随机森林是决策树的集合。在这篇文章中,我将向您展示如何从随机森林中可视化决策树。
首先让我们在房价数据集上训练随机森林模型。
加载数据并训练随机森林。
可下载资源
X = pd.DataFrame(data, columns=feature_names)-
1.criterion gini or entropy
-
2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
-
3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
-
4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
-
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
-
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
-
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
-
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
-
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
-
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
-
n_estimators:要建立树的个数
让我们将森林中的树数设置为 100:
RandomForestRegressor(n_estimators=100)决策树存储在 模型list 中的 estimators_ 属性中 rf 。我们可以检查列表的长度,它应该等于 n_estiamtors 值。
len(estimators_)
>>> 100我们可以从随机森林中绘制第一棵决策树( 0 列表中有索引):
plot\_tree(rf.estimators\_\[0\])
这棵树太大,无法在一个图中将其可视化。
让我们检查随机森林中第一棵树的深度:
tree_.max_depth
>>> 16我们的第一棵树有 max_depth=16. 其他树也有类似的深度。为了使可视化具有可读性,最好限制树的深度。让我们再次训练随机森林 max_depth=3。
第一个决策树的可视化图:
plot\_tree(rf.estimators\_\[0\])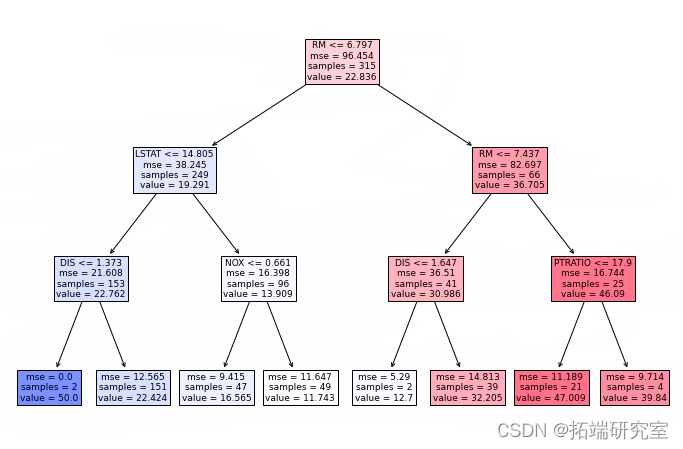
我们可以可视化第一个决策树:
viz
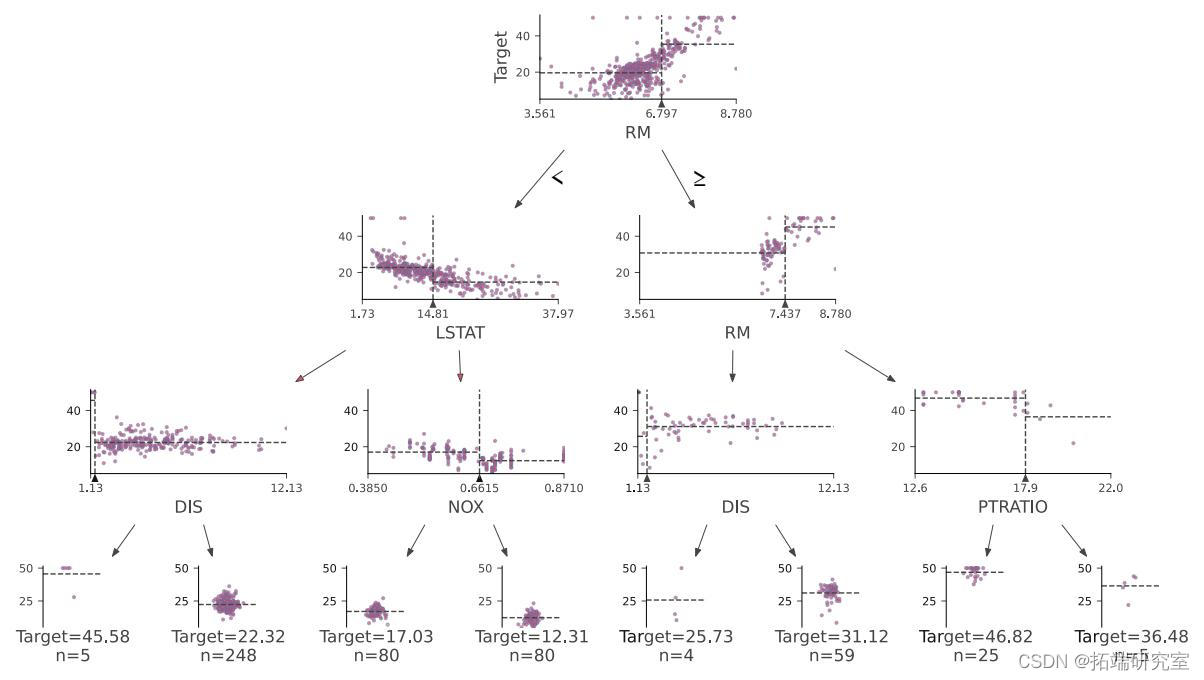
随时关注您喜欢的主题
概括
我将向您展示如何可视化随机森林中的单个决策树。可以通过 estimators_ 列表中的整数索引访问树。有时当树太深时,值得用 max_depth 超参数限制树的深度。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据

