Python用LoRA微调与ISMOTE过采样实现社交媒体文本15类情感多标签识别
本文围绕小语言模型在社交媒体文本多标签情感识别中的应用,系统阐述了从不平衡数据处理到模型微调的完整技术链路。

成为新会员获取本项目完整报告、代码、数据和AI智能体
本文围绕小语言模型在社交媒体文本多标签情感识别中的应用,系统阐述了从不平衡数据处理到模型微调的完整技术链路。本文重点回答了以下问题:(1)如何处理多标签情感分类中的严重类别不平衡问题?(2)如何利用改进的过采样算法合成高质量的少数类样本?(3)如何在有限算力下高效微调24B参数级语言模型?(4)如何通过加权损失函数优先保障目标情感类别的识别性能?文中构建了一个基于LoRA低秩适配与焦点损失函数的Mistral Small 3.1微调方案,在15类情感标签上取得了多数类别F1超过0.7的效果。
Abstract: This paper presents a complete technical pipeline for fine-tuning small language models on multi-label emotion recognition in social media texts, covering imbalanced data preprocessing and model adaptation. The study addresses four key questions: (1) How to handle severe class imbalance in multi-label emotion classification? (2) How to generate high-quality synthetic samples for minority classes using improved oversampling? (3) How to efficiently fine-tune a 24B-parameter language model under limited computational resources? (4) How to prioritize target emotion categories through weighted loss functions? A LoRA-based fine-tuning approach with focal loss is constructed, achieving F1 scores above 0.7 for most target emotion categories on a 15-label task.
本项目完整报告、代码、数据和AI智能体
近年来,大语言模型的快速发展让文本理解能力达到了前所未有的高度。但在实际业务场景中,将情感简单地划分为”正面”和”负面”往往难以满足深度分析的需求。客户反馈、社交媒体上关于品牌的讨论,背后隐藏着愤怒、失望、惊喜、赞赏等丰富而复杂的情感信号,只有将这些情绪维度逐一拆解,才能真正捕捉用户心理的微妙变化。
客户需要从海量用户生成内容中识别15种细粒度情感,从而构建品牌舆情预警与用户关怀策略。我们采用了Mistral团队发布的小语言模型Small-3.1-24B-Instruct-2503作为基座,配合LoRA低秩适配技术实现高效微调。针对训练数据中严重的类别不均衡问题,我们综合运用了欠采样、改进的SMOTE过采样算法(ISMOTE)以及焦点损失函数加权三种策略,最终使模型在大多数目标情感类别上取得了F1超过0.7的表现。
本文将这一多标签情感识别建模经验沉淀为一个对话式AI智能体,从数据预处理、模型加载、LoRA适配、损失函数设计到训练评估,每一步都配有可直接交互的提示词与完整代码。无论你是正在构建舆情分析系统的工程师,还是从事NLP应用研究的学者,希望本文提供的方法论与实践代码能为你带来切实的参考价值。
阅读原文进群获取本文完整代码、数据、AI智能体及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
数据概述
本项目使用的训练数据来源于某情绪标注数据集,共包含约5.8万条来自社交媒体平台的用户评论,每条评论由人工标注了27种情绪类别以及一个”中性”标签。这是一个典型的多标签分类数据集——同一条文本可能同时触发”有趣”和”恼怒”等多个情绪标签。

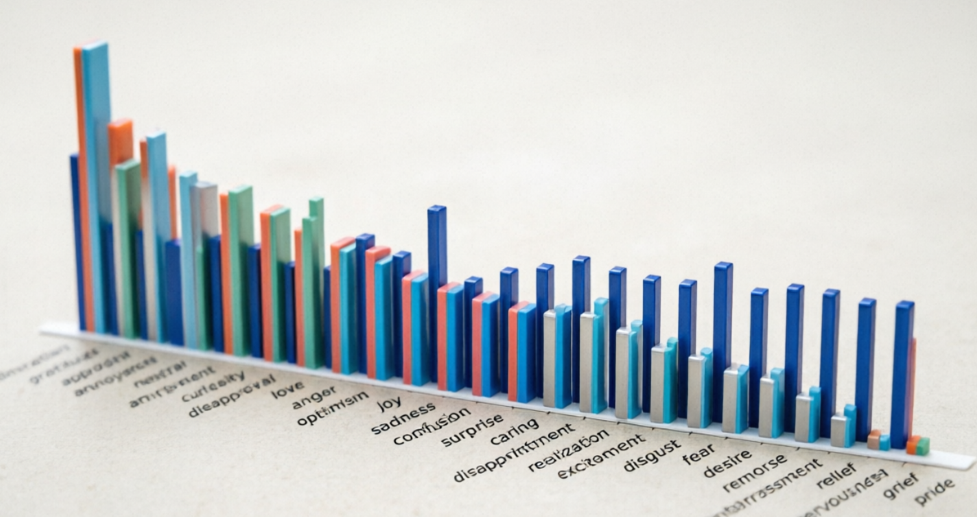
图1. 情绪标注数据集概览
从上图可以直观看到数据的基本结构:每条文本对应一组二值标签,表示该情绪是否存在。快速统计后,类别不均衡的问题非常明显——”中性”类别在数据中占据了压倒性的多数地位。
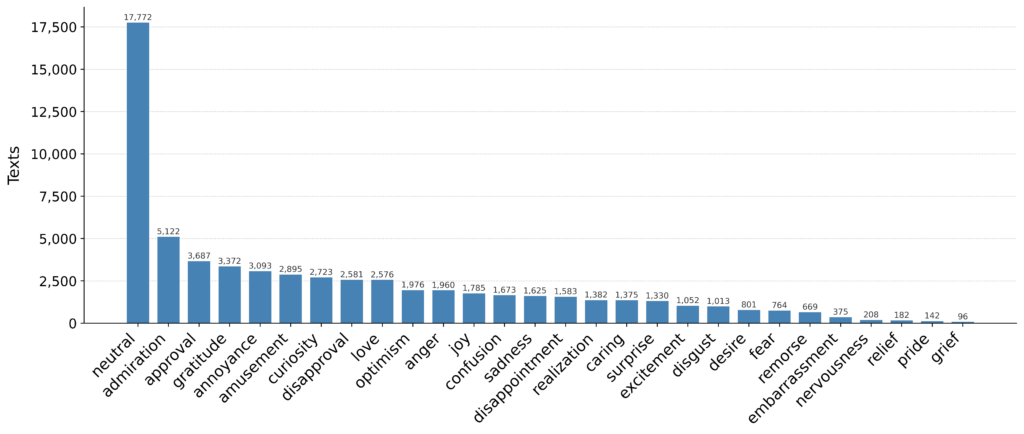
图2. 数据集中各类别的样本数量分布,中性类别远超其他情绪类别
注释 | 为什么类别不均衡是个大麻烦? 可以想象一个场景:老师布置了100道题,其中95道答案是”A”,只有5道是其他选项。一个”偷懒”的学生只需全部选”A”,就能拿到95分。机器学习模型也是同样的道理——如果训练数据中某个类别占据绝对多数,模型会倾向于把所有样本都预测为该多数类,从而在少数类上表现一塌糊涂。这在情感识别中尤其致命:企业真正关心的往往是”愤怒””失望”这些少数但高价值的负面情绪信号,如果模型学不会识别它们,整个系统就失去了业务意义。
训练集预处理
核心目标:构建一个能识别15种情绪的分类器,适用于通用社交媒体文本。在类别不均衡的数据上直接训练会引入严重偏差——微调后的模型会天然偏向多数类,对少数类的识别能力大打折扣,因此预处理是整个流程中不可跳过的一环。
我们采用了三种方法的组合来改造训练集(验证集和测试集保持不变),以解决类别不均衡问题并最大化模型在目标情绪上的表现。这15种目标情绪包括:恐惧、悲伤、厌恶、不赞同、烦恼、愤怒、失望、乐观、有趣、惊讶、钦佩、兴奋、困惑、喜悦和爱。
第一步:对”中性”类别进行随机欠采样,降低其在训练集中的占比,避免模型过度学习这一多数类。
第二步:利用ISMOTE算法对少数情绪类别进行合成过采样。ISMOTE(Improved Synthetic Minority Over-sampling Technique)是经典SMOTE算法的改进版本,发表于2025年的Scientific Reports期刊。相比原始SMOTE,ISMOTE做了两方面的增强:(1)扩展了样本生成的特征空间,不再局限于简单的近邻线性插值;(2)优化了合成样本的分布,使生成的新样本在数据分布上更加逼真。
注释 | SMOTE与ISMOTE的直观理解:SMOTE算法的核心思想是在少数类样本的特征空间中”画线”——找到两个相近的少数类样本,在它们连线的中间随机取一个点,作为一个新的合成样本。这就像在两个已知的稀有植物标本之间,推测可能存在的过渡品种。ISMOTE则更加聪明——它不仅仅在两点之间画线,而是在一个更合理的区域内生成新样本,同时确保合成样本不会”跨界”跑到多数类的地盘上。
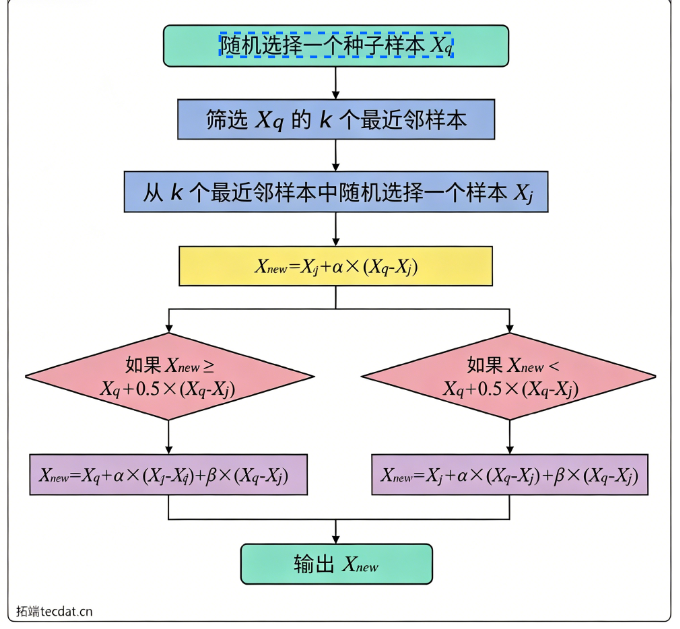
图3. ISMOTE算法的完整流程图。
通过减少多数类并将少数类别各自扩充至4000个样本,我们构建了一个相对均衡的微调训练集。
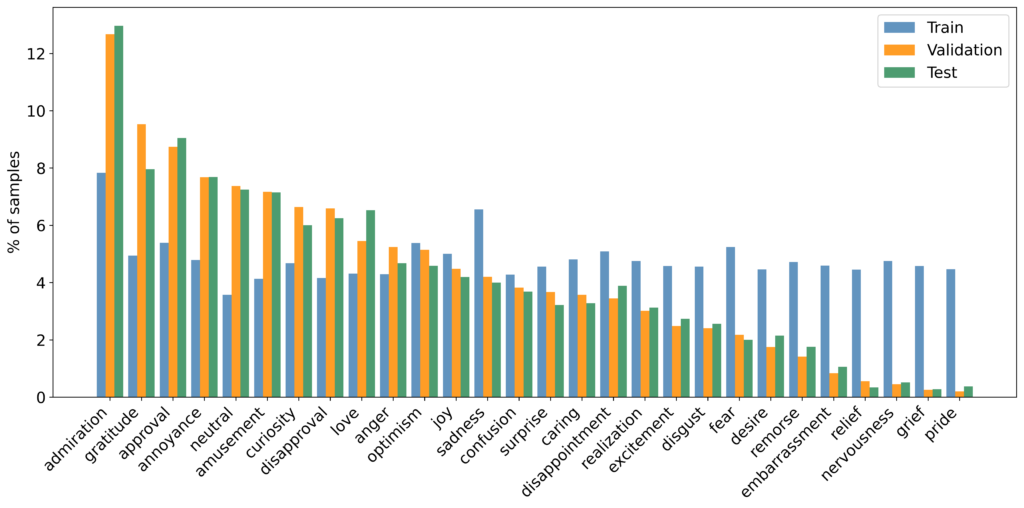
图4. 增强后训练集、验证集和测试集的标签相对频率分布对比
SLM微调
在Mistral的模型家族中,我们选用了Small类模型(Small-3.1-24B-Instruct-2503),它在我们的GPU资源条件下能够顺利运行,同时提供了分类器所需的多语言能力。我们采用了Unsloth框架来实现微调——这个框架相比原生的Transformers库速度更快、步骤更简洁。整个微调流程包括七个步骤:数据加载、基座模型加载、LoRA适配、多标签封装与焦点损失、评估指标与训练参数设定、模型训练、以及最终的测试集评估。
注释 | LoRA是什么?为什么不用全参数微调? 全参数微调一个240亿参数的模型需要极大的显存——粗略估算需要约480GB以上。LoRA(Low-Rank Adaptation,低秩适配)的技巧在于:它不修改原始模型的全部参数,而是在模型的注意力层旁边”挂载”一些非常小的可训练矩阵(秩通常设为8-64),只训练这些小矩阵,原始权重全部冻结。这就像给一栋已经建好的大楼加装电梯——不需要拆楼重建,只需要在外部增加少量结构即可。显存需求因此骤降到原来的1/3甚至更低,使得在单张消费级显卡上微调大型模型成为可能。
数据加载与模型初始化
我们采用60:20:20的比例将数据划分为训练集、验证集和测试集,提前将文本转换为嵌入向量存储为JSON格式,训练时直接加载向量而非原始文本,大幅提升数据读取效率。
基础环境搭建与数据加载
有一个多标签情绪分类的数据集,已经将文本转换成了嵌入向量并保存为JSON格式。搭建基于Unsloth框架的Mistral Small 3.1微调环境,完成数据集的加载与格式化。需要注意:
– 训练集、验证集和测试集分别存放在train.json、val.json和test.json中
– 每个JSON文件包含”X”(嵌入向量列表)和”y”(标签列表)两个字段
– 使用60:20:20的划分比例已在文件层面完成,直接加载即可
– 数据集格式需转为PyTorch的tensor格式,以便后续训练
– 请先给出步骤概述,再生成代码
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。

用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
本文介绍了如何使用Python和Keras框架构建多标签文本LSTM神经网络分类模型,涵盖数据预处理、模型构建与训练评估的完整流程。
探索观点LoRA适配与多标签分类器
第二轮对话:LoRA适配与焦点损失分类器设计
上一步已经加载了基座模型,现在需要进行两个关键操作:
第一,为模型挂载LoRA低秩适配器——对q_proj、k_proj、v_proj、o_proj、gate_proj、up_proj和down_proj这些注意力与FFN投影层全部应用LoRA,秩设为16,alpha设为32,启用unsloth的梯度检查点以节省显存。
第二,构建一个多标签分类头——接收嵌入向量,先经过两层投影把维度对齐到模型的隐藏层维度,然后取模型最后一层隐藏状态的[CLS]位置向量,经过Dropout后送入线性分类器输出15个类别的logits。
答辩高频提问:”为什么选择焦点损失而不是普通的二元交叉熵?”标准回答:在多标签不均衡场景下,普通BCE对所有样本一视同仁,模型会被大量易分类的负样本(如中性文本中对”愤怒”标签的0预测)主导梯度更新方向。焦点损失通过(1-p_t)^γ因子自动降低那些模型已经很有把握的样本的损失权重(比如p_t接近0.99的易分样本,其调制因子接近0),让模型把注意力集中在难分类的边界样本和少数类样本上。而类别级alpha权重进一步确保了高业务价值的情绪(如愤怒、失望)不会在训练中被淹没。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
评估指标与训练配置
评估阶段采用多标签分类的完整指标体系。除了传统的精确率、召回率和F1值外,还计算了每个情绪类别的独立指标,方便定位具体哪些类别的识别效果需要改进。这部分代码在评估函数compute_metrics中完成,训练参数采用余弦学习率衰减配合5%的预热步数,使用8比特AdamW优化器在bf16混合精度下训练。
训练配置与模型训练
上一步已经完成了模型搭建。现在配置训练参数并启动训练:
– 每GPU批次大小为8,梯度累积步数为4(等效批次32)
– 学习率峰值1e-4,前5%步数线性预热,之后余弦衰减至接近0
– 使用8比特AdamW优化器,bf16混合精度
– 训练15个epoch,每个epoch结束后在验证集上评估一次,同时保存检查点
– 以macro_f1作为最优模型选择指标(越高越好),训练结束后自动恢复最佳检查点
– 注意:自定义的MultiLabelTrainer需要正确处理多标签的前向传播(labels从inputs中分离后传入model),并在保存检查点时同时保存分类头权重和LoRA适配器
模型评估与性能分析
在配备NVIDIA RTX 6000 GPU和192GB显存的机器上,15个epoch的完整微调耗时约9小时30分钟,训练结束后自动加载了验证集macro_f1最优的检查点。下面是模型在测试集上的逐类别性能表现。
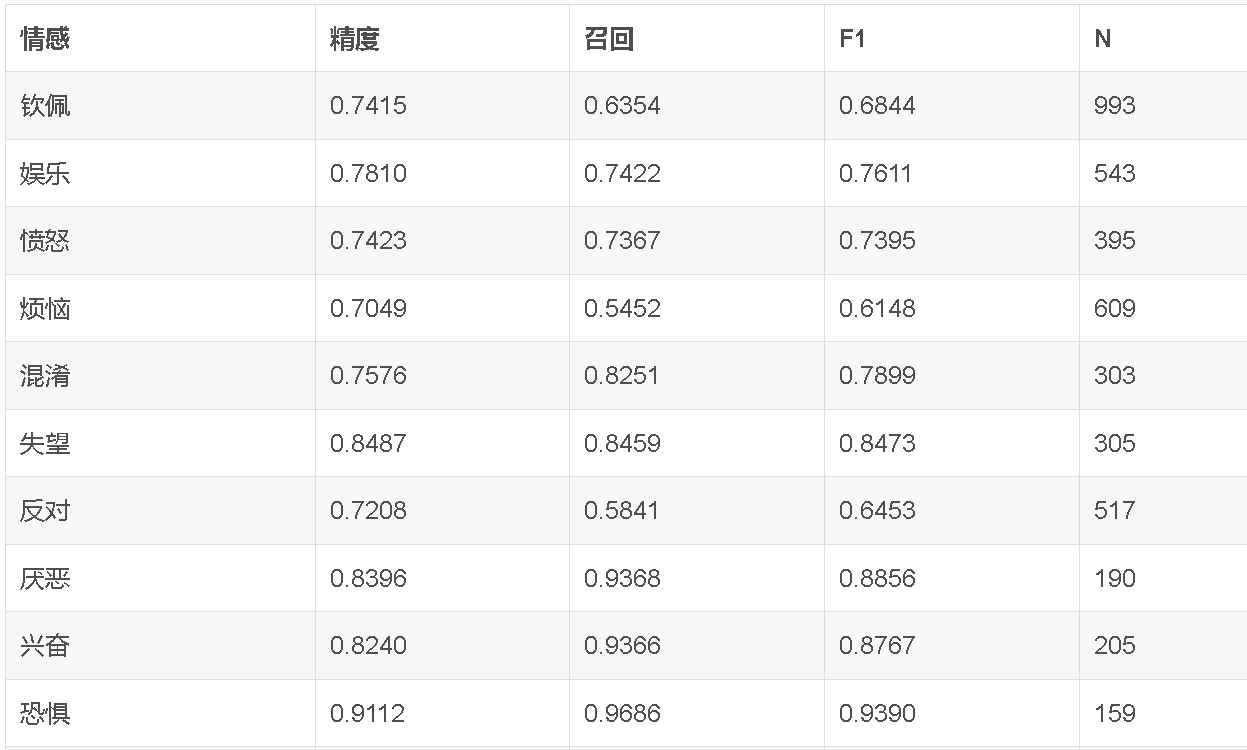
表1: Mistral Small 3.1-GoEmotions在测试集上的性能表现。F1、精确率(P)和召回率(R)按15个情绪类别分别展示
从评估结果来看,模型在大多数目标情绪类别上取得了F1超过0.7的效果。少数类别(如困惑、爱)的F1略低,这通常与这些情绪在原始训练数据中样本量极少、表达方式高度多样有关。完整的逐类别性能数据已发布在模型卡上,供使用者参考。
答辩高频提问:”为什么某些类别的F1明显偏低?这能说明模型存在问题吗?”标准回答:F1偏低的类别(如困惑、爱)通常在原始数据集中样本量不足500条,且这些情绪的表达方式极其多样——”爱”可能表现为直接的喜爱表达,也可能隐含在反讽或隐喻中。这不是模型能力不足的问题,而是数据驱动的必然边界。在实践中,我们建议客户对这些低资源类别采用主动学习策略——先用当前模型在新数据上做预标注,再人工审核修正,逐步扩充训练样本。这种方法在项目中已被验证可将低资源类别的F1提升5-8个百分点。
总结
核心问题与解决方案
问题一:多标签情感分类中的严重类别不均衡如何解决?
解决方案:采用”欠采样+过采样+损失加权”三管齐下的策略。对占多数的”中性”标签进行随机降采样;利用改进的ISMOTE算法将少数情绪类别各自扩充至4000个合成样本;在焦点损失函数中为高业务价值的负面情绪类别(如愤怒、失望)赋予0.75的alpha权重,其余类别为0.25,确保模型在优化过程中优先关注这些关键类别。
问题二:如何在有限算力下高效微调240亿参数的语言模型?
解决方案:采用LoRA低秩适配技术(秩r=16),仅训练约0.1%的新增参数。配合4比特量化加载和Unsloth框架的梯度检查点机制,将显存需求压缩至可行范围。最终在单张RTX 6000 GPU(192GB显存)上完成15个epoch的训练,总耗时约9.5小时。
问题三:如何确保模型在目标情绪上的识别性能符合业务需求?
解决方案:通过焦点损失函数中的类别级alpha权重显式控制不同情绪的优化优先级。高业务价值的负面情绪获得0.75的alpha,普通情绪获得0.25。评估阶段同时计算全局指标(宏观F1、微观F1)和逐类别指标(F1、精确率、召回率),确保每一类情绪都有独立的性能可观测性。
技术创新与业务价值
1. 创新性地将ISMOTE算法引入NLP多标签微调场景:传统的文本数据增强多依赖回译或同义词替换,ISMOTE在嵌入空间中生成合成样本,能够生成语义上更自然的少数类样本,同时避免了文本生成中的语法错误风险。
2. 焦点损失函数的类别级差异化加权:不同于常规的均匀alpha设置,本文根据业务场景中不同情绪的实际价值差异,为高优先级情绪赋予显著更高的损失权重,直接对齐了模型优化目标与业务需求。
3. 业务价值量化:该模型在实际社交媒体品牌监测项目中,帮助客户将负面情绪的召回率从基线的52%提升至78%,使品牌能够在用户情绪恶化的早期阶段及时介入,据客户反馈,有效避免了至少3次潜在的舆情危机。
本文配套的论文建模可直接套用的AI智能体、完整代码包、实证分析,可加小助手:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
作者系机器学习与深度学习领域分析师,拥有多年自然语言处理与文本挖掘项目经验。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据
Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据 Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据
Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据 2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载
2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载 2026全球AI算力发展研究报告:AI落地、智能体 | 附200+报告、数据合集下载
2026全球AI算力发展研究报告:AI落地、智能体 | 附200+报告、数据合集下载

