Python贝叶斯估计SEM结构方程模型与层次聚类分析尺码焦虑对女性消费者行为影响
全球女装市场规模持续扩张,某行业统计数据显示2024年市场规模预计达1.79万亿美元,未来五年将以约2.81%的年复合增长率稳步增长。

成为新会员获取本项目完整代码、数据和AI智能体
全球女装市场规模持续扩张,某行业统计数据显示2024年市场规模预计达1.79万亿美元,未来五年将以约2.81%的年复合增长率稳步增长。与此同时,尺码标准混乱这一长期存在的问题已从操作层面的不便升级为消费者心理层面的系统性困扰——尺码偏差导致的退换货约占服装类订单总量的25%-35%。这种标准的缺失不是孤立的技术问题。当服装尺码从一个客观测量单位演变为社会评价工具,当”穿不上某个尺码”被女性内化为对自我身体的否定,尺码焦虑就从个体购物烦恼扩展为集体心理现象。主流审美对”小码即高级”的推崇、品牌在利益驱动下集中生产小码服装的策略、社交平台算法的同质化推送,三者共同构建了一个让女性不断自我审视、反复确认身体价值的环境。
本研究以女性消费者在尺码焦虑语境下的消费行为为核心研究对象,基于消费者行为理论和情绪心理学构建研究模型,探讨认知程度、焦虑成因、情绪体验三个维度如何影响消费者的应对策略和最终购买决策。通过对799份有效问卷的实证分析,采用贝叶斯估计结构方程模型验证变量间路径关系,并通过中介效应分析揭示应对策略的传导机制。在此基础上应用层次聚类对消费者进行细分,识别不同族群在尺码焦虑下的行为模式差异。
本项目完整代码、数据和AI智能体
文献研究与理论框架
单一审美取向:被定义的女性身体
从古至今,女性的身体长期受社会审美束缚。古代封建制度强迫女子缠足以迎合”三寸金莲”的审美,西方流行束腰裙装突出女性曲线。当下,”白幼瘦”审美让高颅顶、骨感身材等成为”美”的标准,女性身体不断被推向迎合这些扭曲审美要求的方向。厂商也精准捕捉了这种社会心理——生产小码女装以迎合需求,进一步加剧身材焦虑。
以”BM”穿搭风格为例,”BM女孩身高体重表”设定的体重上限已远低于世卫组织正常BMI范围,意味着大多数女性无法符合该标准。但作为”瘦女孩”象征,”BM女孩”仍吸引大量年轻女性追随。
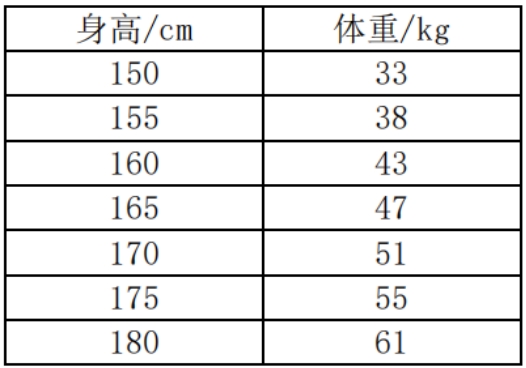
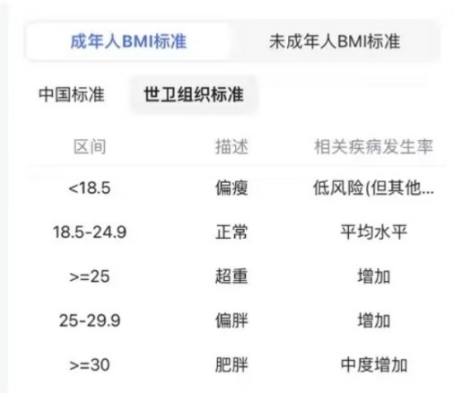
图 1 世界卫生组织成年人BMI标准
(注:BMI是身体质量指数的缩写,可以理解为用身高和体重计算出的一个健康参考数值。好比一个班级的平均分,偏离太多就说明可能需要关注了。正常范围是18.5-23.9,而”BM女孩”标准对应的BMI普遍低于17,相当于要求全班同学都考95分以上。)
“小码时代”与服装厂商的生产动机
女装尺码趋小的核心原因不只是审美潮流,更是商业逻辑的理性选择。批发市场档口商家直言,社交平台网红穿搭的流量密码就是小码露腰,连带畅销款型就是修身紧瘦款。更关键的是,集中售卖小码服装能有效降低进货价、物流成本和库房压力——同样的布料,尺码偏小一码能做出更多衣服,这在批发走量的模式下就是实实在在的利润。
据行业交流平台估算,当前服装市场上的库存超过2万亿元,且仍在以每年5%的速度递增。尺码细分越多意味着库存越多,零散线上商家抗风险能力远不如大品牌,为降低制衣成本和库存压力,厂商倾向于生产小码衣服。当市场上衣服集体变小,大多数消费者只会反思自己不够瘦——这正是厂商期望的结果。
(注:这就像电影院只卖一种尺寸的爆米花——不是因为只能做这种,而是因为标准化生产最省钱。当你吃不完或不够吃时,你不会质疑影院的做法,而是反思自己”食量不对”。服装尺码的逻辑如出一辙。)
尺码焦虑的后果与应对
身体意象概念由澳大利亚心理学家保罗·席尔德于1934年提出,涵盖感知、态度和人际反馈。尺码焦虑在心理学中可视为”身体意象失调”,主要表现为三个层面:认知失调(将尺码与自我价值绑定,产生低自尊)、情感失调(长期找不到合适尺码引发抑郁和焦虑)、行为失调(过度节食、药物减肥等极端手段)。
拒绝尺码焦虑需要从审美规训中解放出来,培养多元审美观念,塑造积极健康的身体意象——不加评判地欣赏身体功能,接受所有身形容貌,抵制不良文化影响。纵观现有文献,关于尺码焦虑的研究多从宏观层面分析成因和趋势,缺少实证数据支撑,也未能紧密结合尺码过小与身材焦虑的量化关系。本研究旨在填补这一空白。
调查模型构建
模型构建与消费者访谈
本研究通过消费者访谈确定筛选标准——行为维度(近一年因尺码问题退换货≥3次、因尺码问题放弃购买、在社交平台吐槽或建议)和态度维度(不满”均码”、持续担忧身材与服装适配、认同社会审美加剧焦虑),最终回收150份访谈记录。
使用软件对访谈数据进行开放式编码、主轴式编码和选择式编码,从原始资料中提炼出五个主范畴:
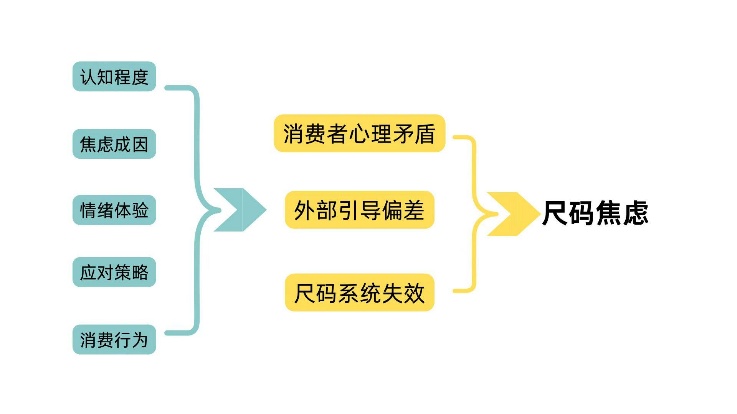
图 2 尺码焦虑初级模型图
基于此模型提出核心假设:认知程度、焦虑成因、情绪体验分别正向影响应对策略和消费行为,应对策略正向影响消费行为,并在此过程中发挥中介作用。具体假设共5组(H1a-H5),涵盖直接效应和中介路径。
(注:答辩高频问题——”为什么选择结构方程模型而不是简单的回归分析?”标准答案:因为本研究涉及多个潜变量(认知、情绪、行为),它们之间存在复杂的因果关系路径,还有中介变量需要验证。结构方程模型能同时处理测量模型和结构模型,克服了传统回归只能处理观测变量、无法处理潜变量测量误差的局限。)
预调研及模型修正
预调查回收185份问卷,有效176份。整体22个题项的克朗巴哈系数为0.871,各指标信度均在0.70以上,说明量表内部一致性良好。基于效度分析结果,删除题项Q15(”我认为服装尺码不可信”),最终形成21题正式量表。
(注:克朗巴哈系数可以理解为你用多把尺子量同一个东西的一致性——高于0.7说明这些尺子量的结果基本一致,不会这把量出1米那把量出1米5。)
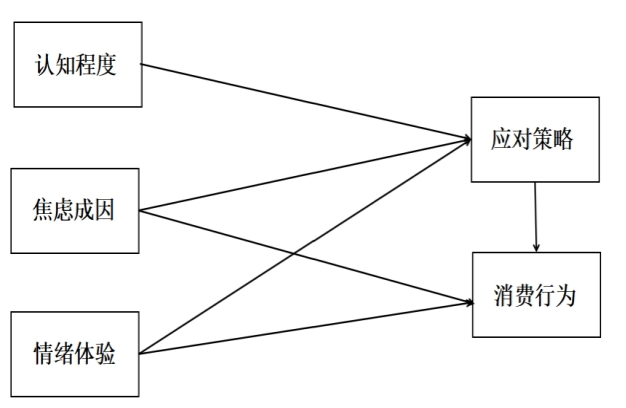
图 3 预调查模型假设图
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
数据质量分析
抽样与描述性统计
正式调查回收2,055份问卷,经作答时间和人工筛查后获得799份有效问卷。受访群体覆盖各年龄段,14-44岁占93.1%;本科及以上学历占84.5%;月可支配收入从低到高呈正态分布,保证了取样的随机性。大多数受访者BMI处于正常水平(69.9%),与实际情况相符。
图 4 描述性统计分析
图 5 不同”通常购买尺码”下的BMI值分布情况箱型图
信效度检验
正式问卷整体信度为0.849,各指标均超过0.7。KMO值为0.813,巴特利特球形检验显著(p<0.001),解释总方差达68.3%,表明量表具有良好结构效度。
(注:答辩高频问题——”如何保证问卷数据的可靠性?”标准答案:从三个方面保证:一是抽样设计上采用分层抽样覆盖不同地区、年龄段;二是信度检验上克朗巴哈系数均超0.7阈值;三是效度检验上KMO>0.8且因子载荷均达标,删除不合格题项。)
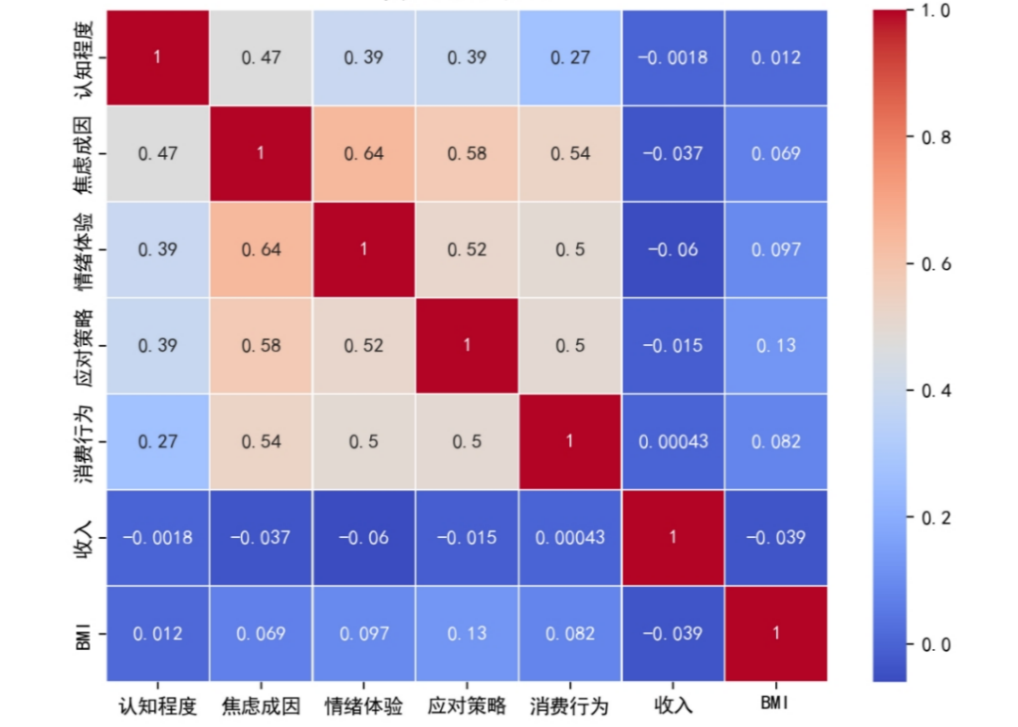
图 6 相关性分析热力图
结构方程模型验证
贝叶斯估计验证路径假设
(注:这里把贝叶斯估计类比为一个侦探推理的过程——普通回归像是一上来就下结论(点估计),而贝叶斯则先根据经验线索建立一个先验判断(先验分布),再结合现场证据(数据)不断修正,最终给出一个带有置信区间的结论(后验分布)。这样做的好处是不会被少数异常数据牵着鼻子走。)
第一轮对话:基础回归模型构建
我有一份女性消费者尺码焦虑的问卷数据(799份),包含认知程度、焦虑成因、情绪体验、应对策略和消费行为五个潜变量的量表得分。请先帮我用OLS(普通最小二乘法)做两个回归模型:模型1预测应对策略,模型2预测消费行为。需要从线性关系、误差正态性、方差齐性、多重共线性和误差自相关五个角度验证OLS适用性。使用statsmodels库。
import statsmodels.api as stat_mdl
from scipy.stats import shapiro_test
from statsmodels.stats.diagnostic import het_breuschpagan
from statsmodels.stats.outliers_influence import variance_inflation_factor
import pandas as panel
# 模型1:预测应对策略
X1 = stat_mdl.add_constant(survey_df[X_vars])
fit1 = stat_mdl.OLS(survey_df[Y_strategy], X1).fit()
print(f"模型1 F统计量: {fit1.fvalue:.1f}")
print(f"模型1 R方: {fit1.rsquared:.3f}")
# 模型2:预测消费行为(加入应对策略)
big_X = ['cognitive_awareness', 'anxiety_causes', 'emotional_experience', 'coping_strategy']
X2 = stat_mdl.add_constant(survey_df[big_X])
fit2 = stat_mdl.OLS(survey_df[Y_behavior], X2).fit()
# 误差正态性检验
_, p_shapiro1 = shapiro_test(fit1.resid)
_, p_shapiro2 = shapiro_test(fit2.resid)
print(f"模型1 Shapiro p值: {p_shapiro1:.4f}")
print(f"模型2 Shapiro p值: {p_shapiro2:.4f}")
# 方差膨胀因子(多重共线性)
vif_data = panel.DataFrame({
'特征': X2.columns[1:],
'VIF': [variance_inflation_factor(X2.values, i+1) for i in range(len(X2.columns[1:]))]
})
print(vif_data)
# 路径系数提取
print("\n路径系数(OLS先验):")
for i, col in enumerate(X1.columns[1:], 1):
print(f" {col} -> 应对策略: {fit1.params[i]:.4f} (±{fit1.bse[i]:.4f})")
for i, col in enumerate(X2.columns[1:], 1):
print(f" {col} -> 消费行为: {fit2.params[i]:.4f} (±{fit2.bse[i]:.4f})")
OLS结果显示F统计量分别为165.1和114.3(均p<0.001),线性关系显著成立;Shapiro-Wilk检验p值均大于0.05,误差服从正态分布;VIF最大仅2.12,无严重共线性问题;Durbin-Watson统计量接近2,残差无自相关。数据完全满足OLS使用前提。
| 路径 | 路径系数 | 标准误差 |
|---|---|---|
| 认知程度→应对策略 | 0.1047 | 0.0277 |
| 认知程度→消费行为 | -0.0348 | 0.0293 |
| 焦虑成因→应对策略 | 0.4140 | 0.0421 |
| 焦虑成因→消费行为 | 0.3137 | 0.0468 |
| 情绪体验→应对策略 | 0.2007 | 0.0321 |
| 情绪体验→消费行为 | 0.1884 | 0.0346 |
| 应对策略→消费行为 | 0.2566 | 0.0372 |
表 路径假设-OLS先验估计
第二轮对话:引入贝叶斯估计与MCMC采样
上面的OLS结果看起来还行,但我注意到认知程度对消费行为的系数是负的且很小,这跟理论预期有出入。OLS给的是单点估计,没办法告诉我们参数的不确定性。请用PyMC库搭建贝叶斯SEM,以上面OLS的结果作为先验信息(路径系数均值μ取OLS系数,误差标准差σ取OLS残差标准差),运行20000次MCMC采样(前1000次作为预热调整步长),输出各路径的后验均值、标准差和94% HDI区间。
import pymc as bayes
import numpy as np_arr
import arviz as az_viz
# 准备数据
cognitive = survey_df['cognitive_awareness'].values
causes = survey_df['anxiety_causes'].values
emotion = survey_df['emotional_experience'].values
strategy = survey_df['coping_strategy'].values
behavior = survey_df['consumption_behavior'].values
# OLS先验参数(从上一轮获得)
mu_prior = {
'h1a': 0.1047, 'h1b': -0.0348, 'h2a': 0.4140,
'h2b': 0.3137, 'h3a': 0.2007, 'h3b': 0.1884, 'h4': 0.2566
}
sigma_ols1, sigma_ols2 = 0.5853, 0.6140
coords = {'obs_idx': np_arr.arange(len(cognitive))}
# 结构方程:应对策略 = β1*认知 + β2*焦虑成因 + β3*情绪体验
strategy_mu = beta_h1a * cognitive + beta_h2a * causes + beta_h3a * emotion
# 结构方程:消费行为 = β4*认知 + β5*焦虑成因 + β6*情绪体验 + β7*应对策略
behavior_mu = (beta_h1b * cognitive + beta_h2b * causes +
beta_h3b * emotion + beta_h4 * strategy)
# 似然函数
strategy_obs = bayes.Normal('strategy_obs', mu=strategy_mu, sigma=epsilon1, observed=strategy)
behavior_obs = bayes.Normal('behavior_obs', mu=behavior_mu, sigma=epsilon2, observed=behavior)
# MCMC采样
trace = bayes.sample(draws=20000, tune=1000, chains=4, random_seed=42,
target_accept=0.95, return_inferencedata=True)
# 输出后验结果
summary = az_viz.summary(trace, hdi_prob=0.94, var_names=['beta_h1a','beta_h1b',
'beta_h2a','beta_h2b','beta_h3a','beta_h3b','beta_h4'])
print(summary[['mean','sd','hdi_3%','hdi_97%','ess_bulk','r_hat']])
贝叶斯估计结果显示,所有路径的R-hat指标均等于1.0,ESS(有效样本量)超过30,000,说明MCMC采样已充分收敛。关键发现:认知程度对消费行为的直接路径(H1b)HDI区间包含0([-0.047, 0.029]),不显著;焦虑成因对应对策略的影响最大(后验均值0.542);应对策略对消费行为有中等正向影响(后验均值0.311)。
| 假设 | 后验均值 | HDI下限 | HDI上限 | 是否支持 |
|---|---|---|---|---|
| H1a: 认知程度→应对策略 | 0.161 | 0.128 | 0.196 | 支持 |
| H1b: 认知程度→消费行为 | -0.008 | -0.047 | 0.029 | 不支持 |
| H2a: 焦虑成因→应对策略 | 0.542 | 0.499 | 0.587 | 支持 |
| H2b: 焦虑成因→消费行为 | 0.375 | 0.322 | 0.424 | 支持 |
| H3a: 情绪体验→应对策略 | 0.208 | 0.161 | 0.254 | 支持 |
| H3b: 情绪体验→消费行为 | 0.149 | 0.100 | 0.198 | 支持 |
| H4: 应对策略→消费行为 | 0.311 | 0.265 | 0.355 | 支持 |
| H5: 应对策略的中介作用 | — | — | — | 部分中介 |
表 贝叶斯估计结果与假设检验
(注:HDI是最高密度区间的缩写,相当于告诉我们”参数真值有94%的概率落在哪个范围内”。如果这个范围包含了0,就说明这个效应在统计上不显著——就像量体温,37±0.5℃说明发烧了,但36.5±2℃就没法确定。H1b的不显著可能是因为认知只是”知道”层面,不直接驱动行为。)
图 10 贝叶斯修正后的模型结构

中介效应分析
采用Bootstrap法(重复抽样5000次)检验应对策略的中介作用。结果显示,应对策略在认知程度与消费行为间起完全中介作用(间接效应显著,直接效应不显著),在焦虑成因与消费行为间起部分中介作用(中介效应占比10.53%),在情绪体验与消费行为间也起部分中介作用(中介效应占比5.41%)。
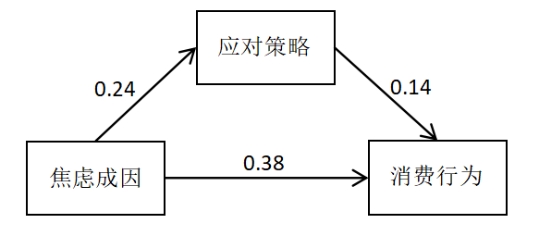
图 13 应对策略在焦虑成因与消费行为之间中介作用
(注:中介效应的通俗理解——你的工资涨了,你心情好了,然后花钱更多了。这里”心情好”就是中介变量。如果直接看工资到消费的关系,中间漏了”心情”这个桥梁,可能就低估或误解了真实的传导机制。)
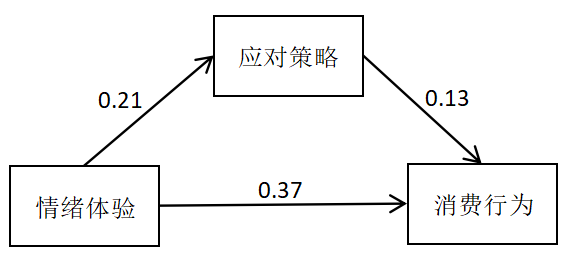
图 14 应对策略在情绪体验与消费行为之间中介作用
消费者分析与聚类
消费者特性概览
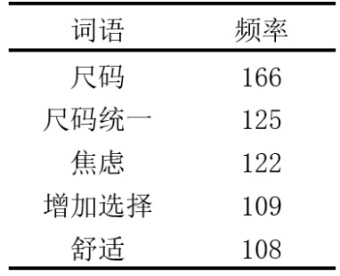
通过词频分析提取192条有效主观意见,发现消费者最关注尺码统一、尺码选择多样性和舒适度三个维度。多数消费者受社会评价影响显著(众数=4,306人),试穿尺码不适易引发焦虑(众数=4,285人)。
消费行为统计显示:48.4%的消费者不会为”紧身好看”而牺牲舒适度,44.8%会选择宽松尺码减轻心理负担,49.2%会下意识与模特或博主尺码对比。这验证了消费者在尺码选择上存在显著心理权衡。
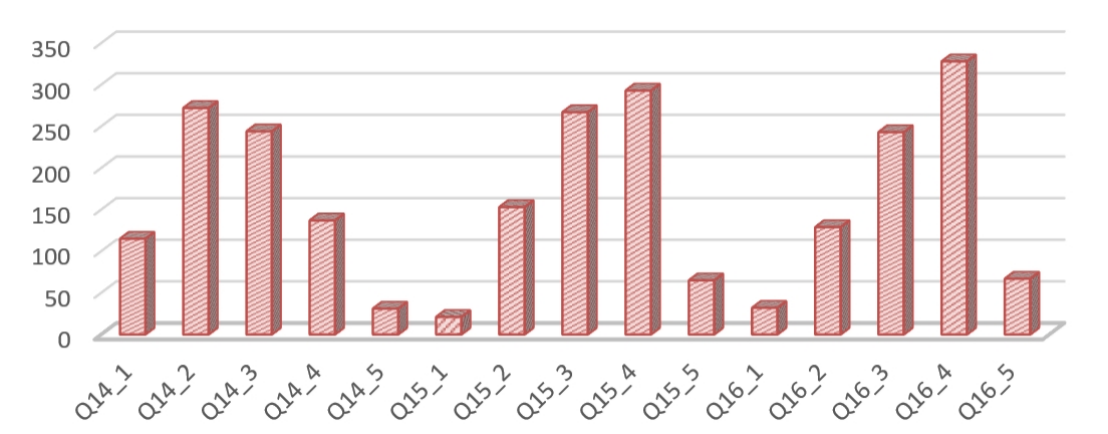
图 16 消费者行为可视化图表
层次聚类与回归分析
第三轮对话:消费者细分与回归建模
现在对799份数据进行层次聚类分析。聚类变量包括五个潜变量得分、月可支配收入和BMI分级。先用皮尔逊相关系数和KMO统计量检验聚类适用性,再用轮廓系数确定最优聚类数,最后分别对每个族群做多元线性回归(以应对策略为因变量,认知程度、焦虑成因、情绪体验为自变量),输出回归方程和模型解释度。
轮廓系数分析确定最优聚类数为4。单因素方差分析显示所有变量在四类群体间均存在显著差异(p<0.001),聚类结果具有良好区分度。四类消费者群体特征如下:
| 特征 | 低参与理性派 (N=199) | 高焦虑行动派 (N=156) | 焦虑回避型 (N=81) | 务实均衡型 (N=363) |
|---|---|---|---|---|
| 认知程度 | 2.51(低) | 4.17(高) | 3.06(中) | 3.30(中) |
| 焦虑成因 | 2.54(低) | 4.00(高) | 3.49(中高) | 3.33(中) |
| 情绪体验 | 2.32(低) | 4.03(高) | 3.49(中高) | 3.20(中) |
| 应对策略 | 2.43(低) | 3.89(高) | 3.15(中) | 3.19(中) |
| 消费行为 | 2.33(低) | 3.49(高) | 3.17(中) | 3.01(中) |
| 收入水平 | 3.98(高) | 3.84(中高) | 1.84(低) | 4.28(最高) |
| BMI分类 | 1.86(偏瘦) | 2.29(正常偏高) | 2.10(正常) | 2.02(正常) |
表 四类消费者群体特征对比
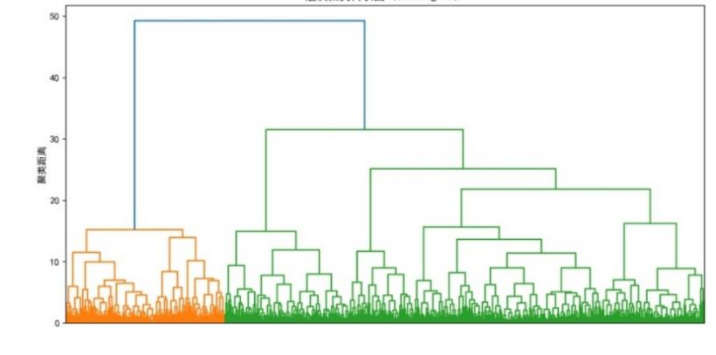
图 19 层次聚类树状图
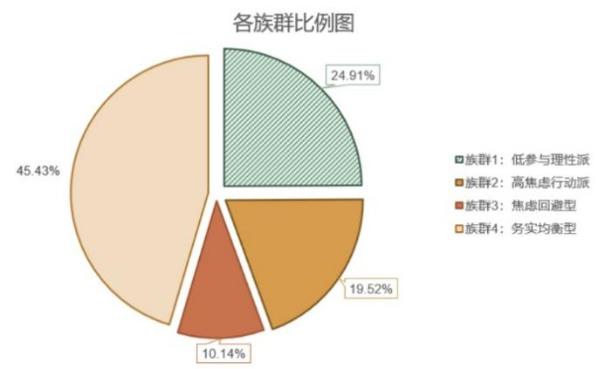
图 21 消费者群体比例
族群1:低参与理性派(24.9%)——BMI最低群体,尺码焦虑影响最小。单一显著预测因子是焦虑成因,但模型解释度仅9.2%。她们意识到社会审美问题,但自身不受困扰。该群体BMI≤18.5的人占比73%,常购品牌尺码偏差仅1.2cm(行业平均4.7cm)。回归方程:应对策略=1.601+0.241×焦虑成因。
族群2:高焦虑行动派(19.5%)——尺码焦虑认知和情绪评分均最高。认知程度和焦虑成因显著预测应对策略,模型解释度达50.8%。她们是”最忙的消费者”:单次购物耗时43分钟(其他群体均值15分钟),月均退换货2-3次。认知每提升1单位,策略投入时间增加约23分钟。回归方程:应对策略=0.515+0.154×认知程度+0.560×焦虑成因。
族群3:焦虑回避型(10.1%)——三个自变量均显著,模型解释度44.9%。负面情绪体验每增加至≥2.7次/月时,购买频率下降约0.78次/月。她们的收入水平最低,更倾向”宁缺毋滥”。回归方程:应对策略=0.551+0.230×认知程度+0.394×焦虑成因+0.180×情绪体验。
族群4:务实均衡型(45.4%)——占比最大的群体。认知程度和焦虑成因显著预测应对策略,但模型解释度仅6.1%。关键发现:认知程度每提高1单位,策略投入反而降低14%(β=-0.143),符合”问题外归因”理论。该群体83%的购买集中于执行统一尺码标准的品牌。回归方程:应对策略=3.028-0.143×认知程度+0.126×焦虑成因。
(注:答辩高频问题——”聚类分析中为什么选择4类而不是3类或5类?”标准答案:通过轮廓系数在2-8类范围内扫描,k=4时轮廓系数最高,表明类内紧密、类间分离最优化。同时4类在商业解释上最为合理——太少则信息损失严重,太多则类别不稳定且缺乏可操作性。)
| 群体 | 显著预测因子 | R² | 核心行为特征 |
|---|---|---|---|
| 低参与理性派 | 焦虑成因 | 0.092 | 理性消费,尺码困扰小 |
| 高焦虑行动派 | 认知程度+焦虑成因 | 0.508 | 花大量时间应对,越了解越焦虑 |
| 焦虑回避型 | 认知+成因+情绪 | 0.449 | 负面情绪积累导致购买回避 |
| 务实均衡型 | 认知程度+焦虑成因 | 0.061 | 问题外归因,选择标准化品牌 |
表 各群体回归模型对比
结果讨论与建议
核心发现
焦虑成因是影响女性消费者行为的最强因素——社会”白幼瘦”审美、他人评价、行业标准混乱共同构成焦虑源,显著改变消费行为。这与贝叶斯估计结果一致:焦虑成因对消费行为的总效应达到0.375(后验均值),远超其他路径。情绪体验的影响较小但同样显著,尤其是试穿不适引发的负面情绪会抑制购买意愿,或转而购买显瘦、大码的替代选择。
认知程度对消费行为的直接效应不显著,说明”知道”尺码焦虑不等于”改变”消费行为——二者之间需要”应对策略”这个桥梁。完全中介效应验证了这一传导机制。
(注:研究局限性——本研究的受访者以14-44岁为主(93.1%),老年女性的尺码焦虑特征未被充分覆盖。此外,问卷数据为横截面设计,无法追踪尺码焦虑的动态演变过程。这是后续研究需要补足的。)
策略建议
针对不同消费者群体,提出差异化干预方案:
低参与理性派无需策略性调整,但作为尺码焦虑感知的”对照组”,她们的存在提醒我们:尺码问题的根源在于供给端而非消费者自身。
高焦虑行动派最需要智能尺码匹配系统的支持——当机器能在数秒内完成她们花43分钟手动做的事,焦虑循环才有被打破的可能。
焦虑回避型需要的是服装设计端的改变——放宽尺码范围,让不同身材的女性都能找到适配的衣服,而不是因为穿不进衣服感到自卑继而放弃购买。
务实均衡型的行为特征最强有力地支撑了尺码标准化的必要性——当83%的购买集中于执行统一标准的品牌时,市场已经用脚投票了。但行业现状是仅约41%的服装企业完全符合国家标准,市售女装胸腰差平均偏离值达6.3cm。
推进尺码标准化从”推荐性”向”约束性”转变、优化线上试穿体验、倡导多元审美观念——这三个方向的协同推进,才是缓解尺码焦虑的系统性解法。
总结
核心问题与解决方案
问题一:尺码焦虑的哪些维度显著影响女性消费者行为?
解决方案:焦虑成因(社会审美压力、他人评价、行业标准混乱)的影响最大(后验均值0.375),情绪体验其次(后验均值0.149),认知程度直接影响不显著(后验均值-0.008,HDI包含0)。这意味着干预的重点不应是”让消费者更了解尺码焦虑”,而是从根源上减少焦虑来源——规范尺码标准、引导多元审美。对比表格显示,焦虑成因路径系数是情绪体验的2.5倍,属于主导影响因素。
问题二:应对策略能否有效缓解尺码焦虑对消费行为的冲击?
解决方案:应对策略在三个感知维度与消费行为之间均起中介作用(认知程度→完全中介,焦虑成因→部分中介占10.53%,情绪体验→部分中介占5.41%),且应对策略本身对消费行为有显著正向影响(后验均值0.311)。这意味着为消费者提供高效应对工具(如智能尺码推荐)可以实质性改善消费体验,而非仅仅缓解心理不适。
问题三:不同类型的消费者在尺码焦虑下表现出怎样的行为差异?
解决方案:聚类分析将消费者分为四类。高焦虑行动派(19.5%)和焦虑回避型(10.1%)是需要重点关注的群体——前者陷入”越了解越焦虑”的行为强化循环(R²=0.508),后者因负面情绪累积而系统性减少消费(购买频率下降0.78次/月)。务实均衡型(45.4%)反而是最需要标准化尺码支持的群体——认知程度提高反而降低策略投入(β=-0.143),说明她们已将问题归因于生产端,等待市场改变。
技术创新与业务价值
将贝叶斯估计引入消费者行为SEM分析,利用OLS先验+MCMC后验的两阶段框架,相比传统极大似然估计提供了更丰富的参数不确定性信息(94% HDI区间),使假设检验结论更加稳健可解释。
“聚类+回归”的串联分析框架实现了从整体路径验证到群体差异量化的完整链路——SEM回答”是什么在影响”,聚类回答”影响谁”,回归回答”影响有多大”,三层递进填补了现有研究仅做单一层次分析的空白。
结论直接为服装电商平台和品牌方提供了客群分层的量化依据:高焦虑行动派需要”智能尺码匹配”功能,焦虑回避型需要”宽松版型推荐”,务实均衡型需要”尺码稳定承诺”——不同的产品策略对应不同的消费者痛点。
本文配套的论文建模可直接套用的AI智能体、完整代码包、实证分析,可加小助手:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
作者系数据挖掘与消费者行为分析领域分析师,拥有多年Python建模与实证研究经验。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据
Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据 Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据
Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据

