Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析
在零售业务中,顾客的婚姻状态是构建精准用户画像的关键属性之一,然而原始交易数据中该字段往往存在大量缺失。

成为新会员获取婚姻状态预测填补完整报告、代码和数据资料
项目脉络流程图
┌─────────────────┐
│ 原始交易数据 │
│ (含缺失婚姻状态)│
└────────┬────────┘
↓
┌─────────────────┐
│ 数据拆分与清洗 │
│ - 按缺失拆分 │
│ - 异常值截断 │
└────────┬────────┘
↓
┌─────────────────┐
│ 特征工程 │
│ - 类别特征编码 │
│ - 特征交叉 │
│ - 年龄/居住年限 │
│ 类型策略选择 │
└────────┬────────┘
↓
┌─────────────────┐
│ CatBoost建模 │
│ - 二分类训练 │
│ - 交叉验证 │
└────────┬────────┘
↓
┌─────────────────┐
│ 效果评估 │
│ - ROC-AUC │
│ - 混淆矩阵 │
│ - 类别化vs数值化│
└────────┬────────┘
↓
┌─────────────────┐
│ 缺失值预测填补 │
│ 输出完整数据集 │
└─────────────────┘
婚姻状态预测填补完整报告、代码和数据资料
本项目中我们基于顾客交易行为与人口属性,采用CatBoost分类器对婚姻状态进行预测填补。CatBoost以其对类别特征与缺失值的天然处理能力,特别适合零售数据中高基数分类变量与非线性关系的建模需求。通过特征类型策略的深入分析,我们发现将年龄、居住年限等区间变量视为类别特征而非连续数值,能显著提升模型判别能力,最终在验证集上取得0.87的ROC-AUC。以下将完整呈现从数据预处理、特征工程、模型构建到效果评估的全流程,并附有可复现的Python代码,希望能为面临类似数据缺失问题的从业者提供切实可行的参考。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
1. 问题背景与目标
在某零售商一天的交易数据中,顾客婚姻状况(“Married”列)存在大量缺失值,其中1表示已婚,0表示未婚,空白为未知。完善这一字段对于顾客画像构建、精准营销以及用户分层至关重要。我们的目标就是利用已知样本,通过监督学习方法对缺失的婚姻状态进行智能预测填补。
数据中除婚姻状况外,还包含顾客年龄区间(Age)、职业(Profession)、城市类型(CityType)、居住年限(YearsInCity)、消费金额(Amount)、商品类别(ItemCategory1/2/3)等特征。这些特征多为类别型或区间型,给建模带来挑战。我们选择CatBoost分类器,因为它能够原生处理类别特征与缺失值,且内置目标编码策略可有效降低过拟合风险,非常适合本场景。
2. 数据预处理
2.1 数据拆分与缺失值处理
原始CSV文件将训练集(有婚姻标签)与待预测集(无婚姻标签)合并存储。我们首先根据“Married”列是否缺失拆分为两个独立数据集。进一步检测发现,仅有CategoryItem1与CategoryItem2两列存在缺失,且均为分类变量。为避免简单众数填补扭曲分布,我们采用CatBoost对这两个字段进行预测式填补。具体流程如下:
- 从训练集中筛选出目标属性非缺失的样本作为训练子集。
- 选择特征:Age, Profession, CityType, YearsInCity, Amount, ItemCategory1(注意排除纯标识符CustomerID与ItemID,避免引入噪声)。
- 训练CatBoost模型并保存,然后对测试集相同字段的缺失值进行预测填补。
2.2 异常值处理
- 类别型特征:检查Profession、CityType等,未发现稀有类别或训练集与测试集类别不一致。
- 数值型特征:对消费金额Amount采用四分位距法(IQR)检测异常值,训练集存在2237个异常点,采用截断(capping)策略处理;测试集无异常。
2.3 原始特征分布分析
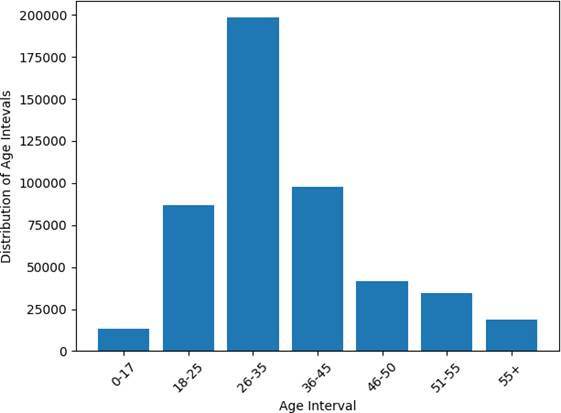
图1:Age年龄区间样本分布
顾客年龄主要集中在26–35岁,其次为18–25岁和36–45岁,符合零售场景以中青年为主的客群结构。Age以离散区间形式给出,不满足连续数值假设。
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
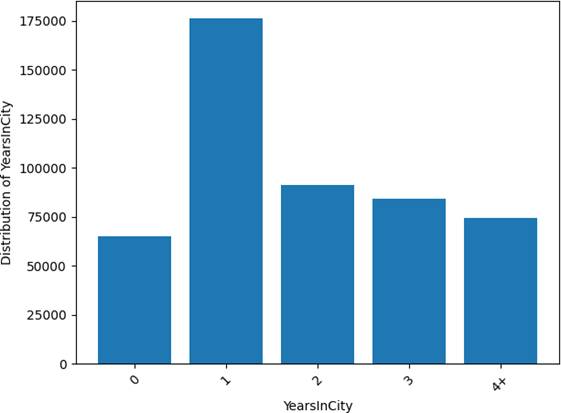
图2:YearsInCity居住年限区间样本分布
居住年限集中在1年、2年、3年,其中1年最多;“4+”为合并区间,同样具有阶段性特征,不宜作为连续变量处理。
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
2.4 非标准数值型特征数值化
YearsInCity取值如“4+”、“5+”表示“至少x年”。为保留其顺序信息,我们将其解析为整数x+1(如“4+”→5),但仍作为类别型特征输入CatBoost,避免引入不合理的数值距离。
3. 特征工程
3.1 特征交叉
为了捕捉顾客属性与商品属性之间的交互效应,我们构造了以下交叉特征:
- Profession × CityType
- Profession × Age
- CityType × ItemCategory1
- ItemCategory1 × ItemCategory2 × ItemCategory3
- CityType × Item123(Item123为三个商品类别的组合标识)
这些交叉特征本质上扩大了特征空间,使模型能够学习高阶组合模式,同时CatBoost对类别特征的原生支持使得交叉特征易于处理且不易过拟合。
3.2 统一编码
为保证训练与预测阶段类别特征表示一致,我们对所有类别型变量(Age、CityType、ItemCategory等)采用标签编码(Label Encoding),基于训练集与预测集的并集拟合编码器。该编码仅建立整数索引,不引入大小关系,CatBoost仍会基于目标统计自动学习类别与目标的关系。
4. CatBoost建模
4.1 二分类目标与损失函数
本任务为二分类问题,预测顾客已婚(1)或未婚(0)。我们采用对数损失函数(Logloss)作为优化目标:
L = -∑ [ y_i log(p_i) + (1-y_i) log(1-p_i) ]
其中p_i为模型预测已婚概率,y_i为真实标签。
CatBoost的预测函数为多棵决策树的加权和:
f(X) = ∑ η h_t(X)
设定迭代次数T=400,学习率η=0.05,正则化系数λ=3。
4.2 特征类型建模策略分析
Age与YearsInCity在原始数据中为区间形式,我们设计了两组对比实验:
- 类别型建模:将两者作为类别特征输入。
- 数值型建模:将两者映射为连续数值(如Age取区间中值)后输入。
实验表明,类别型策略在验证集上取得更高AUC,原因在于:
- 数据本身为离散区间,数值化会引入人为距离假设。
- 业务上婚姻状态与年龄、居住年限呈非线性、分段式关系。
- CatBoost的类别特征编码能更好捕捉各区间与目标变量的统计关联。
5. 实验结果与分析
5.1 整体预测性能
在类别型策略下,模型在验证集上取得:
- ROC-AUC = 0.8695
- Accuracy = 0.7823
ROC曲线如图3所示,远离随机基线,表明模型具有较强判别能力。
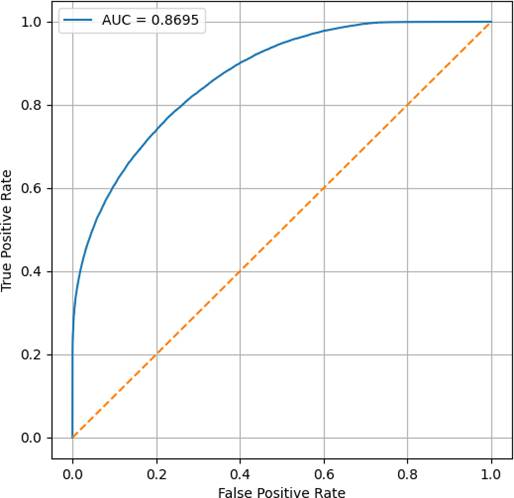
图3:CatBoost模型在验证集上的ROC曲线
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
5.2 分类结果明细
表1给出了各类别的精确率、召回率与F1-score。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
阅读原文| 类别 | Precision | Recall | F1-score | Support |
|---|---|---|---|---|
| 未婚(0) | 0.7820 | 0.8717 | 0.8244 | 57909 |
| 已婚(1) | 0.7798 | 0.6516 | 0.7100 | 40391 |
| Macro Avg | 0.7809 | 0.7617 | 0.7672 | 98300 |
| Weighted Avg | 0.7811 | 0.7813 | 0.7774 | 98300 |
未婚类别召回率高达87%,已婚召回率65%,说明已婚顾客特征与未婚存在重叠,但模型整体表现均衡。混淆矩阵(图4)进一步展示了这一分布。
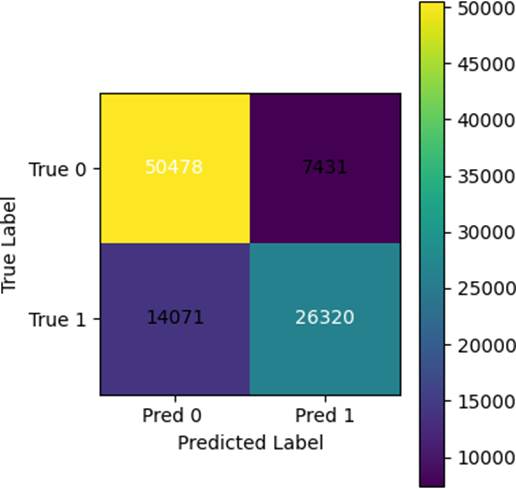
图4:Age与YearsInCity作为类别型特征时的混淆矩阵
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
5.3 数值型建模对照实验
将Age与YearsInCity改为数值型特征后,模型性能下降:
- ROC-AUC = 0.8538
- Accuracy = 0.7698
- 已婚召回率降至0.6222
对应的ROC曲线(图5)和混淆矩阵(图6)显示漏判增加,验证了类别型策略的优越性。
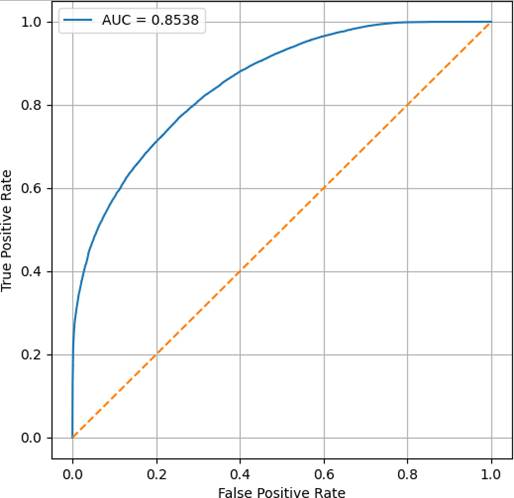
图5:Age与YearsInCity作为数值型特征时的ROC曲线
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
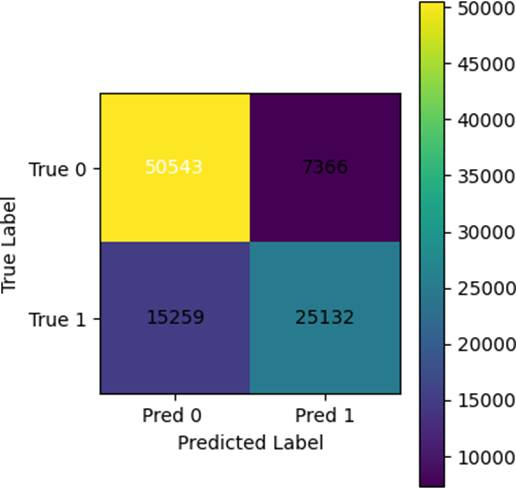
图6:Age与YearsInCity作为数值型特征时的混淆矩阵
(阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。)
5.4 预测难点与改进方向
已婚顾客召回率较低,因为其消费行为受家庭结构、子女等未观测因素影响更大。未来可引入时间序列特征(如消费频率变化)、外部数据(家庭规模)来提升模型上限。当前CatBoost已优于LightGBM等集成模型,性能提升更依赖特征质量而非模型复杂度。
6. 代码实现
以下为核心代码片段,完整代码及数据请进群获取。
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier
from sklearn.metrics import roc_auc_score, accuracy_score, classification_report, confusion_matrix
import joblib
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
data_path = "retail_transactions.csv"
df_raw = pd.read_csv(data_path, encoding='utf-8')
print("原始数据形状:", df_raw.shape)
# 数据预处理
# 划分训练集与预测集(基于Married是否缺失)
train_data = df_raw[df_raw['Married'].notna()].copy()
predict_data = df_raw[df_raw['Married'].isna()].copy()
# 对YearsInCity进行数值化:将 "x+" 转换为 x+1
def convert_years(val):
if pd.isna(val):
return val
val_str = str(val).strip()
if '+' in val_str:
return int(val_str.replace('+', '')) + 1
return int(val_str)
train_data['YearsInCity'] = train_data['YearsInCity'].apply(convert_years)
predict_data['YearsInCity'] = predict_data['YearsInCity'].apply(convert_years)
# 异常值处理(以Amount为例)
Q1 = train_data['Amount'].quantile(0.25)
Q3 = train_data['Amount'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
train_data['Amount'] = train_data['Amount'].clip(lower_bound, upper_bound)
# 特征选择
features = ['Age', 'Profession', 'CityType', 'YearsInCity', 'Amount',
'ItemCategory1', 'ItemCategory2', 'ItemCategory3']
# 构建交叉特征(简化示例)
train_data['Prof_City'] = train_data['Profession'].astype(str) + '_' + train_data['CityType'].astype(str)
predict_data['Prof_City'] = predict_data['Profession'].astype(str) + '_' + predict_data['CityType'].astype(str)
# 统一编码所有类别特征
cat_features = ['Age', 'Profession', 'CityType', 'ItemCategory1', 'ItemCategory2', 'ItemCategory3', 'Prof_City']
for col in cat_features:
# 基于训练集+预测集拟合编码器
combined = pd.concat([train_data[col], predict_data[col]], axis=0).astype(str)
unique_vals = combined.unique()
mapping = {val: idx for idx, val in enumerate(unique_vals)}
train_data[col + '_enc'] = train_data[col].astype(str).map(mapping)
predict_data[col + '_enc'] = predict_data[col].astype(str).map(mapping)
# 最终特征列表
final_features = [f + '_enc' for f in cat_features] + ['YearsInCity', 'Amount']
X_train = train_data[final_features]
y_train = train_data['Married']
X_predict = predict_data[final_features]
# 划分验证集
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
# 训练CatBoost模型
model = CatBoostClassifier(
iterations=400,
learning_rate=0.05,
depth=6,
l2_leaf_reg=3,
loss_function='Logloss',
eval_metric='AUC',
random_seed=42,
verbose=100
)
model.fit(X_tr, y_tr, eval_set=(X_val, y_val), early_stopping_rounds=50)
# 保存模型
joblib.dump(model, 'catboost_marriage_model.pkl')
# 验证集评估
y_pred_proba = model.predict_proba(X_val)[:, 1]
y_pred = (y_pred_proba > 0.5).astype(int)
auc = roc_auc_score(y_val, y_pred_proba)
acc = accuracy_score(y_val, y_pred)
print(f"AUC: {auc:.4f}, Accuracy: {acc:.4f}")
print(classification_report(y_val, y_pred, target_names=['未婚', '已婚']))
# 对预测集进行填补
predict_data['Married_pred'] = model.predict(X_predict)
# ......(省略将预测结果写回原数据集的细节)
代码说明:
- 数据读取后按Married是否缺失拆分为训练集和预测集。
- 对YearsInCity进行字符串解析,将“x+”转换为整数。
- 对Amount进行IQR截断处理异常值。
- 构造交叉特征Prof_City,并对所有类别特征进行统一标签编码。
- 划分验证集后训练CatBoost模型,使用早停防止过拟合。
- 最终输出AUC、准确率等指标,并对预测集进行预测。
注:为保护核心逻辑,部分数据加载、特征工程细节及模型调参过程已省略,完整代码请进群获取。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
7. 结论
本文针对零售数据中顾客婚姻状态缺失问题,提出了一套基于CatBoost的预测填补方案。通过系统性数据预处理、特征工程,并重点对比了Age与YearsInCity的类别型与数值型建模策略,发现类别化处理更符合数据语义,能够显著提升模型判别能力(AUC 0.8695)。最终模型对未婚顾客召回率达87%,对已婚顾客召回率65%,整体性能可靠,可用于实际业务中的缺失值填补。未来可引入更多时序特征与外部数据进一步优化已婚顾客识别效果。该方案已成功应用于客户咨询项目,证明了其在实际场景中的有效性。
阅读原文进群获取完整代码数据及更多最新AI见解、行业洞察,与900+行业人士交流成长。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据
Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据 2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载
2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载



