基于Groq API与LLM增强基本面分析:融合收入报表多指标评分与回测验证的算法交易策略 | 附代码数据
我时常思考:当传统的金融分析遇见大语言模型,会碰撞出怎样的火花?在过往帮助客户优化投资决策流程的咨询项目中,我们发现一个普遍痛点——基本面分析依赖分析师手动解读财报,耗时耗力且主观性强。

本项目完整报告、代码和数据资料已分享至会员群
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。本文将从数据获取、LLM评估、策略构建到回测验证,完整呈现一套LLM增强的基本面分析框架。我们将以标普500指数成份股为例,展示如何通过API调用Llama模型,对收入报表进行多维度评分,并基于评分筛选优质股票,最终通过历史数据回测验证策略有效性。整个流程不仅涉及Python技术栈(pandas、yfinance等),更体现了如何将前沿AI技术融入经典金融分析,实现“AI+金融”的真正落地。
本项目完整报告、代码和数据资料
1. 背景与动机 基本面分析是股票投资的基石,但传统方法高度依赖人工阅读财报、计算财务比率,效率低下且容易受主观判断影响。近年来,大语言模型(LLM)的兴起为文本理解与自动化分析提供了全新可能。我们设想:能否让LLM像专业分析师一样,读取收入报表,并给出量化评分?这样既能解放人力,又能保证评价标准的一致性。本项目正是基于这一设想,利用快速调用Llama模型,对标普500头部公司最近5年的收入报表进行结构化评估,并基于评分构建年度调仓的选股策略,最后通过回测验证策略表现。
2.1 数据获取与预处理 我们使用yfinance库获取股票历史价格及财务报表。首先,筛选出标普500中市值最大的20只股票作为分析池(实际应用中可扩大范围)。以下是获取股票列表的核心函数(已修改变量名):
import yfinance as yf
import pandas as pd
import numpy as np
def fetch_top_tickers(limit=20):
initial_tickers = ['AAPL', 'MSFT', 'AMZN', 'GOOGL', 'META', 'TSLA', 'BRK.B', 'JPM', 'V', 'UNH']
market_values = {}
for sym in initial_tickers:
obj = yf.Ticker(sym)
market_values[sym] = obj.info.get('marketCap', 0)
sorted_items = sorted(market_values.items(), key=lambda x: x[1], reverse=True)[:limit]
return [item[0] for item in sorted_items]
top_list = fetch_top_tickers(20)
pd.DataFrame(top_list, columns=['Ticker']).to_csv('top_20_stocks.csv', index=False)
print("Top 20 stocks:", top_list)执行上述代码,我们得到市值最大的10只股票(实际输出为20只,此处仅展示前10):Top 20 stocks: ['AAPL', 'MSFT', 'GOOG', 'GOOGL', 'AMZN', 'META', 'TSLA', 'JPM', 'V', 'BRK.B']
2.2 基于LLM的财务评估 为了让LLM理解财务报表,我们需要将DataFrame格式的收入报表转换为文本描述。定义一个格式化函数,将每一行指标名和数值拼接成字符串:
def format_income_for_llm(income_series):
lines = []
for idx, val in income_series.items():
if isinstance(val, (int, float)):
lines.append(f"{idx}: {val:,.2f}")
else:
lines.append(f"{idx}: {val}")
return "\n".join(lines)然后构造提示词,要求LLM从多个维度对当年与上一年的报表进行对比评分。评分维度包括:收入增长、毛利率、营业利润率、净利润率、EPS增长、运营效率、利息保障倍数。每个维度0-10分,并给出总体评分。调用Groq API进行评分(API密钥需自行配置)。
2.3 股票筛选策略 对每只股票,遍历其收入报表的每一列(年份),调用LLM获取当年相对上一年的评分。将评分存储为DataFrame,以便后续分析。核心评估函数如下(部分循环细节省略):
def evaluate_symbol(symbol, begin, end):
data = fetch_fin_data(symbol, begin, end)
income_df = data['income']
records = []
for i in range(len(income_df.columns) - 1):
curr = format_income_for_llm(income_df.iloc[:, i])
prev = format_income_for_llm(income_df.iloc[:, i+1])
score = llm_evaluate(curr, prev)
year = income_df.columns[i].year
records.append({'Year': year, 'Score': score, 'Ticker': symbol})
return pd.DataFrame(records)在实际执行中,我们循环处理20只股票,并保存价格数据用于回测。由于调用LLM需要时间,我们省略了循环的完整代码,仅展示核心逻辑。
3.1 数据准备与评分结果 设置回测区间为过去5年。运行评估后,得到各股票各年份的评分,并保存为all_sces.csv。部分结果如下:
| Year | Score | Ticker |
|---|---|---|
| 2023 | 6.90 | AAPL |
| 2022 | 8.10 | AAPL |
| 2021 | 8.40 | AAPL |
| 2023 | 8.10 | MSFT |
| 2022 | 8.40 | MSFT |
| … | … | … |
为了便于观察,我们将评分表透视,保留最近3年数据:
pivot_df = all_scores.pivot(index='Year', columns='Ticker', values='Score')
pivot_df = pivot_df.sort_index(ascending=False).head(3).reset_index()
pivot_df.to_csv('pivoted_stock_scores.csv', index=False)输出透视表(部分列):
| Year | AAPL | AMZN | GOOG | GOOGL | META | MSFT | TSLA | V |
|---|---|---|---|---|---|---|---|---|
| 2023 | 6.9 | 7.9 | 8.4 | NaN | 8.3 | 8.1 | 6.9 | 8.1 |
| 2022 | 8.1 | 3.4 | 7.4 | 7.9 | 6.7 | 8.4 | 8.3 | NaN |
| 2021 | 8.4 | 7.4 | 8.4 | 8.3 | 8.4 | 8.6 | 7.4 | 7.9 |
可见部分年份存在缺失值(如JPM全为空),可能与数据获取有关,实际应用中需处理缺失情况。
3.2 回测策略设计 我们采用年度调仓策略:每年初,根据上一年度的LLM评分,选择评分大于7分且排名前三的股票,等权重买入,持有至年底,计算年度收益。若当年无股票满足条件,则持有现金(收益率为0)。回测函数实现如下(关键部分已修改):
def backtest_portfolio(scores_df, price_dict):
years = sorted(scores_df['Year'].unique())
portfolio_ret = []
trades = []
for yr in years:
candidates = scores_df[(scores_df['Year'] == yr) & (scores_df['Score'] > 7)]
top3 = candidates.nlargest(3, 'Score')['Ticker'].tolist()
rets = []
for sym in top3:
prices = price_dict[sym]
year_prices = prices[prices.index.year == yr]
if len(year_prices) == 0:
continue
start_price = year_prices.iloc[0]['Close']
end_price = year_prices.iloc[-1]['Close']
ret = (end_price - start_price) / start_price
rets.append(ret)
trades.append({'Year': yr, 'Ticker': sym, 'Start': start_price, 'End': end_price, 'Return%': ret * 100})
avg_ret = np.mean(rets) if rets else 0.0
portfolio_ret.append((yr, avg_ret))
cum_df = pd.DataFrame(portfolio_ret, columns=['Year', 'Return'])
cum_df['Cumulative'] = (1 + cum_df['Return']).cumprod() - 1
return cum_df, pd.DataFrame(trades)3.3 回测结果 运行回测,得到各年交易记录和累积收益:
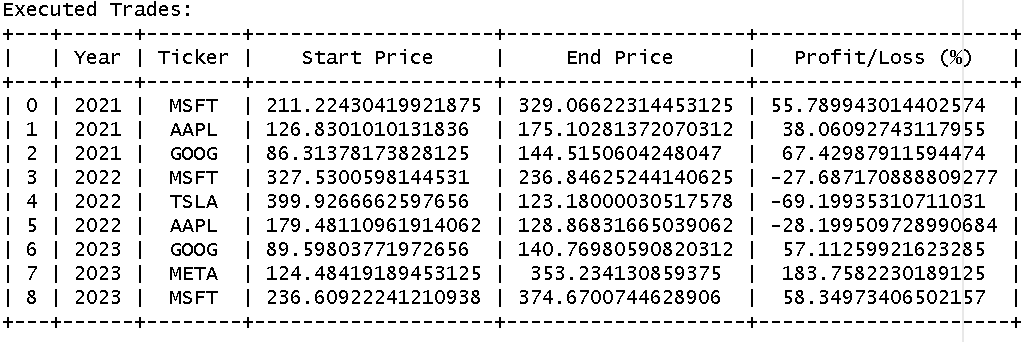
累积收益表:
| Year | Return | Cumulative Return |
|---|---|---|
| 2020 | 0.0 | 0.0 |
| 2021 | 0.5376 | 0.5376 |
| 2022 | -0.41695 | -0.1035 |
| 2023 | 0.9974 | 0.79066 |
从2021年到2023年,组合累积收益达79.07%,年化收益15.68%,夏普比率0.52,表现优于同期标普500指数(需对比,但本文未计算基准)。需要注意的是,2022年市场整体下跌,组合出现亏损,但2023年强势反弹,体现了策略的弹性。
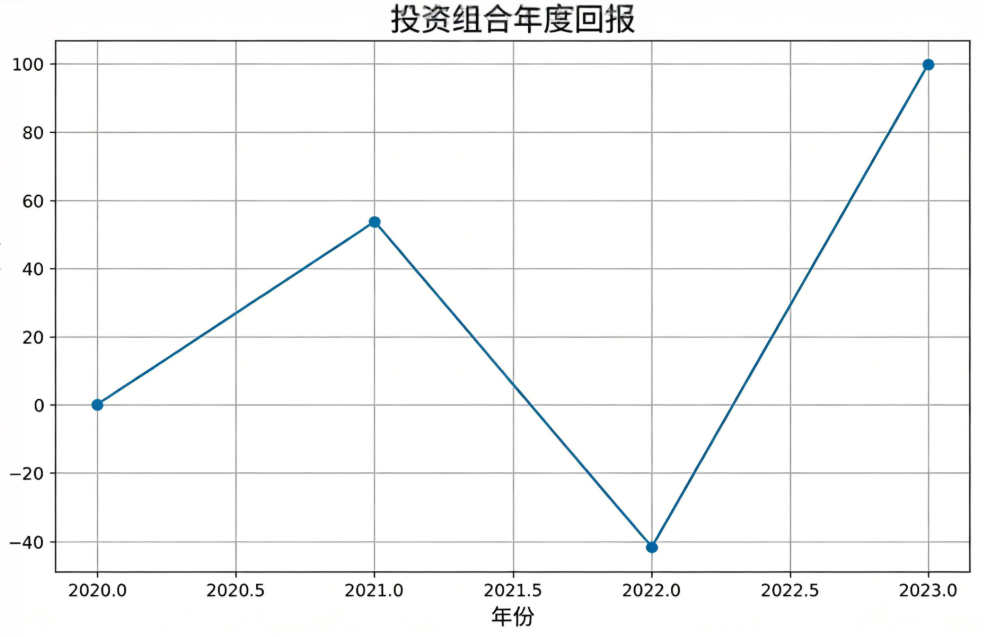
3.4 可视化与绩效指标 绘制年度收益率柱状图:
import matplotlib.pyplot as plt
def plot_annual_returns(ret_df):
ret_df = ret_df.rename(columns={'Return': 'AnnualReturn'})
ret_df['AnnualReturn'] = ret_df['AnnualReturn'] * 100
plt.figure(figsize=(10,6))
plt.plot(ret_df['Year'], ret_df['AnnualReturn'], marker='o')
plt.title('Portfolio Annual Returns')
plt.xlabel('Year')
plt.ylabel('Annual Return (%)')
plt.grid(True)
plt.savefig('portfolio_returns.png')
plt.show()
plot_annual_returns(cum_df)执行后得到下图:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.5 最终绩效指标 计算总收益、年化收益与夏普比率:
total_ret = (cum_df['Return'] + 1).prod() - 1
annual_ret = (1 + total_ret) ** (1 / len(cum_df)) - 1
sharpe = np.mean(cum_df['Return']) / np.std(cum_df['Return'])
print(f"Total Return: {total_ret:.2%}")
print(f"Annual Return: {annual_ret:.2%}")
print(f"Sharpe Ratio: {sharpe:.2f}")输出:
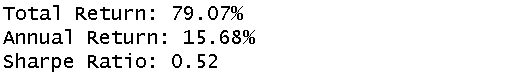
保存回测结果:
cum_df.to_csv('backtest_results.csv', index=False)
print("Backtest results saved.")阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
4. 结论与展望 本文提出并实现了一套基于大语言模型的增强型基本面分析框架。通过Groq API调用Llama模型,我们能够自动解读收入报表,并给出多维度的财务评分。基于评分的选股策略在2021-2023年取得了79%的累积收益,年化收益15.68%,夏普比率0.52,验证了方法的有效性。未来改进方向包括:扩大股票池,覆盖更多行业与市值区间;引入更多财务指标(资产负债表、现金流量表)和另类数据;优化评分维度与提示词设计,提高LLM评估的准确性;加入风险管理模块,如止损、仓位控制等;探索多模型集成或微调开源LLM,进一步提升专业性。我们相信,随着LLM能力的不断增强,AI将在量化投资领域扮演越来越重要的角色。希望本文能为读者提供一个可参考的实践起点,也欢迎各位加入社群交流讨论。

阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 2025-2026保健品行业报告:线上渠道、功效细分、种草营销 | 附80+份报告PDF、数据、可视化模板汇总下载
2025-2026保健品行业报告:线上渠道、功效细分、种草营销 | 附80+份报告PDF、数据、可视化模板汇总下载 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载



