LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
想象一下,你手头有数千篇新闻稿件,需要快速将它们分类到体育、财经、科技等不同栏目,或者自动发现其中隐藏的主题模式。

本项目完整代码和数据资料已分享至会员群
在过去的二十年里,文本表示方法经历了从简单统计到深度语义理解的演进:早期的词袋模型(Bag-of-Words, BoW) 简单粗暴,通过统计单词出现次数构建向量;随后的TF-IDF 引入词频逆文档频率,降低常见词干扰,一度成为工业界标配;如今,大语言模型(LLM)生成的嵌入(如Sentence-BERT)能捕捉上下文语义,成为前沿研究的宠儿。但哪种方法在实际业务中效果更好?何时该用简单方法,何时必须上复杂模型?
本项目完整代码和数据资料
本文将通过一个真实的新闻分类与聚类项目,为你揭晓答案。我们将使用新闻数据集,分别用BoW、TF-IDF和LLM嵌入构建特征,在Scikit-learn中训练多种分类器(逻辑回归、随机森林、SVM)并评估性能;同时对比它们在无监督聚类中的表现。你会发现,最先进的方法并不总是最优——对于某些任务,传统方法反而更快更准。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂“怎么做”,也懂“为什么这么做”;遇代码运行问题,更能享24小时调试支持。
1. 文本表示:从词袋到语义嵌入
在机器学习中,文本必须转化为数值向量才能被算法处理。这一过程称为“文本表示”或“特征提取”。让我们用通俗的比喻来理解三种主流方法:
- 词袋模型(BoW):好比给每篇文章建立一个“词汇表”,统计每个词出现的次数。它忽略了词序和语法,只关心“有没有”和“有多少”。优点是简单快速,缺点是丢失语义信息(比如“苹果好吃”和“好吃苹果”向量相同)。
- TF-IDF:在BoW基础上,给每个词加上一个权重——如果某个词在很多文章中都出现(如“的”“是”),它的重要性就降低;如果只在少数文章中出现,重要性就提高。这样能突出有区分度的关键词。
- LLM嵌入:利用预训练的大语言模型(如BERT),将整个句子或段落映射到一个稠密向量(如384维)。这个向量不仅包含词汇信息,还融入了上下文语义,因此能理解“苹果”是水果还是公司。
下面,我们将在Python中为同一批新闻数据生成这三种表示。
2. 数据准备与特征生成
首先导入所需库,加载BBC新闻数据集(包含2225篇新闻,分5类),并划分为训练集和测试集。
import pandas as pd
import numpy as np
from time import time
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sentence_transformers import SentenceTransformer
# 加载数据集
df = pd.read_csv("https://storage.googleapis.com/dataset-uploader/bbc/bbc-text.csv")
documents = df['text'].tolist()
raw_labels = df['category'].tolist()
# 标签编码
label_encoder = LabelEncoder()
encoded_labels = label_encoder.fit_transform(raw_labels)
# 划分数据集
docs_train, docs_test, y_train, y_test = train_test_split(
documents, encoded_labels, test_size=0.2, random_state=42, stratify=encoded_labels
)2.1 词袋模型特征
bow_vec = CountVectorizer(max_features=5000, min_df=2, stop_words='english')
X_bow_train = bow_vec.fit_transform(docs_train)
X_bow_test = bow_vec.transform(docs_test)2.2 TF-IDF特征
tfidf_vec = TfidfVectorizer(max_features=5000, min_df=2, stop_words='english')
X_tfidf_train = tfidf_vec.fit_transform(docs_train)
X_tfidf_test = tfidf_vec.transform(docs_test)2.3 LLM嵌入特征
embedder = SentenceTransformer('all-MiniLM-L6-v2')
X_emb_train = embedder.encode(docs_train, show_progress_bar=True, batch_size=32)
X_emb_test = embedder.encode(docs_test, show_progress_bar=False, batch_size=32)阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3. 比较一:文本分类性能
我们选择三种经典分类器:逻辑回归(LR)、随机森林(RF)和线性支持向量机(SVM)。分别在三组特征上训练并评估,记录准确率、F1分数和训练时间。
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, f1_score
classifiers = {
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'SVM': SVC(kernel='linear', random_state=42)
}
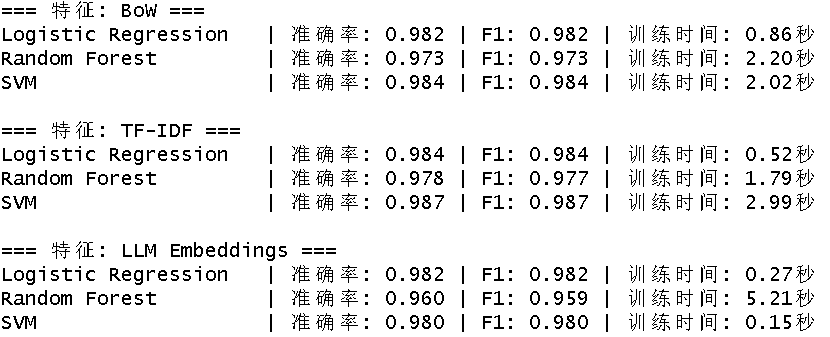
# 训练与评估代码(完整代码见社群)输出结果如下:
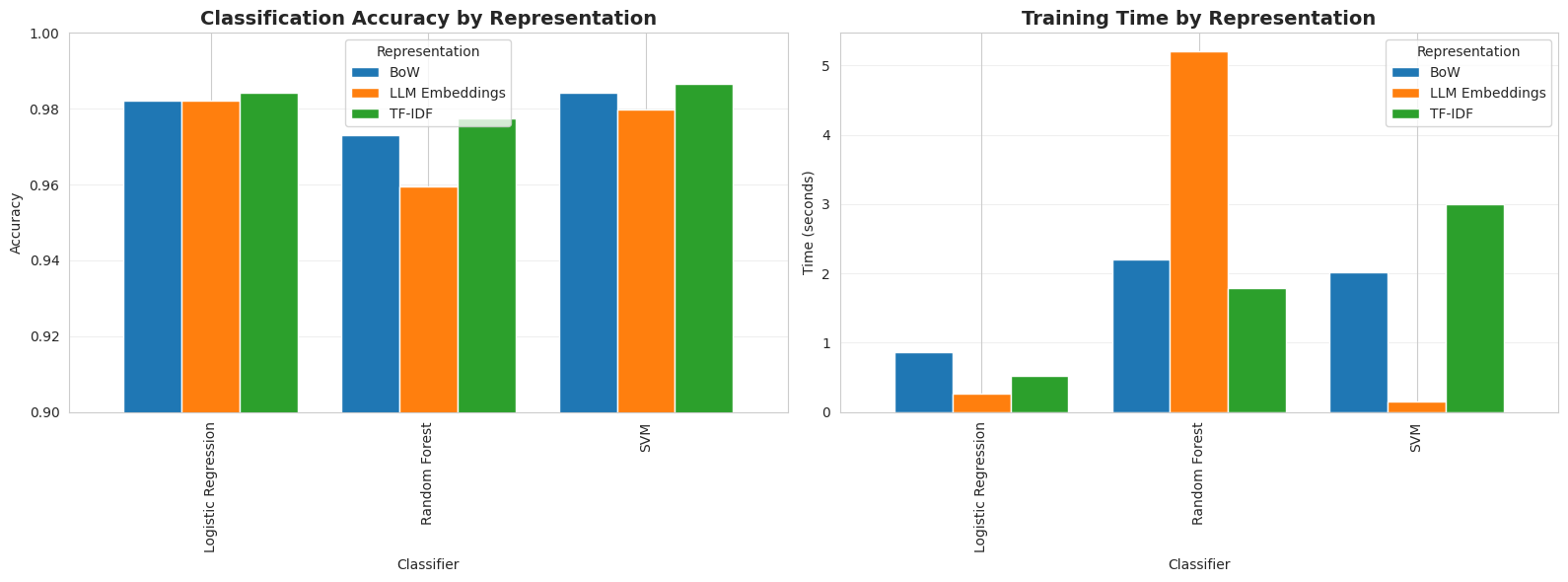
为了直观对比,绘制准确率和训练时间的柱状图:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
分类结果解读
从结果看,TF-IDF + SVM 组合以0.987的准确率拔得头筹,而LLM嵌入 + 逻辑回归 训练最快(0.27秒)。令人意外的是,最先进的LLM嵌入并未在所有指标上领先。原因在于BBC新闻数据集本身类别区分度极高(如体育类文章大量出现“足球”“比赛”等词),传统词频特征已足够捕捉规律;而嵌入模型带来的语义抽象反而可能引入噪声,且训练耗时更长。
这表明:在实际项目中,应从简单方法开始,只有当简单方法遇到瓶颈时,再考虑引入复杂模型。对于本数据集,TF-IDF + 逻辑回归 在精度和速度上取得了最佳平衡(准确率0.984,训练0.52秒),是理想的基线方案。
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
本文深入探讨了多种机器学习模型在股票预测中的应用,结合大语言模型与传统方法,提供了完整的代码实现。
阅读原文4. 比较二:文档聚类
无监督聚类不依赖标签,我们使用K-Means(k=5,与真实类别数一致)对三种特征分别聚类,评估聚类质量。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, adjusted_rand_score
# 使用全量数据生成特征
X_bow_full = bow_vec.fit_transform(documents)
X_tfidf_full = tfidf_vec.fit_transform(documents)
X_emb_full = embedder.encode(documents, show_progress_bar=True, batch_size=32)
# 聚类与评估代码(完整代码见社群)输出:
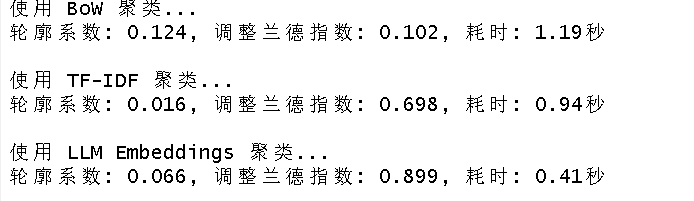
聚类质量可视化:
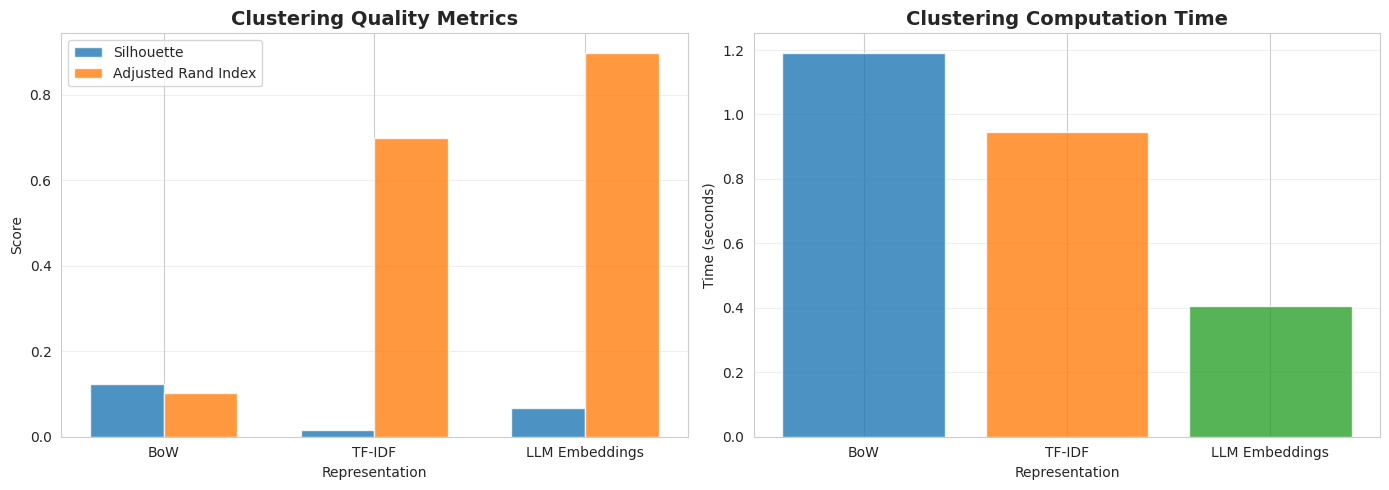
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
聚类结果解读
在聚类任务中,LLM嵌入以0.899的调整兰德指数(ARI)遥遥领先,表明其生成的簇与真实类别高度吻合。这是因为聚类完全依赖特征本身的内在结构,而嵌入包含了语义相似性,能更好地将同一主题的文章聚集在一起。尽管TF-IDF在分类中表现优异,但在无监督场景下,其基于词频的向量难以形成语义紧致的簇(轮廓系数仅0.016)。因此,若任务目标是探索性分析或主题发现,LLM嵌入是更优选择。
5. 总结与业务建议
通过新闻数据集的对比分析,我们得出以下实用指南:
| 任务类型 | 推荐方法 | 理由 |
|---|---|---|
| 快速构建分类基线 | TF-IDF + 逻辑回归 | 精度接近最优,训练快,可解释性强。 |
| 追求最高分类精度 | TF-IDF + SVM(线性) | 当数据线性可分时,SVM能最大化间隔,效果最佳。 |
| 大规模分类需实时预测 | LLM嵌入 + 逻辑回归/SVM | 嵌入维度低(384维),模型轻量,预测速度快(但生成嵌入需算力)。 |
| 无监督主题聚类 | LLM嵌入 + K-Means | 语义信息能有效聚合相似文档,显著优于词频方法。 |
| 极度简单且需解释 | 词袋 + 随机森林 | 可查看特征重要性,但精度略低。 |
关键洞察:没有一种方法能统治所有场景。先进技术(如LLM)在需要语义理解的任务中优势明显,但在强信号的传统分类任务中,传统方法(如TF-IDF)凭借高效和鲁棒性依然不可替代。实际项目应遵循“由简入繁”的原则,以最小成本验证可行性,再逐步升级。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
附录:代码获取与交流
本文所有代码和数据已上传至交流社群,如需完整代码(包括绘图、交叉验证、超参数调优等),请扫描下方二维码或点击“阅读原文”加入社群,与900+同行交流成长,获取24小时技术支持。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据

