
有许多分层数据的例子。例如,地理数据通常按层次分组,可能是全球数据,然后按国家和地区分组 。一个生物学的例子是按物种分组的动物或植物的属性,或者属于一个级别的属性,然后是家族。一个商业例子可能是业务部门和细分的员工满意度。
每个学科都有许多例子,其中观察以某种形式的层次结构进行分组。
可下载资源
在这里,我想解释使用一个简单的例子, 如何使用R来构建分层线性模型。我在整个三组中使用简单的一维数据集。在每个组内,自变量x和因变量y之间存在强正相关关系。
1. nlme包
1.1 随机截距模型
两水平的随机截距模型示例代码
lme( fixed = y~x, random = ~1|A, data)
三水平的随机截距模型示例代码(A/B表示嵌套结构,B嵌套在A里面,比如班级嵌套在学校里面)
lme( fixed = y~x, random = ~1|A/B, data)
1.2 随机斜率模型
两水平的示例代码
lme(fixed = y~x1 + x2,
random = ~x1 + x2|A, data)
三水平的示例代码
# 指定A层截距随机,B层x1对y的斜率随机,可以类推。
lme(fixed = y~x1 + x2, random =
list(A = ~1, B = ~x1), data)
2. lme4包
2.1 随机截距模型
两水平的随机截距模型示例代码
lmer(y~x +(1|A), data
三水平的随机截距模型示例代码(A/B表示嵌套结构,B嵌套在A里面,比如班级嵌套在学校里面)
lmer(y~x + (1|A/B), data)
2.2 随机斜率模型
两水平的示例代码
lmer(y~x + (x|A), data)
三水平的示例代码
lmer(y~x1 + x2 + (x1|A/B), data)
具体问题,理清楚嵌套结构和构建好层次模型就好了。
geom_smooth(aes(x=x,y=y,group=group),method=lm,se=FALSE) +
theme_bw() + theme(legend.position="null")
g + geom_smooth(aes(x=x,y=y),method=lm,se=TRUE)这些组有不同的颜色 。 在本文的其余部分,我将展示如何使用层次模型来模拟这种情况,该模型确实考虑了组信息。

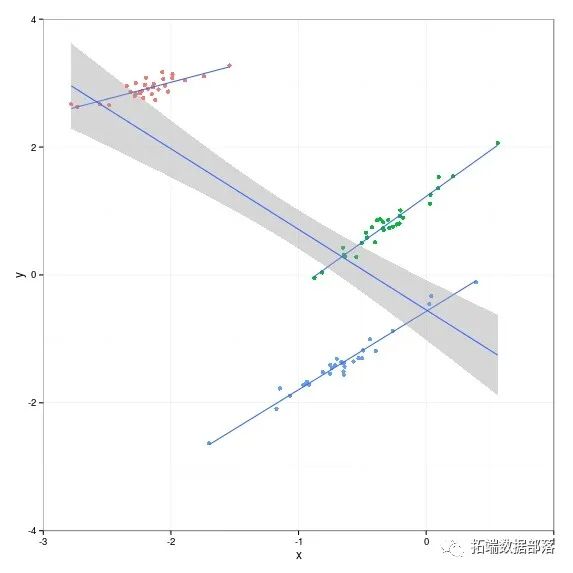
建议的分层线性模型的一个包是arm,它具有与lm()函数非常相似的函数lmer()。
lmer.both <- lmer(y~1+x+(1+x|group),data=df)
summary(lmer.both) # 固定效应是顶层截距和斜率
# (Intercept) x
# 1.978652 1.144952
# 截距组随机效应
#
> ranef(lmer.alpha)
# $group
# (Intercept)
# 1 3.4386106
# 2 -0.8360106
# 3 -2.6026000
# > group.alpha
# [1] 4.2883814 1.2134493 -0.5410049
# > ranef(lmer.alpha)$group[,1] + fixef(lmer.alpha)[1]
# [1] 5.4172624 1.1426413 -0.6239482
group.alpha
# 固定效果是顶层截距
# (Intercept)
# 5.788223
# 对截距和斜率进行分组随机影响
# (Intercept) x
# 1 -1.740225 0.518047
# 2 -4.564296 1.415710
# 3 -6.354477 1.231584
# > group.alpha
# [1] 4.2883814 1.2134493 -0.5410049
# > ranef(lmer.beta)$group +
# [1] 4.0479981 1.2239268 -0.5662542
fixef(lmer.beta)
ranef(lmer.beta)
group.beta
# > fixef(lmer.both)
# (Intercept) x
# 1.578741 1.059370
# > ranef(lmer.both)
# $group
# (Intercept) x
# 1 2.500014 -0.5272426
# 2 -0.355365 0.3545068
# 3 -2.144649 0.1727358
fixef(lmer.both)
ranef(lmer.both)
#我们简单地运行3个回归,每组一个
coef(lm(y~x,data=df[group==1,]))
coef(lm(y~x,data=df[group==2,]))
coef(lm(y~x,data=df[group==3,]))
# (Intercept) x
# 4.0653645 0.5259707
# 1.227969 1.428500
# -0.570280 1.225905
# true values for group.alpha are
# 4.2883814 1.2134493 -0.5410049
(ranef(lmer.alpha)$group[,1]) + fixef(lmer.alpha)[1]
(ranef(lmer.beta)$group[,1]) + fixef(lmer.beta)[1]
# Alpha随机效应图
fit.lines <- data.frame(cbind(intercept=(ranef(lmer.alpha)$gro
g.alpha
# beta随机效应图
fit.lin
iplot(g.alpha 结果显示有三个图,第一个是截距(alpha)依赖于组,第二个是斜率(β)依赖于组,第三个是截距和斜率依赖组。
你可能在想为什么不是做三个单独的线性回归,因为第三个例子产生的系数非常接近于此。原因是基于这样的假设:alphas和beta是从顶层分布中提取的,因此是相关的。这意味着我们可以在组之间汇集信息,如果我们为其中一个组提供的数据非常少 。
术语回归系数是“固定效应”,组别称为“随机效应”。
fit.lines.both$group <- factor(rep(1:3,each=
# 现在执行3个单独的线性回归(每组一个)
lm.mcmc.1 <- MCMCglm(y~1+x,dat
fit.lines.mcmc <- data.frame(rbind + ta=fit.lines.mcm 结果如下所示。
每组只有一个单独的线性回归。对于蓝色和红色组,线条在大多数情况下非常适合数据,但对于只有三个数据点的绿色组,线条遍布整个地方,因为没有任何先验信息,估计数据的斜率和偏移量非常不确定。右侧的图表显示 因为该模型假设所有三组的斜率和偏移都是从一个分布中得出的,所以可以合理地假设斜率是正的。我们知道这适用于这个例子,因为我们设计了数据生成过程。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码
Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析

