
根据生存曲线的估计,可以推断出相比组之间存活时间的差异,因此生存曲线非常有用,几乎可以在每个生存分析中看到。
根据生存曲线的估计,可以推断出相比组之间存活时间的差异,因此生存曲线非常有用,几乎可以在每个生存分析中看到。
可下载资源
我们可以创建简单的生存曲线估计。让我们来看看患有卵巢癌(卵巢浆液性囊腺癌)和患有乳腺癌(乳腺浸润癌)的患者之间存活时间的差异 。
1.生存分析(survival analysis)
2.生存时间(survival time, failure time)
终点事件与起始事件之间的时间间隔。
终点事件:研究者所关系的特定结局。
起始事件:反应研究对象生存过程的起始特征的事件。
终点事件与起始事件是相对而言的,都是由特定的研究目的所决定的,是整个研究过程的标尺,需要在设计时明确规定,并在研究期间严格遵守,不能随意改变。
| 起始事件 | 终点事件 | |
|---|---|---|
| 服药 | —–> | 痊愈 |
| 手术切除 | —–> | 死亡 |
| 染毒 | —–> | 死亡 |
| 化疗 | —–> | 缓解 |
| 缓解 | —–> | 复发 |
3.生存时间的类型(survival time, failure time)
生存时间度量单位可以是年、月、日、小时等,常用符号t表示,右删失数据右上角标记“+”,其他删失数据标记“?”。
截尾数据(Truncation)
只有“左截尾”和“右截尾”两种。
截尾数据的产生,往往是因为实验设计的要求使得数据天然具有上界或者下界。
如一个实验研究退休职工的生存情况,那么显然这些数据都是左截尾的,因为所有个体的年龄都大于退休年龄(如t≥60)
二、统计概念和名词解释
1.条件生存概率(conditional probability of survival)
2.生存率(survival rate, survival function)
fit <- survfit(Surv(times, patient.vital_status) ~ admin.disease_code,
data = BRCAOV.survInfo)
# 可视化 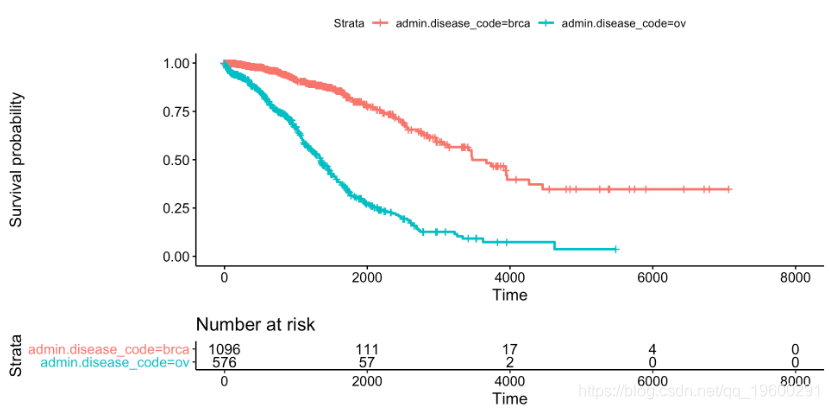
这个简单的图表以优雅的方式呈现了生存概率的估计值,该估计值取决于根据癌症类型分组的癌症诊断天数和信息风险集表,其中显示了在特定时间段内观察的患者数量。生存分析是一个特定的数据分析领域,因为事件数据的审查时间,因此风险集大小是视觉推理的必要条件。
ggplot(
fit, # 生存数据对象.
data = BRCAOV.survInfo, # 生存数据.
risk.table = TRUE, # 风险表.
pval = TRUE, # Logrank检验p-value
conf.int = TRUE, # 生存曲线置信区间.
xlim = c(0,2000),
#生存预测.
break.time.by = 500,
ggtheme = theme_minimal(),
risk.table.y.text.col = T,
risk.table.y.text = FALSE
)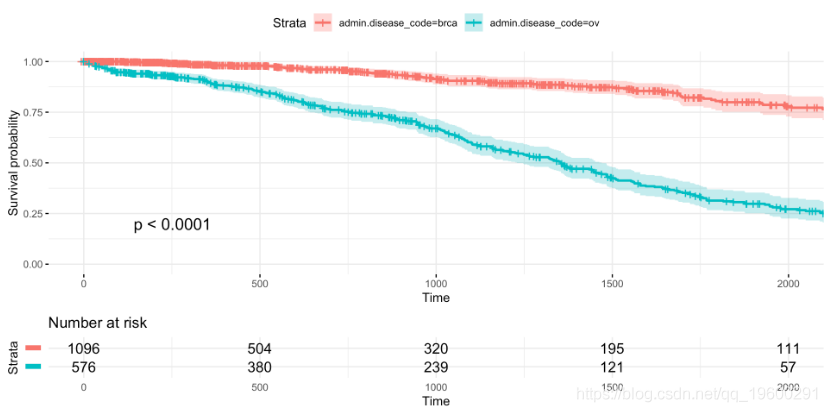
每个参数都在相应的注释中描述,但我想强调xlim控制X轴限制但不影响生存曲线的参数,这些参数考虑了所有可能的时间。
比较
基础包
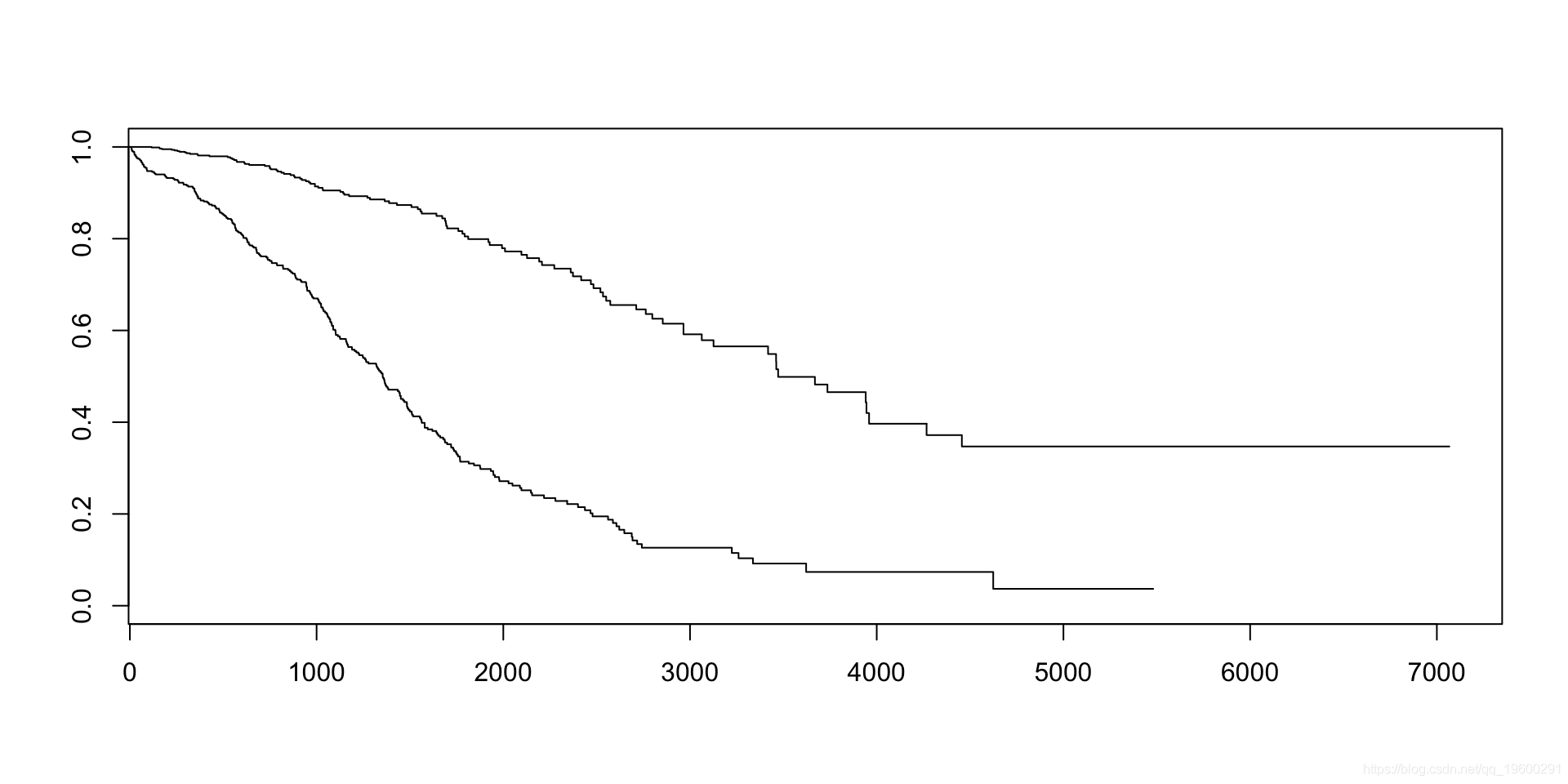
看起来很漂亮…..
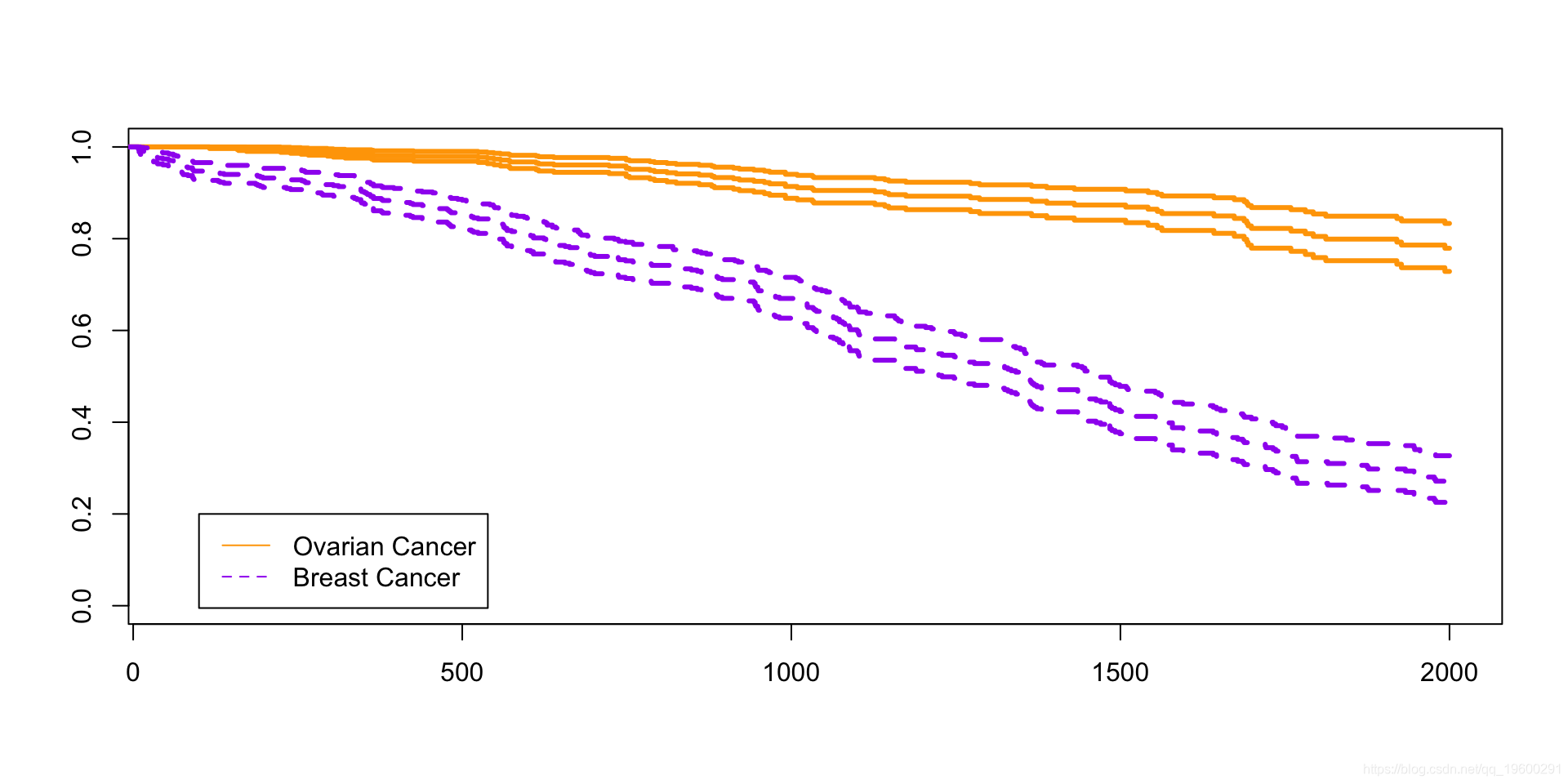
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析



