最新研究表明,中国有超过7亿人在观看在线视频内容。
Bilibili,被称为哔哩哔哩或简称为B站,是中国大陆第二个弹幕视频网站,最大的年轻人潮流文化娱乐社区。
截至2020年3月31日的第一季度它已经拥有超过1.7亿的月度用户,反映了许多人认为的该行业令人眼花缭乱的未来。
网络,数学上称为图,最早研究始于1736年欧拉的哥尼斯堡七桥问题,但是之后关于图的研究发展缓慢,直到1936年,才有了第一本关于图论研究的著作。20世纪60年代,两位匈牙利数学家Erdos和Renyi建立了随机图理论,被公认为是在数学上开创了复杂网络理论的系统性研究。之后的40年里,人们一直讲随机图理论作为复杂网络研究的基本理论。然而,绝大多数的实际网络并不是完全随机的。1998年,Watts及其导师Strogatz在Nature上的文章《Collective Dynamics of Small-world Networks》揭示了复杂网络的小世界性质。随后,1999年,Barabasi及其博士生Albert在Science上的文章《Emergence of Scaling in Random Networks》又揭示了复杂网络的无标度性质(度分布为幂律分布),从此开启了复杂网络研究的新纪元。
随着研究的深入,越来越多关于复杂网络的性质被发掘出来,其中很重要的一项研究是2002年Girvan和Newman在PNAS上的一篇文章《Community structure in social and biological networks》,指出复杂网络中普遍存在着聚类特性,每一个类称之为一个社团(community),并提出了一个发现这些社团的算法。从此,热门对复杂网络中的社团发现问题进行了大量研究,产生了大量的算法,本文试图简单整理一下复杂网络中聚类算法,希望对希望快速了解这一部分的人有所帮助。本文中所谓的社团跟通常我们将的聚类算法中类(cluster)的概念是一致的。
0. 预备知识
为了本文的完整性,我们首先给出一些基本概念。
一个图通常表示为G=(V,E),其中V表示点集合,E表示边集合,通常我们用n表示图的节点数,m表示边数。一个图中,与一个点的相关联的边的数量称为该点的度。对于一个图,图中所有点的度的和恰好等于边数的两倍。图通常用邻接矩阵A表示,邻接矩阵的(i,j)位置元素是1表示点i到点j右边,0表示无边。
本文中我们会用到随机图的概念,所谓随机图,就是指一个图中任何两个点之间连边的概率相等。首先确定n个点,然后以固定概率p去给图中的一对顶点连边,就形成了一个随机图。在研究中,随机图通常用来作为一个null model来与实际网络进行比较,从而得出一些性质结论。
研究社团的划分,一个需要解决的问题是,如何来衡量一个社团的划分的好坏?一个比较简单直观的原则是使得社区内部的边尽可能地多,社区之间的边间可能地少。另外一个稍微复杂点但是更为常用的度量是Newman等人提出的模块度(modularity)的概念,基本的想法是这样的:我们假设在随机图中是不存在这种社团结构的,将实际网络跟其相应的随机网络进行比较,如果一个网络跟随机网络之间的差异越大,表示社团结构越明显。这样,我们对划分后的每一个子网络计算一个“密度”,然后计算该子网络随机情况下的“密度”,这两个“密度”存在一个差值,表示了该子网络偏离随机情况的一种程度,并且这个值越大表示这个子网络相对随机网络越稠密。一个网络中包含的所有子网络的这个差值加到一起的和就是这个复杂网络的模块度,数学公式表示如下:
其中Aij表示图的邻接矩阵,ki 表示点i 的度,m是图的边数,ki*kj/2m表示点 i 和点 j之间边的期望。进一步将模块度可以化为等式右边的形式,nc是社团的总个数,lc是社团c内的边数,dc是社团内的点的度数之和 (note: 社团内的每一个点可能跟本社团内部的点有边,也可能有跟其他社团点连边,故通常 dc> lc)

有了这些知识,我们来看一下复杂网络社团划分的各种算法吧。
1. 图的剖分
把一个网络划分成多个社团就是把一个图剖分成多个图,图的剖分问题是图论中一个比较难的问题,也是研究比较多的问题,理论上是NP-hard的。因此,人们通常研究比较简单的情况:图的二剖分,即把一个图分成两个(一般要求大小相等)的图,比较有名的算法是Kernighan-Lin 算法和谱平分法。
1.1 Kernighan-Lin 算法[1]
思想:不断交换两个子图中的点,使得两个子图之间的边尽可能地少
定义增益函数: Q=两个社团内的边数-社团之间的边数
算法步骤:
Step1 随机划分为已知大小的两个社团
Step2 从两个社团各取一个点,尝试交换并计算ΔQ = Q交换后-Q交换前,选择使ΔQ最大的一对节点对交换
Step3 规定每个节点只能交换一次,对剩余节点重复step2, 直到 ΔQ <0,或者某个子图的所有节点都被交换了一次为止。
Step4 允许每个节点的第二次交换,开始新一轮迭代,直到没有节点对可以交换
1.2 谱平分法
所谓“谱”,就是矩阵的特征值;所谓“平分”,就是将一个图分成大小相等的两个子图。谱平分法就是利用图的拉普拉斯矩阵的第二小特征向量来进行聚类的一种方法。 这里暂且先放一下,下面介绍完谱算法之后再回头具体介绍谱平分法。
1.3 总结
图的剖分常常需要制定子图的个数(否则,整体作为一个),甚至每个子图的大小(否则,常常会将一个点分为一个子图)。但是如果已知一个图就是两个社团组成,谱评分法往往可以得到很好的效果。
2. 凝聚法
这是一大类算法,总体思想是寻找社团“最中心”的边,不断地把最相似的两个点聚到一起,从点聚到小社团,再聚成大社团。根据定义两个点的相似性的不同,产生了很多不同的算法。有的算法并不直接计算相似性,而是看两个点合并到一起后模块度的变化情况,根据变化的大小来选择需要合并的两个点。比较有代表性的算法是Newman在2004年的一个算法[2]
2.1 Newman算法
思想:不断地选择是模块度增长最大的两个社团进行合并
算法步骤:
Step1. 每个点当作一个社团
Step2. 计算两个社团合并后模块度的变化(增长) ΔQ,选取使得ΔQ最大的两个社团进行合并
Step3. 重复step2直到最后合并为一个社团
2.2 Newman算法的优化
Newman算法复杂性是O((m+n)n),Clause,Newman和Moore利用最大堆将该算法复杂度降低为O(n(logn)^2)[3]
对于该算法, 人们想出了很多改进措施,例如以下两个策略:
1. multistep贪婪算法:每次迭代合并多个社团
2. 归一化ΔQ,消除社团大小的影响
2.3 总结
凝聚法优点是简单,限制少,不需要预先指定社团个数,可以发现社团的层次关系。缺点是缺乏全局目标函数; 两个点一旦合并,就永远在一个社团中了,无法撤消;另外,这种算法往往对单个的点比较敏感
3. 分裂法
分裂法的基本思想是找出最有可能位于社团之间的边,把这些边去掉,就自然产生了不同的社团。代表性的算法是Girvan 和Newman在2002年的一个算法 [4].
3.1 GN 算法[4]
首先给出介数(etweenness)的定义,一个边的介数(edge betweenness)是指通过该边的最短路的条数。
直观上,社团之间的边有较高的betweenness,而社团内部的边betweenness相对较小,这样,通过逐个去掉这些高betweenness的边,社团结构就会逐步显现出来。
算法步骤:
Step1. 计算每条边的介数 (O(nm) with BFS)
Step2. 去掉具有最高介数的边
Step3. 如果满足了社团划分的要求, stop; 否则, 转step1.
利用各种其他度量(如边聚类系数等)来代替边介数,该算法也产生了各种各样的变种。
3.2 其他分裂方法
分裂法还有很多,如MST,JP算法等等,在此就不一一描述了。
3.3 总结
凝聚法跟分裂法是对应的,一个自下而上,一个自上而下,一个不断把点连在一起,一个不断去边把点分开。分裂法的优缺点跟凝聚法类似。
4. 谱算法
首先给出一个概念——图的Laplacian 矩阵(L-矩阵)。设A为图的邻接矩阵; D为一个对角阵(对角元素为点 i 的度),则图的Laplacian矩阵L=D-A。关于L-矩阵,有很多性质,如:(1) 矩阵的每一行的元素之和为0 ,由此可以知道该矩阵至少一个0特征值,并且0特征值对应的特征向量为全1向量(1,1,…,1)。(2)0 特征向量的个数与连通分支的个数相同;如果一个图是连通的,那么其Laplacian矩阵只有一个0特征值,其余特征值都是正的。(3)不同特征值的特征向量正交的。
所谓谱,就是指矩阵的特征值。谱算法就是利用邻接矩阵或者拉普拉斯矩阵的特征向量,将点投影到一个新的空间,在新的空间用传统的聚类方法(如k-means)来聚类。
谱算法的一般步骤是:
Step1. 计算相似矩阵(如邻接矩阵A)的前 s 个特征向量
Step2. 令 U 是一个 n× s 矩阵,每一列是一个特征向量
Step3. U 的第 i 行作为点 i 的坐标,用层次聚类法或者k-means等得到最终的社团
需要说明一点是: 如果是计算邻接矩阵的特征值,一般取最大的s个特征值;如果是计算Laplacian矩阵的特征值,则是计算最小的(除0外)s个特征值。
前面我们提到过谱平分法,就是利用Laplacian矩阵倒数第二个小的特征值对应的特征向量(称为Fiedler 向量)来聚类的。因为需要把一个图平分成两个子图,因此就把Fiedler向量中正的分量对应的点分成一类,负的分量对应的点分成另一类。
谱算法的计算瓶颈是计算矩阵的特征值,因为少数的几个特征向量就可以得到很好的聚类,所以只需要计算最大的几个特征值既可以,可以考虑用Lanczos method。
5. 矩阵分解
谱算法的实质是矩阵分解,其他的矩阵分解方法还有SVD 和 NMF 等,矩阵分解的整体思想就是把点从一个空间映射到另一个空间,在新的空间利用传统的聚类方法来聚类。
6. 标签传播算法
标签传播(Label propagation)算法是由Zhu X J于2002年提出[5],它是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。2007年,Raghavan U N等最早提出将LPA最早应用于社区发现,该算法被简称为RAK算法[6]
思想: 每个节点赋予一个标签标志着其所在社区,每次迭代,每个节点标签根据其大多数邻近节点的标签而修改,收敛后具有相同标签的节点属于同一个社区。
算法步骤:
Step1 给每一个节点随机生成一个标签
Step2 随机生成一个所有节点的顺序,按照该顺序将每一个节点的标签修改为其大多数邻居节点的标签。
Step3 重复step2,直到每个节点的标签都不再变化,具有相同标签的节点组成了一个社区。
7. 随机游走
随机游走: 从一个顶点向下一个顶点移动时,以相等的概率来选择当前顶点的一个邻居作为下一个顶点。
基本思想: 社团时相对比较稠密的子图,因此在图中进行随机游走时很容易“陷入”一个社团中。
随机游走的过程构成了一个Markov链。图中每一个顶点对应一种状态;不同状态之间的转移概率为
t 步随机游走从 i 到 j 的概率是 Pij 的t次幂

下面我们介绍一个代表性的随机游走算法,叫做Walktrap 算法[7]
Walktrap 算法
定义如下距离:
顶点 i 和 j 的距离:
社团C到点j的距离:
社团C1到C2的距离: 


算法步骤:
Step1 每一个点当做一个社区,计算相邻的点(社团)之间的距离
Step2 选取使得下式最小的两个社团C1和C2 合并为一个社团,
重复这一步骤直到所有点合并为一个社团。

标签传播算法尽管速度快,但是效果并不太理想。
8. Louvain (BGLL) 算法
Louvain (BGLL) 算法[8]是一个基于模块度最优化的启发式算法,算法两层迭代,外层的迭代是自下而上的凝聚法,内层的迭代是凝聚法加上交换策略,避免了单纯凝聚方法的一个很大的缺点(两个节点一旦合并,就没法再分开)。
算法步骤:
Step1 每一个点初始时被看作一个社团, 按一定次序依次遍历每一个顶点. 对每一个顶点i ,考虑将 i 移至其邻居顶点 j 的社团中模块度的变化ΔQ 。如果 ΔQ>0,将 顶点i 移至使得ΔQ变化最大的顶点的社团中; 否则,顶点 i 保持不动。重复这个过程,直到任何顶点的移动都不能使模块度增大。
Step2 将step1得到的每一个社团看作一个新的顶点,开始新的一轮迭代,直到模块度不再变化。
该算法简单、直观,容易实现;速度快,并且效果也很好。综合效率和效果两方面考虑,该算法应该是目前最好的方法之一。
9.Canopy算法 + K-Means
9.1 Canopy算法
思想:选择计算代价较低的方法计算相似性,将相似的对象放在一个子集中,这个子集被叫做Canopy,不同Canopy之间可以是重叠的
算法步骤:
Step1 设点集为 S,预设两个距离阈值 T1和 T2(T1>T2);
Step2 从S中任选一个点P,用低成本方法快速计算点P与所有Canopy之间的距离,将点P加入到距离在T1以内的Canopy中;如果不存在这样的Canopy,则把点P作为一个新的Canopy的中心,并与点P距离在 T2 以内的点去掉;
Step3 重复step2, 直到 S 为空为止。
该算法精度低,但是速度快,常常作为“粗”聚类,得到一个k值,再用k-means进一步聚类,不属于同一Canopy 的对象之间不进行相似性计算。
9.2 K-Means
K-Means大家都比较熟悉,基本思想是首先找各个社团的“中心点”, 然后就近分配每个顶点
算法步骤:选取k个点作为 k个社团的初始中心点
Step1. 把每个点分配到最近的中心点所在的社团;
Step2. 重新计算中心点,如果中心点不变, stop; 否则, 转 step1.
K-Means算法计算量相对比较大,效果往往还不错,但是使用前要考虑一点:通过各个分量求平均得到的中心点是否有意义, 也就是说在你的问题中欧式距离是否有意义。
10. 基于密度的快速聚类
今年science上有一篇关于聚类的文章[9],提出一种快速的聚类方法,基本思想是: 找出每个类的中心点,将剩余的点按一定策略分配到每个类中。思想很简单,但是文中找每个类中心点的做法还是很有新意的。
算法步骤
Step1 对每一个点i,计算两个量:点i的密度 
Step2 选取
Step3 对于剩余的非中心点,分配给离它最近且密度比它高的邻点所坐在的社团

参考文献
[1].Kernighan & Lin ,An efficient heuristic procedure for partitioning graphs. Bell System Technical Journal 49: 291–307,1970.
[2] Newman. Fast Algorithm for Detecting Community Structure in Networks. Phy.Rev.E, 2004.
[3] Clauset et al. Finding community structure in very large networks, Phy.Rev.E, 2004.
[4] Girvan& Newman,Community structure in social and biological networks, PNAS, 2002
[5] Zhu et al . Learning From Labeled and Unlabeled Data With Label Propagation, Technical Report, CMU-CALD-02-107,2002
[6] Raghavan et al. Near linear time algorithm to detect community structures in large-scale networks, Phy.Rev.E., 2007.
[7] P. Pons et al. Computing communities in large networks using random walks. Journal of Graph Algorithms and Applications,2006.
[8] Vincent D. Blondel et al, Fast Unfolding of Communities in Large Networks, Phy.Rev.E, 2008
[9] Rodriguez & Laio, Clustering by fast search and find of density peaks. Science.2014
热门话题和分区
B站用户日渐成熟,二次元、和游戏成为主流分区;视频量排名前三的分别是生活类、游戏类。其中动画类的分区大多和鬼畜、动漫热门话题相关,这是B站的特色。
图表1
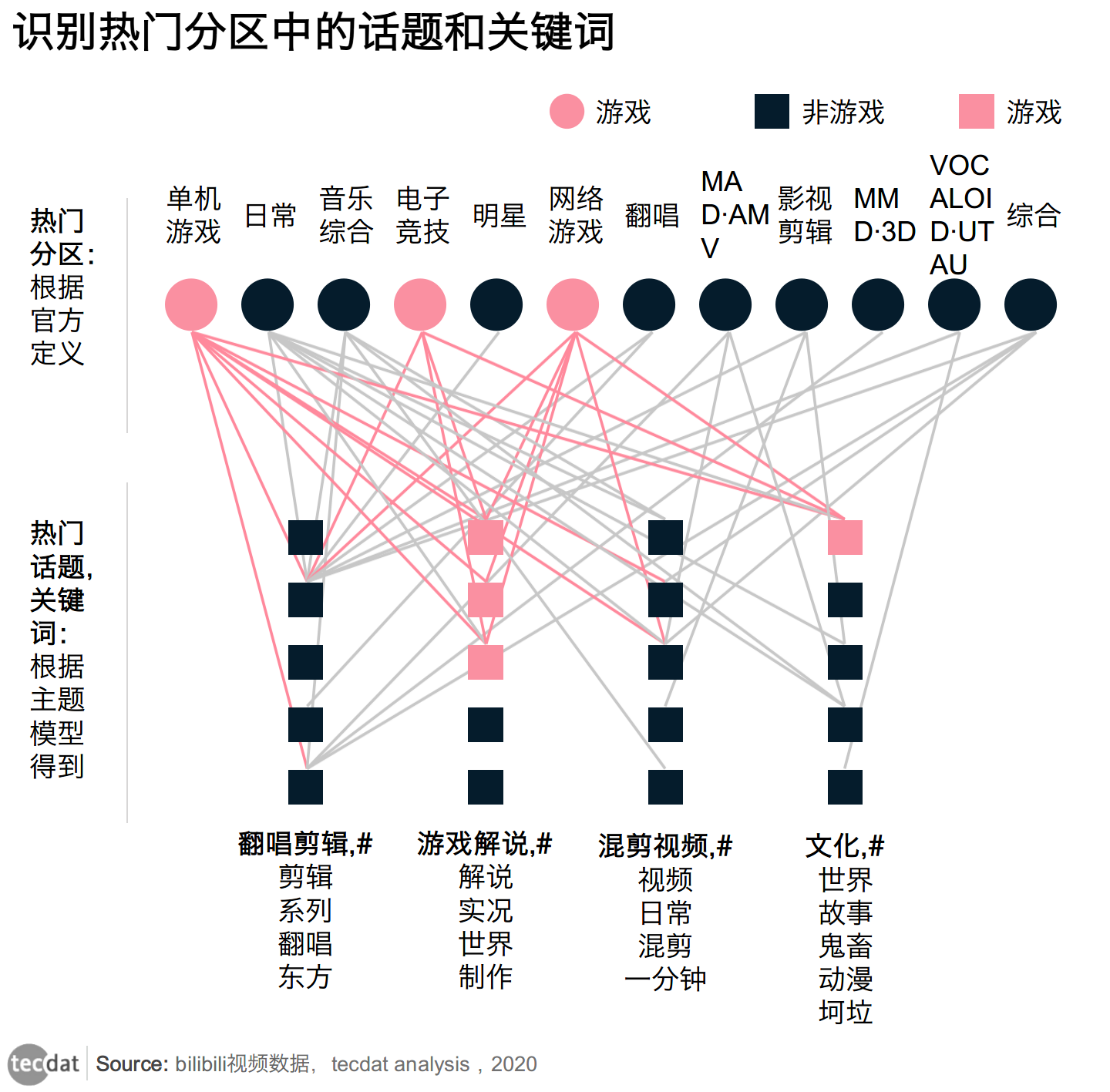
电子竞技和游戏区的相关的热点话题是游戏解说,包含解说、实况等关键词。可以认为“电竞”、“短片”(动画)这几个分区是B站的强项,一定要重点关注。
“短片·一分钟”(动画区的子分区)话题为第三话题,意味着有趣的短片普遍会受到欢迎。我们看到最近大品牌也有在动画区做短片了。
“东方”、“翻唱”这些特色小分区话题也值得关注。
视频播放量和分区、话题
我们根据播放量总共分为<332,332-925,925-2176,2176-6171,>61715个区间。
图表2
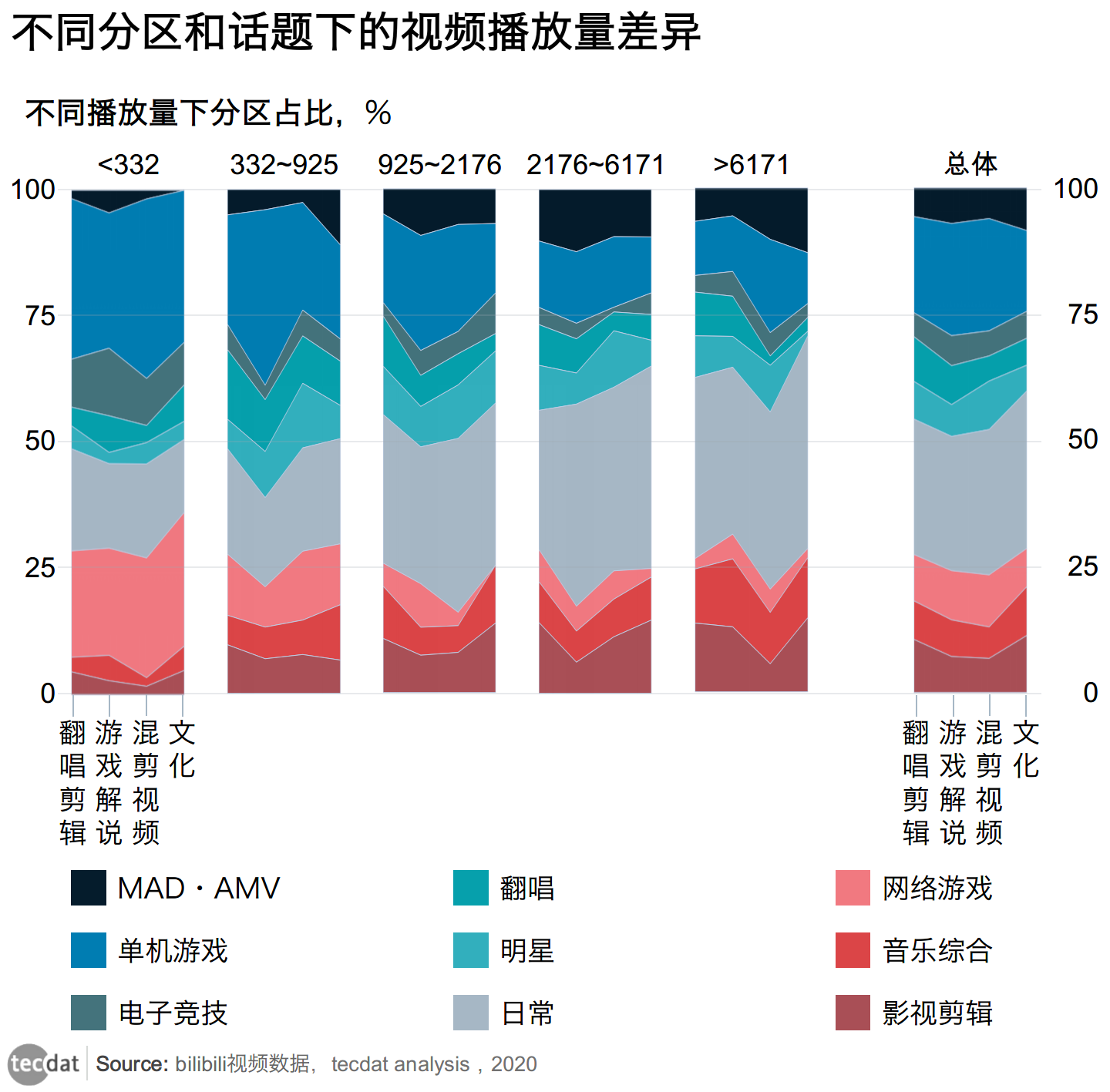
播放量整体还是大量的淹没视频,播放量小于332的达到了整体视频的45.6%,而播放量6171以上的只占到6.9%,按照“二八原则”,视频达到2176以上的播放量即达到B站视频实际效用的界限。
播放量整体还是大量的淹没视频,播放量小于332的达到了整体视频的45.6%,而播放量6171以上的只占到6.9%,按照“二八原则”,视频达到2176以上的播放量即达到B站视频实际效用的界限。

从关联网络中发现Up主社团
发表弹幕、投币、评论等,本身就有一种实时互动,完成着实实在在的、直接的互动。网站会根据用户的点击量进行视频推荐,参与热烈讨论的视频会出现在主页,受众能最快时间地看到页面。
图表3
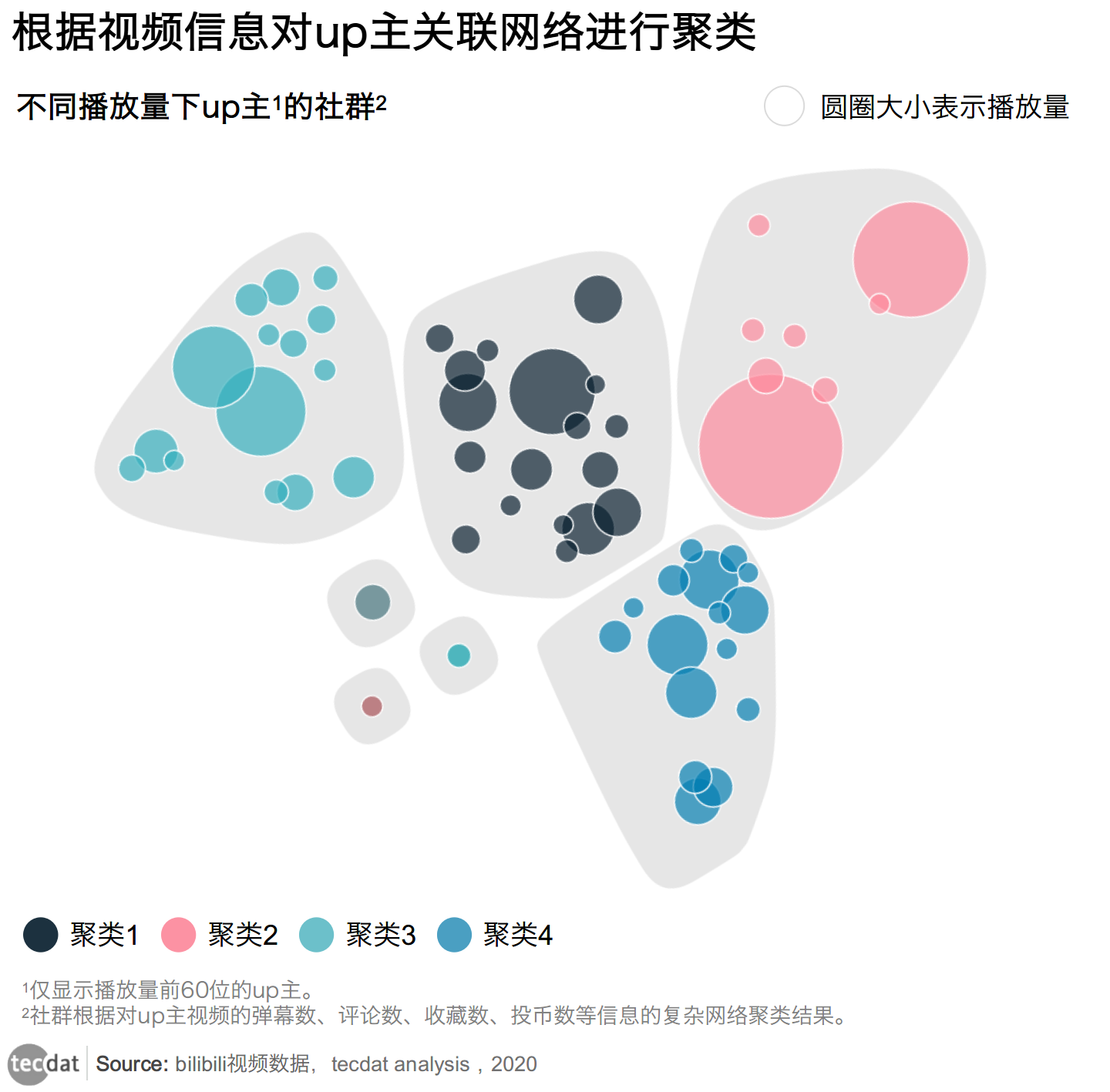
通过这些信息,我们可以用网络社群发现算法挖掘发现受欢迎的视频up主类型。
通过对于当前时间段热门排名TOP100中弹幕进行分析,将数据进行可视化处理,得到最热词汇,既可以知道在这一时间段网络舆论流行的大体趋势,把握用户心里态度,加强受众的互动反馈。还可以激发用户对于弹幕文化的探索的兴趣。使得用户保持新鲜度,延长软件寿命。
可以看出基本上播放量基本是长尾数据,有大量的小数值的数据,但是整体的平均值受极值的影响较大。
从案例结果来看,所有的B站up主被大致分为4个类别。
- 类别1:
该部分up主收藏数高于平均值,受到观众的喜爱,但评论和投币较低,仍有潜力;该类别大部分为业余up主,处于成长期。
- 类别2:
该部分播放量占了30%,是高播放量群体;与观众的互动良好;收藏、投币和分享高;
该类up主粉丝数目也大部分超过十万,能够提供高质量且稳定的视频稿件,为该分区的高价值up主群体。
- 类别3:
该类别的弹幕高于平均值,证明与观众的互动率高;评论、收藏良好。
- 类别4:
该部分up主评论数高于平均值,证明话题性也较高,但弹幕和投币、收藏较低,说明需要提高视频稿件的质量,创作符合观众口味的视频。
本文章中的所有信息(包括但不限于分析、预测、建议、数据、图表等内容)仅供参考,拓端数据(tecdat)不因文章的全部或部分内容产生的或因本文章而引致的任何损失承担任何责任。
 多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码
多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据



