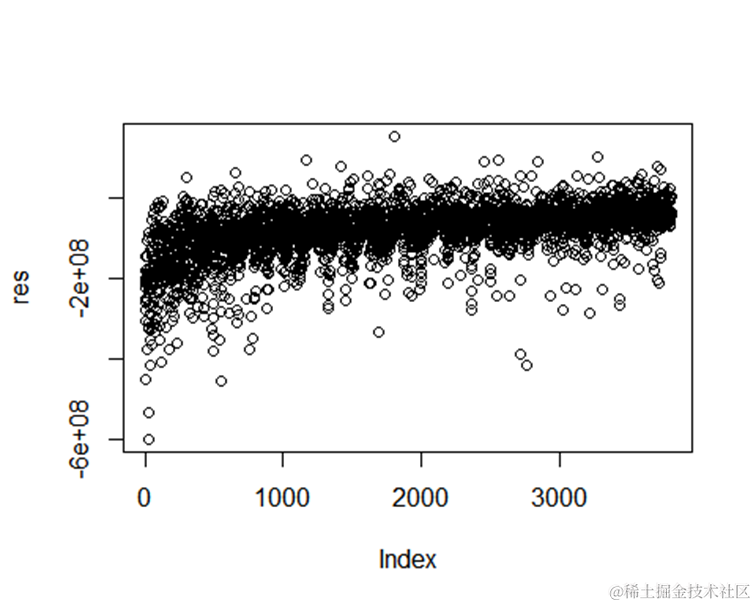
上述代码中,我们使用”randomForest”函数进行建模,其中”ntree=1000″表示决策树的数量,”mtry=6″表示每个决策树的特征选择数量,”nodesize=5″表示每个叶节点的最小观测数。
通过建立模型并获得结果,我们可以评估模型的性能和预测效果。
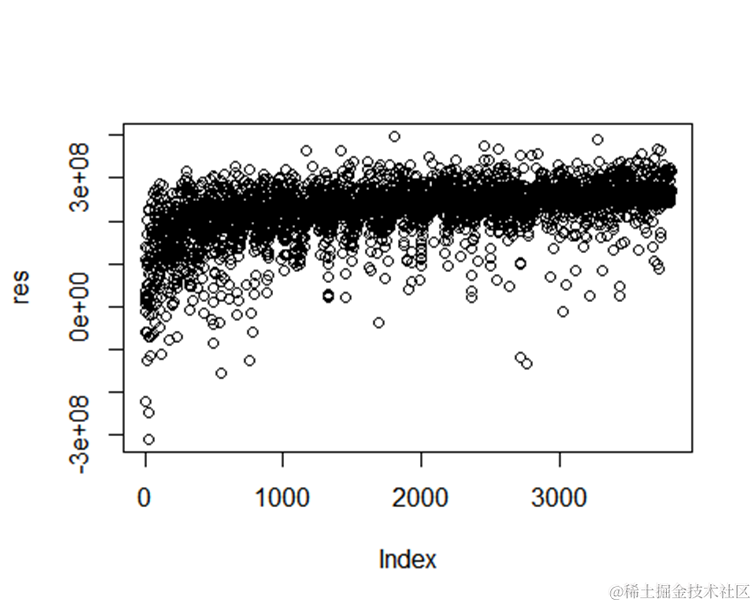
从结果来看,残差是独立的,误差在可接受范围内。
收入作为因变量
f <- randomForest( gross ~.-direc
变量重要性
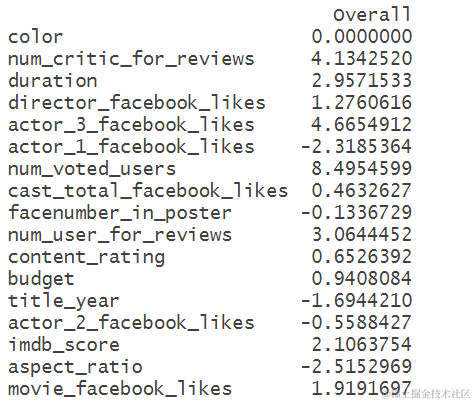
ImpPlot(rf,t
发现最优参数
stmtry <- tuneRF(data[1:10,-whi
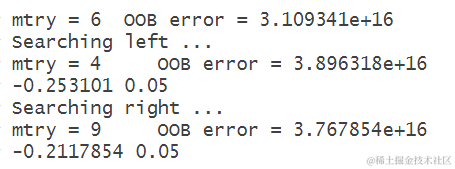
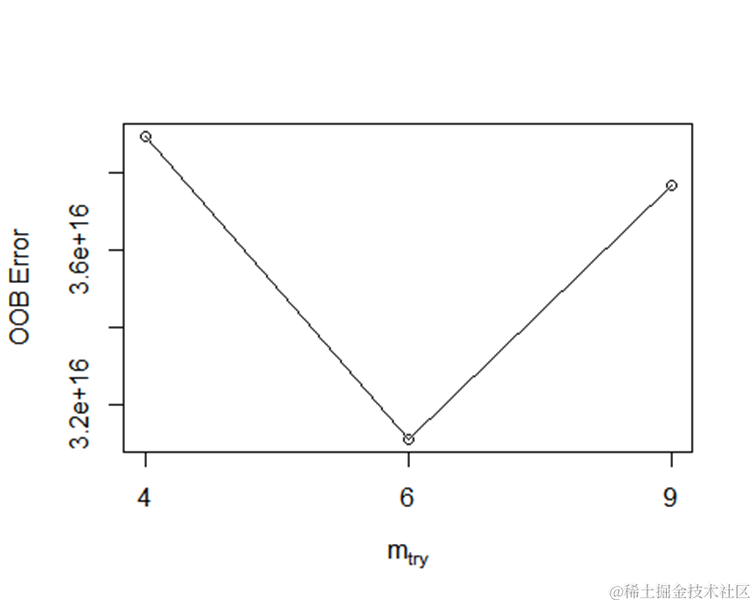
最优参数建模
orest( groslangu1000, mtry=6, nodesize=5, importance=T)
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别
Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别 Python银行客户数据流失预测SMOTE平衡数据实现神经网络、SVM、决策树、随机森林与超参数调优|附代码数据
Python银行客户数据流失预测SMOTE平衡数据实现神经网络、SVM、决策树、随机森林与超参数调优|附代码数据

