
Apriori 算法是一个相当新的算法,由 Agrawal 和 Srikant 于 1994 年提出。
它是一种用于频繁项集挖掘的算法,允许公司理解和组织向上销售和交叉销售活动。
最强大的应用程序之一是我们在亚马逊上在线购物时看到的推荐系统 – 以及当今几乎所有电子商务网站上都存在的各种其他版本。
问:什么是购物篮?主要运用在什么场景?
答:单个客户一次购买商品的综合称为一个购物篮,即某个客户本次的消费小票。常用场景:超市货架布局:互补品与互斥品;套餐设计。
问:购物篮的常用算法?
答:常用算法有
-
不考虑购物顺序:关联规则。购物篮分析其实就是一个因果分析。关联规则其实是一个很方便的发现两样商品关系的算法。共同提升的关系表示两者是正相关,可以作为互补品,如豆瓣酱和葱一起卖也才是最棒的。替代品的概念便是我买了这个就不用买另外一个。
-
考虑购物顺序:序贯模型。多在电商中使用,比如今天你将这个商品加入了购物车,过几天又将另一个商品加入了购物车,这就有了一个前后顺序。但许多实体商店因为没有实名认证,所以无法记录用户的消费顺序。
问:求出互补品与互斥品后对布局有什么用?
答:根据关联规则求出的商品间的关联关系后,可能会发现商品间存在强关联,弱关联与排斥三种关系。每种清醒有各自对应的布局方式。
-
强关联:关联度的值需要视实际情况而定,在不同的行业不同的也业态是不同的。强关联的商品彼此陈列在一起会提高双方的销售量。双向关联的商品如果陈列位置允许的话应该相关联陈列,即A产品旁边有B,B产品边上也一定会有A,比如常见的剃须膏与剃须刀,男士发油与定型梳;而对于那些单向关联的商品,只需要被关联的商品陈列在关联商品旁边就行,如大瓶可乐旁边摆纸杯,而纸杯旁边则不摆大瓶可乐,毕竟买大可乐的消费者大概率需要纸杯,而购买纸杯的顾客再购买大可乐的概率不大。
-
弱关联:关联度不高的商品,可以尝试摆在一起,然后再分析关联度是否有变化,如果关联度大幅提高,则说明原来的弱关联有可能是陈列的原因造成的。
-
排斥关系:指两个产品基本上不会出现在同一张购物小票中,这种商品尽量不要陈列在一起。
根据购物篮的信息来进行商品关联度的分析不仅仅只有如上三种关系,它们仅代表商品关联度分析的一个方面(可信度)。全面系统的商品关联分析必须有三度的概念,三度包括支持度,可信度和提升度。
这是为了帮助理解一个非常简单的数据集,其中包含单个国际标准书号 (ISBN),它是一本书的唯一国际出版商标识符号。每行代表购买了所列书籍的唯一客户。
目标是了解基本购买行为,向客户推荐的其他书籍是什么——这样它可以提高公司的收入以及对所提供服务的整体满意度。
我们以网络图结束,该图展示了置信度高于 55% 的关系或先验
设置和导入数据集
import numpy as np import pandas as pd data.head()
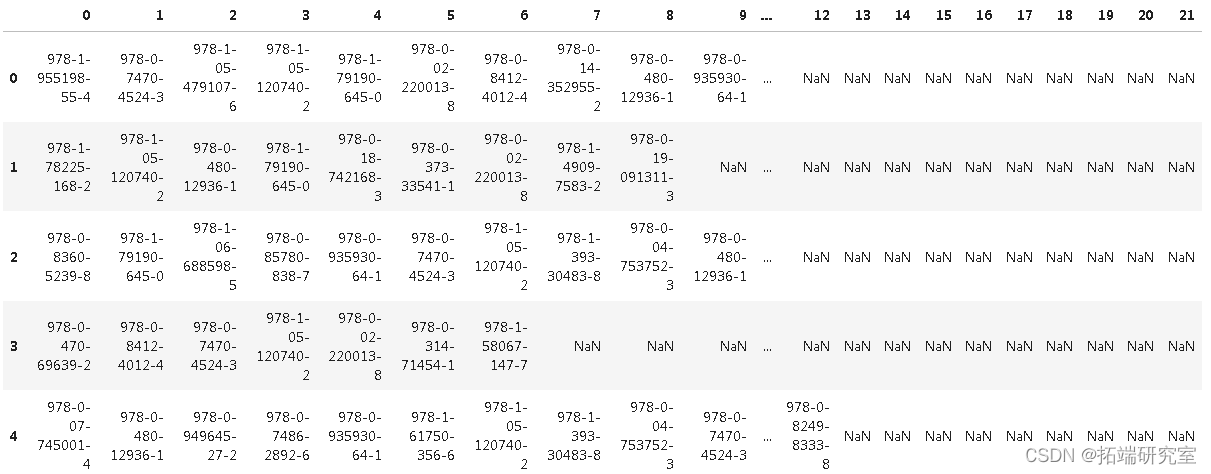
data.shape
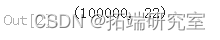
数据集上的EDA
#执行堆叠的步骤,转换为字符串,包括删除索引 dt2 = pd.DataFrame dt2 = dt2.reset_index(drop = True)

dt2.nunique() # 总共有4,999本独特的书籍
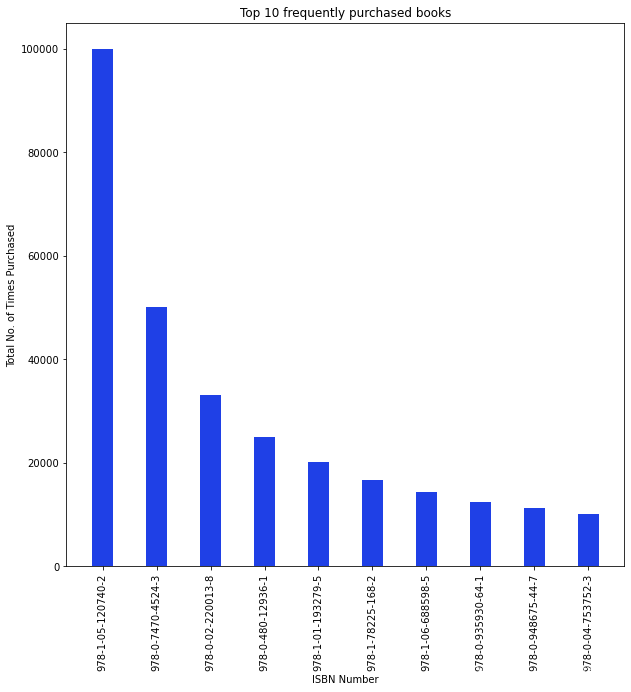
#数据集中购买最多的前10本书 top0 = pd.DataFrame(dt2.value_counts(sort= True, ascending=False).head(10)) to10
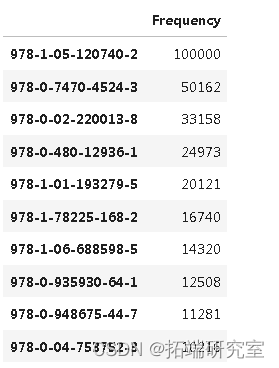
# 创建条形图 plt.bar(t0.index, top_10\['Frequency'\])
预处理
tdf = t.fit(d2).transform(da2)

ted = t.fit(r).transform(tr) t_f

tdf = df.astype("int")
t_f

oks = d.DataFrame(tf, columns=e.columns_) bos.head()

建立Apriori模型
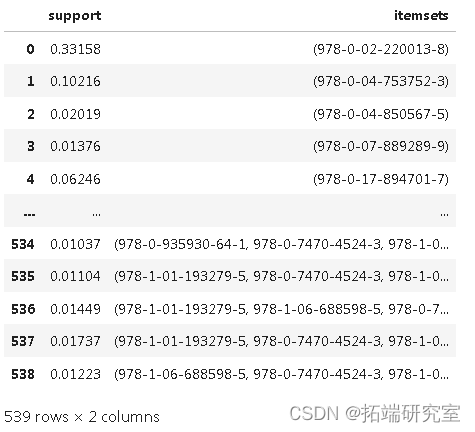
runets = apriori(o2, min\_support=0.01, use\_colnames=True)
feqts
随时关注您喜欢的主题
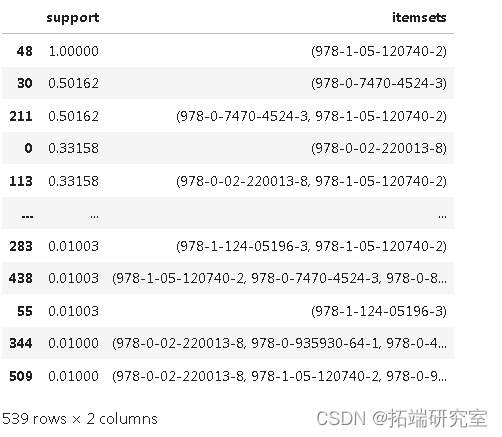
fetes.sort_values( by = \['support'\] ,ascending = False)
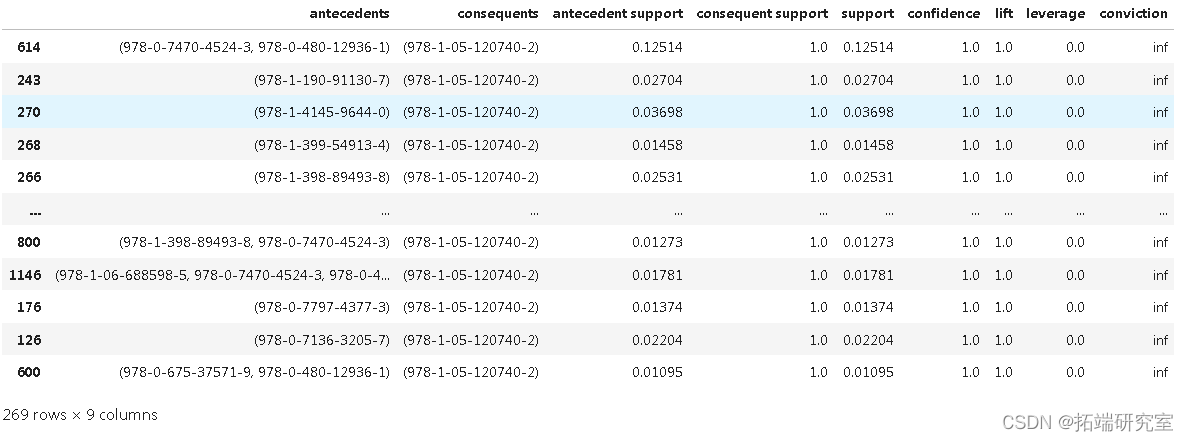
rls = assoc(fret, metric = "lift", min_threshold = 1)

re.solues('confidence', ascending = False)
ruls.head()

rul = rls\[res\['confidence'\] >= 0.55\] rue
结论网络图
fig, ax = plt.subplots(figsize = (10,6)) G = x.from\_pandas\_edgelist(ul,source = 'antecedents') n.draw(A)

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究
SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究 SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究
SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究
