LangChain DeepAgents与Claude Flow的多智能体编码系统可靠性评估
作为长期在企业一线与高校实验室之间穿梭的研究者,我经常被问到同一个问题:为什么强大的大模型(LLM)在演示时惊艳四座,一放进生产环境就变得难以驾驭?

成为新会员获取本项目完整教程资料
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
我们将从“给模型套上缰绳”的理念出发,先介绍如何用LangChain的DeepAgents构建一个编码智能体,并通过HumanEval基准和Pass@1/Pass@k指标量化它的可靠性;接着引入Claude Flow——一个让多个智能体像交响乐团般协作的编排框架,并展示两个真实场景:全栈应用自动生成与多源研究报告撰写。下图概括了全文的技术路径: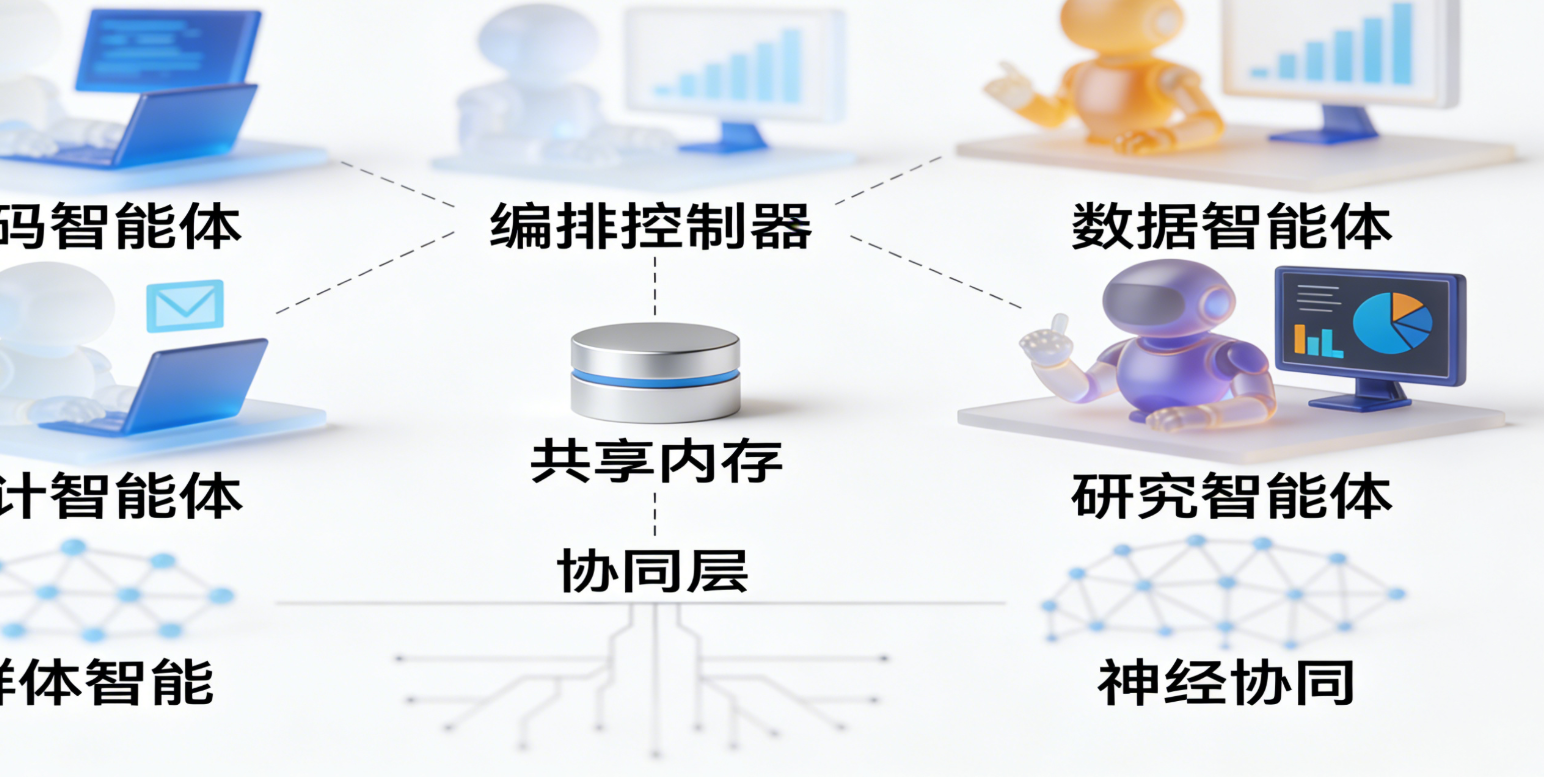
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
本项目完整教程资料
Harness Engineering:给AI套上“缰绳”
Harness Engineering的核心思想并非更换模型,而是在模型周围构建一个结构化的控制系统——包括系统提示词、工具/API、测试环境和中间件——从而引导模型输出,提升任务成功率并控制成本。这就像给一匹烈马套上缰绳,不改变它的奔跑能力,但让它按骑手的方向前进。
本文使用LangChain的DeepAgents库来实现这一理念。DeepAgents内置了任务规划、内存虚拟文件系统、子智能体生成等能力,天然适合作为Harness的载体。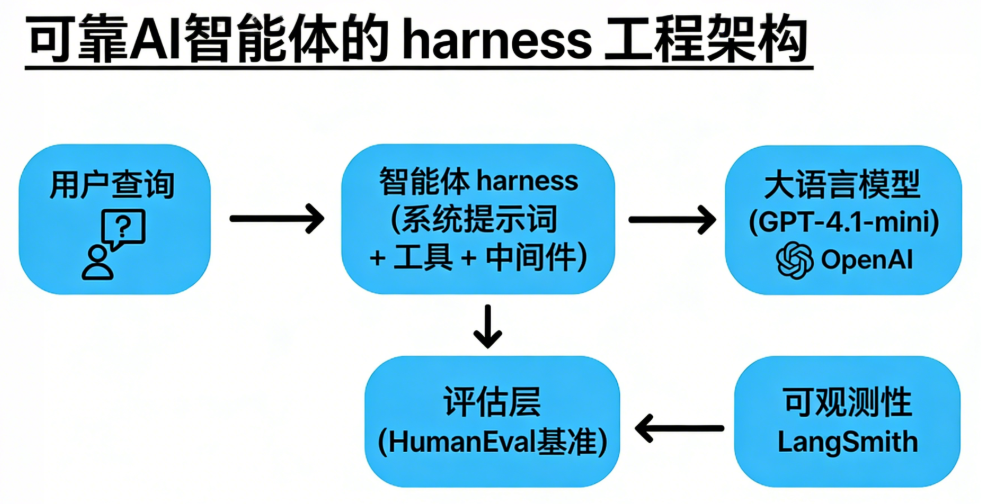
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
评估指标:Pass@1与Pass@k
我们选用HumanEval基准——包含164个手写Python编程问题,用于评估代码生成的正确性。主要关注两个指标:
• Pass@1(首次通过率):模型一次尝试解决问题的百分比。这是生产系统最关心的指标,代表用户体验。
• Pass@k(多轮通过率):模型生成k个样本中至少有一个正确的概率,用于衡量模型的探索能力。
构建第一个编码智能体
准备API密钥
1. 登录LangSmith控制台,点击“Setup Observability”,生成API密钥并保存。
2. 获取OpenAI API密钥,本文使用gpt-5-mini模型作为智能体的“大脑”。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
环境安装# 克隆HumanEval评测库并安装(移除自动执行脚本,避免误运行)
!git clone https://github.com/openai/human-eval.git
!sed -i '/evaluate_functional_correctness/d' human-eval/setup.py
!pip install -qU ./human-eval deepagents langchain-openai
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
初始化环境变量import os
from google.colab import userdata
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGSMITH_API_KEY'] = userdata.get('LANGSMITH_API_KEY')
os.environ['LANGSMITH_PROJECT'] = 'DeepAgentProject'
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
定义并推送提示词模板
我们将三个不同风格的提示词模板存储到LangSmith,方便后续迭代管理。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
推送成功后,可以在LangSmith控制台的Prompts板块看到它们:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
创建第一个智能体(使用v1提示词)from deepagents import create_deep_agent
from langchain.chat_models import init_chat_model
SELECTED_PROMPT = "coding-agent-v1"
pulled_prompt = ls_client.pull_prompt(SELECTED_PROMPT)
system_message = pulled_prompt.messages[0].prompt.template
llm_model = init_chat_model("openai:gpt-5-mini")
coding_agent = create_deep_agent(
model=llm_model,
system_prompt=system_message,
)
print("智能体已就绪")
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
加载HumanEval测试集
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
生成代码与后处理
定义一个函数,从智能体输出中提取纯函数代码。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
输出示例: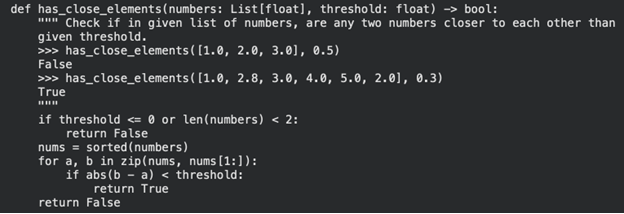
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
运行小规模评估(5个问题)
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
统计通过率与平均延迟:passed_count = sum(r["passed"] for r in evaluation_results)
pass_rate = passed_count / len(evaluation_results)
avg_latency = sum(r["latency_sec"] for r in evaluation_results) / len(evaluation_results)
输出示例: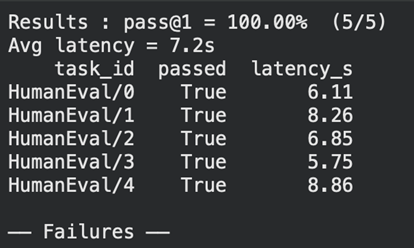
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
打开LangSmith的Tracing页面,可以看到每次调用的token消耗和费用:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
定义第二个智能体(v3提示词+中间件)
为了提升可靠性,我们引入“思维链”提示词,并添加一个中间件限制模型调用次数,防止陷入无限循环。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
再次评估新智能体:new_results = []
for task in task_id_list[:SAMPLE_SIZE]:
prob = all_problems[task]
t0 = time.time()
code = generate_with_new_agent(prob)
latency = time.time() - t0
outcome = check_correctness(prob, code, timeout=TIMEOUT_SEC)
new_results.append({
"task_id": task,
"passed": outcome["passe
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
结果示例: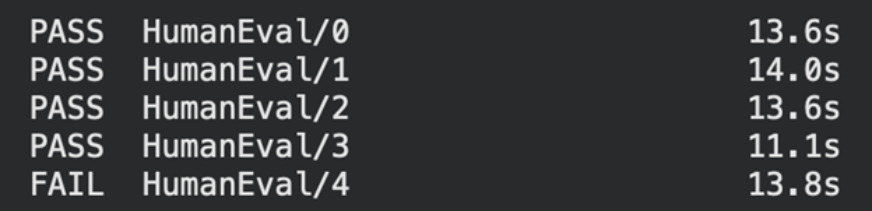
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
从初步结果看,v3提示词虽然通过率略高(4/5),但并非绝对更优,需要大规模测试才能判断稳定性。而中间件的引入控制了调用次数,避免了部分失败场景的无限重试。这正体现了Harness Engineering的思想:通过系统级的约束而非仅靠提示词来提升整体可靠性。
从单智能体到多智能体协作:Claude Flow
当任务复杂度超出单个智能体的能力范围时,我们需要一个多智能体编排框架。Claude Flow正是为此而生——它是一个开源框架,允许多个Claude智能体通过共享内存、分工协作完成复杂任务,其核心是“女王/工人”模型:一个协调者(女王)将任务拆解,分配给多个专门化的工人智能体,最终汇总成果。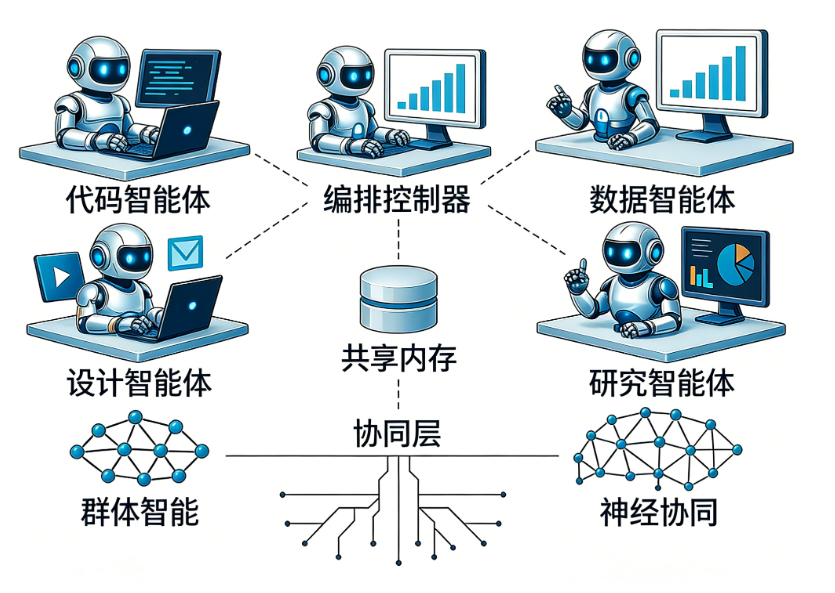
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
工作原理
当你提交任务时,协调智能体将其分解为子任务,分配给不同的专家智能体(如研究员、编码员、分析师)。这些智能体可并行或串行工作,结果存入共享内存。协调者监控进度、解决冲突,并合成最终输出。它还支持通过MCP(模型上下文协议)调用外部工具,甚至创建新的子智能体。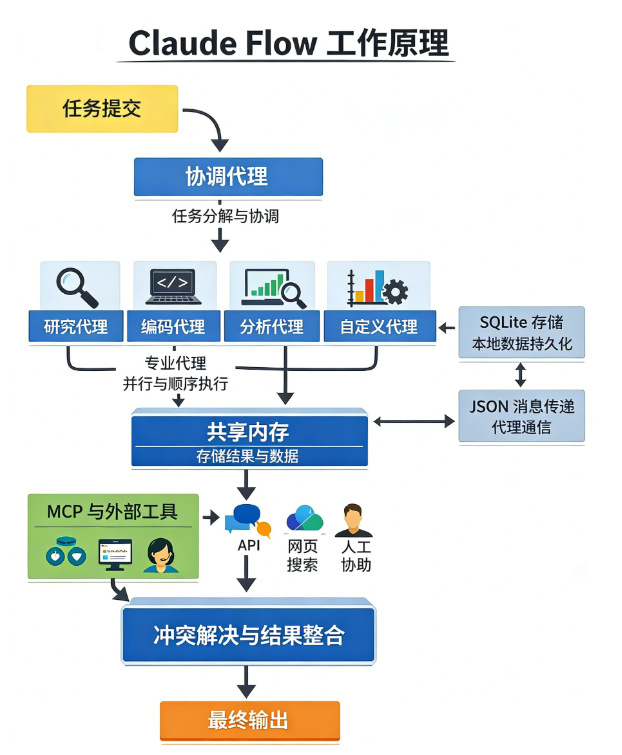
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
安装与配置
确保Node.js ≥ v18,并全局安装Claude Code和Claude Flow:npm install -g @anthropic-ai/claude-code
npm install -g claude-flow@alpha
验证安装:claude-flow --version # 应输出类似 ruflo v3.5.14
在项目目录初始化:mkdir task-app && cd task-app
npx claude-flow@alpha init --force
初始化截图: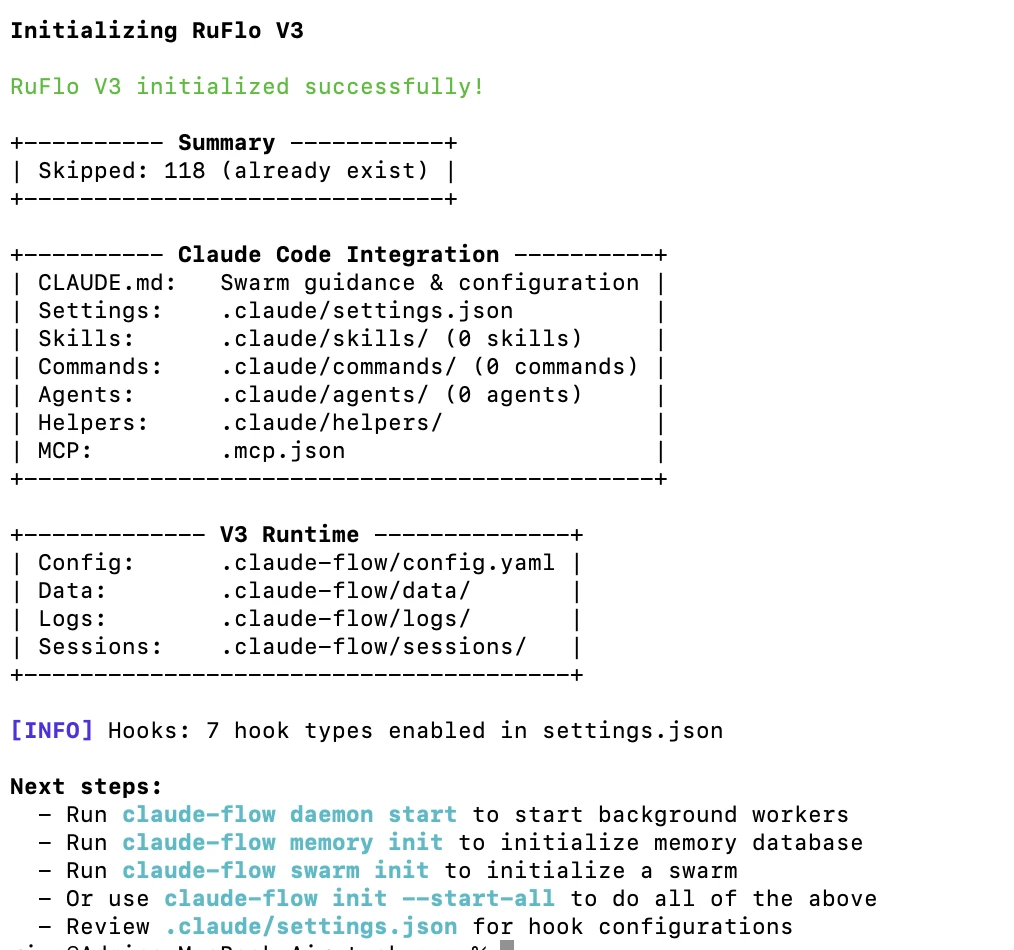
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
启动后台服务:claude-flow init --start-all
启动成功的界面:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
任务一:全栈应用自动生成
我们让Claude Flow生成一个任务管理Web应用(React前端 + Express后端 + SQLite数据库 + JWT认证)。注意:必须用引号包裹提示词,通过claude命令提交给智能体集群。
提交任务界面:
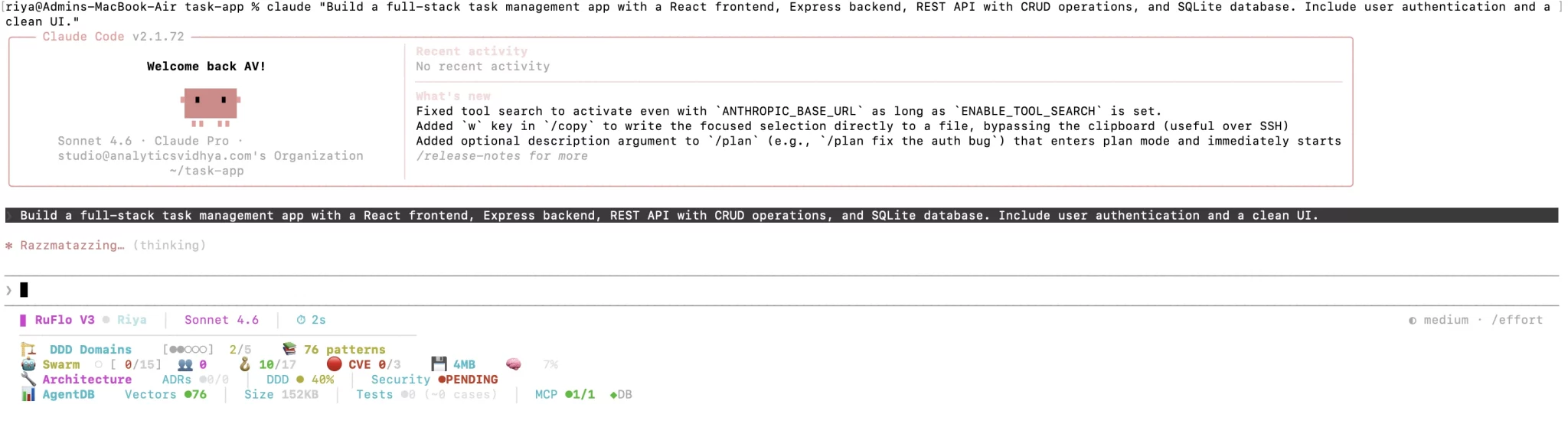
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
系统会自动生成前端、后端、数据库、认证等智能体,并行工作,几分钟后即可输出完整的项目代码和README。开发者原本需要数周的工作被压缩到几分钟。
任务二:多源研究报告生成
假设我们需要一份对比AI编排框架(Claude Flow、LangChain、AutoGen、CrewAI)的竞争分析报告。先确保MCP搜索工具已启用:
claude-flow daemon start
claude-flow swarm init
初始化成功截图:
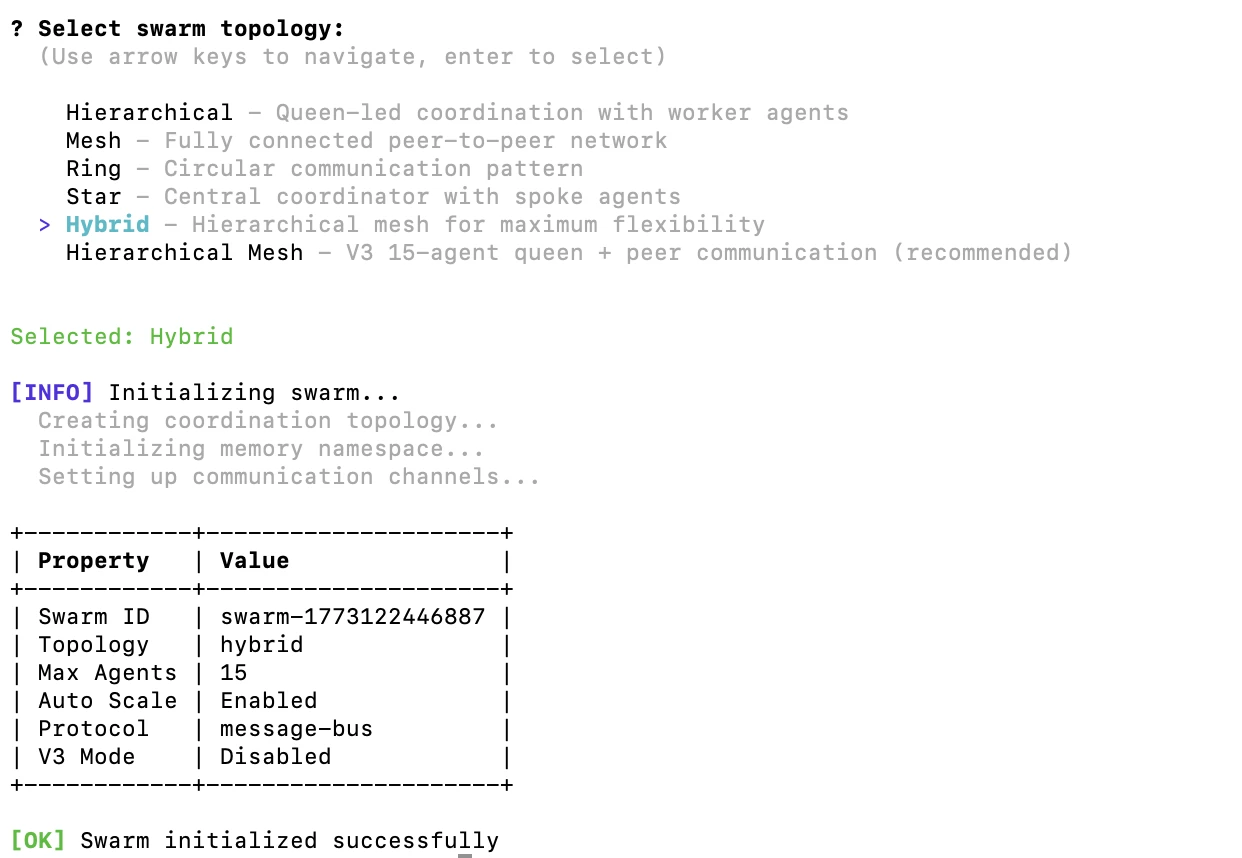
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
提交研究任务:
提交后截图:

阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
多个研究智能体会并行搜索文档、阅读代码库,最后由合成智能体整合成一份结构清晰的报告。传统上需要数小时的工作,在Claude Flow中仅需数分钟。
优缺点对比
| 维度 | 优势 | 劣势 |
|---|---|---|
| 性能 | 多智能体并行,大幅缩短任务完成时间 | 增加API调用次数,可能推高成本 |
| 输出质量 | 专家智能体专注特定领域,结果更精准 | LLM的非确定性可能导致输出结果波动 |
| 可扩展性 | 可通过增加智能体轻松扩展至企业级工作流 | 大型集群需精细调优以平衡成本与性能 |
| 灵活性 | 支持自定义智能体角色、工具和拓扑 | 初始配置和编排复杂度较高 |
| 系统设计 | 任务分解减轻单模型上下文负担 | 问题可能跨多个智能体,调试难度增加 |
| 生态 | 内置内存持久化、工具调用、错误处理等生产级特性 | 依赖Claude Code,与其他LLM提供商的兼容性有限 |
结论
Harness Engineering与多智能体编排共同构成了构建可靠AI系统的双引擎。前者通过对模型输入输出的系统性控制,提升了单一智能体的稳定性和可观测性;后者则通过分工协作,突破了单智能体的能力天花板。本文通过编码智能体的构建与评估,展示了Harness Engineering的实际操作;通过Claude Flow的两个应用案例,展示了多智能体协作的威力。未来,随着框架的成熟,我们有望像搭建乐高一样,快速组合出适应各种复杂场景的智能体集群。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
常见问题
Q1: 什么是中间件(middleware)?
A: 中间件是位于模型调用前后的软件层,用于扩展智能体能力、控制调用次数、处理错误等,是实现Harness Engineering的关键组件。
Q2: LangSmith有替代品吗?
A: 有,例如Langfuse、Arize Phoenix等,都提供LLM追踪与监控能力。
Q3: 评估编码智能体的行业标准基准有哪些?
A: 除HumanEval外,SWE-bench、BigCodeBench等也是常用的真实场景代码生成基准。
Q4: Claude Flow支持哪些模型?
A: 当前主要支持Claude系列模型(Sonnet、Opus),未来可能扩展至其他提供商的模型。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载
2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载

