我们将使用葡萄酒数据集进行主成分分析。
数据包含177个样本和13个变量的数据框;vintages包含类标签。这些数据是对生长在意大利同一地区但来自三个不同栽培品种的葡萄酒进行化学分析的结果:内比奥罗、巴贝拉和格里格诺葡萄。来自内比奥罗葡萄的葡萄酒被称为巴罗洛。
这些数据包含在三种类型的葡萄酒中各自发现的几种成分的数量。这份数据集为我们提供了一个宝贵的机会,能够深入了解不同葡萄品种在化学成分上的差异,以及这些差异如何影响葡萄酒的品质和风味。
通过对这些变量的分析,我们可以探索哪些化学指标对于区分不同品种的葡萄酒最为关键,进而为葡萄酒的生产和品鉴提供科学依据。

视频
主成分分析PCA降维方法和R语言分析葡萄酒可视化实例
# 看一下数据
head(no)输出

转换和标准化数据
对数转换和标准化,将所有变量设置在同一尺度上。
# 对数转换
no_log <- log(no)
# 标准化
log\_scale <- scale(no\_log)
head(log_scale)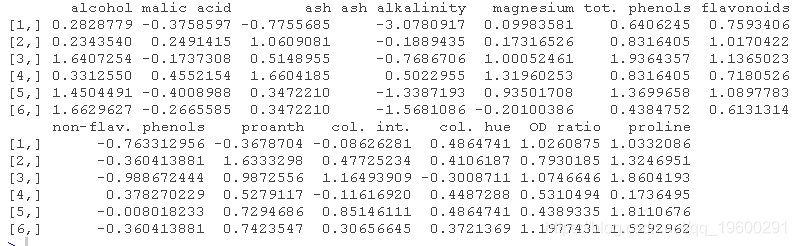
主成分分析(PCA)
使用奇异值分解算法进行主成分分析
prcomp(log_scale, center=FALSE)
summary(PCA)
基本图形(默认设置)
带有基础图形的主成分得分和载荷图
plot(scores\[,1:2\], # x和y数据
pch=21, # 点形状
cex=1.5, # 点的大小
legend("topright", # legend的位置
legend=levels(vint), # 图例显示
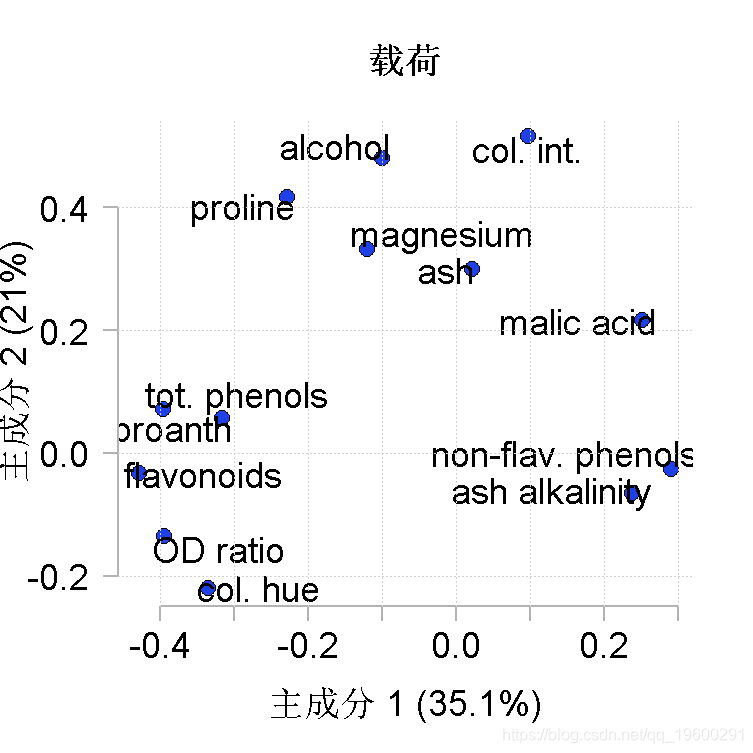
plot(loadings\[,1:2\], # x和y数据
pch=21, # 点的形状
text(loadings\[,1:2\], # 设置标签的位置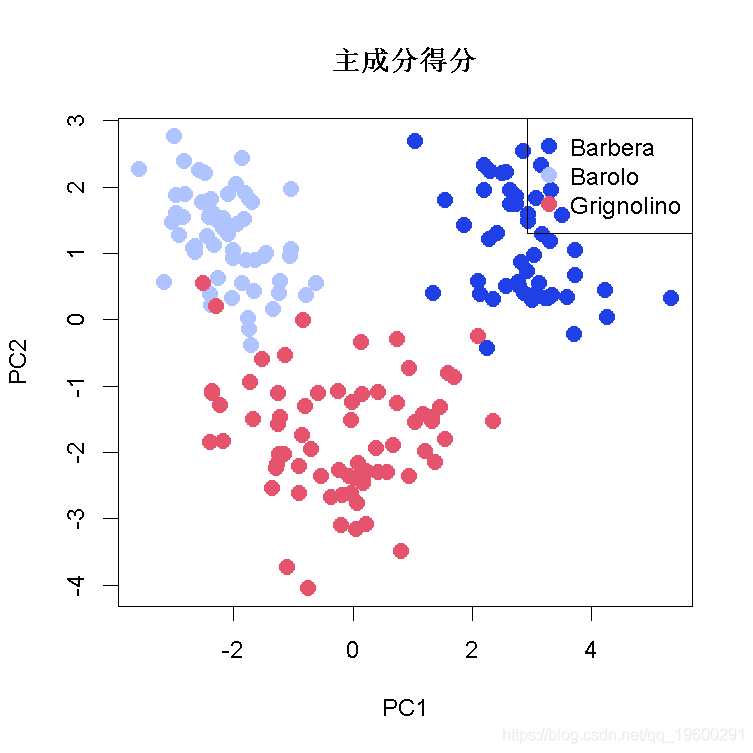
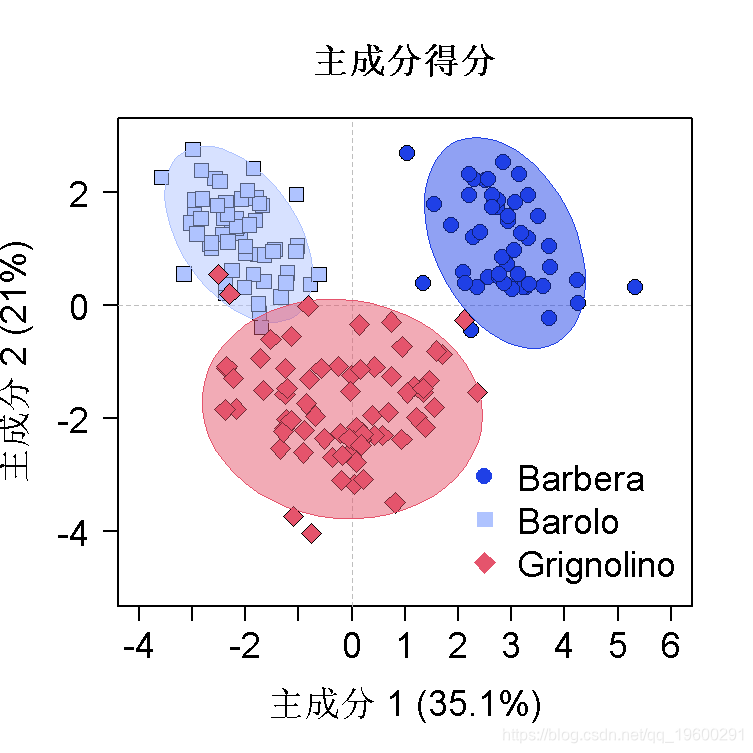
此外,我们还可以在分数图中的组别上添加95%的置信度椭圆。

置信度椭圆图函数
## 椭圆曲线图
elev=0.95, # 椭圆概率水平
pcol=NULL, # 手工添加颜色,必须满足长度的因素
cexsize=1, # 点大小
ppch=21, # 点类型,必须满足因素的长度
legcexsize=2, # 图例字体大小
legptsize=2, # 图例点尺寸
## 设定因子水平
if(is.factor(factr) {
f <- factr
} else {
f <- factor(factr, levels=unique(as.character(factr)))
}
intfactr <- as.integer(f) # 设置与因子水平相匹配的整数向量
## 获取椭圆的数据
edf <- data.frame(LV1 = x, LV2=y, factr = f) # 用数据和因子创建数据框
ellipses <- dlply(edf, .(factr), function(x) {
Ellipse(LV1, LV2, levels=elev, robust=TRUE, draw=FALSE) #从dataEllipse()函数中按因子水平获取置信度椭圆点
})
## 获取X和Y数据的范围
xrange <- plotat(range(c(as.vector(sapply(ellipses, function(x) x\[,1\])), min(x), max(x))))
## 为图块设置颜色
if(is.null(pcol) != TRUE) { # 如果颜色是由用户提供的
pgcol <- paste(pcol, "7e", sep="") # 增加不透明度
# 绘图图形
plot(x,y, type="n", xlab="", ylab="", main=""
abline(h=0, v=0, col="gray", lty=2) #在0添加线条
legpch <- c() # 收集图例数据的矢量
legcol <- c() # 收集图例col数据的向量
## 添加点、椭圆,并确定图例的颜色
## 图例
legend(x=legpos, legend=levels(f), pch=legpch,
## 使用prcomp()函数的PCA输出的轴图示
pcavar <- round((sdev^2)/sum((sdev^2))基础图形
绘制主成分得分图,使用基本默认值绘制载荷图
plot(scores\[,1\], # X轴的数据
scores\[,2\], # Y轴的数据
vint, # 有类的因素
pcol=c(), # 用于绘图的颜色(必须与因素的数量相匹配)
pbgcol=FALSE, #点的边框是黑色的?
cexsize=1.5, # 点的大小
ppch=c(21:23), # 点的形状(必须与因子的数量相匹配)
legpos="bottom right", # 图例的位置
legcexsize=1.5, # 图例文字大小
legptsize=1.5, # 图例点的大小
axissize=1.5, # 设置轴的文字大小
linewidth=1.5 # 设置轴线尺寸
)
title(xlab=explain\[\["PC1"\]\], # PC1上解释的方差百分比
ylab=explain\[\["PC2"\]\], # PC2解释的方差百分比
main="Scores", # 标题
cex.lab=1.5, # 标签文字的大小
cex.main=1.5 # 标题文字的大小
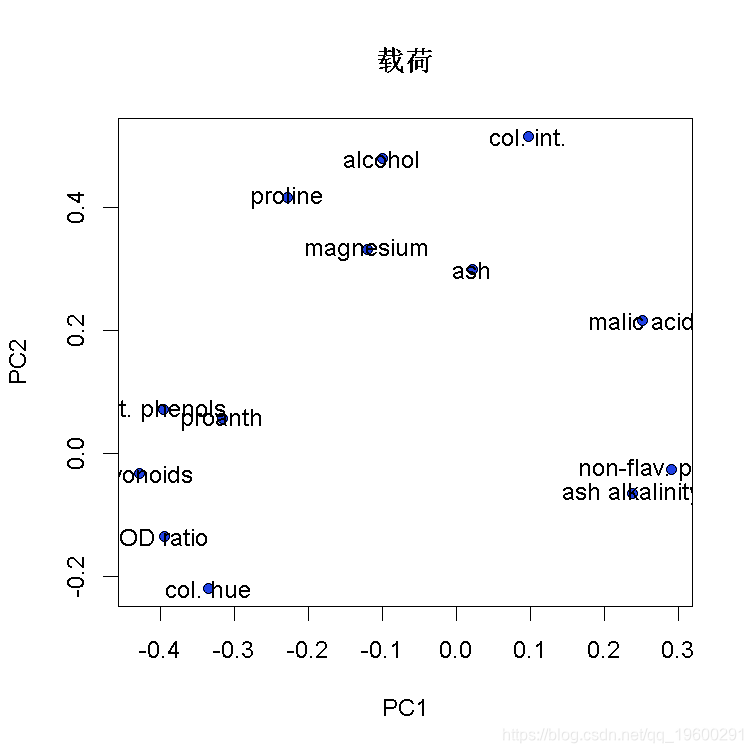
plot(loadings\[,1:2\], # x和y数据
pch=21, # 点的形状
cex=1.5, # 点的大小
# type="n", # 不绘制点数
axes=FALSE, # 不打印坐标轴
xlab="", # 删除x标签
ylab="" # 删除y标签
)
pointLabel(loadings\[,1:2\], #设置标签的位置
labels=rownames(PCAloadings), # 输出标签
cex=1.5 # 设置标签的大小
) # pointLabel将尝试将文本放在点的周围
axis(1, # 显示x轴
cex.axis=1.5, # 设置文本的大小
lwd=1.5 # 设置轴线的大小
)
axis(2, # 显示y轴
las=2, # 参数设置文本的方向,2是垂直的
cex.axis=1.5, # 设置文本的大小
lwd=1.5 # 设置轴线的大小
)
title(xlab=explain\[\["PC1"\]\], # PC1所解释的方差百分比
ylab=explain\[\["PC2"\]\], # PC2解释的方差百分比
cex.lab=1.5, # 标签文字的大小
cex.main=1.5 # 标题文字的大小
)
随时关注您喜欢的主题

 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载 2025-2026食品饮料行业全景洞察报告:婴童零辅食、量贩零食、东南亚出海 | 附180+份报告PDF、数据、可视化模板汇总下载
2025-2026食品饮料行业全景洞察报告:婴童零辅食、量贩零食、东南亚出海 | 附180+份报告PDF、数据、可视化模板汇总下载

