增量法使我们具有(渐近)正态性,因此一旦有了标准偏差,便可以得到置信区间。
考虑简单的泊松回归。给定的样本
,其中
,目标是导出用于一个95%的置信区间
给出
,其中
是预测。
可下载资源
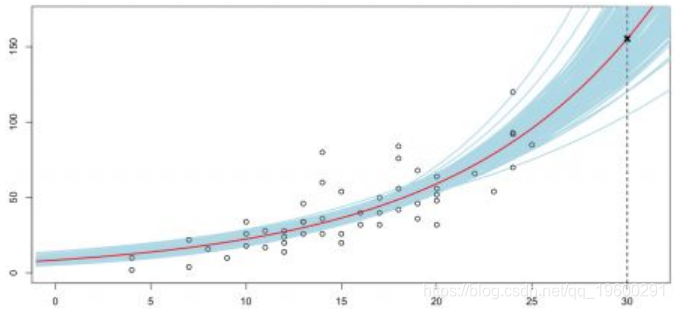
因此,我们要导出预测的置信区间,而不是观测值,即下图的点
> r=glm(dist~speed,data=cars,family=poisson)
> P=predict(r,type="response",
+ newdata=data.frame(speed=seq(-1,35,by=.2)))
> plot(cars,xlim=c(0,31),ylim=c(0,170))
> abline(v=30,lty=2)
> lines(seq(-1,35,by=.2),P,lwd=2,col="red")
> P0=predict(r,type="response",se.fit=TRUE,
+ newdata=data.frame(speed=30))
> points(30,P1$fit,pch=4,lwd=3)即

最大似然估计
![]()
视频
什么是Bootstrap自抽样及R语言Bootstrap线性回归预测置信区间
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
,Fisher信息来自标准最大似然理论。
![]()
这些值的计算基于以下计算
在对数泊松回归的情况下,
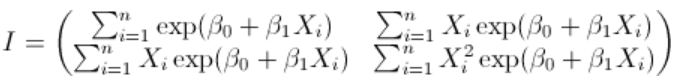
让我们回到最初的问题。
线性组合的置信区间
获得置信区间的第一个想法是获得置信区间
![]()
因此,方差矩阵的近似将基于通过插入参数的估计量而获得。
然后,由于作为渐近多元分布,参数的任何线性组合也将是正态的,即具有正态分布。所有这些数量都可以轻松计算。首先,我们可以得到估计量的方差
因此,如果我们与回归的输出进行比较,
> summary(reg)$cov.unscaled
(Intercept) speed
(Intercept) 0.0066870446 -3.474479e-04
speed -0.0003474479 1.940302e-05
> V
[,1] [,2]
[1,] 0.0066871228 -3.474515e-04
[2,] -0.0003474515 1.940318e-05根据这些值,很容易得出线性组合的标准偏差,
一旦我们有了标准偏差和正态性,就得出了置信区间,然后,取边界的指数,就得到了置信区间
> segments(30,exp(P2$fit-1.96*P2$se.fit),
+ 30,exp(P2$fit+1.96*P2$se.fit),col="blue",lwd=3)基于该技术,置信区间不再以预测为中心。

增量法
实际上,使用表达式作为置信区间不会喜欢非中心区间。因此,一种替代方法是使用增量方法。我们可以使用一个程序包来计算该方法,而不是在理论上再次写一些东西,
> P1
$fit
1
155.4048
$se.fit
1
8.931232
$residual.scale
[1] 1增量法使我们具有(渐近)正态性,因此一旦有了标准偏差,便可以得到置信区间。

通过两种不同的方法获得的数量在这里非常接近
> exp(P2$fit-1.96*P2$se.fit)
1
138.8495
> P1$fit-1.96*P1$se.fit
1
137.8996
> exp(P2$fit+1.96*P2$se.fit)
1
173.9341
> P1$fit+1.96*P1$se.fit
1
172.9101bootstrap技术
第三种方法是使用bootstrap技术基于渐近正态性(仅50个观测值)得出这些结果。我们的想法是从数据集中取样,并对这些新样本进行log-Poisson回归,并重复很多次数,
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现
【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现 数据分享|广义线性模型beta二项分布的淋巴结疾病风险预测可视化R语言实现
数据分享|广义线性模型beta二项分布的淋巴结疾病风险预测可视化R语言实现


