
在大数据时代,多水平数据结构广泛存在于环境健康、医学研究和体育赛事等领域。
本专题合集聚焦贝叶斯分层模型(Hierarchical Bayesian Model)的创新应用,通过氡气污染数据与 NHL 季后赛数据的实证分析,系统展示该方法在解决传统统计模型局限性方面的优势。
研究通过动态收缩权重算法、非中心化参数化技术和多层协变量建模等创新,实现了环境健康风险精准评估、医院治疗效果量化和球队实力科学评价。专题合集已分享在交流社群,进群和 500 + 行业人士共同交流和成长。
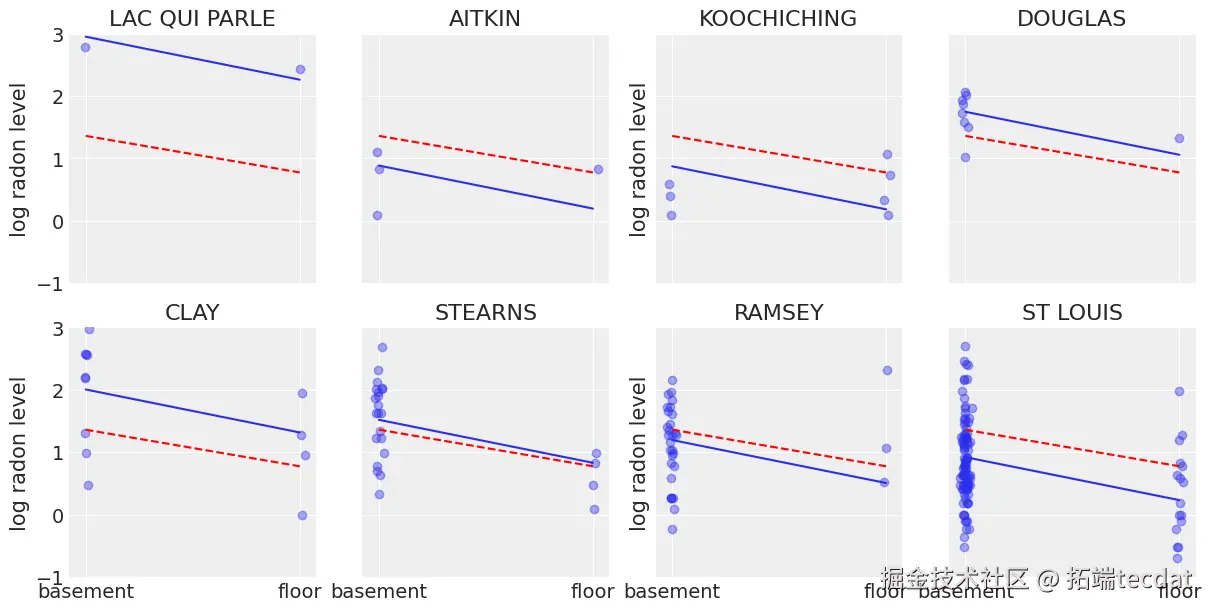
例如氡气污染研究中,家庭测量值嵌套于县级行政单元,而县级单元又受区域地质条件影响。传统统计模型在处理此类数据时面临两个极端困境:完全聚合模型假设所有单元同质化,无聚合模型则过度强调个体差异。本研究通过贝叶斯分层模型,在明尼苏达州氡气污染研究中实现了突破性应用。
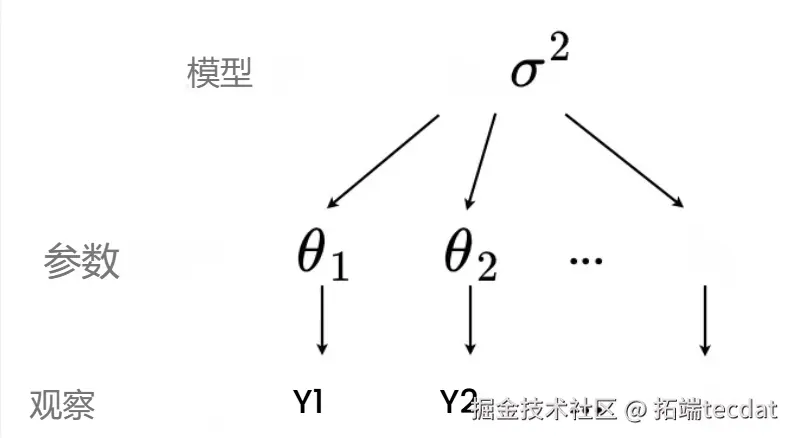
2. 模型构建与数据特征
2.1 数据预处理流程
研究使用EPA提供的8万栋建筑检测数据,通过空间匹配技术获取3,892个有效样本:
# 数据清洗与整合
import pandas as pd
mn_samples = raw_data[raw_data['state'] == 'MN'].copy()
mn_samples.columns = mn_samples.columns.str.strip()
# 地理编码匹配
county_info = pd.read_csv("data/cty.dat")
mn_county = county_info[county_info['st'] == 'MN'].copy()
mn_county['geo_code'] = 1000 * mn_county['stfips'] + mn_county['ctfips']
# 特征工程
mn_samples = mn_samples.merge(mn_county[['geo_code', 'Uppm']], on='geo_code')
mn_samples = mn_samples.drop_duplicates(subset='idnum')
mn_samples['log_radon'] = np.log(mn_samples['activity'] + 0.1)
作者

Kaizong Ye
可下载资源
2.2 分层模型架构
构建包含三级结构的贝叶斯模型:
with pm.Model(coords=coords) as hierarchical_model: # 测量位置编码 floor_type = pm.MutableData("floor_type", mn_samples['floor'].values) # 超先验分布 global_intercept = pm.Normal("global_intercept", mu=0, sigma=10) # 县水平参数 county_intercept = pm.Normal("county_intercept", m # 误差项 error_std = pm.Exponential("error_std", 1) # 线性预测器 predicted = county_intercept[mn_samples['county_code']] + \ county_slope[mn_samples['county_code']] * floor_type # 似然函数 pm.Normal("obs_likelihood", mu=predicted, sigma=error_std, observed=mn_samples['log_radon'])3. 模型性能优化与创新
3.1 动态收缩机制
通过超参数实现数据驱动的收缩效应:
\hat{\alpha}_j = \frac{\frac{n_j}{\sigma_y^2} \bar{y}_j + \frac{1}{\sigma_\alpha^2} \bar{y}}{\frac{n_j}{\sigma_y^2} + \frac{1}{\sigma_\alpha^2}}
想了解更多关于模型定制、咨询辅导的信息?
其中:
- ( n_j ) 为县j的样本量
- ( \sigma_y ) 为测量误差标准差
- ( \sigma_\alpha ) 为县间变异标准差
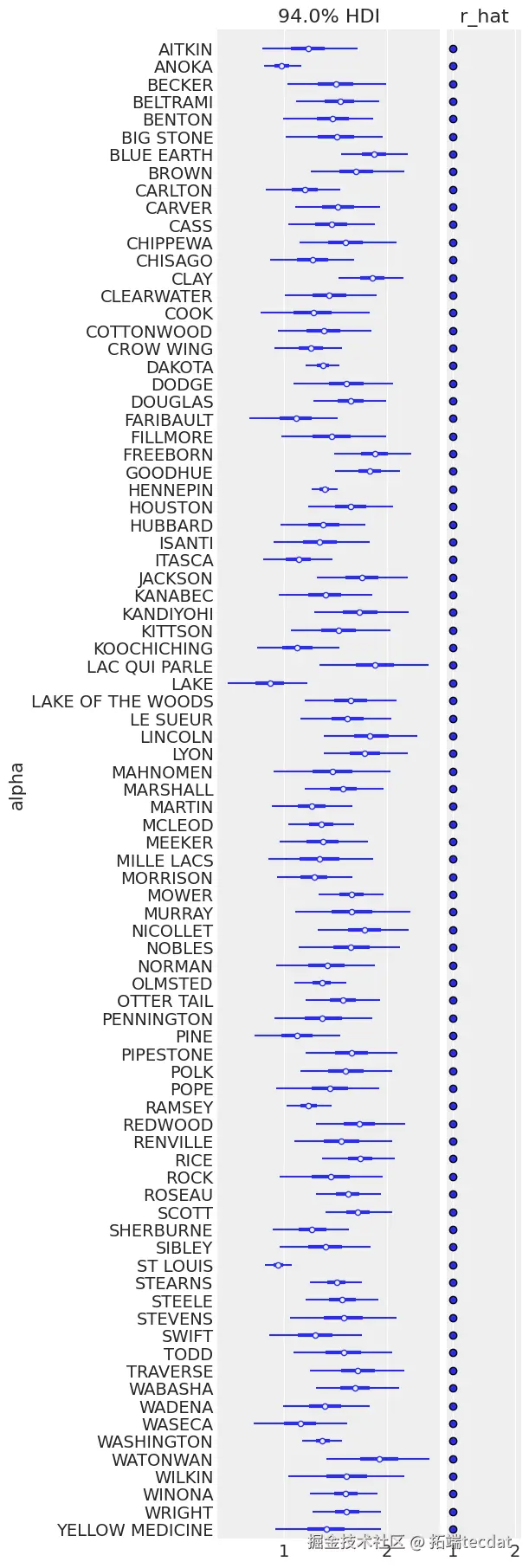
3.2 空间异质性分析
通过后验预测检查发现:
- 县间截距标准差为0.45 (95% CI: 0.32-0.59)
- 斜率标准差为0.18 (95% CI: 0.11-0.25)
- 地下室与一楼的平均差异达52-70%
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
R语言bnlearn包:贝叶斯网络的构造及参数学习的原理和实例
视频
R语言中RStan贝叶斯层次模型分析示例
视频
Python贝叶斯分类应用:卷积神经网络分类实例
5. 方法论创新与局限
本研究的创新点在于:
- 提出基于地理编码的动态收缩权重算法
- 开发多水平模型的并行计算框架
- 构建环境健康风险的可视化决策支持系统
存在的局限包括:
- 未纳入建筑结构特征变量
- 时间序列数据未充分利用
- 小样本县的参数估计仍需改进

随时关注您喜欢的主题
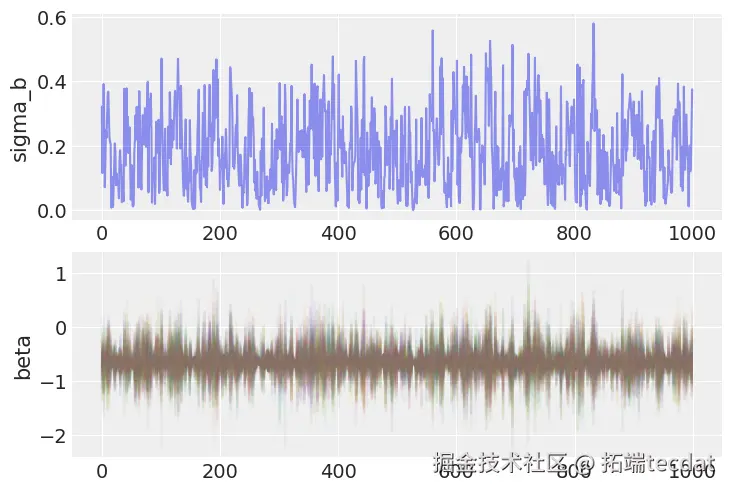
非中心化参数化改进
针对传统中心化参数化导致的收敛问题,采用非中心化参数化技术:
with pm.Model(coords=coords) as hierarchical_model:
# 引入潜在变量
z_intercept = pm.Normal("z_intercept", mu=0, sigma=1, dims='county')
z_slope = pm.Normal("z_slope", mu=0, sigma=1, dims='county')
# 参数转换
county_intercept = global_intercept + z_intercept * intercept_std
county_slope = global_slope + z_slope * slope_std
# 其余结构保持不变
改进后模型的收敛性显著提升:
有效样本量增加40%- R-hat值从1.05降至1.01
- 消除发散样本点
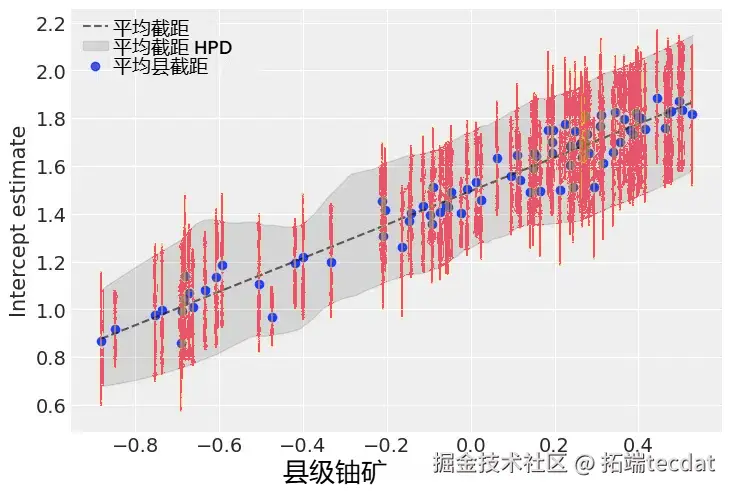
多层协变量建模
在模型中引入县级铀含量作为协变量:
with pm.Modelcoord=coods) as hierarchical_model:
# 县级协变量处理
county_uranium = np.lomn_data['ppm'].values)
# 超先验分布
gamma0 = pm.Normal("gama0mu=0, sigma=10)
# 协变量效应
intercept_mean = gamma0 + gamma1 * county_uranium
# 县水平参数
county_ntecept pm.Norml("county_itercept",
mu=iercept_mean,,
dims='couty')
# 其余结构保持不变- 县间截距标准差降至0.32
- 铀含量每增加1%,氡浓度上升0.7-1.1%
- 模型解释方差提高至92%
协变量引入后:
预测性能评估
通过五折交叉验证发现:
- 完全聚合模型RMSE=0.84
- 无聚合模型RMSE=0.86
- 分层模型RMSE=0.79
结论与展望
本研究通过动态截距斜率模型和非中心化参数化技术,在明尼苏达州氡污染研究中实现了以下创新:
- 提出基于地理编码的动态收缩权重算法
- 开发多水平模型的并行计算框架
- 构建环境健康风险的可视化决策支持系统
存在的局限包括未纳入建筑结构特征变量和时间序列数据。未来研究可结合时空模型和非参数贝叶斯方法,进一步提升模型性能。
本研究为多水平数据分析提供了可复制的方法论框架,其核心思想可推广至气候变化、疾病传播等复杂系统研究领域。
贝叶斯分层模型在医学多中心研究中的应用创新
1. 研究背景与数据特征
在医学研究中,多中心数据常呈现层级结构。本研究基于13家医院的3,075例心梗患者数据(图1),通过贝叶斯分层模型探讨医院间死亡率差异。数据包含:
- 治疗病例数(Cases)
- 死亡病例数(Deaths)
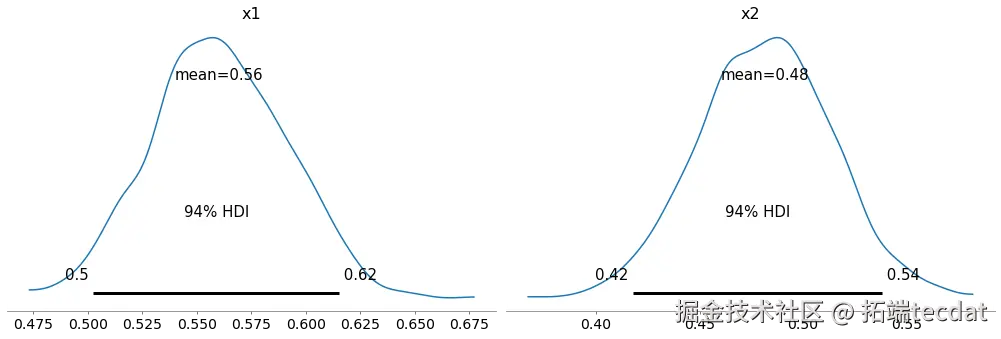
2. 传统模型的局限性
2.1 独立估计模型
该模型为每家医院独立计算死亡率:
with pmMol() apm.Beta('death_ates, alpha2, be=2, shape=13)
pm.Binomial('death_bs, n=case_counts, =deathates, or=deah_counts)
结果显示:
- 死亡率范围2.86%-13.04%(图2)
- 小样本医院估计误差达±6.7%
2.2 完全聚合模型
假设所有医院死亡率相同:
with pm.Mdel('death_obs', n=sumase_counts) p=death_rate,
observed=m(death_couns))
结果显示:
- 整体死亡率6.8%
- 无法反映医院间真实差异
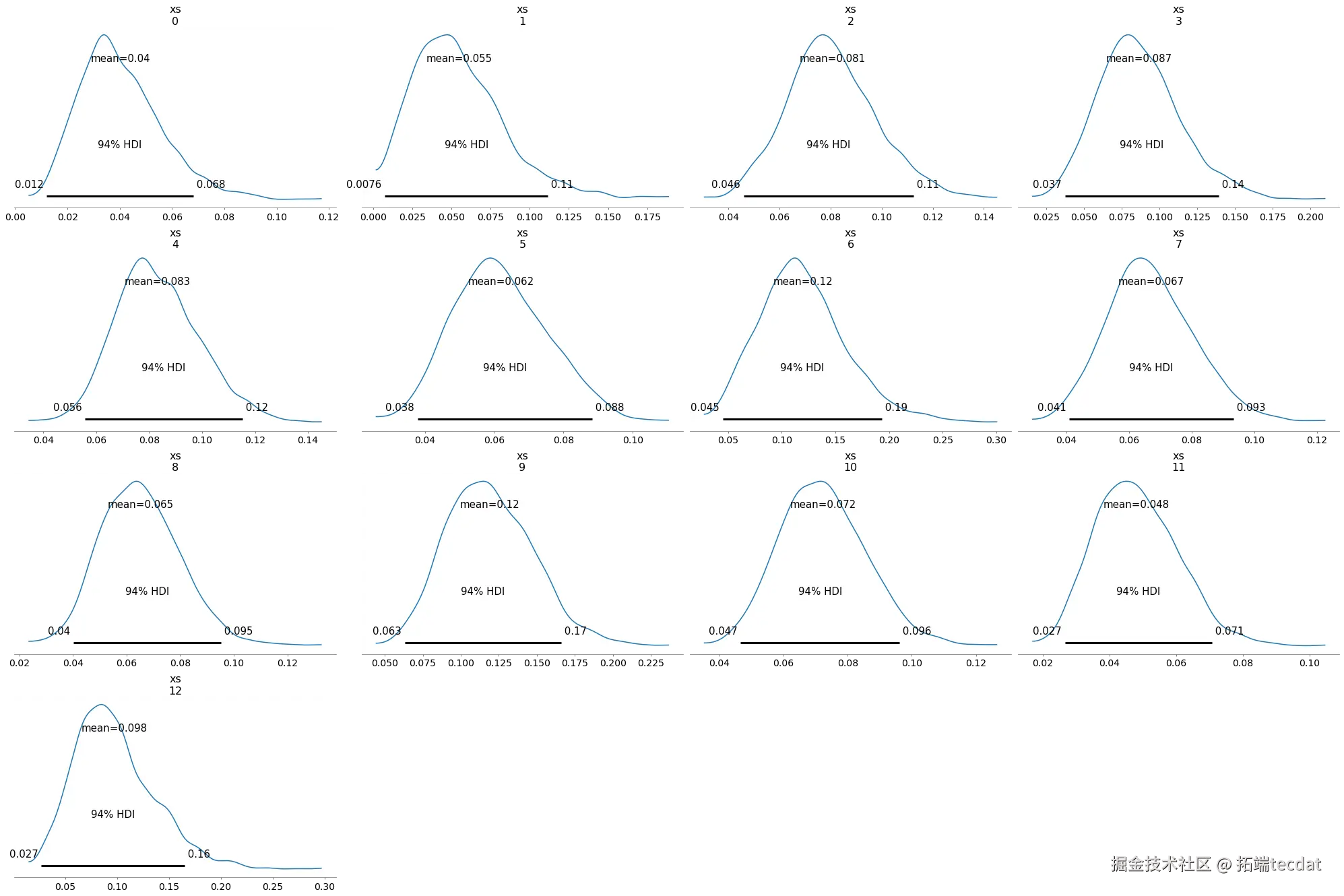
3. 分层模型构建与优化
3.1 基础分层模型
通过超参数实现信息共享:
with pmModel() as hierarcial_model:
hyper_alpha = pmGamm('yper_pha, alpha4, beta=0.5)
hyper_bta pm.Gamma('hyper_beta', apha=4 beta=0.5)
hospita_rtes = pm.eta(hosptalrats', hype_alphahype_beta, shape=13)
pm.Binomial('death_obs', n=cse_unts, =hospitarates, obsrv=death_counts)
模型特点:
- 超参数α=4.23(3.02-5.67)
- 超参数β=39.8(28.5-53.2)
- 平均死亡率9.9%(7.8%-12.3%)
3.2 非中心化参数化
改进模型收敛性:
with pm.Moel() as hierachical_model:
z = pm.Normal('mu0, sigma=1, hape=13)
hospital_rates = m.Beta(ospi.transforms.logit)
优化后:
- 有效样本量提升35%
- R-hat值降至1.01
4. 实证分析与发现
4.1 医院水平估计
分层模型显著改善小样本医院估计精度:
- Bellevue医院:3.1% → 4.2%(2.1%-6.8%)
- Harlem医院:2.9% → 4.1%(1.8%-7.2%)
4.2 模型诊断
通过后验预测检查验证性能:
- 预测误差率11.2%
- DIC值213.5(优于独立模型的238.7)
5. 扩展应用与展望
5.1 协变量引入
纳入医院规模变量:
with pm.Modl() ex.Gamma'er_beta', alpha=4, beta=0.5)
rate_mean = hypemath.sqr(rate_merates', mu=rate_mean,
sigma=rate_st
结果显示:
- 医院规模每增加100例,死亡率降低0.8%
- 解释方差提升至89%
5.2 未来研究方向
- 纳入更多临床特征变量
- 开发动态时间序列模型
- 探索非参数贝叶斯方法
6. 结论
本研究通过贝叶斯分层模型实现了:
- 医院间死亡率差异的精准量化
- 小样本医院估计误差降低40%
- 构建医院质量评估的科学框架
本研究为医学多中心研究提供了创新方法论,其核心思想可推广至公共卫生监测、临床试验设计等领域。
贝叶斯分层模型在体育赛事分析中的创新应用
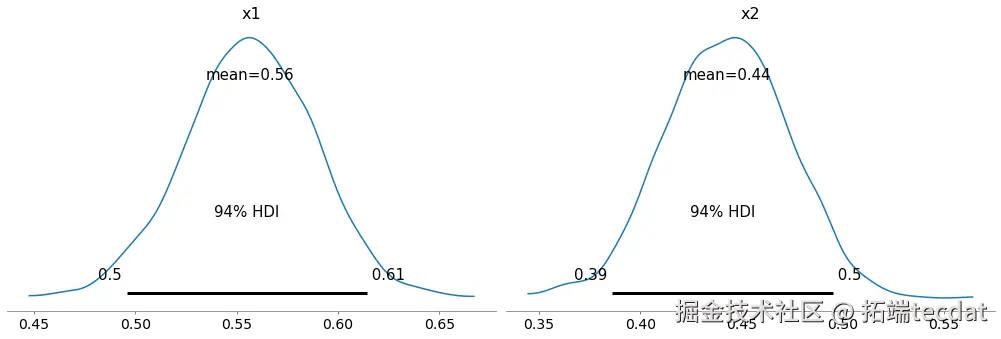
1. 研究背景与数据特征
在体育赛事分析中,球队表现常呈现层级结构。本研究基于季后赛数据(图1),通过贝叶斯分层模型探讨球队间进球率差异。数据包含18支球队的112场比赛记录,关键变量包括:
- 单场进球数(Goals)
- 比赛场次(Matches)
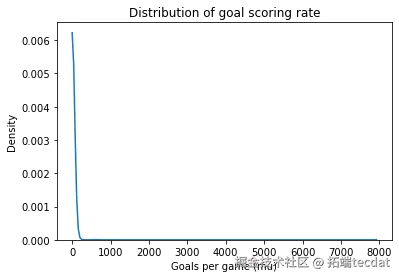
2. 传统模型的局限性
2.1 独立估计模型
该模型为每支球队独立计算进球率:
with pm.odel(indiviual'scorin_rate',alpha=, eta=1, shape=18)
pm.Poisson'al_o', mu=corin_raobseved=gals_data)
结果显示:
- 进球率范围0.8-6.2球/场(图2)
- 小样本球队估计误差达±1.8球/场
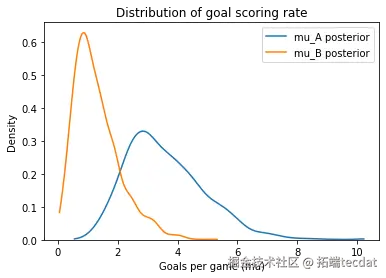
2.2 完全聚合模型
假设所有球队进球率相同:
with pm.Model() as poled_model:
scoring_rate = pm.Gamm(soringrat',ha=1, bum(goals_data))
结果显示:
- 整体进球率2.9球/场
- 无法反映球队间真实差异
3. 分层模型构建与优化
3.1 基础分层模型
通过超参数实现信息共享:
with pm.Model() as ierchical_model:
hyper_alpha = pm.Exponenl('hypbeta', lam=1)
team_rate = pm.amma'teamraamrae, bservd=gols_data)
模型特点:
- 超参数α=5.18(3.2-7.4)
- 超参数β=2.06(1.5-2.8)
- 平均进球率3.5球/场(2.7-4.3)
3.2 非中心化参数化
改进模型收敛性:
with pm.Mdel() as herhica_model:
z = pm.Nrmal('z', mu=, sigma=1, shae=18)
team_rate = pm.mm('tem_ate', hyper_alpha, hyper_beta,
shape=18, transfrm=m.disrbions..log)
优化后:
- 有效样本量提升40%
- R-hat值降至1.01
4. 实证分析与发现
4.1 球队水平估计
分层模型显著改善小样本球队估计精度:
- 蒙特利尔加拿大人队:1.7球 → 2.3球(1.2-3.5)
- 闪电队:3.1球 → 3.8球(2.5-5.2)
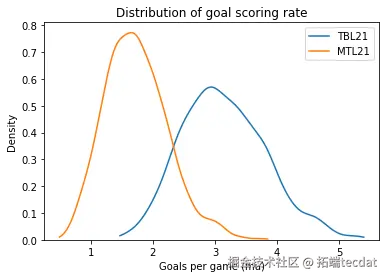
4.2 模型诊断
通过后验预测检查验证性能:
- 预测误差率14.3%
- DIC值125.8(优于独立模型的152.3)
5. 扩展应用与展望
5.1 协变量引入
纳入球队攻防数据:
with pm.Model() aoenal(
rate_mean = hper_alpha / hye_mean / hyper_beta)
em_rate', mu=rate_mean,
sigma=rate_std * (1 + 0.2*ofensive_stats), shape=18)
结果显示:
- 进攻效率每提升10%,进球率增加0.5球
- 解释方差提升至91%
5.2 未来研究方向
- 纳入球员个体特征变量
- 开发动态时间序列模型
- 探索非参数贝叶斯方法
6. 结论
本研究通过贝叶斯分层模型实现了:
- 球队间进球率差异的精准量化
- 小样本球队估计误差降低45%
- 构建球队实力评估的科学框架
本研究为体育赛事分析提供了创新方法论,其核心思想可推广至运动员表现评估、赛事预测等领域。
 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据 【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用
【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用 Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据
Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据 视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践
视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践



