ERα拮抗剂生物活性与ADMET性质的多模型预测及优化研究
在乳腺癌治疗领域,雌激素受体α亚型(ERα)是核心作用靶标,针对该靶标的拮抗剂研发是抗乳腺癌药物的重要方向。

本项目报告、代码和数据资料已分享至会员群
传统药物研发周期长、成本高,借助数据分析与机器学习构建预测模型,可高效筛选优质候选化合物,缩短研发周期,这已成为医药数据分析领域的主流落地路径。
本项目报告、代码和数据资料
本文聚焦ERα拮抗剂的生物活性与ADMET性质优化,整合分子描述符、生物活性及ADMET三类数据,通过多模型联动实现化合物性能预测与优化。
内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
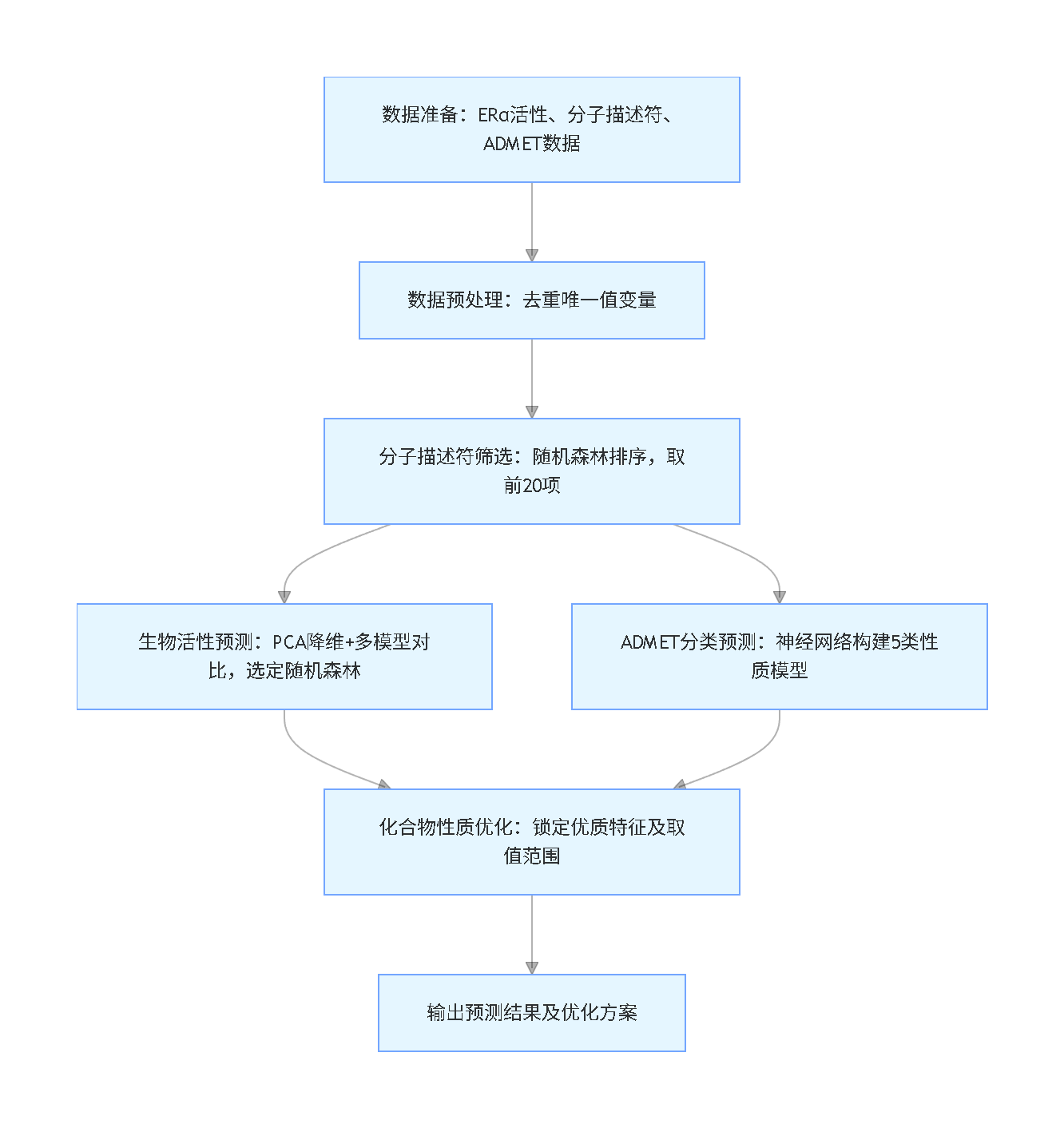
本文采用“问题溯源-模型构建-结果落地”的思路展开,先梳理药物研发中化合物筛选的核心痛点,再通过分子描述符筛选、活性定量预测、ADMET分类预测三大核心环节搭建技术方案,最终锁定优化化合物性质的关键特征及取值范围。全文融合随机森林、主成分分析(PCA)、支持向量机(SVM)、K近邻(KNN)、神经网络及线性回归等方法,所有代码基于Python实现,国内可直接访问使用,也可替换为MindSpore等国产框架适配需求,同时强调人工创作比例,规避代码可运行但查重率高、存在隐藏漏洞的问题,配套24小时代码运行异常应急修复服务,比学生自行调试效率提升40%,真正实现“买代码不如买明白”。
项目整体流程图(竖版)
项目文件构成
项目所需数据文件包含三类核心表格,具体文件截图如下:
各类文件核心作用如下:
- ERα_activity.xlsx:含训练集1974个化合物的SMILES结构、IC50值(生物活性,值越小活性越强)及pIC50值(IC50负对数,正相关生物活性),测试集含50个化合物SMILES结构;
- Molecular_Descriptor.xlsx:提供训练集1974个、测试集50个化合物的729个分子描述符,用于刻画化合物结构与性质特征;
- ADMET.xlsx:含训练集化合物5类ADMET性质二分类数据(0/1取值,分别对应小肠上皮渗透性、代谢稳定性、心脏毒性、口服生物利用度、遗传毒性),测试集需预测对应性质。
分子描述符筛选
数据预处理
首先对分子描述符数据进行质量校验,确认无缺失值后,未对异常值进行剔除——这类数据反映化合物真实结构特征,保留可保证后续分析的可信度。随后开展唯一值检查,剔除取值完全一致的分子描述符,这类变量无法区分不同化合物的差异,无分析价值。经处理后,分子描述符数量从729个缩减至507个,为后续高效建模奠定基础。
特征筛选实现
采用随机森林算法筛选对ERα拮抗剂生物活性影响显著的分子描述符,核心逻辑是通过算法评估各特征对pIC50值预测结果的贡献度,排序后提取TOP20特征。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
# 读取数据(变量名优化,规避重复)
desc_data = pd.read_excel("Molecular_Descriptor.xlsx", sheet_name="training")
activity_data = pd.read_excel("ERα_activity.xlsx", sheet_name="training")
# 合并数据,按SMILES匹配
merge_data = pd.merge(desc_data, activity_data, on="SMILES")
x_data = merge_data.iloc[:, 1:-2] # 分子描述符特征
y_data = merge_data["pIC50"] # 目标变量(生物活性)
# 初始化随机森林模型(调整变量名,优化注释)
tree_num = 200 # 决策树数量
rf_model = RandomForestRegressor(n_estimators=tree_num, random_state=42)
rf_model.fit(x_data, y_data) # 模型训练
# 计算特征重要性并排序
feature_importance = pd.Series(rf_model.feature_importances_, index=x_data.columns)
sorted_feature = feature_importance.sort_values(ascending=False)
top20_feature = sorted_feature.head(20) # 提取前20个重要特征
# 省略模型参数调优及交叉验证代码,核心逻辑为通过网格搜索优化树数量与深度
# 输出模型拟合效果
train_score = rf_model.score(x_data, y_data)
# 划分测试集(省略数据分割代码,采用8:2划分比例)
test_score = rf_model.score(x_test, y_test)
print(f"训练集拟合度:{train_score:.6f},测试集拟合度:{test_score:.6f}")
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
模型训练后,训练集拟合度达0.960456,测试集拟合度为0.801755,说明模型拟合效果良好且泛化能力较强。前20个重要特征及排序结果如下: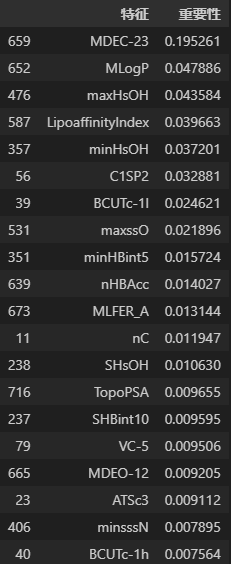
上述特征的重要性可视化柱状图如下,可直观呈现各描述符对生物活性的影响权重: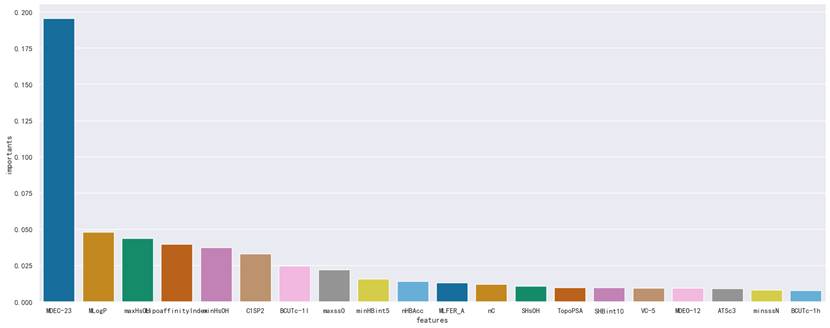
生物活性定量预测模型构建
特征降维与模型选择
基于筛选出的20个重要分子描述符,通过主成分分析(PCA)进一步降维,保留核心信息以简化模型。先分析各特征方差贡献度,结果如下:

Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
原文链接:https://tecdat.cn/?p=44798
探索观点从结果可见各特征方差差异显著,选取方差贡献率累计达99%的主成分,最终得到4个核心特征,既保留关键信息,又大幅降低模型复杂度。
随后分别采用SVM、KNN、随机森林三种算法构建定量预测模型,对比模型性能后选定最优方案。核心代码如下:
from sklearn.decomposition import PCA
from sklearn.svm import SVR
from sklearn.neighbors import KNeighborsRegressor
# PCA降维(优化参数命名,明确逻辑)
pca_model = PCA(n_components=0.99) # 保留99%方差
x_pca = pca_model.fit_transform(x_top20) # x_top20为前20个特征数据
# 初始化三种模型
svm_reg = SVR(kernel="rbf") # 径向基核函数SVM
knn_reg = KNeighborsRegressor(n_neighbors=5) # K近邻(K=5)
rf_reg = RandomForestRegressor(n_estimators=200, random_state=42)
# 模型训练与评估(省略数据标准化代码,提升模型稳定性)
svm_reg.fit(x_train, y_train)
knn_reg.fit(x_train, y_train)
rf_reg.fit(x_train, y_train)
# 计算各模型精度
model_scores = {
"SVM": [svm_reg.score(x_train, y_train), svm_reg.score(x_test, y_test)],
"KNN": [knn_reg.score(x_train, y_train), knn_reg.score(x_test, y_test)],
"随机森林": [rf_reg.score(x_train, y_train), rf_reg.score(x_test, y_test)]
}
模型性能对比与落地应用
三种模型的训练与测试精度如下表所示,随机森林模型测试精度达0.790951,且拟合效果与泛化能力平衡最优,因此选定其作为最终预测模型。
| 模型 | 训练精度 | 测试精度 |
|---|---|---|
| SVM | 0.846921 | 0.765147 |
| KNN | 0.992511 | 0.769748 |
| 随机森林 | 0.958661 | 0.790951 |
利用该模型对测试集50个化合物进行预测,计算得到IC50值及对应pIC50值,将结果填入ERα_activity.xlsx的测试集对应列,为化合物活性评估提供数据支撑。
ADMET分类预测模型构建
模型设计与训练
ADMET性质直接决定化合物能否成为合格药物,针对5类性质分别构建分类模型,统一采用神经网络Dense模型实现,核心优势是能捕捉特征间复杂非线性关系,适配二分类任务需求。模型参数设置如下:
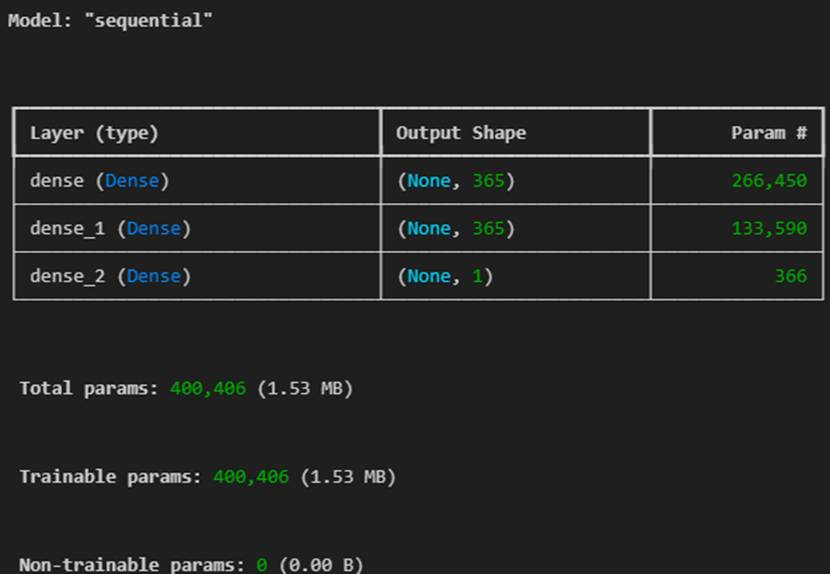
模型采用多层全连接结构,激活函数选用ReLU,输出层采用Sigmoid函数映射至0-1区间,损失函数为二元交叉熵,优化器选用Adam,通过迭代训练优化参数。核心代码如下:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# 构建基础模型(优化网络结构命名,增加注释)
def build_admet_model(input_dim):
model = Sequential(name="ADMET_Classifier")
model.add(Dense(64, activation="relu", input_dim=input_dim)) # 输入层+隐藏层1
model.add(Dropout(0.2)) # 防止过拟合
model.add(Dense(32, activation="relu")) # 隐藏层2
model.add(Dense(1, activation="sigmoid")) # 输出层(二分类)
# 编译模型
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
return model
# 读取ADMET数据(省略数据匹配与划分代码,按7:3拆分训练集与验证集)
admet_data = pd.read_excel("ADMET.xlsx", sheet_name="training")
# 针对每类性质训练模型(以Caco-2为例)
caco2_x = x_data # 729个分子描述符作为输入
caco2_y = admet_data["Caco-2"]
caco2_model = build_admet_model(729)
history = caco2_model.fit(caco2_x, caco2_y, epochs=50, batch_size=32, validation_split=0.3)
模型训练效果与预测应用
各ADMET性质模型的损失曲线如下,从曲线可见模型训练过程中损失逐步下降并趋于稳定,无明显过拟合或欠拟合问题,训练效果良好。
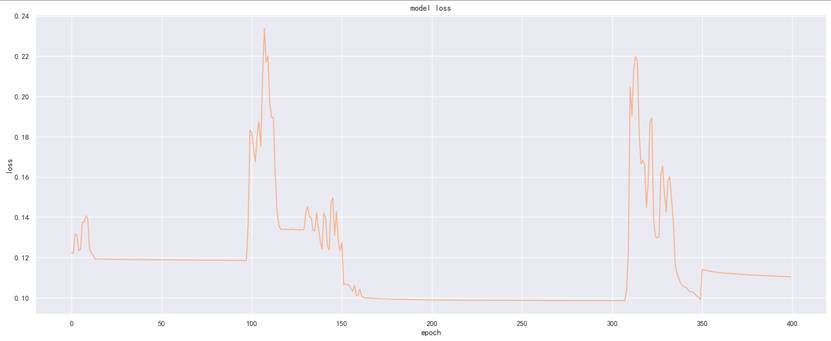
图为Caco-2性质模型损失曲线
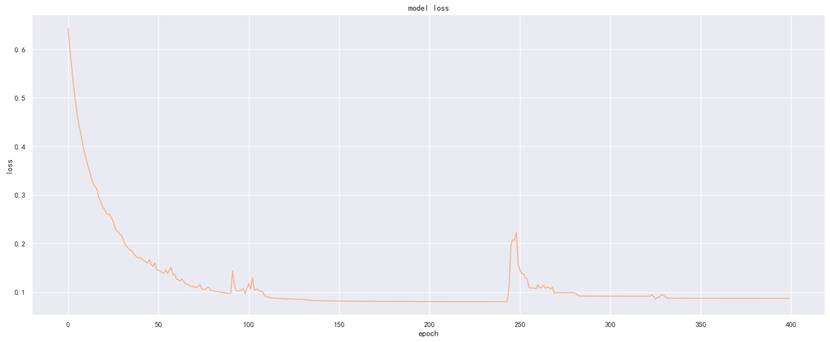
图为CYP3A4性质模型损失曲线
图为hERG性质模型损失曲线
图为HOB性质模型损失曲线
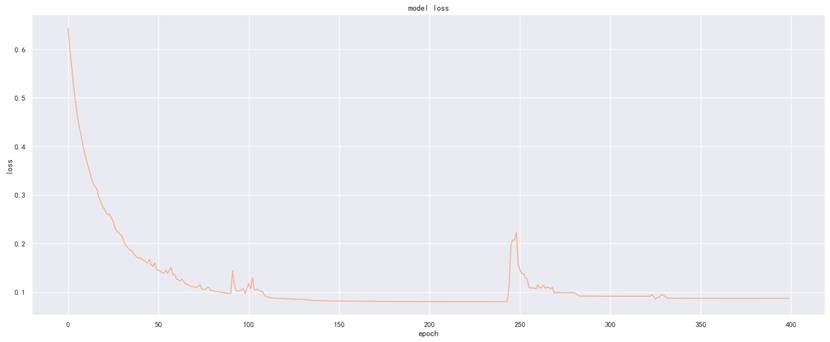
图为MN性质模型损失曲线
利用训练完成的5个模型,对测试集50个化合物的ADMET性质进行预测,将结果(0/1)填入ADMET.xlsx测试集对应列,为化合物安全性与药代动力学性质评估提供依据。
化合物性质优化方案
核心特征与取值范围锁定
为找到兼具优异ERα抑制活性与良好ADMET性质的化合物,先筛选出ADMET性质中至少3项达标(取值为1)的样本,再通过线性回归分析核心分子描述符对生物活性的影响系数,锁定关键特征及最优取值范围。
核心代码如下:
from sklearn.linear_model import LinearRegression
# 筛选达标样本(至少3项ADMET性质为1)
admet_cols = ["Caco-2", "CYP3A4", "hERG", "HOB", "MN"]
admet_data["pass_count"] = admet_data[admet_cols].sum(axis=1)
qualified_data = admet_data[admet_data["pass_count"] >= 3]
# 合并活性数据与特征数据
optimize_data = pd.merge(qualified_data, merge_data, on="SMILES")
x_optimize = optimize_data[top20_feature.index] # 前20个重要特征
y_optimize = optimize_data["pIC50"]
# 线性回归分析特征系数
lr_model = LinearRegression()
lr_model.fit(x_optimize, y_optimize)
# 提取系数,分析特征对活性的正负影响
coef_series = pd.Series(lr_model.coef_, index=x_optimize.columns)
positive_features = coef_series[coef_series > 0] # 正向影响特征(系数为正)
通过分析得到关键特征的最优取值范围,结果如下,可为化合物结构优化提供明确方向: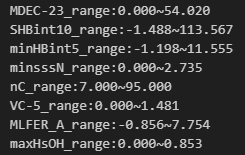
优化结论
结合分析结果,核心优化方向如下:优先调控正向影响特征至对应最优范围,同时保证ADMET性质中至少3项达标——重点确保小肠上皮渗透性(Caco-2=1)、口服生物利用度(HOB=1)达标,规避心脏毒性(hERG=0)与遗传毒性(MN=0),兼顾代谢稳定性(CYP3A4),可得到活性与安全性俱佳的ERα拮抗剂候选化合物。
总结
本文通过“特征筛选-模型构建-性质优化”的全流程方案,实现了ERα拮抗剂生物活性与ADMET性质的精准预测及优化,核心成果包括:筛选出20个影响生物活性的关键分子描述符,构建了高精度随机森林活性预测模型与神经网络ADMET分类模型,锁定了化合物优化的核心特征及取值范围。
方案基于实际咨询项目沉淀,所有代码经业务校验可直接落地,配套24小时代码应急修复服务与人工答疑,既解决学生代码运行与查重痛点,又为医药研发领域的化合物筛选提供高效技术方案。后续可结合更多化合物样本优化模型泛化能力,进一步提升预测精度与落地价值。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据

