在之前的文章中,我们研究了许多使用 多输出回归分析的方法。
在本教程中,我们将学习如何使用拟合和预测多输出回归数据。
对于给定的 x 输入数据,多输出数据包含多个目标标签。本教程涵盖:
- 准备数据
- 定义模型
- 预测和可视化结果
多输出(多因变量)回归是一种回归分析方法。在传统的回归中,通常只有一个因变量,而多输出回归则有多个因变量。这种方法试图找到一个模型,能够同时预测多个因变量与一个或多个自变量之间的关系。例如,在预测房价时,不仅要预测房屋的总售价,还可能同时预测房屋的每平方米价格等多个因变量,此时就可以使用多输出回归方法。
集成学习梯度提升决策树(GRADIENT BOOSTING REGRESSOR,GBR)回归是一种机器学习方法。其中,集成学习是通过组合多个弱学习器来构建一个强学习器的方法。梯度提升决策树是一种基于决策树的集成学习算法,它通过不断地拟合残差来逐步提升模型的性能。GBR 回归则是将这种算法应用于回归问题,即预测连续值的任务。
我们将从加载本教程所需的库开始。
准备数据
首先,我们将为本教程创建一个多输出数据集。它是随机生成的数据,具有以下一些规则。该数据集中有三个输入和两个输出。我们将绘制生成的数据以直观地检查它。
f = plt.figure()
f.add_subplot(1,2,1)
plt.title("Xs 输入数据")
plt.plot(X)
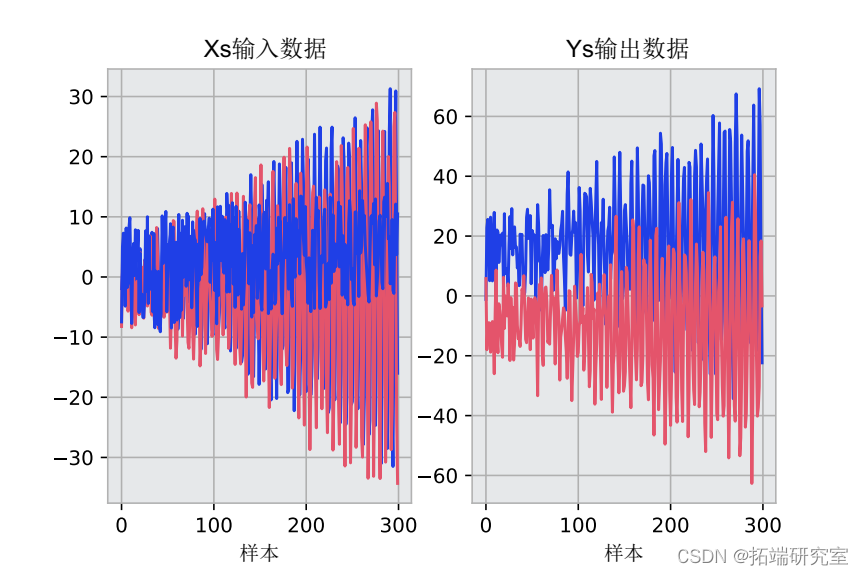
可下载资源
作者

接下来,我们将数据集拆分为训练和测试部分并检查数据形状。
print("xtrain:", xtrain.shape, "ytrian:", ytrain.shape)

定义模型
我们将定义模型。作为估计,我们将使用默认参数实现。可以通过 print 命令查看模型的参数。
model = MutRer(es=gbr) print(model )
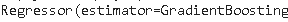
现在,我们可以用训练数据拟合模型并检查训练结果。
fit(xtrain, ytrain) score(xtrain, ytrain)

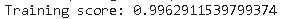
预测和可视化结果
我们将使用经过训练的模型预测测试数据,并检查 y1 和 y2 输出的 MSE 率。
随时关注您喜欢的主题
predict
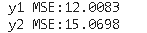
最后,我们将在图中可视化结果并直观地检查它们。
xax = range(len) plt.plot plt.legend
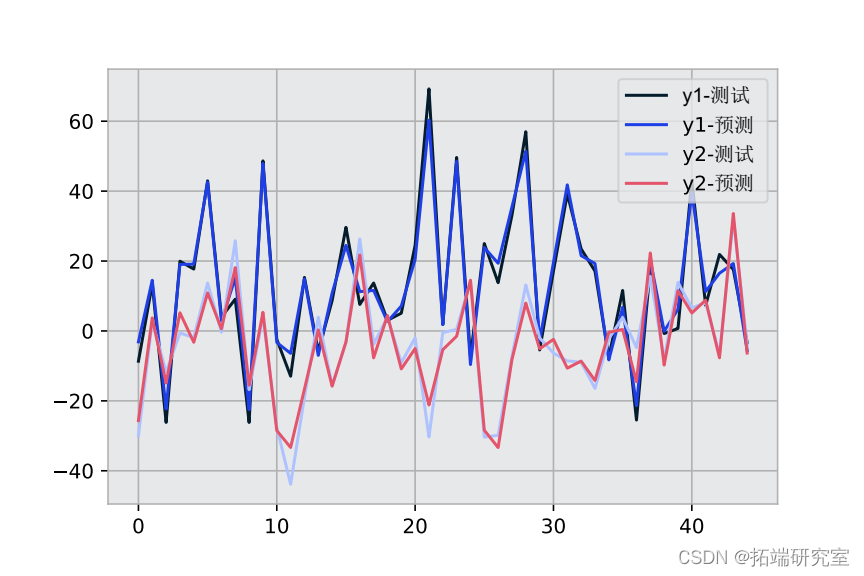
在本教程中,我们简要学习了如何在 Python 中训练了多输出数据集和预测的测试数据。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

