llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程
在当今AI技术快速迭代的背景下,大模型的能力边界不断被突破,但随之而来的隐私安全、推理成本等问题也逐渐凸显。

本项目完整教程资料已分享至会员群
全文脉络流程图
本项目完整教程资料
项目文件目录
进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
Qwen3.5模型概述
Qwen3.5是阿里推出的最新大模型系列,在推理、编程和多模态任务上都有出色表现。独立基准测试显示,Qwen3.5-397B-A17B在LiveCodeBench、AIME26等测试中得分很高,不少类别上超过了主流模型,推理吞吐量也比前代提升明显。
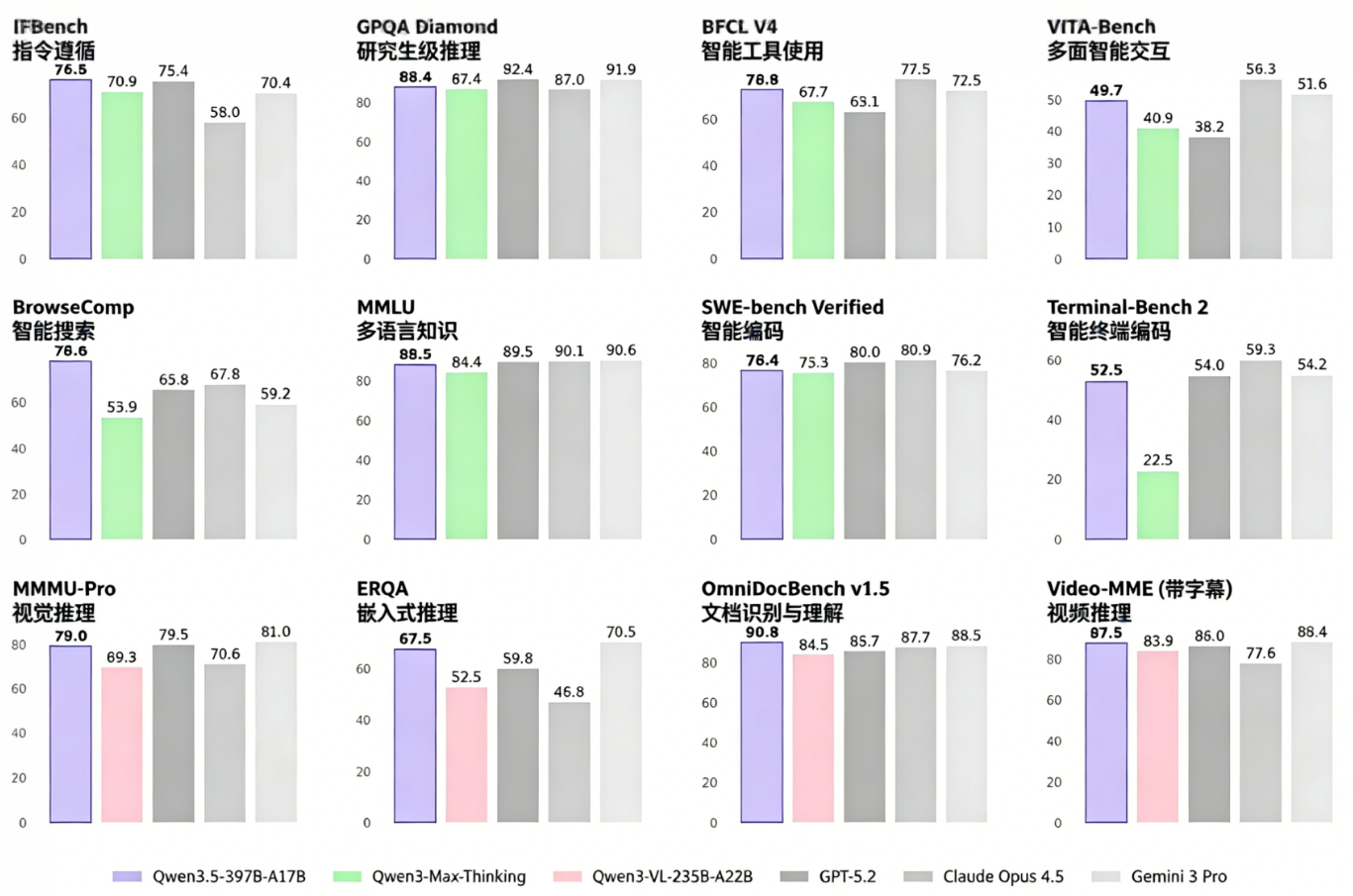
硬件与软件要求
要在本地流畅运行Qwen3.5,得先满足硬件和软件要求。我们这次用的是NVIDIA H200 GPU(141GB显存),搭配240GB系统内存,能高效运行MXFP4_MOE版本的Qwen3.5。作为参考,Unsloth 4-bit动态量化版本UD-Q4_K_XL大约占214GB磁盘空间,能直接放在256GB的设备上,也能在单张24GB GPU加256GB内存的环境中运行,每秒能生成25个以上token。3-bit量化版本能放在192GB内存里,8-bit版本则需要最多512GB的显存和内存总和。一般来说,显存加内存的总和最好和量化后的模型大小差不多。如果不够,llama.cpp能把部分模型卸载到SSD,但推理速度会变慢。软件方面,得安装最新的NVIDIA GPU驱动,还有近期的CUDA Toolkit,保证和llama.cpp、CUDA加速推理兼容。
环境搭建
要在本地运行Qwen3.5,得有一台性能强劲的GPU机器。大多数笔记本和台式机没有足够的显存或内存来运行这么大的模型,所以我们用云GPU虚拟机。这次我们用Hyperbolic来私密运行模型,也可以用AutoDL、恒源云等替代平台。选Hyperbolic是因为它目前的GPU实例性价比很高。
先启动一个单H200 GPU的实例。
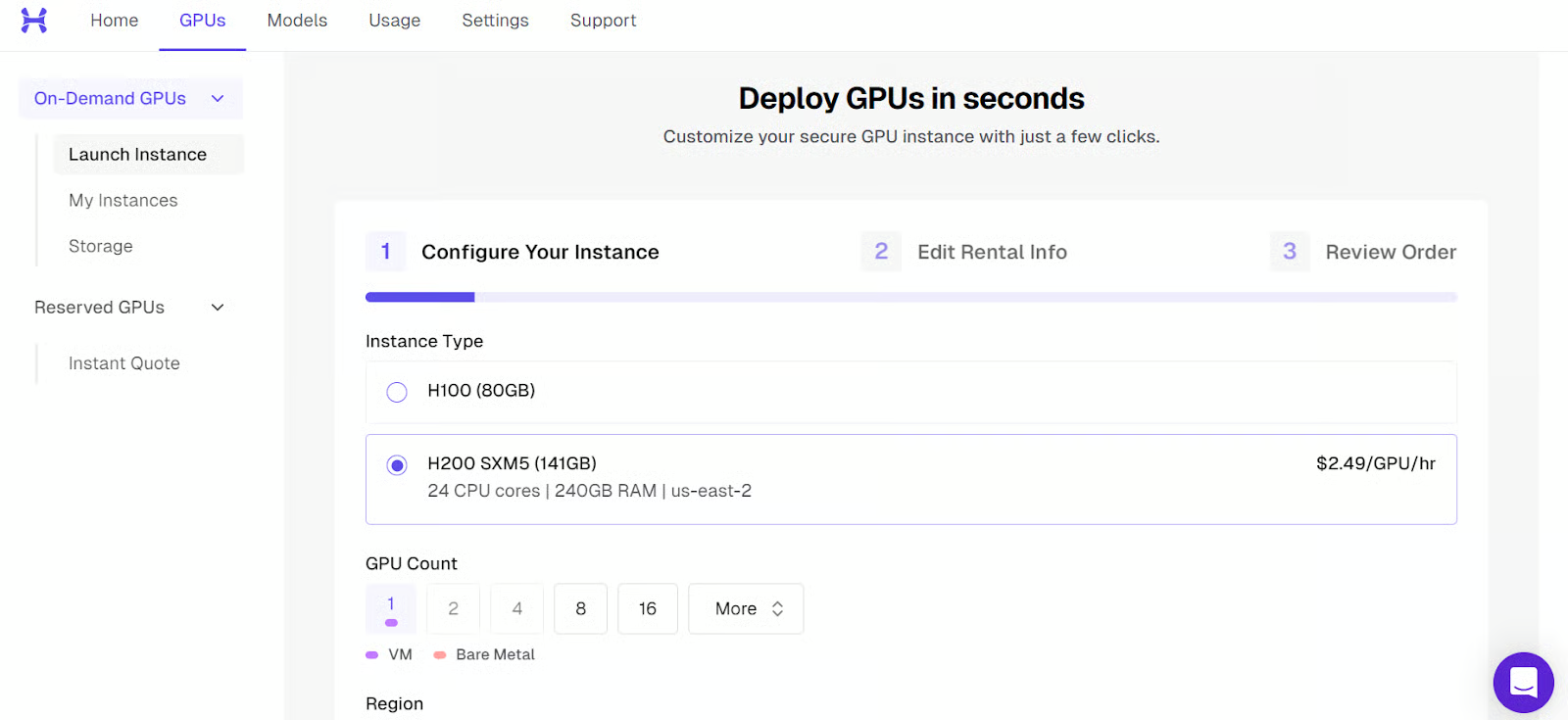
机器启动后,能看到公网IP地址和连接所需的SSH命令。连接前,确保本地设置好了SSH,创建虚拟机时添加了公钥。
实例准备好后,用带端口转发的SSH连接。这很重要,因为我们要通过8080端口在本地访问llama.cpp推理服务:
ssh -L 8080:localhost:8080 root@129.212.191.53第一次连接时,输入yes确认,然后用SSH密钥认证。
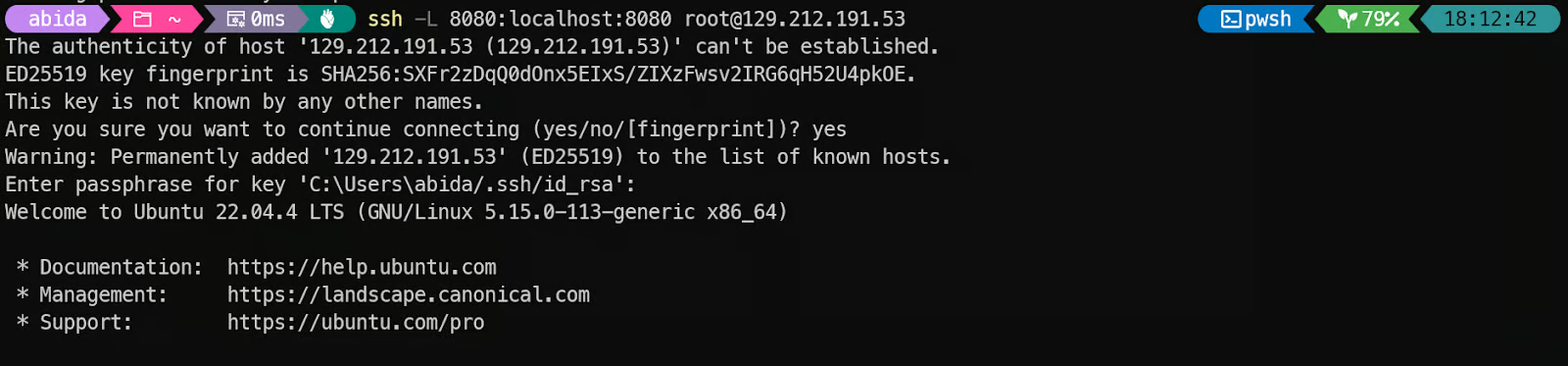
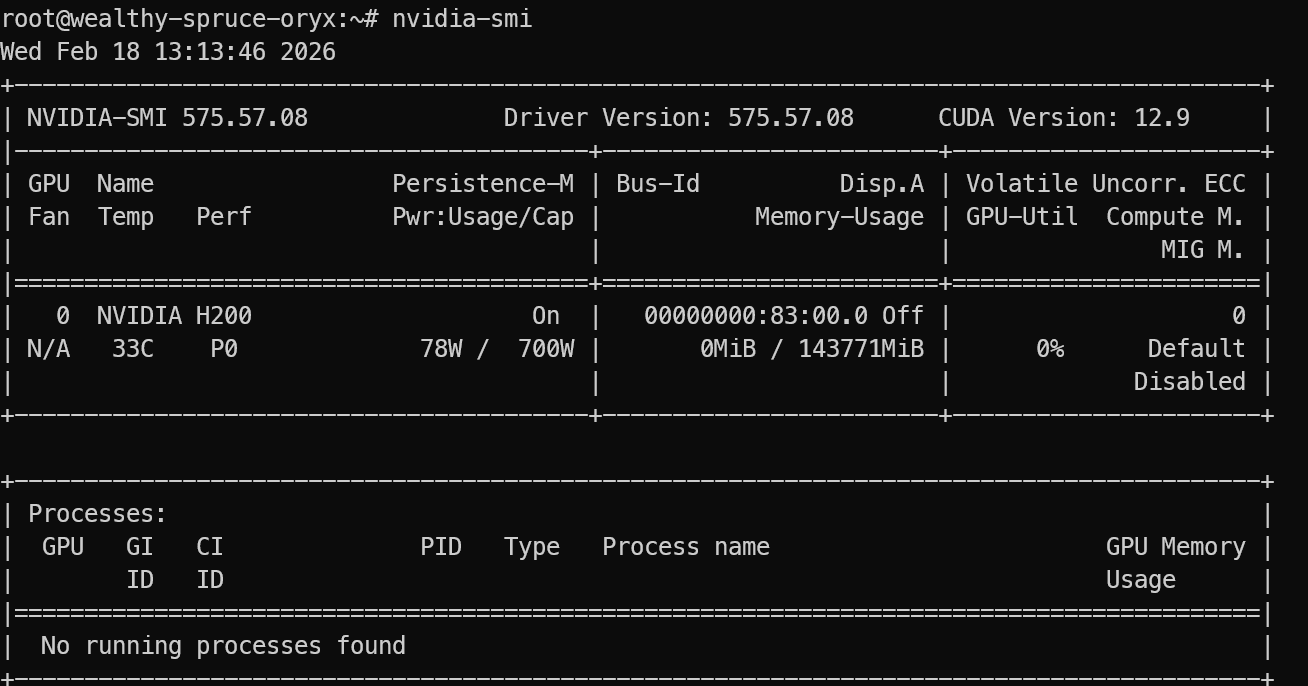
登录后,验证GPU是否正确检测:
nvidia-smi输出里应该能看到NVIDIA H200。
最后,安装下载、编译和运行llama.cpp所需的Linux软件包:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -y完成这步后,环境就准备好安装llama.cpp和本地运行Qwen3.5了。
安装llama.cpp
llama.cpp是开源的C/C++推理引擎,能让你用最少的设置本地运行大语言模型,支持CPU和GPU加速。
先克隆llama.cpp仓库:
接下来,用CMake配置启用CUDA的构建。我们用-DGGML_CUDA=ON启用CUDA,把CUDA架构设为90a,因为我们用的是NVIDIA H200(Hopper架构)。这能让构建生成针对Hopper特性优化的GPU代码。
现在编译服务器二进制文件。llama-server是内置的REST服务器,能把llama.cpp暴露为API端点:
最后,把编译好的二进制文件复制到主文件夹,方便运行:
下载Qwen3.5模型
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
现在llama.cpp安装好了,下一步是下载GGUF格式的Qwen3.5模型权重。这些文件很大,所以用Hugging Face CLI是最可靠的方法,直接把它们下载到GPU机器上。
我们先安装Python,因为Hugging Face下载工具和认证工具是作为Python包分发的。虽然llama.cpp本身是用C++写的,但Python让管理模型下载和传输容易多了。
先安装pip:
接下来,安装Hugging Face Hub客户端和性能辅助工具。hf_transfer和hf-xet能大幅加快下载速度,这在下载数百GB的模型文件时很重要:
现在从Hugging Face下载Qwen3.5模型。这次我们只获取MXFP4_MOE变体,它针对高效的MoE推理进行了优化:

下载完成后,模型文件会存储在model_storage/Qwen3.5里,准备加载到llama.cpp进行本地推理。
进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
启动推理服务
现在我们能用llama-server启动Qwen3.5了。这会给我们一个OpenAI兼容的API端点,能从本地工具和应用调用。
我们针对单GPU设置优化了服务器,做了三件关键的事。第一,启用--fit on,让llama.cpp自动在GPU显存和系统内存之间平衡模型,而不是在模型不能完全放进显存时失败。
第二,用--ctx-size 16384设置更大的上下文窗口,让服务器能处理更长的提示。第三,启用--jinja并传递--chat-template-kwargs来控制聊天格式,禁用思考模式以获得更快、更直接的响应。
用以下命令运行服务器:
模型加载时,你会注意到它同时使用GPU显存和系统内存,这对于大型MoE模型来说是正常的。

加载完成后,服务器可以在以下地址访问:
- 虚拟机上的
0.0.0.0:8080 - SSH端口转发后本地机器上的
http://127.0.0.1:8080
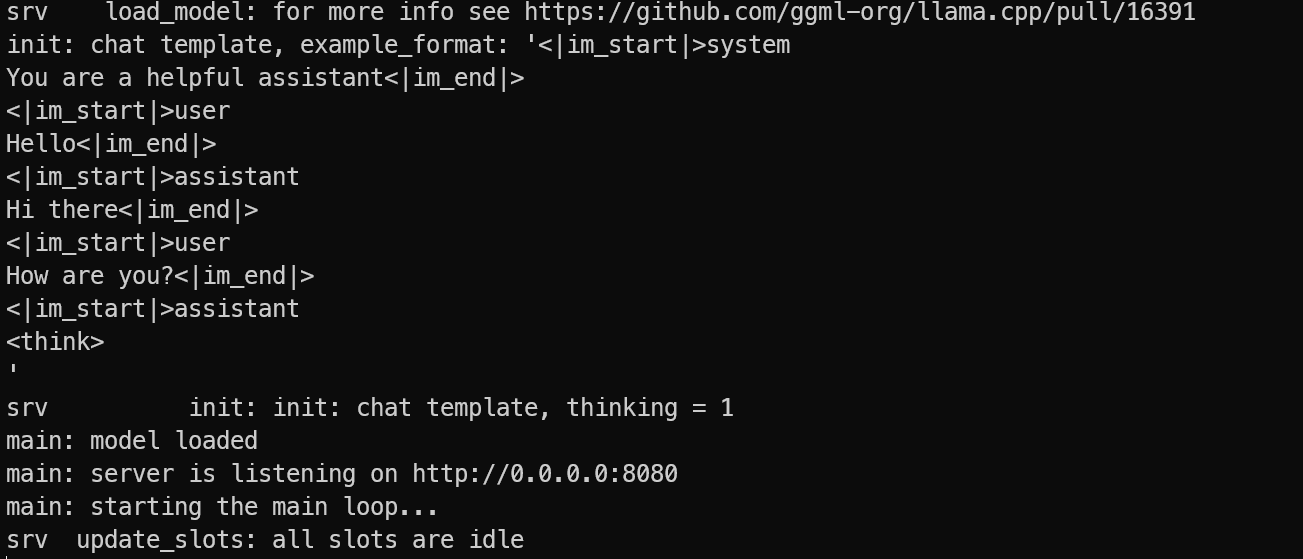
让服务器保持运行。在本地电脑上,打开一个新终端,用SSH端口转发重新连接:
然后通过列出可用模型来测试服务器:
如果响应中看到Qwen3.5,说明服务器运行正常,你可以准备从OpenAI SDK和本地应用调用它了。
接口测试
现在Qwen3.5推理服务器运行起来了,下一步是验证它能和真实的客户端应用正常工作。llama.cpp最大的优势之一是llama-server暴露了OpenAI兼容的API,这意味着你可以使用官方OpenAI SDK而不用改变代码结构。
先在本地机器上(或者如果你愿意的话在虚拟机里)安装OpenAI Python包:
现在运行一个简单的测试脚本。这会连接到你本地转发的端点http://127.0.0.1:8080/v1,而不是OpenAI的云服务器。
这里有几个重要的细节需要理解:
base_url指向你本地的Qwen3.5服务器,而不是OpenAI的API。- SDK仍然需要
api_key,但llama.cpp不强制认证,所以任何占位符值都可以。 model="Qwen3.5"名称和我们启动服务器时设置的别名匹配。
如果一切配置正确,你会从模型得到快速、清晰的响应。
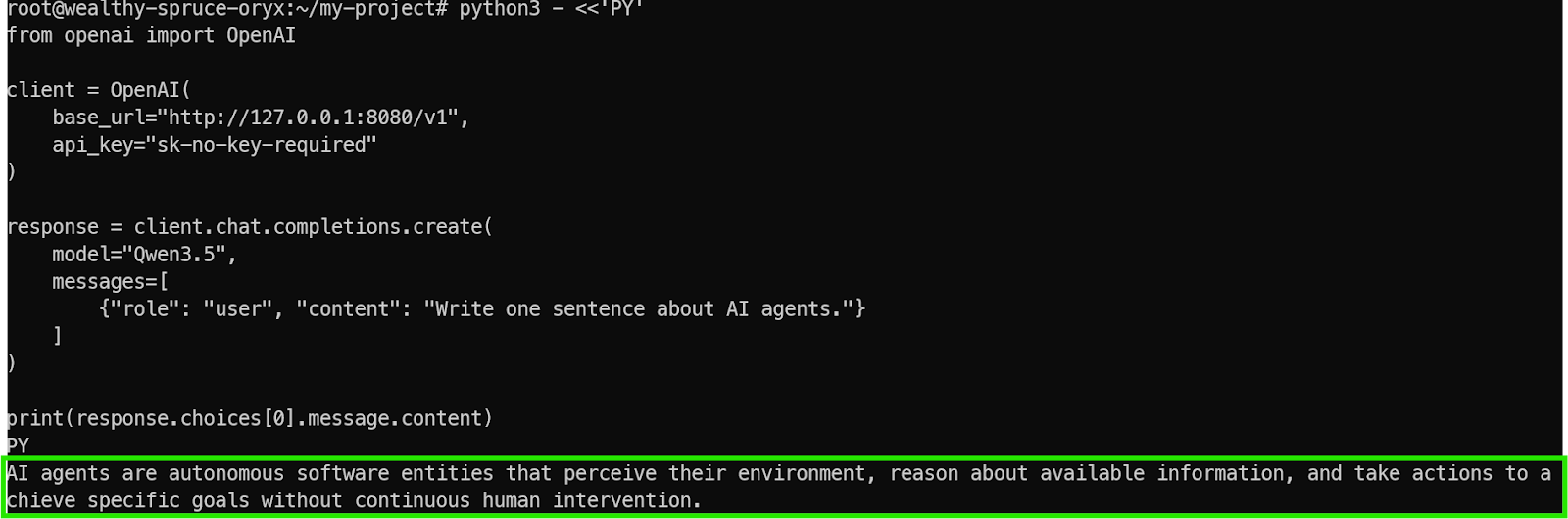
这确认了:- Qwen3.5模型加载成功
- llama.cpp服务器运行正常
- 你的SSH端口转发正常工作
- 端点与OpenAI风格的应用完全兼容
此时,你可以将Qwen3.5集成到任何已经支持OpenAI API格式的本地工具、智能体工作流或应用中。
股票筛选应用开发
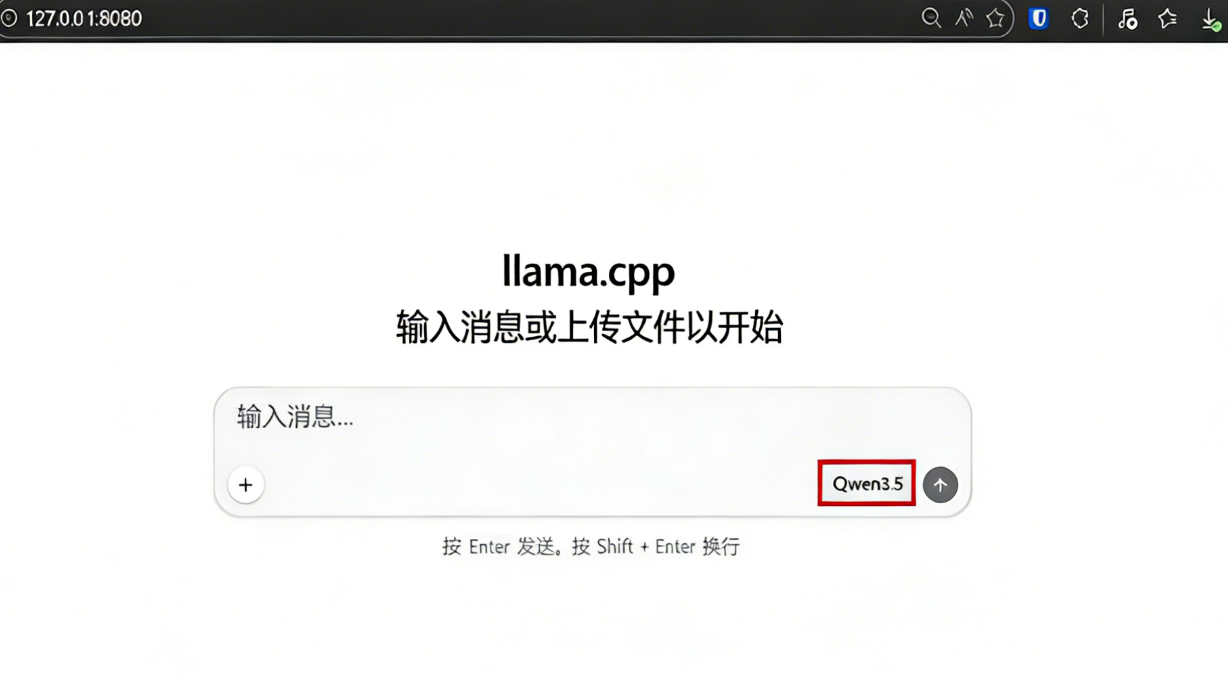
llama.cpp包含一个内置的、ChatGPT风格的WebUI,你可以用它直接在浏览器中与模型聊天。这对于快速测试、提示迭代和生成代码很有用,不需要先写任何客户端脚本。
因为我们已经设置了SSH端口转发,你可以在本地机器上打开WebUI,它的行为就像服务器运行在你的笔记本上一样。
默认情况下,WebUI可以在以下地址访问:
http://127.0.0.1:8080
如果这个页面加载,它确认了两件事。你的SSH隧道工作正常,Qwen3.5服务器可以在本地访问,同时仍然在GPU虚拟机上私密运行。
进入WebUI后,粘贴这个提示。目标是让模型同时生成Python代码和简短的使用指南。
构建一个简单的Python TUI(文本用户界面)“股票筛选训练器”,使用rich库运行(没有Web UI),用python stock_app.py启动。它应该让你输入股票代码列表,选择模式(成长/价值/分红)和风险(低/中/高),从免费来源获取每个股票的基本公开指标,显示实时加载状态,然后渲染一个漂亮的表格和“根据我的评分规则的前5名”部分,带有清晰的“仅供教育,不构成财务建议”免责声明,并将完整结果保存到stockults.csv。
几秒钟内,Qwen3.5应该会生成一个stop.py文件,通常还有一个关于如何运行它的快速解释。
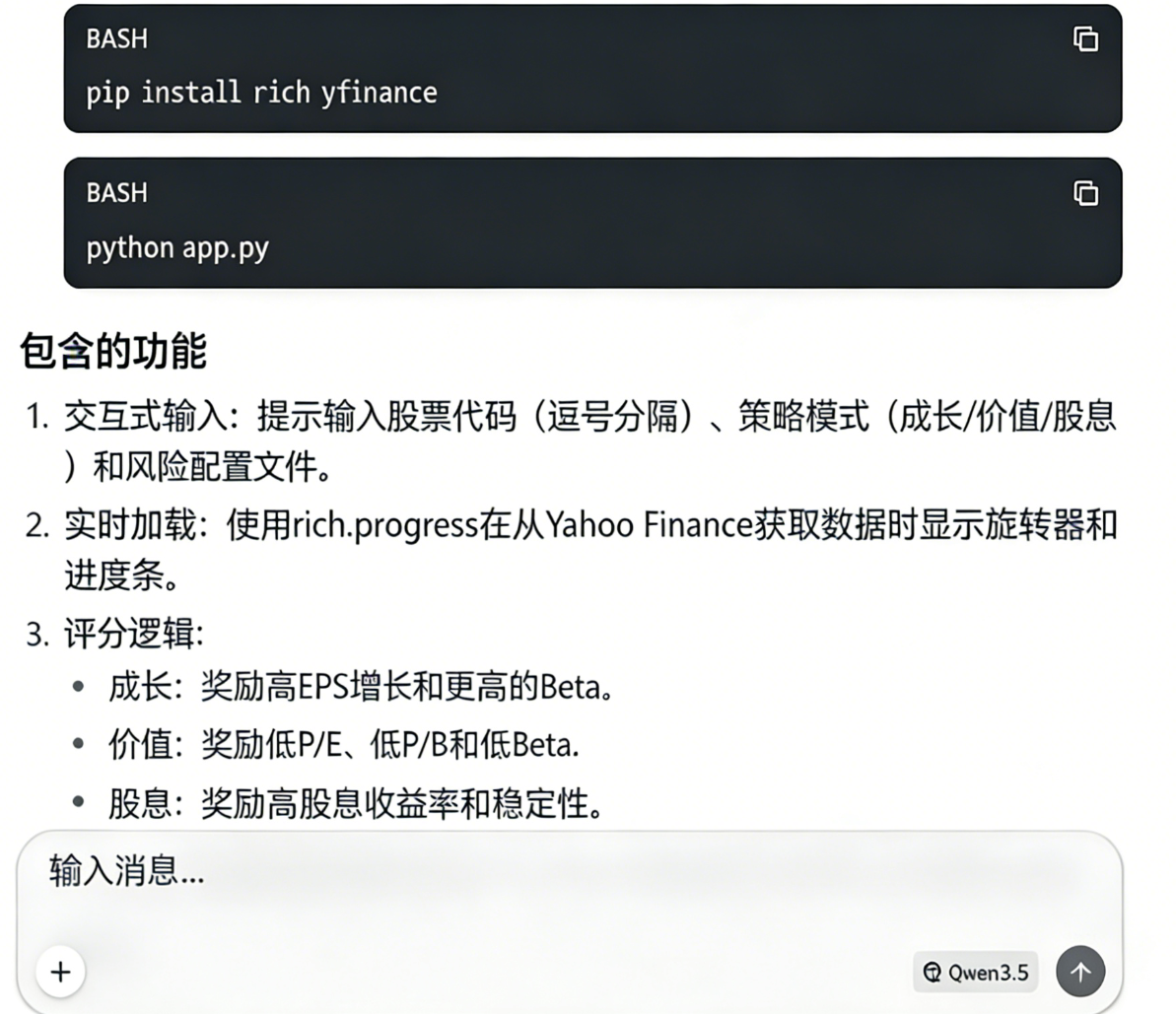
现在切换到你的本地终端(你的笔记本)。安装生成的应用所需的依赖:
这会安装:
rich用于TUI布局、表格、提示和进度指示器yfinance用于获取免费的公开股票指标
创建一个名为stock_app.py的文件,粘贴模型生成的代码,然后运行:
运行脚本后,你应该会看到TUI在你的终端中正常启动。应用会提示你输入要分析的股票代码,以及你偏好的筛选模式和风险水平。
例如,我们用三只热门股票测试了它。
短暂的加载阶段后,工具返回完整的股票指标表格,根据评分规则突出显示结果,并将所有内容保存到stock_results.csv文件。
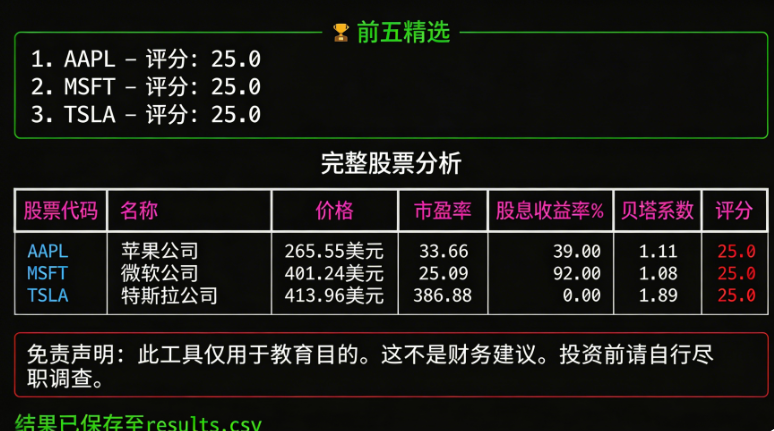
这是一个很好的例子,说明Qwen3.5如何仅使用4-bit量化模型端点和简单提示,一次性生成完整的工作应用。
进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
总结
本地运行Qwen3.5是一种强大的方式,可以在保持一切私密和完全在你控制之下的同时,访问前沿规模的模型。在本文中,模型托管在单个H200 GPU虚拟机上,使用SSH端口转发从本地机器安全访问,并通过优化的llama.cpp OpenAI兼容端点提供服务。
也就是说,有一些实际限制值得记住。因为一切都依赖于活动的SSH隧道,连接需要保持稳定。如果你的网络中断或会话断开,你会失去对本地端口的访问,通常需要重新连接并重新启动部分工作流。
另一个常见问题是正确构建llama.cpp。如果你没有为你的GPU指定正确的CUDA架构标志,编译可能需要更长时间,并且可能无法完全针对硬件进行优化。提前设置正确的架构会在构建时间和性能上产生明显差异。
最后,虽然4-bit MXFP4_MOE量化对于高效运行大型模型非常好,但它并不总是适合智能体编程工作流。在使用Qwen Code CLI、Kilo Code CLI和OpenCode等工具进行测试时,模型在深度推理方面遇到困难,并且在较长的生成循环中经常失败,有时甚至触发GPU不稳定。
更高精度的量化或更小的专注于推理的模型可能更适合可靠的基于智能体的编程。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载
2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据 Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据
Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据

