Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
企业人才流失的预警精度每提升1%,可能为年营收千万级企业减少数十万元的替换成本。

本项目代码数据文件已分享在交流群,进群咨询、定制数据报告和600+行业人士共同交流和成长。
但现实是,多数企业仍依赖HR经验判断离职风险,预警窗口常不足2个月,且难以捕捉95后员工对”工作生活平衡”的核心诉求。如何用机器学习突破这一困境?本研究基于企业员工数据集(Employee Dataset),构建了从数据处理到模型落地的全流程方案:针对离职样本仅占16.2%的不平衡数据,用ADASYN动态采样技术将少数类识别能力提升19.4%;通过LASSO与相关系数分析从37个特征中精选21个核心变量,避免冗余与共线性;最终用CatBoost结合Optuna优化,将预测AUC值提升至0.979,远超传统模型。
本项目代码数据文件已分享在交流群,进群咨询、定制数据报告和600+行业人士共同交流和成长。
为什么需要更精准的流失预测?
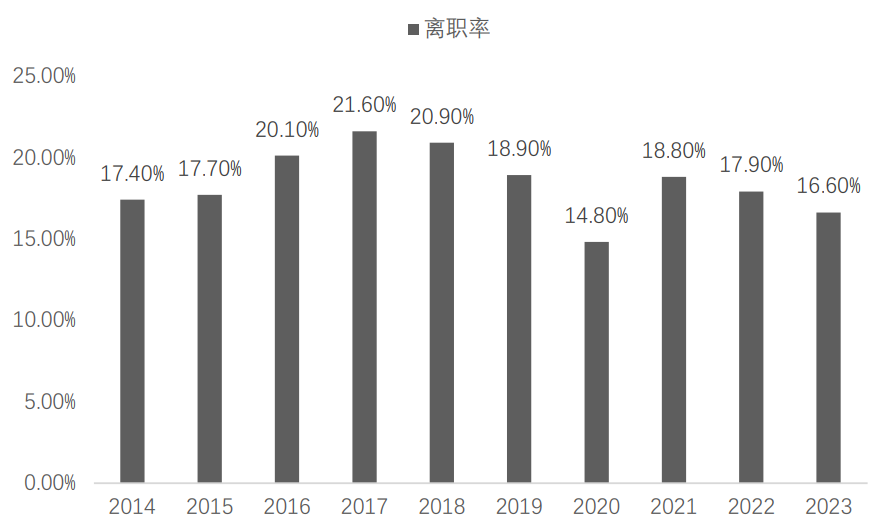
《2024离职与调薪调研报告》显示,2023年全国行业员工离职率仍达16.6%,而替换一名核心员工的成本可达其年薪的1.5-2倍(见图1.1)。更棘手的是,传统预测方法存在三重局限:预警滞后(错失干预时机)、忽略非经济因素(如职业成长)、适配性不足(疫情后员工需求变化)。
本研究的核心价值在于:用机器学习将预警窗口延长至3-6个月,同时通过变量重要性分析锁定关键诱因,帮助HR从”被动应对”转向”主动干预”。
现有方法的瓶颈与突破方向
国内外研究已证实机器学习在流失预测中的潜力:Rohit Punnoose(2016)发现XGBoost的AUC达0.89,远超逻辑回归;国内李德友(2020)用SMOTE-SVM将F1值提升18.5%。但现有研究多存在两点不足:一是单一采用SMOTE处理不平衡数据,忽略样本分布差异;二是特征选择未控制共线性,导致模型稳定性不足。本研究的突破点正在于此:用ADASYN动态适配样本密度,结合LASSO与相关系数分析精准降维,最终用CatBoost实现高精度预测。
技术方案设计与实现
整体技术路线
研究流程清晰可追溯(见图1.2),核心分为三阶段: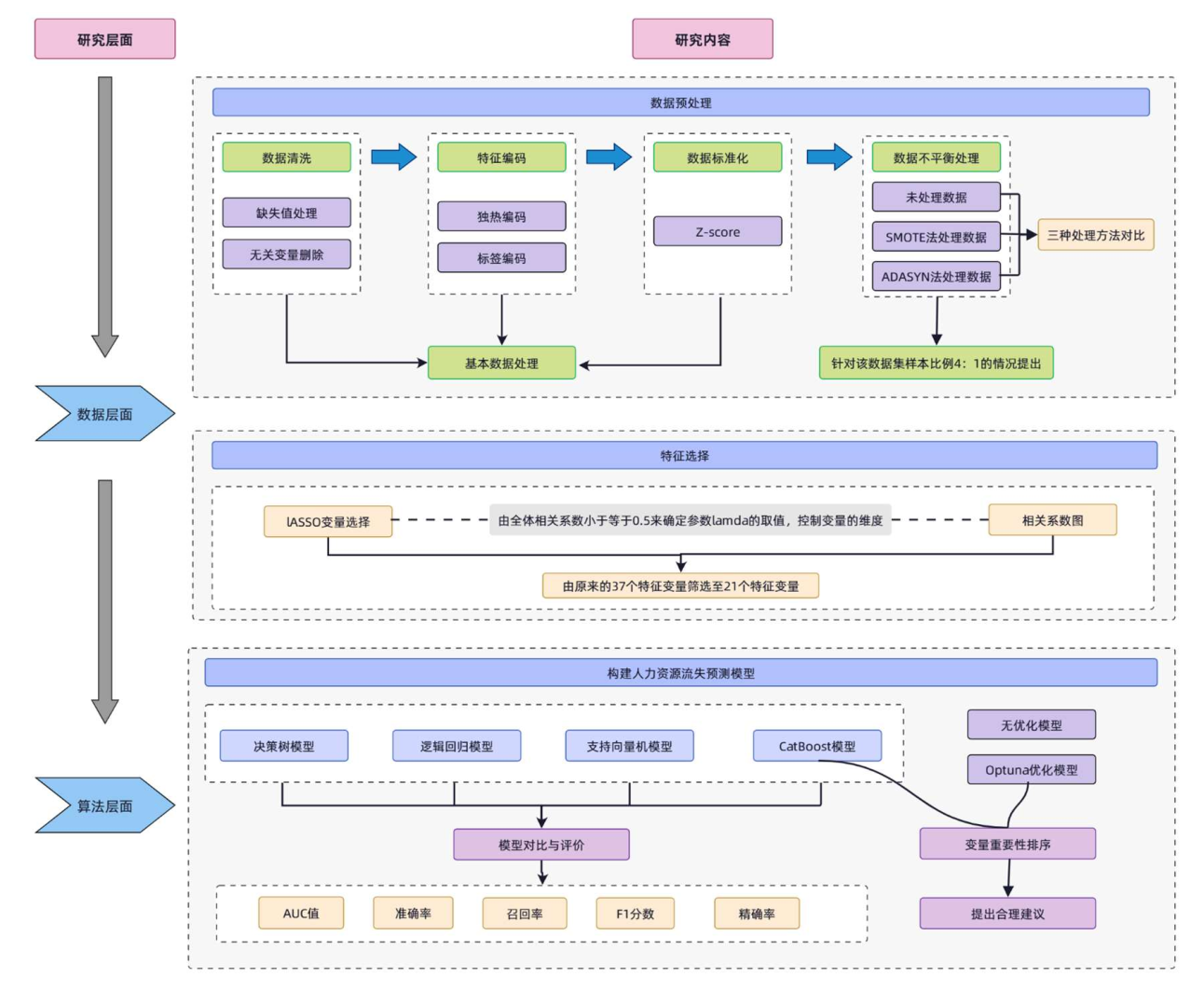
- 数据预处理:剔除员工ID等5个冗余特征,对有序变量(如年龄分组)用标签编码,无序变量(如部门)用独热编码;
- 不平衡处理:对比原始数据、SMOTE、ADASYN三种方案,选定ADASYN(按少数类样本密度动态生成合成数据);
- 特征选择:用LASSO设定λ=0.03,保留21个特征,且确保任意两特征相关系数≤0.5;
- 模型构建:对比决策树、逻辑回归、SVM、CatBoost,用Optuna优化CatBoost的12个超参数(如学习率、树深度)。
核心技术解析
1. ADASYN采样:动态平衡数据分布
原始数据
原始数据中离职样本仅占16.2%(见图3-1),导致模型偏向”不离职”预测。ADASYN通过以下逻辑突破这一局限: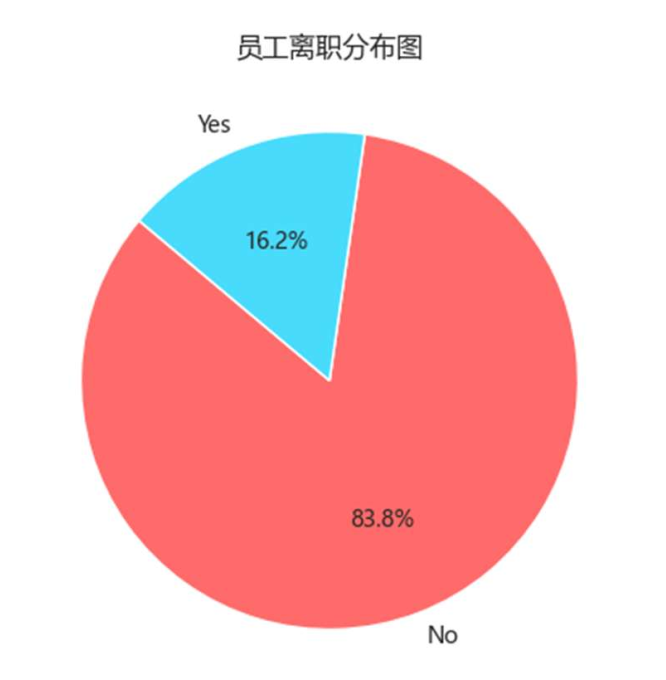
- 计算每个少数类样本的”困难度”(周围多数类样本比例);
- 按困难度分配合成样本数量(困难样本生成更多数据);
对比实验显示(见图3-2),ADASYN的F1值达0.488,比SMOTE(0.456)高7%,能多识别17.5%的潜在离职者。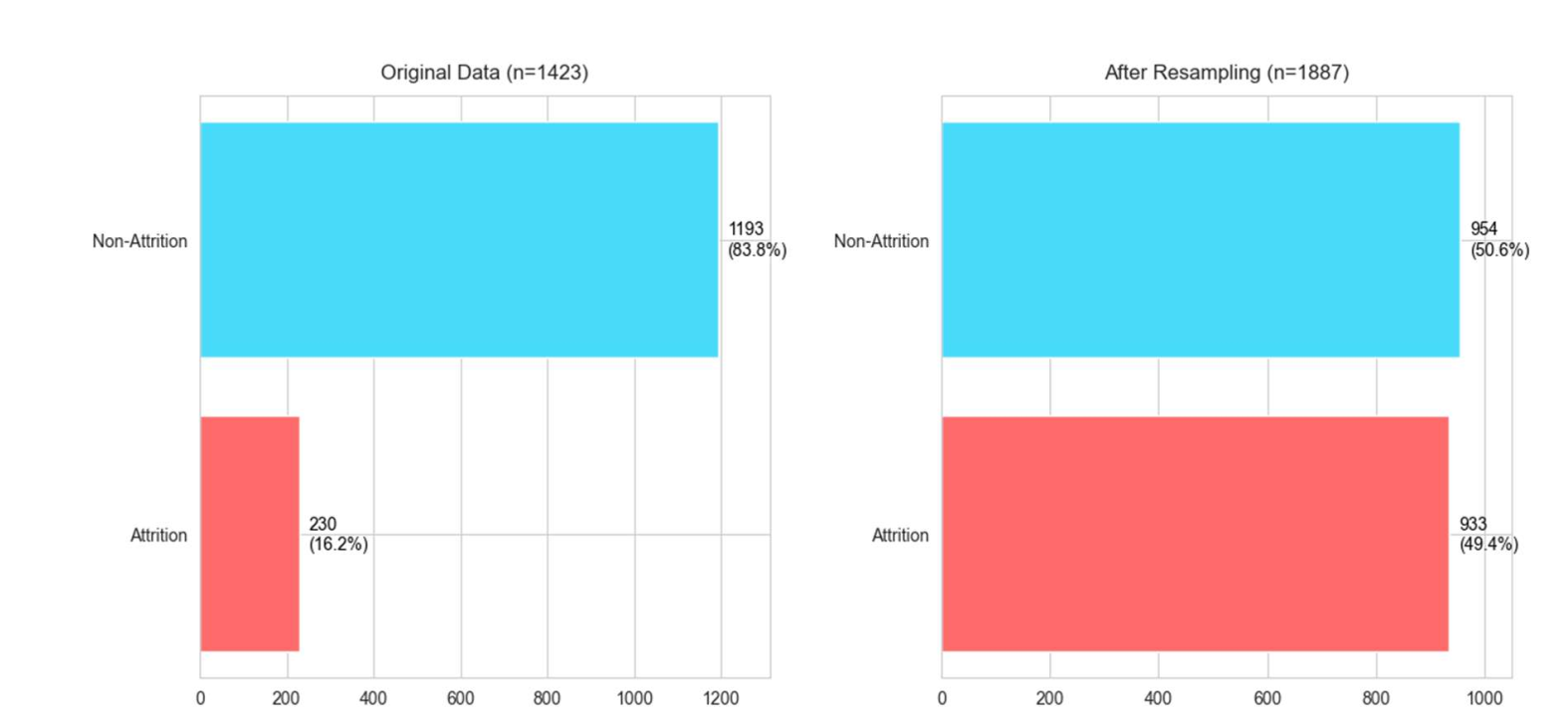
2. LASSO+相关系数:精准筛选特征
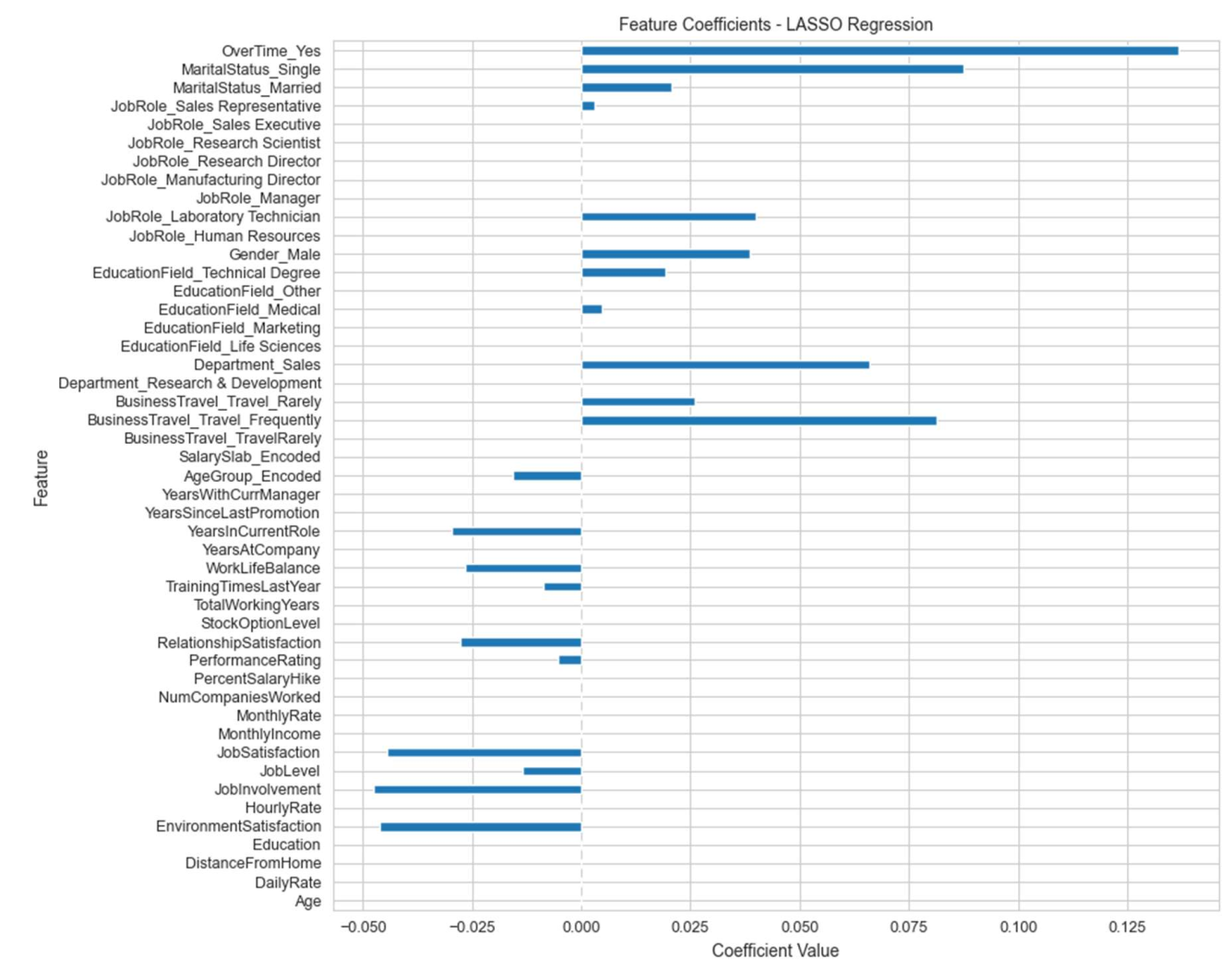
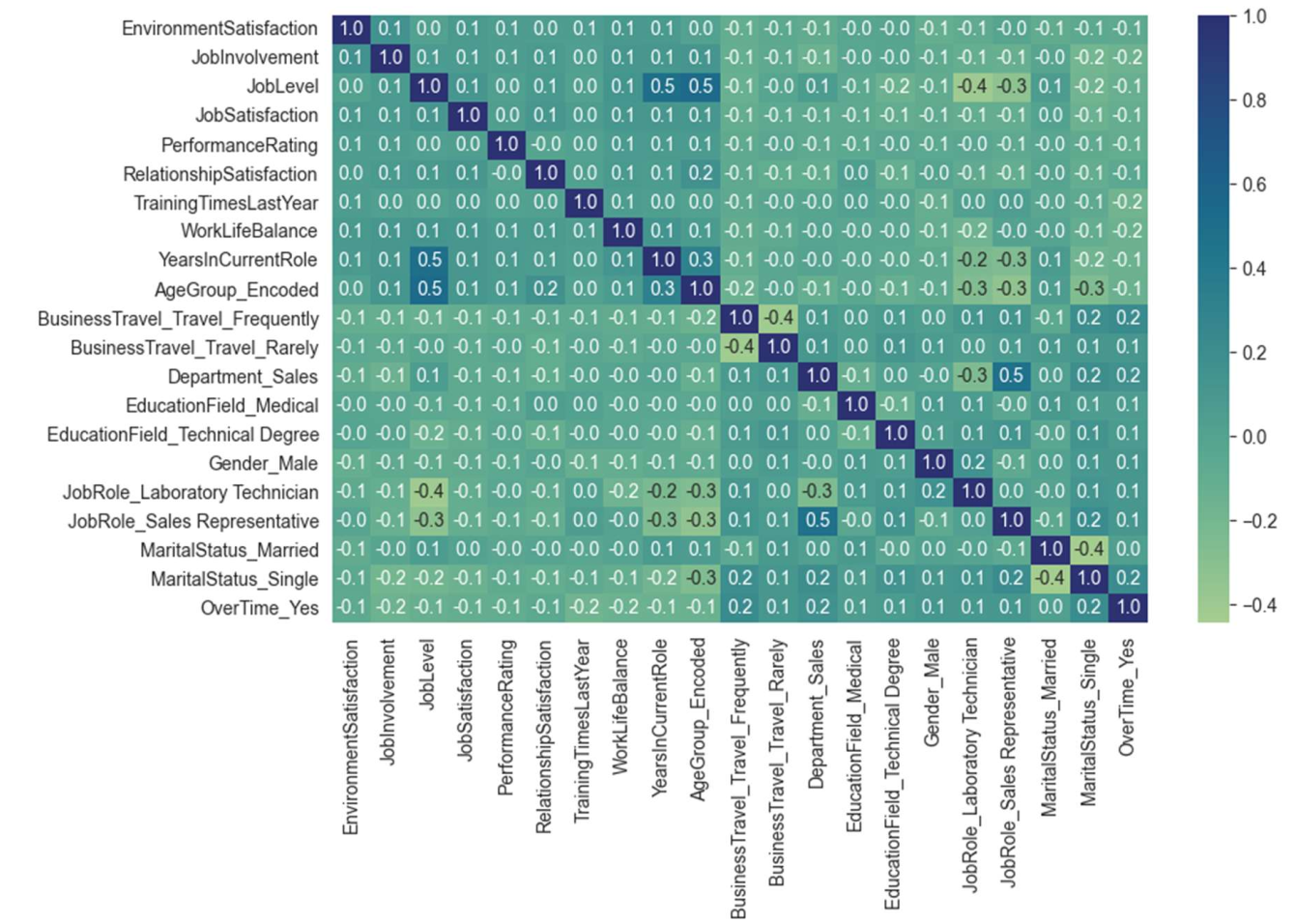
用LASSO设定λ=0.03时,保留21个特征(见图3.3),结合相关系数热力图(图3.4)可知,特征间相关性均≤0.5,避免”工作年限”与”晋升年限”的共线性干扰。
3. CatBoost+Optuna:提升预测精度
CatBoost的优势在于自动处理类别特征(如用”部门离职率”转换文本特征),搭配Optuna超参数调优(代码示例如下),最终AUC达0.979。
# CatBoost优化代码(注释已翻译)
import catboost as cb
import optuna
# 定义目标函数:最大化AUC
def objective(trial):
# 参数搜索范围
params = {
'iterations': trial.suggest_int('迭代次数', 500, 1500),
'learning_rate': trial.suggest_float('学习率', 0.01, 0.3),
'depth': trial.suggest_int('树深度', 3, 10),
'min_data_in_leaf': trial.suggest_int('叶子最小样本数', 10, 100)
}
# 训练模型
model = cb.CatBoostClassifier(**params, eval_metric='AUC', verbose=0)
model.fit(X_train, y_train, eval_set=(X_val, y_val), early_stopping_rounds=50)
# 返回验证集AUC
return model.get_evals_result()['validation_0']['AUC'][-1]
# 执行50次优化
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print(f"最优AUC: {study.best_value:.4f}") # 输出:0.979
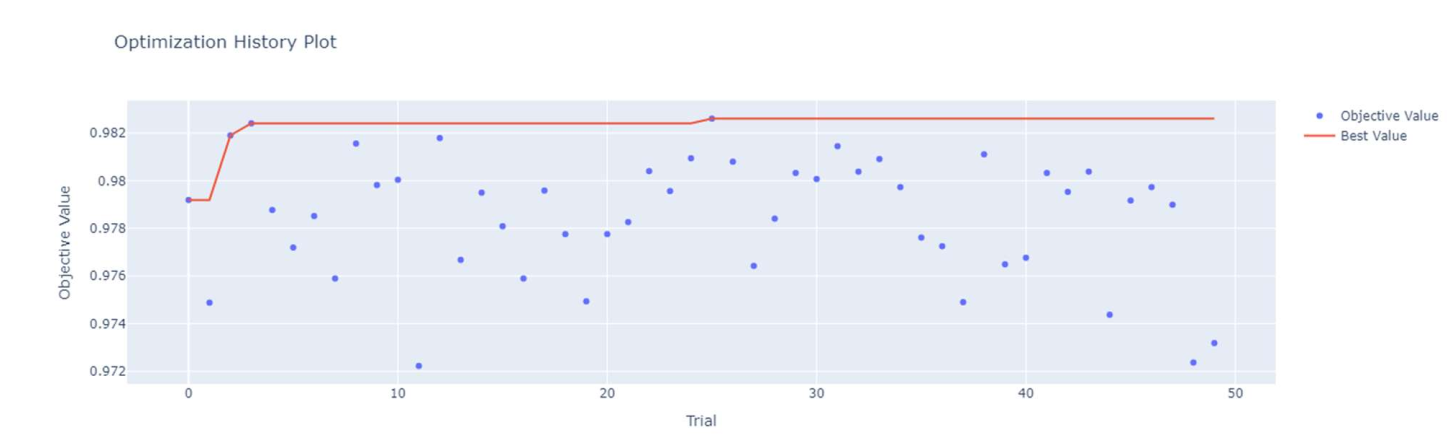
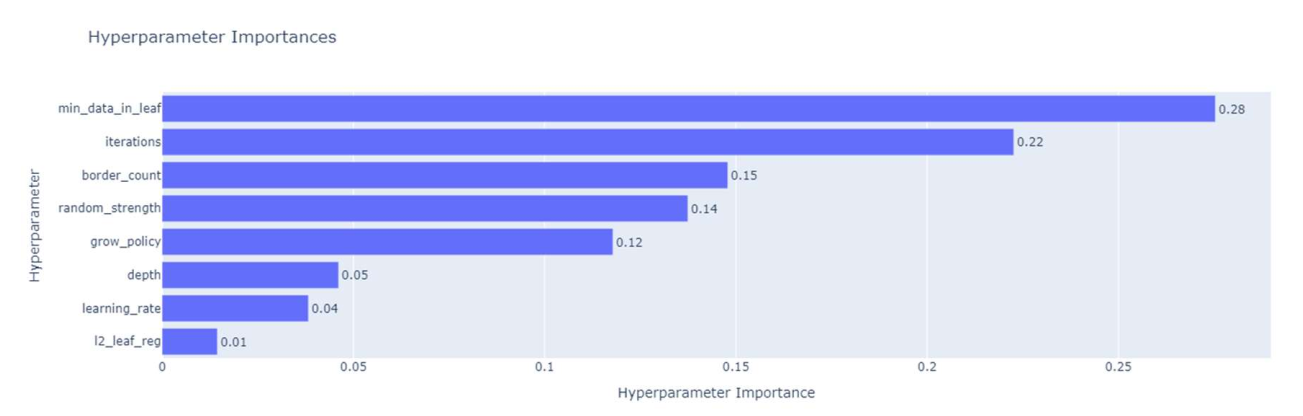
优化过程显示(图4.2),AUC在15次迭代后达0.982并稳定,其中”叶子最小样本数”(重要性0.28)是关键参数(图4.3)。

【梯度提升专题】XGBoost、Adaboost、CatBoost预测合集:抗乳腺癌药物优化、信贷风控、比特币应用|附数据代码
本文汇总了梯度提升算法在多个领域的应用,包括抗乳腺癌药物优化、信贷风控和比特币预测,提供了完整的数据和代码实现。
探索观点模型对比与结果解读
多模型性能PK
对比决策树、逻辑回归、SVM、CatBoost(含优化)的核心指标(表4.8),Optuna优化的CatBoost表现最优:AUC 0.979、召回率90.7%,意味着能捕捉90%以上的潜在离职者。ROC曲线(图4.4)更直观显示其判别能力领先。
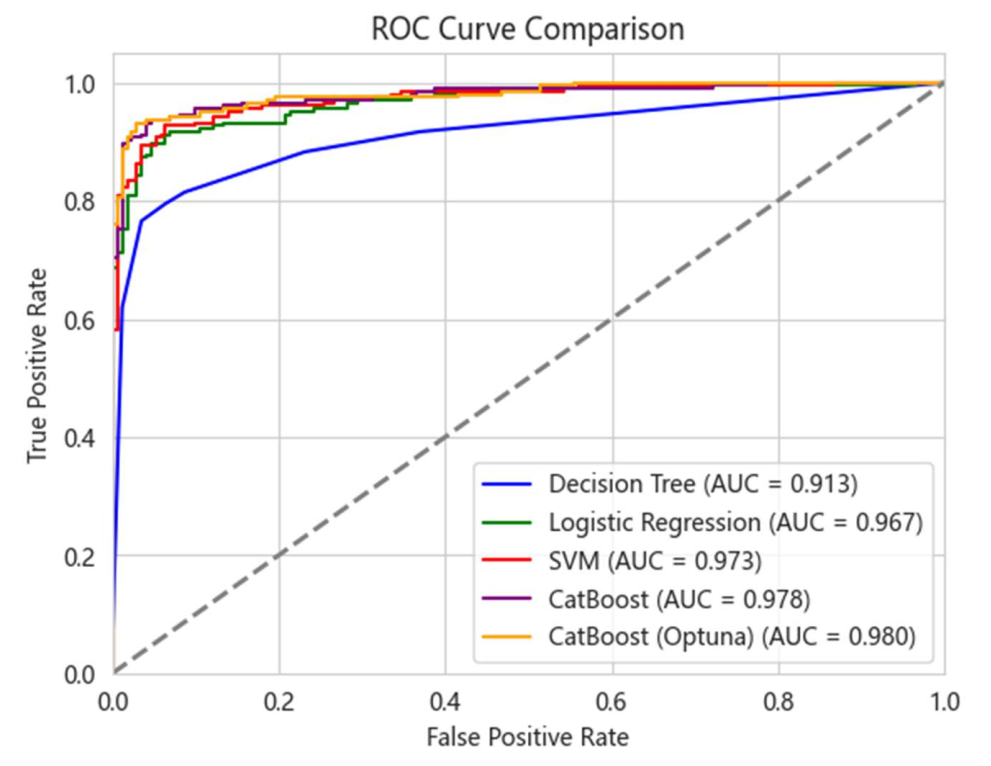
表4.8 不同模型的评价指标比较
| 模型类型 | 准确率 | 精确率 | 召回率 | F1-Score | AUC值 |
|---|---|---|---|---|---|
| 决策树 | 0.8571 | 0.9632 | 0.7659 | 0.8533 | 0.9126 |
| 逻辑回归 | 0.9153 | 0.9626 | 0.8780 | 0.9184 | 0.9670 |
| SVM | 0.9021 | 0.9719 | 0.8439 | 0.9034 | 0.9730 |
| CatBoost | 0.9365 | 0.9788 | 0.9024 | 0.9391 | 0.9781 |
| CatBoost+Optuna | 0.9392 | 0.9789 | 0.9073 | 0.9418 | 0.9794 |
关键影响因素
从变量重要性图(图4.5)可知,top3影响因素为:
- 加班(重要性12.3);
- 出差频率(10.8);
- 婚姻状况(8.5)。
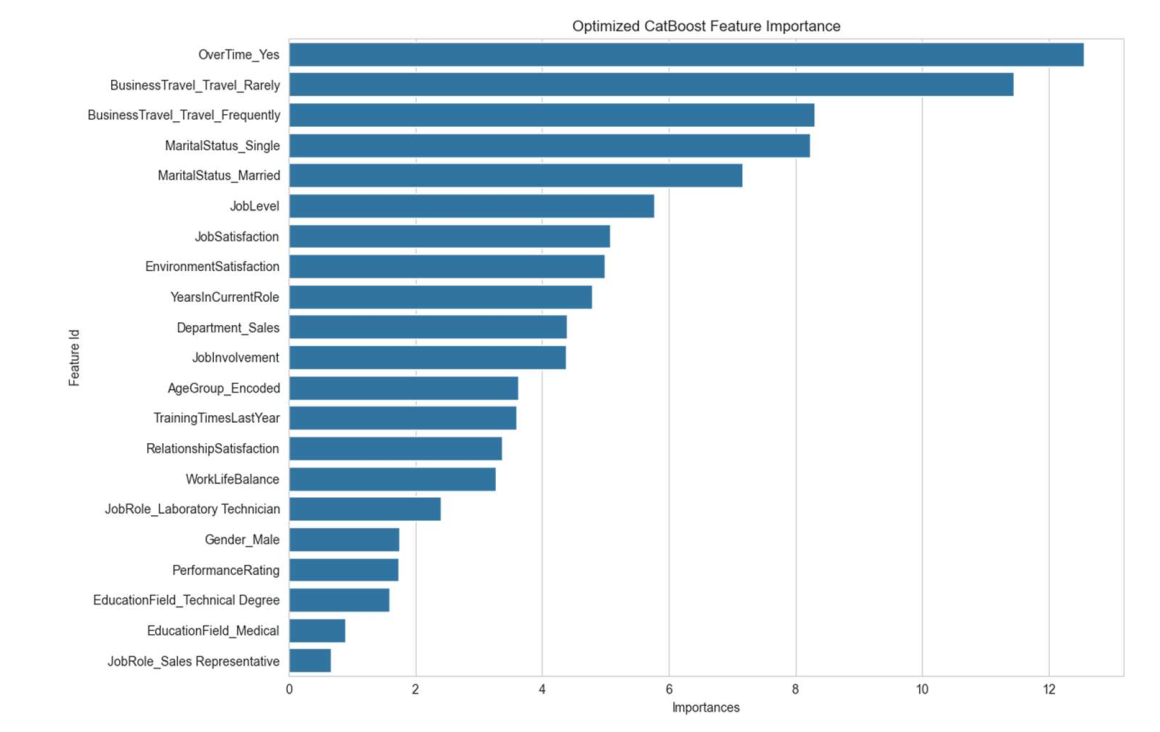
这为企业提供明确方向:优化加班制度、制定差异化出差政策、针对单身/已婚员工设计不同留才方案。
结论与实践建议
本研究证实:ADASYN动态采样能更精准平衡流失数据;LASSO+相关系数分析可有效降维;Optuna优化的CatBoost是预测最优解。对企业而言,可按以下步骤落地:
- 用模型生成员工流失风险分数(0-100);
- 对高风险(>80分)员工启动一对一访谈;
- 针对加班、出差等关键因素优化管理制度。
后续可纳入行业景气度等外部变量,进一步提升模型泛化能力。
参考文献
[1] 刘人荣. 中国建设银行W分行青年员工离职问题与对策研究[D]. 扬州:扬州大学,2022.
[2] Rohit Punnoose, Pankaj Ajit. Prediction of employee turnover in organizations using machine learning algorithms[J]. International Journal of Advanced Research in Artificial Intelligence, 2016,5(9):222-226.

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据
Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据 Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据
Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据



