Python用Seedream4.5图像生成模型API调用与多场景应用|附代码教程
在AI技术快速迭代的当下,图像生成已从实验室走向产业落地。

本项目完整教程资料已分享至会员群
Seedream 4.5模型概述
Seedream 4.5是一款企业级图像生成模型,它在三个方面表现突出:一是生成的图像主体一致性好,不会出现前后画面人物或物体特征突变的情况;二是小文字细节清晰,能准确渲染海报、说明书中的文字内容;三是多图像融合能力强,可以把多张图的风格和元素自然结合。此外,模型支持4K高清图像生成,使用成本也比较低,每张图像生成仅需少量费用。需要注意的是,BytePlus的API服务在国内使用可能需要通过国际网络访问,国内也有类似的图像生成服务可供选择,如百度文心一格、阿里通义万相等,大家可根据实际需求选择。
本项目完整教程资料
API环境搭建
创建API密钥
要使用Seedream 4.5的API,首先需要创建API密钥。大家可以前往官方网站,点击页面上的“Get API”按钮,登录后在“Access API”页面创建密钥。创建过程中需要验证手机号并提供账单信息,不过这不是订阅制,只会按实际API请求收费。创建好密钥后,我们在代码同级目录下创建一个名为
.env的文件,将密钥按以下格式写入:
ARK_API_KEY=你的密钥Python依赖安装
我们需要安装几个Python包来与API交互,使用以下命令安装:pip install byteplus-python-sdk-v2 python-dotenv httpx requests typing_extensions pydantic
图像生成功能
基础图像生成
完成环境搭建后,我们可以开始生成图像。基础的图像生成流程包括导入依赖包、加载API密钥、创建客户端、发送请求这几个步骤。下面是修改后的代码,我们对变量名和语法做了调整,注释也翻译成了中文:
# 定义图像生成的提示词
img_prompt = """
生成一张具有未来感的城市夜景图,画面中有飞行汽车和全息投影广告。
"""
# 发送图像生成请求
img_resp = api_client.images.generate(
model="seedream-4-5-251128",
prompt=img_prompt,
watermark=False,
...... # 此处省略了部分可选参数设置代码
)
# 获取生成图像的URL
result_img_url = img_resp.data[0].url
print("生成的图像URL:", result_img_url)
图像下载
为了方便使用,我们可以编写一个函数将生成的图像下载到本地。将以下函数保存到util.py文件中,然后在生成图像的代码中导入并使用这个函数。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
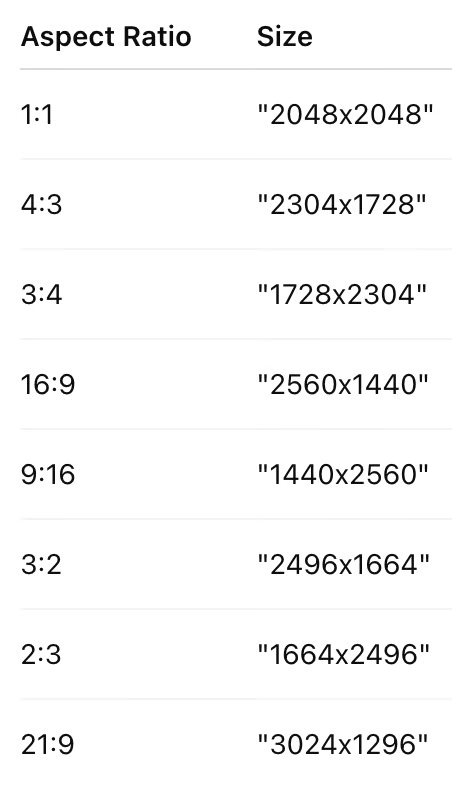
图像尺寸设置
Seedream 4.5提供了两种设置图像尺寸的方式。一种是直接指定分辨率为“2K”或“4K”,然后在提示词中描述图像的宽高比、形状或用途,让模型自动确定具体的宽高。另一种是直接用像素值指定,比如“2560×1440”,但需要注意总像素数要在360万到1670万之间,宽高比要在1/16到16之间。为了方便大家使用,模型官方给出了一些推荐的尺寸,如下表所示:
批量图像生成
如果需要生成一组主题相关的图像,比如故事板,可以使用批量生成功能。我们需要设置sequential_image_gen和sequential_image_gen_option参数。我们用提示词“生成一组4张视觉连贯、风格一致的图像,展示人生的四个阶段:童年、青少年、成年、老年。确保四张图是同一个人”做了测试,结果如下:

不过测试中发现,第四张图的人物性别偶尔会出现不一致的情况,大家使用时可以多生成几次挑选满意的结果。
文本生成测试
我们还测试了模型生成包含文字的图像的能力。提示词是“生成一张数学教授站在黑板前的图像,黑板上写着根号2是无理数的证明过程”,结果如下:
可以看到,不仅证明过程是正确的,文字的渲染也非常清晰,这对于需要生成包含说明文字的海报、教材插图等场景非常有用。
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
探索观点
图像编辑功能
基于URL的图像编辑
除了生成图像,我们还可以对已有图像进行编辑。最简单的方式是提供图像的URL,然后在提示词中描述要做的修改。我们用一张风景图做了测试,提示词是“把这张图变成雪景”,结果如下:

需要注意的是,Seedream 4.5不会自动匹配输入图像的尺寸,我们需要手动在请求中指定输出尺寸,比如示例中我们设置了
size="1664x2496"来匹配原图的宽高比。
本地图像编辑
如果图像在本地,我们可以先将其转换为base64格式,再进行编辑。在utils.py中添加以下函数:
# 读取图像文件并转换为base64
with open(img_path, "rb") as f:
encoded_data = base64.b64encode(f.read()).decode("utf-8")
return f"data:{mime_type};base64,{encoded_data}"
多图输入编辑
Seedream 4.5还支持同时输入多张图像,将它们的风格和元素融合在一起。比如我们输入一张人物照片和一张服装照片,提示词是“让图1的人物穿上图2的服装”,结果如下:
可以看到,模型很好地保留了人物的面部特征,这一点在很多同类模型中表现并不理想。
遮罩编辑尝试
有些图像生成模型支持通过黑白遮罩来指定编辑区域,但Seedream 4.5目前没有原生支持这个功能。不过我们尝试了把遮罩作为输入图像,同时在提示词中描述需求,在简单场景下也能得到不错的结果:
但这种方式并不稳定,比如我们尝试用同样的方法添加一只狗,就没有成功,所以如果需要精确的区域编辑,建议等待模型后续更新。
完整内容及更多AI见解和行业洞察请进群获取。
应用最佳实践
提示词编写技巧
为了获得更好的图像生成效果,编写提示词时要注意以下几点:用简洁的语言描述主体、动作和环境;说明图像的用途,比如海报、logo等;通过关键词或参考图像控制风格;将需要出现在图像中的文字放在双引号中。
图像编辑技巧
编辑图像时,要明确说明哪些部分需要修改,哪些部分保持不变,可以使用“添加”“移除”“替换”“修改”这几个词来描述操作。如果场景比较复杂,还可以在图像上用箭头、方框等标记出要编辑的区域。
批量生成技巧
使用多张输入图像时,要在提示词中明确每张图的角色,比如“图1提供人物,图2提供服装”;同时,即使模型有参数指定生成数量,也最好在提示词中再次强调,比如“生成一组4张图像”。
总结
Seedream 4.5是一款成熟且实用的图像生成模型,它在图像质量、指令遵循和成本方面都有不错的表现。通过Python API,我们可以轻松实现图像生成、编辑、批量处理等功能,将其应用到创意设计、营销物料制作等多个场景中。
模型的API设计也非常友好,同一个生成端点可以处理单图生成、URL/本地图编辑、多图融合、批量生成等多种需求,只需要调整几个参数即可切换模式。虽然它没有带来特别颠覆性的创新,但在现有功能的执行完成度上做得非常出色,适合作为企业级应用的工具。
如果大家想进一步学习相关知识,可以参考Python API入门、Python图像处理等课程,为实际项目打下更坚实的基础。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据
Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载
2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据

